CS338-Ch3
advertisement

CS-338
Compiler Design
Dr. Syed Noman Hasany
Assistant Professor
College of Computer, Qassim University
Chapter 3: Lexical Analyzer
• THE ROLE OF LEXICAL ANALYSER :
It is the first phase of the compiler.
It reads the input characters and produces as output a
sequence of tokens that the parser uses for syntax
analysis.
It strips out from the source program comments and
white spaces in the form of blank , tab and newline
characters .
It also correlates error messages from the compiler
with the source program (because it keeps track of
line numbers).
2
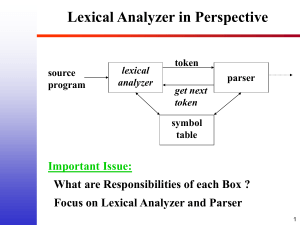
Interaction of the Lexical
Analyzer with the Parser
Source
Program
Lexical
Analyzer
Token,
tokenval
Parser
Get next
token
error
error
Symbol Table
3
The Reason Why Lexical
Analysis is a Separate Phase
• Simplifies the design of the compiler
– LL(1) or LR(1) parsing with 1 token lookahead would
not be possible (multiple characters/tokens to match)
• Provides efficient implementation
– Systematic techniques to implement lexical analyzers
by hand or automatically from specifications
– Stream buffering methods to scan input
• Improves portability
– Non-standard symbols and alternate character
encodings can be normalized (e.g. trigraphs)
4
Attributes of Tokens
y := 31 + 28*x
Lexical analyzer
<id, “y”> <assign, > <num, 31> <+, > <num, 28> <*, > <id, “x”>
token
tokenval
(token attribute)
Parser
5
Tokens, Patterns, and Lexemes
• A token is a classification of lexical units
– For example: id and num
• Lexemes are the specific character strings that
make up a token
– For example: abc and 123
• Patterns are rules describing the set of lexemes
belonging to a token
– For example: “letter followed by letters and digits” and
“non-empty sequence of digits”
6
Tokens, Patterns, and Lexemes
• A lexeme is a sequence of characters from
the source program that is matched by a
pattern for a token.
lexeme
Pattern
Token
7
Tokens, Patterns, and Lexemes
Token
Sample Lexemes
Informal Description of Pattern
const
const
const
if
if
if
relation
<, <=, =, < >, >, >=
< or <= or = or < > or >= or >
id
pi, count, D2
letter followed by letters and digits
num
3.1416, 0, 6.02E23
any numeric constant
literal
“core dumped”
any characters between “ and “ except
“
Classifies
Pattern
Actual values are critical. Info is :
1. Stored in symbol table
2. Returned to parser
3.2 Input Buffering
• Examining ways of speeding reading the
source program
– In one buffer technique, the last lexeme under process will be overwritten when we reload the buffer.
– Two-buffer scheme handling large look ahead safely
3.2.1 Buffer Pairs
• Two buffers of the same size, say 4096, are alternately
reloaded.
• Two pointers to the input are maintained:
– Pointer lexeme_Begin marks the beginning of the
current lexeme.
– Pointer forward scans ahead until a pattern match is
found.
If forward at end of first half then begin
reload second half;
forward:=forward + 1;
End
Else
if forward at end of second half then begin
reload first half;
move forward to beginning of first half
End
Else forward:=forward + 1;
3.2.2 Sentinels
E
= M * eof C * * 2 eof
eof
forward:=forward+1;
If forward ^ = EOF then begin
If forward at end of first half then begin
reload second half;
forward:=forward + 1;
End
Else if forward at end of second half then begin
reload first half;
move forward to beginning of first half
End
Else terminate lexical analysis;
Specification of Patterns for
Tokens: Definitions
• An alphabet is a finite set of symbols
(characters)
• A string s is a finite sequence of symbols
from
– s denotes the length of string s
– denotes the empty string, thus = 0
• A language is a specific set of strings over
some fixed alphabet
14
Specification of Patterns for
Tokens: String Operations
• The concatenation of two strings x and y is
denoted by xy
• The exponentation of a string s is defined
by
s0 = (Empty string: a string of length zero)
si = si-1s for i > 0
note that s
= s = s
15
Specification of Patterns for
Tokens: Language Operations
• Union
L M = {s s L or s M}
• Concatenation
LM = {xy x L and y M}
• Exponentiation
L0 = {}; Li = Li-1L
• Kleene closure
L* = i=0,…, Li
• Positive closure
L+ = i=1,…, Li
16
Language Operations Examples
L = {A, B, C, D }
D = {1, 2, 3}
L D = {A, B, C, D, 1, 2, 3 }
LD = {A1, A2, A3, B1, B2, B3, C1, C2, C3, D1, D2, D3 }
L2 = { AA, AB, AC, AD, BA, BB, BC, BD, CA, … DD}
L4 = L2 L2 = ??
