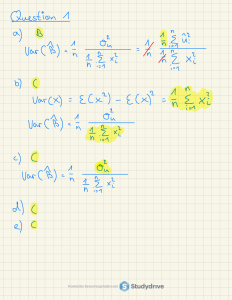Guía de Problemas: Análisis de Datos e Inferencia Causal
advertisement

Guía de Problemas de Años Anteriores
IN41432-2 Análisis de Datos e Inferencia Causal
(Esta guía de problemas no refleja el contenido específico que se incluye en cada control, ni su dificultad o
extensión. Son una selección de preguntas que han sido utilizadas en controles de años anteriores para reflejar
distintas preguntas posibles, y para familiarizarse con la mecánica de un control – VoF, enunciados,
desarrollo, etc.)
Este control evalúa su capacidad de aplicar los contendidos aprendidos en el curso. Por ello, remita sus
respuestas sólo a conceptos relacionados a éste.
Si tiene dudas levante su mano, y alguien atenderá su pregunta, entendiendo que sólo preguntas aclaratorias
serán contestadas. Por favor limítese al espacio asignado para cada pregunta; y la hoja (por ambos lados) para la
pregunta de desarrollo.
No olvide poner su nombre en cada hoja.
Nota final: Puntaje máximo XX puntos. La nota 4.0 se alcanza con YY puntos. (cada pregunta tendrá asignado
puntaje)
Parte I. Verdadero o Falso. No se requiere justificar respuestas. El puntaje total de esta parte se calculará
mediante la siguiente fórmula: 1,0 * (# preguntas correctas) - 0,3 * (# preguntas incorrectas). Pudiendo quedar
un puntaje negativo que se traspasa al resto del control.
1.____ En el contexto del Modelo de Regresión Lineal Clásico (CRLM, por sus siglas en inglés), el sesgo por
omisión de variables no desaparece a pesar de aumentar el tamaño muestral.
Verdadero. A pesar de que se aumente el tamaño muestral n, se sigue dejando fuera del modelo una
variable relevante, lo que genera un sesgo, es decir, que los parámetros estimados resultan inconsistentes
además de sesgados cuando el tamaño muestral no es lo suficientemente grande (insesgado es cuando se
cumple que 𝐸(β) = β).
2.____ Un coeficiente 𝑅2 muy pequeño (ej: 0,01) indica que hay variables no observables correlacionados con
las variables independientes del modelo.
Falso.
El 𝑅2 se interpreta como la proporción de la variación muestral de la variable dependiente que es explicada
por los regresores en la estimación por MCO. Dicho esto, 𝑅 2 no es determinante para concluir que una
variable regresora está correlacionada con un factor no observable contenido en 𝑢𝑖 .
3.____ Suponga el que se quiere estimar el modelo 𝑦𝑖 = 𝛽0 + 𝛽1 𝑋1𝑖 + 𝛽2 𝑋2𝑖 + 𝑢𝑖 , sin embargo, usted estima
𝑦𝑖 = 𝛽0 + 𝛽1 𝑋1𝑖 + 𝑢𝑖 . Si se espera que la correlación entre 𝑋1 y 𝑋2 sea positiva, y que 𝛽2 sea negativo,
entonces el sesgo de 𝛽1 es negativo.
Verdadero.
