Document
advertisement

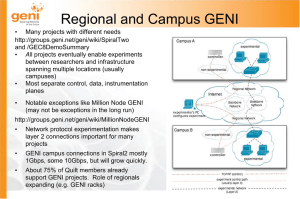
Rick McGeer Chief Scientist, US IGNITE December 9, 2013 Distributed Clouds and Software Defined Networking Complementary Technologies for the Next-Generation Internet Or, A Post-Hoc Justification for the Last 10 Years of My Life 3 4 The Future is Distributed Clouds integrated with Software-DefinedNetworks! 5 SDN is a set of abstractions over the networking control plane Proxies are an essential element of the Internet Architecture Shouldn’t there be an abstraction architecture for proxies? 6 Network Challenges • Original Concept of the Network: dumb pipe between smart endpoints – Content-agnostic routing – Rates controlled by endpoints – Content- and user-agnostic forwarding • Clean separation of concerns – Routing and forwarding by network elements – Rate control, admission control, security at endpoints Clean separation of concerns doesn’t work very well • Need application-aware stateful forwarding (e.g., multicast) • Need QoS guarantees and network-aware endpoints – For high-QoS applications – For lousy links • Need in-network security and admission control – Endpoint security easily overwhelmed… Some Examples • • • • • • • • • Load-balanced end-system multicast Adaptive/DPI-based Intrusion Detection In-network transcoding to multiple devices Web and file content distribution networks Link-sensitive store-and-forward connection-splitting TCP proxies Email proxies (e.g., MailShadow) In-network compression engines (Riverbed) Adaptive firewall In-situ computation for data reduction from high-bandwidth sensors (e.g., high-resolution cameras) Common Feature • All of these examples require some combination of in-network and endpoint services – Information from the network – Diversion to a proxy – Line-rate packet filtering • All require endpoint processing – Stateful processing – Connection-splitting – Filesystem access • Three central use cases – Optimization of network resources, especially bandwidth – Proximity to user for real-time response – In-situ sensor processing Historic Solution: Middleboxes • Dedicated network appliances to perform specific function • Gets the job done, but… – Appliances proliferate (one or more per task) – Opaque – Interact unpredictably… • Don’t do everything • – E.g., generalized in-situ processing engine for data reduction APST, 2005: “The ability to support…multiple coexisting overlays [of proxies]…becomes the crucial universal piece of the [network] architecture.” OpenFlow and SDN • L2/L3 Technology to permit software-defined control of network forwarding and routing • What it’s not: – – – – – On-the-fly software decisions about routing and forwarding In-network connection-splitting store-and-forward In-network on-the-fly admission control In-network content distribution Magic…. • What it is: – Table-driven routing and forwarding decisions (including drop and multicast) – Callback protocol from a switch to a controller when entry not in table (“what do I do now?”) – Protocol which permits the controller to update the switch In-Network Processing • L4/L7 Services provided by nodes in the network – – – – – TCP/Application layer proxies Stateful/DPI based intrusion detection Application-layer admission control Application-layer load-balancing …. • Key features – Stateful processing – Transport/Application layer information required Middleboxes and the Network • Classic View: Proxies and Middleboxes are a necessary evil that breaks the “end-to-end principle” (Network should be a dumb pipe between endpoints) • Modern View (Peterson): “Proxies play a fundamental role in the Internet architecture: They bridge discontinuities between different regions of the Internet. To be effective, however, proxies need to coordinate and communicate with each other.” • Generalized Modern View (this talk): Proxies and Middleboxes are special cases of a general need: endpoint processing in the network. We need to merge the Cloud and the Network. Going From Today to Tomorrow • Today: Middleboxes • Tomorrow: In-network general-purpose processors fronted by OpenFlow switches • Advantages of Middleboxes – Specialized processing at line rate • Disadvantages of middleboxes – – – – – Nonexistent programming environment Opaque configuration Vendor-specific updates Only common functions get done Interact unpredictably… Anatomy of a Middlebox Incoming Packets ASIC L2/L3/ DPI Packet Filter Embedded Linux Processing Engine Packet Output Generalized Architecture Incoming Packets L2/L3 Packet Filter Software on a Processing Engine Outgoing Packets The Future Incoming Packets OpenFlow Switch