L* = { All possible strings of L plus }
L+ = L* -
L (L D ) = ??
L (L D )* = ??
Specification of Patterns for
Tokens: Regular Expressions
• Basis symbols:
– is a regular expression denoting language {}
– a is a regular expression denoting {a}
• If r and s are regular expressions denoting
languages L(r) and M(s) respectively, then
–
–
–
–
rs is a regular expression denoting L(r) M(s)
rs is a regular expression denoting L(r)M(s)
r* is a regular expression denoting L(r)*
(r) is a regular expression denoting L(r)
• A language defined by a regular expression is
called a regular set
18
• Examples:
– let
{a, b}
a|b
(a | b) (a | b)
a*
(a | b)*
a | a*b
– We assume that ‘*’ has the highest precedence and is
left associative. Concatenation has second highest
precedence and is left associative and ‘|’ has the lowest
precedence and is left associative
• (a) | ((b)*(c ) ) = a | b*c
Algebraic Properties of
Regular Expressions
AXIOM
r|s=s|r
r | (s | t) = (r | s) | t
(r s) t = r (s t)
r(s|t)=rs|rt
(s|t)r=sr|tr
r = r
r = r
r* = ( r | )*
r** = r*
DESCRIPTION
| is commutative
| is associative
concatenation is associative
concatenation distributes over |
Is the identity element for concatenation
relation between * and
* is idempotent
Finite Automaton
• Given an input string, we need a “machine”
that has a regular expression hard-coded in
it and can tell whether the input string
matches the pattern described by the regular
expression or not.
• A machine that determines whether a given
string belongs to a language is called a
finite automaton.
Deterministic Finite Automaton
• Definition: Deterministic Finite Automaton
– a five-tuple (, S, , s0, F) where
•
•
•
•
•
is the alphabet
S is the set of states
is the transition function (SS)
s0 is the starting state
F is the set of final states (F S)
• Notation:
– Use a transition diagram to describe a DFA
• states are nodes, transitions are directed, labeled edges, some states are
marked as final, one state is marked as starting
• If the automaton stops at a final state on end of input, then the input
string belongs to the language.
① a
={a}
L= {a}
S = {1,2}
(1,a)=2
S0 = 1
F = {2}
② a|b
={a,b}
L = {a,b}
S = {1,2}
(1,a)=2, (1,b)=2
S0 = 1
F = {2}
③ a(a|b)
={a,b}
L = {aa,ab}
S = {1,2,3}
(1,a)=2, (2,a)=3, (2,b)=3
S0 = 1
F = {3}
④ a*
= {a}
L = {,a,aa,aaa,aaaa,…}
S = {1}
(1, )=1, (1,a)=1
S0 = 1
F = {1}
⑤a⁺
={a}
L = {a,aa,aaa,aaaa,…}
S = {1,2}
(1,a)=2, (2,a)=2
S0 = 1
F = {2}
Note: a⁺=aa*
⑥ (a|b)(a|b)b
= {a,b}
L = {aab,abb,bab,bbb}
S = {1,2,3,4}
(1,a)=2, (1,b)=2, (2,a)=3, (2,b)=3,
(3,b)=4
S0 = 1
F = {4}
⑦ (a|b)*
={a,b}
L={,a,b,aa,bb,ba,ab,aaa,…,bbb,…,abab,…,b
aba,bbba,…,…}
S = {1}
(1,a)=1, (1,b)=1
S0 = 1
F = {1}
⑧ (a|b)⁺
={a,b}
L = {a,aa,aaa,…,b,bb,bbb,…}
S = {1,2}
(1,a)=2, (1,b)=2, (2,a)=2, (2,b)=2
S0 = 1
F = {2}
Note: (a|b)⁺=(a|b)(a|b)*
⑨a⁺|b⁺
={a,b}
L = {a,aa,aaa,…,b,bb,bbb,…}
S = {1,2,3}
(1,a)=2, (2,a)=2, (1,b)=3, (3,b)=3
S0 = 1
F = {2,3}
⑩a(a|b)*
={a,b}
L={a,aa,ab,…,aba,…,abb,…,baa,abbb,…,bab
aba,…}
S = {1,2}
(1,a)=2, (2,a)=2, (2,b)=2
S0 = 1
F = {2}
⑪a(b|a)b⁺
={a,b}
L = {aab,abb,aabb,…,abbb,abbbb,…}
S ={1,2,3,4}
(1,a)=2, (2,a)=3, (2,b)=3, (3,b)=4,
(4,b)=4
S0 = 1
F = {4}
⑫ ab*a(a⁺|b⁺)
={a,b}
L = {aaa,aab,abaa,abbaa,…,abbab,abbabbb,…}
S = {1,2,3,4,5}
(1,a)=2, (2,b)=2, (2,a)=3, (3,a)=4, (4,a)=4,
(3,b)=5, (5,b)=5
S0 = 1
F = {4,5}
Specification of Patterns for
Tokens: Regular Definitions
• Regular definitions introduce a naming
convention:
d 1 r1
d 2 r2
…
d n rn
where each ri is a regular expression over
{d1, d2, …, di-1 }
• Any dj in ri can be textually substituted in ri to
obtain an equivalent set of definitions
35
Specification of Patterns for
Tokens: Regular Definitions
• Example:
letter AB…Zab…z
digit 01…9
id letter ( letterdigit )*
• Regular definitions are not recursive:
digits digit digitsdigit
wrong!