Tenemos que:
Estimado: 𝑦𝑖 = 𝛽0 + 𝛽1 𝑋1𝑖 + 𝑢𝑖
Real: 𝑦𝑖 = 𝛽0 + 𝛽1 𝑋1𝑖 + 𝛽2 𝑋2𝑖 + 𝑢𝑖
̂1 :
Para entender el sesgo de una variable omitida evaluamos la expresión del estimador 𝛽
Sabemos que:
̂1 = Cov(𝑋1 ,𝑦𝑖 ) = 1 ∗ Cov(𝑋1 , 𝛽0 + 𝛽1 𝑋1 + 𝛽2 𝑋2 + 𝑢𝑖 )
𝛽
Var(𝑋1 )
1
Var(𝑋1 )
̂1 =
𝛽
∗ [𝐶𝑜𝑣(𝑋1 , 𝛽0 ) + 𝐶𝑜𝑣(𝑋1 , 𝛽1 𝑋1 ) + 𝐶𝑜𝑣(𝑋2 , 𝛽2 𝑋2 ) + 𝐶𝑜𝑣(𝑋1 , 𝑢𝑖 )]
Var(𝑋 )
1
̂1 = 1 ∗ [0 + 𝐶𝑜𝑣(𝑋1 , 𝛽1 𝑋1 ) + 𝐶𝑜𝑣(𝑋2 , 𝛽2 𝑋2 ) + 0)]
𝛽
Var(𝑋 )
1
̂1 = 1 ∗ [𝛽1 𝐶𝑜𝑣(𝑋1 , 𝑋1 ) + 𝛽2 𝐶𝑜𝑣(𝑋1 , 𝑋2 )]
𝛽
Var(𝑋 )
1
̂1 = 1 ∗ [𝛽1 𝑉𝑎𝑟(𝑋1 ) + 𝛽2 𝐶𝑜𝑣(𝑋1 , 𝑋2 )]
𝛽
Var(𝑋 )
1
𝛽 𝑉𝑎𝑟(𝑋1 ) 𝛽2 𝐶𝑜𝑣(𝑋1 , 𝑋2 )
̂1 = 1
𝛽
+
Var(𝑋1 )
Var(𝑋1 )
𝐶𝑜𝑣(𝑋1 , 𝑋2 )
̂1 = 𝛽1 + 𝛽2 ∗
𝛽
Var(𝑋1 )
̂1 = 𝛽1 + 𝑠𝑒𝑠𝑔𝑜
𝛽
=> 𝑠𝑒𝑠𝑔𝑜 = 𝛽2 ∗
𝐶𝑜𝑣(𝑋1 , 𝑋2 )
Var(𝑋1 )
De la expresión anterior si hacemos un análisis de signos se tiene que el sesgo de 𝛽1 es negativo.
-𝛽2 es negativo.
- 𝐶𝑜𝑣(𝑋1 , 𝑋2 ) es positivo, pues 𝐶𝑜𝑟𝑟(𝑋1 , 𝑋2 ) es positiva y se tiene que 𝐶𝑜𝑣(𝑋1 , 𝑋2 ) = 𝐶𝑜𝑟𝑟(𝑋1 , 𝑋2 ) ∗
𝑆𝑋1 ∗ 𝑆𝑋2 como los errores son siempre positivos y no estamos cambio en ellos, hacemos el análisis
considerando que 𝐶𝑜𝑣 ≃ 𝐶𝑜𝑟𝑟.
2
-𝑉𝑎𝑟(𝑋1 ) es siempre positivo pues 𝑉𝑎𝑟(𝑋1 ) = 𝜎𝑋1
Notar que el sesgo será cero si β = 0 o no hay correlación entre las variables independientes.
4.____ El Modelo de Probabilidad Lineal (Linear Probability Model o LPM) usa Mínimos Cuadrados
Ordinarios (o OLS, por sus siglas en inglés) para determinar la probabilidad de un resultado (outcome).
Verdadero.
Es el mismo procedimiento, sólo cambia la interpretación de la variable estimada 𝑦𝑖 .
5.____ La asignación aleatoria resuelve el problema de sesgo de selección sólo si el tamaño de la muestra es
suficiente grande (se cumple la ley de los grandes números).
Verdadero.
6.____ Los experimentos de campo aumentan la validez externa comparado a estudios observacionales.
Falso.
Porque los estudios observacionales contemplan a la población en su comportamiento real, sin interferencia.
Entonces se puede extrapolar más que aplicando un tratamiento.
7.____ El ejemplo del Dr John Snow y la epidemia de cólera en Londres puede ser considerado un experimento
natural pues en ese tiempo no existía un comité de ética para aprobar el experimento.
Falso.