Controllers + Small Cloud Packet Output Advantages of the Generalizing and Factoring the Middlebox • Transparent • Open programming environment: Linux + OpenFlow • Much broader range of features and functions • Interactions between middleboxes mediated by OpenFlow rules – Verifiable – Predictable • Updates are software uploads OpenFlow + In Network Processing + Line-rate processing + Largely implementable on COTS switches + Packet handling on a per-flow basis + Rapid rule update + Unified view of the network + L2-L7 services But I Need Proxies Everywhere… • Proxies are needed where I need endpoint processing – In-situ data reduction – Next to users – Where I need filtering • Can’t always predict these in advance for every service! • So I need a small cloud everywhere, so I can instantiate a middlebox anywhere • Solution = Distributed “EC2” + OpenFlow network • “Slice”: Virtual Network of Virtual Machines • OpenFlow creates Virtual Network • “EC2” lets me instantiate VM’s everywhere Shenker’s SDN Architecture Virtual Network Network "Operating System" OpenFlow Physical Network Specification of a virtual network, with explicit forwarding instructions Translation onto OpenFlow rules on physical network Effectuation on physical network 26 Perfect for L1-L3 Application Virtual Network Transport IP MAC PHY Network "Operating System" OpenFlow Physical Network 27 Key Function we want: Add Processing Anywhere in the Virtual Network Application Virtual Distributed System Transport IP Distributed System "Operating System" MAC OpenFlow + Cloud Managers PHY Physical Distributed Cloud 28 Going from Virtual Network to Virtual Distributed System Virtual Distributed System Distributed System "Operating System" OpenFlow + Cloud Managers Physical Distributed Cloud Specification of a virtual distributed cloud, with explicit forwarding instructions BETWEEN specified VMs Translation onto OpenFlow rules on physical network AND instantiation on physical machines at appropriate sites Effectuation on physical network AND physical clouds 29 Key Points • Federated Clouds can be somewhat heterogeneous – Must support common API – Can have some variants (switch variants still present a common interface through OpenFlow) • DSOS is simply a mixture of three known components: – Network Operating System – Cloud Managers (e.g., ProtoGENI, Eucalytpus, OpenStack) – Tools to interface with Network OS and Cloud Managers (nascent tools under development) 30 Implications for OpenFlow/SDN • Southbound API (i.e., OpenFlow): minimal and anticipated in 1.5 – “Support for L4/L7 services”, aka, seamless redirection • Northbound API – – – – Joint allocation of virtual machines and networks Location-aware allocation of virtual machines WAN-aware allocation of networks QoS controls between sites • Build on/extend successful architectures – “Neutron for the WAN” 31 Implications for Cloud Architectures • Key problem we’ve rarely considered: how do we easily instantiate and stitch together services at multiple sites/multiple providers? • Multiple sites is easy, multiple providers is not • Need easy way to instantiate from multiple providers – Common AUP/Conventions? Probably – Common form of identity/multiple IDs? Multiple or bottom-up (e.g. Facebook) – Common API? Absolutely • Need to understand what’s important and what isn’t – E.g. very few web services charge for bandwidth 32 Initial Attempts • • • • • Ignite Technical Architecture/GENI Racks GENI Mesoscale SAVI JGN-X … 33 With Credit To… 34 GENI Mesoscale • Nationwide network of small local clouds • Each cloud – 80-150 worker cores – Several TB of disk – OpenFlow-native local switching • Interconnected over OpenFlow-based L2 Network • Local “Aggregate Manager” (aka controller) • Two main designs with common API – InstaGENI (ProtoGENI-based) – ExoGENI (ORCA/OpenStack-based) • Global Allocation through federate aggregate managers • User allocation of networks and slices through tools (GENI portal, Flack) 35 GENI And The Distributed Cloud Stack • Physical Resources – GENI Racks, Emulab, GENI backbone • Cloud OS – ProtoGENI, ExoGENI… • Orchestration Layer – GENI Portal, Flack… 36 Instageni rack topology of 222 37 ©2010 HP Created on xx/xx/xxxx U.S. Ignite City Technical Architecture Existing head-end Existing ISP connects Most equipment not shown Layer 3 GENI control plane Layer 2 Ignite Connect (1 GE or 10GE) Layer 2 connect to subscribers OpenFlow switch(es) Flowvisor Remote management Instrumentation Aggregate manager Measurement Programmable servers Storage Video switch (opt) New GENI / Ignite rack pair Home GENI Mesoscale Deployment 39 Distributed Clouds