36
Specification of Patterns for
Tokens: Notational Shorthand
• The following shorthands are often used:
r+ = rr*
r? = r
[a-z] = abc…z
• Examples:
digit [0-9]
num digit+ (. digit+)? ( E (+-)? digit+ )?
37
Regular Definitions and
Grammars
Grammar
stmt if expr then stmt
if expr then stmt else stmt
expr term relop term
term
Regular definitions
term id
if if
num
then then
else else
relop < <= <> > >= =
id letter ( letter | digit )*
38 + )?
num digit+ (. digit+)? ( E (+-)? digit
Constructing Transition Diagrams for Tokens
• Transition Diagrams (TD) are used to represent the tokens
– these are automatons!
• As characters are read, the relevant TDs are used to attempt
to match lexeme to a pattern
• Each TD has:
• States : Represented by Circles
• Actions : Represented by Arrows between states
• Start State : Beginning of a pattern (Arrowhead)
• Final State(s) : End of pattern (Concentric Circles)
• Each TD is Deterministic - No need to choose between 2
different actions !
Example : All RELOPs
start
0
<
1
=
2
return(relop, LE)
>
3
return(relop, NE)
other
=
4
5
*
return(relop, LT)
return(relop, EQ)
>
6
=
7
other
8
return(relop, GE)
*
return(relop, GT)
Example TDs : id and delim
Keyword
or id :
letter or digit
start
9
letter
10
other
*
11
return(install_id(),
gettoken())
delim :
delim
start
28
delim
29
other
30
*
Combine TD for KW and IDs
• Install_id(): decides for the attribute
– It will check the accepted lexeme in the list of keywords; if it is
matched, zero is returned.
– Otherwise checks the lexeme in symbol table, if it is found, the
address is returned.
– If the lexeme not found in symbol table, install_id() first installs
the ID in the symbol table and return the address of the newly
created entry.
• Gettoken(): decides for the token
– If zero returned by install_id(), the same word(or its numeric form)
is returned as token
– Otherwise token “ID” is returned.
42
Example TDs : Unsigned #s
digit
start
12
digit
13
digit
.
14
digit
15
digit
E
16
+|-
E
20
digit
*
21
digit
other
18
digit
digit
start
17
digit
.
22
digit
23
other
24
*
digit
start
25
digit
26
other
27
*
Questions: Is ordering important for unsigned #s ?
Why are there no TDs for then, else, if ?
19
*
Keywords Recognition
All Keywords / Reserved words are matched as ids
• After the match, the symbol table or a special keyword table is
consulted
• Keyword table contains string versions of all keywords and
associated token values
if
0
then
0
begin
0
...
...
• If a match is not found, then it is assumed that an id has been
discovered
Transition Diagrams & Lexical
Analyzers
state = 0;
token nexttoken()
{
while(1) {
switch (state) {
case 0:
c = nextchar();
/* c is lookahead character */
if (c== blank || c==tab || c== newline) {
state = 0;
lexeme_beginning++;
/* advance beginning of lexeme */
}
else if (c == ‘<‘) state = 1;
else if (c == ‘=‘) state = 5;
else if (c == ‘>’) state = 6;
else state = fail();
break;
… /* cases 1-8 here */
case 9:
c = nextchar();
if (isletter(c)) state = 10;
else state = fail();
break;
case 10; c = nextchar();
if (isletter(c)) state = 10;
else if (isdigit(c)) state = 10;
else state = 11;
break;
case 11; retract(1); install_id();
return ( gettoken() );
… /* cases 12-24 here */
case 25; c = nextchar();
if (isdigit(c)) state = 26; Case numbers correspond
to transition diagram states
else state = fail();
break;
!
case 26; c = nextchar();
if (isdigit(c)) state = 26;
else state = 27;
break;
case 27; retract(1); install_num();
return ( NUM );
}
}
}
When Failures Occur:
int state = 0,
start = 0;
Int lexical_value;
/* to “return” second component of token */
Init fail()
{
forward = token_beginning;
switch (start) {
case 0:
start = 9; break;
case 9:
start = 12; break;
case 12: start = 20; break;
case 20: start = 25; break;
case 25: recover(); break;
default:
/* compiler error */
}
return start;
}
Using a Lex Generator
Lex source prog
lex.l
lex.yy.c
Input stream
tokens
Lex
Compiler
C
compiler
a.out
lex.yy.c
a.out
sequence of input.c