Se considera un experimento natural dado que los grupos de tratamiento y control son asignados de manera
natural y sin intervención de terceros, no porque no estuvieran las condiciones para realizar un experimento
de campo.
Para las siguientes tres preguntas, respecto a la asignación aleatoria (random assignment):
𝑌 (0) 𝑠𝑖 𝐷𝑖 = 0
𝑌𝑖 = { 𝑖
𝑌𝑖 (1) 𝑠𝑖 𝐷𝑖 = 1
8.____ 𝑌𝑖 son las asignaciones aleatorias correspondientes a cada individuo 𝑖.
Falso.
Son los resultados potenciales de los grupos de control y tratamiento frente a recibir o no el tratamiento.
9.____ Cuando hay asignación aleatoria se cumple que: 𝔼[𝑌𝑖 (1)|𝐷𝑖 = 0] = 𝔼[𝑌𝑖 (1)|𝐷𝑖 = 1].
Verdadero.
10.____
Cuando hay asignación aleatoria se cumple que: 𝔼[𝑌𝑖 (0)|𝐷𝑖 = 0] = 𝔼[𝑌𝑖 (0)|𝐷𝑖 = 1].
Verdadero.
Para las próximas dos preguntas, suponga que datos de una muestra de la edad de estudiantes en un evento,
obteniéndose la siguiente gráfica:
11.____
Al menos el 75% de los estudiantes tiene 10 años o más.
Verdadero.
12.____
El promedio de edad de los estudiantes es exactamente 13 años.
Falso.
Esa es la mediana.
Parte II. Preguntas conceptuales y de desarrollo. Conteste las siguientes preguntas. Por favor limítese al
espacio asignado para cada pregunta.
1. Un estudio reciente examinó brechas salariales de género a partir de los datos de Uber, empresa que provee
una red de transporte a través de una app, coordinando “conductores” con “pasajeros”. Se sabe que Uber
paga a los conductores de acuerdo a las carreras que realizan y que su algoritmo de asignación de carreras
no toma en consideración la variable de género para asignar conductores. Dada la novedad del estudio,
algunos diarios presentaron los resultados con los siguientes gráficos: el salario por hora promedio
comparando hombres y mujeres (izquierda), y las carreras completadas de conductores Uber sobre las
semanas de experiencia trabajando en la app (derecha).
a) Interprete los gráficos con respecto a si existe discriminación por género en Uber, discuta brevemente
los principios de Tufte para el gráfico de la derecha, y calcule el lie factor (factor de mentira) del gráfico
izquierdo (haga los supuestos que estime necesarios).
De acuerdo al gráfico izquierdo, existe una diferencia salarial entre hombres y mujeres en Uber, lo que
podría llevar a pensar en discriminación de algún tipo. Si el algoritmo de Uber es ciego al género,
significa que hay otras componentes (diferentes a la discriminación) que están influyendo en los
salarios. Ejemplo de esto es el gráfico de la derecha, donde se muestra que los hombres en promedio, al
mismo tiempo de trabajo, han acumulado más experiencia, lo que está directamente vinculado a
las ganancias (sesgo de selección). Una buena visualización de datos debe “Provide the greatest
number of ideas in the shortest time with the least ink in the smallest space” (claridad). A la derecha, si
bien la información se transmite fácilmente y no hay distorsión (integridad), no hay eficiencia en el uso
de la “tinta”, pues se puede comunicar lo mismo sin la malla de cuadrícula.
En cuanto al Lie Factor del gráfico izquierdo, se calcula como:
2−1
𝑡𝑎𝑚𝑎ñ𝑜 𝑒𝑓𝑒𝑐𝑡𝑜 𝑔𝑟á𝑓𝑖𝑐𝑜
1
𝐿𝐹 =
=
= 16.2
21.28
−
20.04
𝑡𝑎𝑚𝑎ñ𝑜 𝑒𝑓𝑒𝑐𝑡𝑜 𝑟𝑒𝑎𝑙
20.04
Como el Lie Factor es muy elevado (un buen nivel sería entre 0,95 y 1,05), por lo que el gráfico de la
izquierda no tiene integridad pues presenta mucha distorsión.