and NSFNet: Back to the Future • • • • GENI today is NSFNet circa 1985 GENI and the SFA: Set of standards (e.g., TCP/IP) Mesoscale: Equivalent to NSF Backbone GENIRacks: Hardware/software instantiation of standards that sites can deploy instantly – Equivalent to VAX 11 running Berkeley Unix – InstaGENI cluster running ProtoGENI and OpenFlow • Other instantiations which are interoperable – VNode (Aki Nakao, University of Tokyo and NICT) – Tomato (Dennis Schwerdel, TU-Kaiserslautern) JGN-X (Japan) 41 SAVI (Canada) 42 Ofelia (EU) 43 “Testbeds” vs “Clouds” • JGN-X, GENI, SAVI, Ofelia, GLab, OneLab are all described as “Testbeds” – But they are really Clouds – Tests require realistic services • History of testbeds: – Academic ResearchAcademic/Research servicesCommercial services – Expect similar evolution here (but commercial will come faster) 44 Programming Environment for Distributed Clouds • Problem: Allocating and configuring distributed clouds is a pain – Allocate network of VM’s – Build VM’s and deploy images – Deploy and run software • But most slices are mostly the same • Automate commonly-used actions and pre-allocate typical slices • 5-minute rule: Build, deploy, and execute “Hello, World” in five minutes • Decide what to build: start with sample application 45 TransGeo: A Model TransCloud Application • Scalable, Ubiquitous Geographic Information System • Open and Public – Anyone can contribute layers – Anyone can host computation • Why GIS? – – – – – – 46 Large and active community Characterized by large data sets (mostly satellite images) Much open-source easily deployable software, standard data formats Computation naturally partitions and is loosely-coupled Collaborations across geographic regions and continents Very pretty… TransGeo Architecture 47 TransGeo Sites (May 2013) 48 49 50 Opening up TransGEO: The GENI Experiment Engine • Key Idea: Genericize and make available the infrastructure behind the TransGEO demo – Open to every GENI, FIRE, JGN-X, Ofelia, SAVI…experimenter who wants to use it • TransGEO is a trivial application on a generic infrastructure – Perhaps 1000 lines of Python code on top of • • • • • • 51 Key-Value Store Layer 2 network Sandboxed Python programming environment Messaging Service Deployment Service GIS Libraries GENI Experiment Engine • • • • • • • • • 52 Permanent, Long-Running, Distributed File System Permanent, Long-Running, GENI-wide Message Service Permanent, Long-Running, Distributed Python Environment Permanent, world-wide Layer-2 VLANs on high-performance networks All offered in slices All shared by many experimenters Model: Google App Engine Advantage for GENI: Efficient use of resources Advantage for Experimenters: Up and running in no time GENI Experiment Engine Architecture 53 Staged Rollout • Permanent Layer-2 Network Spring 2014 • Shared File System based on (Swift) Spring 2014 • Python environment Summer 2014 54 Thanks and Credits Joe Mambretti, Fei Yeh, Jim Chen Northwestern/ iCAIR Andy Bavier, Marco Yuen, Larry Peterson, Jude Nelson, Tony Mack PlanetWorks/Princeton Chris Benninger, Chris Matthews, Chris University of Victoria Pearson, Andi Bergen, Paul Demchuk, Yanyan Zhuang, Ron Desmarais, Stephen Tredger, Yvonne Coady, Hausi Muller Heidi Dempsey, Marshall Brinn, Vic Thomas, Niky Riga, Mark Berman, Chip Elliott BBN/GPO Rob Ricci, Leigh Stoller, Gary Wong University of Utah Glenn Ricart, William Wallace, Joe Konstan US Ignite Paul Muller, Dennis Schwerdel TU-Kaiserslautern Amin Vahdat, Alvin AuYoung, Alex Snoeren, Tom DeFanti UCSD 55 Thanks and Credits Nick Bastin Barnstormer Softworks Shannon Champion Matrix Integration Jessica Blaine, Jack Brassil, Kevin Lai, Narayan Krishnan, Dejan Milojicic, Norm Jouppi, Patrick Scaglia, Nicki Watts, Michaela Mezo, Bill Burns, Larry Singer, Rob Courtney, Randy Anderson, Sujata Banerjee, Charles Clark HP Aki Nakao University of Tokyo 56 Conclusions • Distributed Clouds are nothing new… – Akamai was basically the first Distributed Cloud – Single Application, now generalizing • But this is OK… – Web simply wrapped existing services • • Now in vogue with telcos (“Network Function Virtualization”) What’s new/different in GENI/JGN-X/SAVI/Ofelia…. – Support from programmable networks – “Last frontier” for software in systems • Open Problems – Siting VMs! – Complex network/compute/storage optimization problems • Needs – “http”-like standardization of APIs at IaaS, PaaS layers 57 Links http://citeseerx.ist.psu.edu/viewdoc/download?d oi=10.1.1.20.123&rep=rep1&type=pdf http://pages.cs.wisc.edu/~akella/CS838/F09/838Papers/APST05.pdf http://www.youtube.com/watch?v=eXsCQdshMr4