La Tabla 1 muestra los resultados más emblemáticos del artículo. Al respecto:
1.
Cook, C., Diamond, R., Hall, J., List, J. A., & Oyer, P. (2017). The Gender Earnings Gap in the Gig Economy: Evidence from ov er a Million
Uber Drivers. Growth, 2. Algunos resultados se han modificado por simplicidad y por motivos pedagógicos para esta evaluación.
b) Usando el modelo (6), determine cuál es el efecto de aumentar la velocidad en un 10% en el salario.
Para el mismo modelo, interprete el efecto del número de carreras en el salario. ¿Cómo cambia su
respuesta, si es que lo hace, si el coeficiente asociado al número de carreras fuera 10 veces más grande?
• El efecto de aumentar la velocidad en un 10% es de un aumento de (10*0,4544 =) 4,544% en el salario
por hora de los conductores manteniendo constante las demás variables del modelo. (Log-Log)
• Por cada carrera adicional hay un aumento del 5,5% (100*0,055) del salario/hora manteniendo constante
las demás variables del modelo. (Log-Nivel)
• Si el coeficiente de NCarreras fuese de 0,055*(10)=0,55 hay un aumento del 55%(100*0,55) del
salario/hora manteniéndose constante las demás variables del modelo. (Log-Nivel)
c) ¿Es importante agregar las variables de cancelación de usuarios/conductores? Argumente.
Para interpretar la inclusión de las variables de cancelación se deben comparar las columnas 2 y 3,
donde se puede ver que el coeficiente de la variable de interés (es Hombre) no cambia.
Esto quiere decir que las cancelaciones de usuario/conductor no afectan el efecto del género sobre el
salario del conductor; lo que significa que la brecha salarial NO viene dado por alguna decisión (tal
vez por discriminación) basada en el género por parte del usuario o conductor. Una conclusión muy
relevante para entender el fenómeno de brecha y discriminación. En otras palabras, entender la brecha
porque los usuarios cancelan al ver el conductor, tendría una interpretación muy distinta de los
resultados.
d) Concluya con respecto a si existe, y por qué de existir, una brecha salarial de género en Uber.
Argumente.
Los resultados indican que la brecha salarial por género (¡que existe!), se debe a decisiones o conductas
de los conductores (hombres o mujeres). La brecha desaparece cuando se controla por la velocidad,
barrios y horarios que acceden los conductores y al número de carreras. Es decir, los hombres
ganan más no por una discriminación de Uber (no sabe el género del conductor al pagar), ni por el
usuario (no hay efectos de cancelaciones), sino porque los conductores hombres hacen más carreras,
ya sea porque van más rápido o porque han acumulado más experiencia (más carreras), y saben
qué momentos y lugares son mejores para tener más carreras.
En la misma línea, seguramente van a horarios y barrios de difícil acceso también pudiendo hacer más
carreras. Como el salario depende del número de carreras, ganan más.
Nota: esto no quiere decir que no haya discriminación a nivel social (por ejemplo, los horarios que las
mujeres pueden hacer carreras podrían estar afectadas por labores familiares).
2. Un estudio analizó la salud de personas que concurren al hospital en comparación con las que no van,
obteniendo el siguiente resultado (Nota: tabla con formato en inglés; “,” son miles y “.” marcan los
decimales).
Donde Health Status corresponde a una medida del estatus de salud de los pacientes, variando desde 1 (muy
mala salud) hasta 5 (excelente salud). Al respecto:
a) Comente los resultados de la tabla anterior y explique por qué puede llevar a una conclusión equívoca.
b) Complete la siguiente tabla de resultados potenciales (celdas con “?”s).
Grupo que fue al hospital
(Hospital)
2.5
Grupo que no fue al
hospital (No Hospital)
?
Estatus de salud si se fuera al hospital (Yi(1))
?
?
Tratamiento – es decir, ir al hospital (Di)
?
?
Estatus de salud observado
?
?
Estatus de salud si no se fuera al hospital (Yi(0))
c) Indique el efecto de tratamiento promedio (ATE o Average Treatment Effect) y el efecto por diferencias
entre no observables, si piensa que los hay. Explique cualquier supuesto (razonable) que haga, si considera
que no se tiene toda información.
Pauta a,b y c:
La tabla indica que, en promedio el estatus de salud de la gente que va al hospital es menor respecto a la
gente que no asiste. Esto indicaría que el hospital, contrariamente a su función, enferma más a los
pacientes. Dicha conclusión se debe al sesgo de selección: usualmente, la gente que va al hospital posee
niveles de salud más bajos en comparación con los que no van (si no, ¿para qué irían?).
Grupo que fue al
hospital (Hospital)
Estatus de salud si no se fuera al hospital
(Yi(0))
Estatus de salud si se fuera al hospital (Yi(1))
Tratamiento – es decir, ir al hospital (Di)
Estatus de salud observado
2.5
Grupo que no fue al
hospital (No
Hospital)
3.93
3.21
1
3.21
3.93
0
3.93
El único supuesto es el 3.93 que está en amarillo. De este no se tiene información, pero si las personas que
no van al hospital no están enfermas (supuesto), no deberían porque cambiar su estado de salud (algunos
alumnos podían haber supuesto un valor mayor, pero lo debían justificar también].
ATE = ⏟
E[Yi (1)|Di = 1] − E[Yi (0)|Di = 1] + {⏟E[Yi (0)|Di = 1] − E[Yi (0)|Di = 0]}
Average tratment effect on the treatment
ATE = 3.21 − 2.5 + {2.5 − 3.93}
ATE = 0.71 − 1.43 = −0.72
Selection bias
3. Considere una intervención en la cual se quiere obtener el efecto promedio de tratamiento (ATE, por sus
siglas en inglés). Demuestre bajo qué condiciones al agregar una covariable 𝑋𝑖 a la especificación ésta
producirá un estimador de ATE más eficiente. Hint: considere que el error estándar del estimador del
ATE se puede expresar de la siguiente forma cuando no existen covariables:
̂) = √
𝑆𝐸(𝐴𝑇𝐸
(𝑉𝑎𝑟(𝑌𝑖 (0)) + 𝑉𝑎𝑟(𝑌𝑖 (1)) + 2 𝐶𝑜𝑣(𝑌𝑖 (0), 𝑌𝑖 (1)))
𝑁−1
Las siguientes igualdades y supuestos le pueden ser útil:
o 𝑉𝑎𝑟(𝑌 – 𝑋) = 𝑉𝑎𝑟(𝑌) + 𝑉𝑎𝑟(𝑋) – 2 𝐶𝑜𝑣(𝑌, 𝑋).
𝐶𝑜𝑣(𝑌,𝑋 )
o 𝛽1 = 𝑉𝑎𝑟(𝑋) cuando 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖
o Las muestras están balanceadas, es decir m = N/2.
Primero deben notar que para agregar al modelo deben reemplazar Var(Yi (Di )) por Var(Yi (Di ) − Xi ) ,
para ambos valores de Di quedando la ecuación:
̂) = √
SE(ATE′
= √
(Var(Yi (0) − Xi ) + Var(Yi (1) − Xi ) + 2 Cov(Yi (0) − X i , Yi (1) − Xi ))
N−1
(Var(Yi (0)) + Var(Yi (1)) + 2Cov(Yi (0), Yi (1)) + 4(Var(Xi ) − Cov(Yi (0), Xi ) − Cov(Yi (1), Xi )))
N−1
Al comparar ambos errores estándar, se puede ver que el término decisivo es
4 (Var(Xi ) − Cov(Yi (0), Xi ) − Cov(Yi (1), Xi )) < 0
Reordenando, se debe cumplir que
Cov(Yi (0), X i ) + Cov(Yi (1), Xi ) > Var(Xi )
o bien
Cov(Yi (0), Xi ) Cov(Yi (1), Xi )
+
>1
Var(X i )
Var(Xi )
En otras palabras, los coeficientes de β1 para la regresión de Yi sobre Xi en ambos casos deben ser
suficientemente fuertes para cumplir la condición. Es decir, que la covariable sea un buen predictor.
4. Un investigador está interesado en estudiar los factores que influyen en los salarios por hora de una
muestra de 3.000 trabajadores. Para ello, considera las siguientes especificaciones:
ln 𝐸𝑖 = 𝛽0 + 𝛽1 𝑆𝑖 + 𝛽2 𝐸𝑥𝑝𝑖 + 𝑢𝑖 (1)
ln 𝐸𝑖 = 𝛽0 + 𝛽1 𝑆𝑖 + 𝛽2 𝐸𝑥𝑝𝑖 + 𝛽3 𝑀𝑎𝑙𝑒𝑖 + 𝑢𝑖 (2)
ln 𝐸𝑖 = 𝛽0 + 𝛽1 𝑆𝑖 + 𝛽2 𝐸𝑥𝑝𝑖 + 𝛽3 𝑀𝑎𝑙𝑒𝑖 + 𝛽4 𝑆𝑖 ⋅ 𝑀𝑎𝑙𝑒𝑖 + 𝛽5 𝐸𝑥𝑝𝑖 ⋅ 𝑀𝑎𝑙𝑒𝑖 + 𝑢𝑖 (3)
Donde 𝑆𝑖 corresponde a los años de escolaridad, 𝐸𝑥𝑝𝑖 indica los años de experiencia del trabajador y
𝑀𝑎𝑙𝑒𝑖 toma el valor 1 si el trabajador es hombre.
Los resultados de las estimaciones se despliegan en la siguiente tabla, donde los errores estándar están
en paréntesis):
a) Interprete el coeficiente asociado a los años de escolaridad y a la interacción entre esta última y la
variable categórica asociada a sexo en la regresión (3).
El efecto marginal de la escolaridad en el retorno de la educación es:
∂ log E
= 0.94 + 0.005 ⋅ male
∂S
Respecto al coeficiente de escolaridad, un año extra de escolaridad implica un 9,4% de aumento en los
rendimientos de la educación para las mujeres.
Respecto a la interacción, y manteniendo la experiencia constante, los retornos de la educación son
0.5% mayores para hombres en comparación con las mujeres.
b) Interprete el coeficiente asociado a 𝑀𝑎𝑙𝑒𝑖 en la regresión (2) y (3).
Para la regresión (2), es posible concluir que los hombres ganan 23.4% más que las mujeres. Por otro
lado, para la regresión (3), entre las personas con 0 años de escolaridad y 0 años de experiencia, los
hombres ganan 11.7% más que las mujeres.
c) Explique cómo testearía la elección de un modelo por sobre los otros. (Puede ocupar el reverso de
esta página)
Para testear qué modelo es mejor, se debiera recurrir al estadístico F para modelos restringidos/no
restringidos. Sabiendo los coeficientes de determinación de cada regresión es posible construir el
estadístico que compare los modelos:
R2NR − R2R n − (k + 1)
⋅
∼ Fq,n−(k+1)
q
1 − R2NR
Donde NR hace referencia al modelo irrestricto, R al restricto, q es el número de restricciones aplicadas
y k el número de covariables (sin incluir constante).
F=
La hipótesis nula es la igualdad de coeficientes iguales a cero para llegar del modelo no restringido al
restringido.
A modo de ejemplo, para testear los modelos (1) y (2), la hipótesis nula es βMALE = 0, frente a la
alternativa βMALE ≠ 0.
. 359 − .319 3000 − (3 + 1)
⋅
∼ F1,2996
1
1 − .359
> F1,2996 .
F1,2 =
Y la regla de rechazo es F1,2
NOTA: No es necesario que los alumnos planteen los tests. Solo que expliquen cómo lo harían (no
contaban con calculadora en el control)
5. Los siguientes modelos indican la demanda en Estados Unidos por café de Brasil (en lbs.), CAFE, en
función de su precio (Pbc), el precio del té (Pt), el precio del café colombiano (Pcc), y el ingreso
̅ 2 : R2
promedio de los hogares (I), todo en dólares. Entre paréntesis están los errores estándares. R
ajustado.
̂ = 9,1 + 7,8𝑃𝑏𝑐 + 2,4𝑃𝑡 + 0,0035𝐼
(1) 𝐶𝐴𝐹𝐸
(15,6)
(1,2) (0,0010)
𝑅̅ 2 = .60 𝑁 = 250
̂ = 9,3 + 2,6𝑃𝑡 + 0,0036𝐼
(2) 𝐶𝐴𝐹𝐸
(1,0) (0,0009)
2
̅
𝑅 = .61 𝑁 = 250
a) En base a las estimaciones anteriores, ¿qué concluye en relación a la demanda de café de Brasil
(viendo cada una de las variables independientes)? Explique brevemente.
Para el modelo 1, no se puede rechazar la hipótesis de que 𝛽1 = 0 al nivel de significancia de α =
0,05. Esto sugiere decir que el precio del café brasileño no tiene ningún efecto sobre la demanda
por café brasileño (algo contra intuitivo). Para las otras dos variables se rechaza la hipótesis nula en
favor de la hipótesis alternativa al nivel de significancia de α = 0; 05, es decir, tanto el precio del té
como el ingreso promedio de los hogares tienen un efecto sobre la demanda de café brasileño.
Observamos en el modelo (2) de la tabla que el R2 aumentó, es decir, aumentó la explicación de la
variabilidad de la demanda respecto a la variabilidad del modelo (1). Además, si se realizan los
mismos test de significancia individual, se encontrará que ambos coeficientes son significativos.
Ahora, considere la nueva estimación (3).
̂ = 10,0 + 8,0𝑃𝑐𝑐 − 5,6𝑃𝑏𝑐 + 2,6𝑃𝑡 + 0,0030𝐼
(3) 𝐶𝐴𝐹𝐸
(4,0)
(2,0)
(1,3) (0,0010)
2
̅
𝑅 = .65 𝑁 = 250
b) ¿Cómo cambian sus conclusiones? Explique (en su explicación debe notar los cambios entre cada
estimación).
Ahora podemos observar que las conclusiones que obtuvimos en los apartados anteriores eran
erróneas y que todo se produjo porque en el modelo (1) no incluimos una variable relevante que era
el precio del café colombiano. Además, los coeficientes son todos significativos. El impacto que
podría tener remover una variable relevante de un modelo: Estimaciones sesgadas, creencias de que
hay variables irrelevantes en el modelo.
6. Un estudio realizado con eBay, plataforma global de compras y ventas por internet, examinó si pagarles
a motores de búsquedas por avisos publicitarios tiene efecto en sus ventas. Tabla 2 muestra los
resultados utilizando la especificación (ec.), sin y con controlar por efectos estacionales, donde
𝑙𝑜𝑔𝐺𝑎𝑠𝑡𝑜𝑠𝑖 es el logaritmo del gasto en publicidad en búsquedas por Internet en un distrito 𝑖 en EEUU
(áreas geográficas más pequeñas que una ciudad).
A) Interprete los resultados de la tabla 2, y determine qué puede aprender eBay del efecto de pagar por
publicidad en los motores de búsqueda.
De acuerdo con la tabla 2, se puede ver que aumentar en un 1% el gasto en avisos publicitarios
tendría un efecto promedio de ~0,89% y ~0,13% en las ventas, dependiendo si se controla por
efectos estacionales. Esta es la elasticidad. eBay puede aprender muy poco. Si bien al gastar más, se
tiene más ventas (lo que no implica mayor margen), debe tener mucho cuidado ya que esta correlación
no implica causalidad. Del primer resultado, es esperable: Si se gasta más en publicidad en diciembre
entonces se vende más que antes, pero no por la publicidad, sino por efecto estacional. Del segundo, la
relación persiste, aunque es menor. El problema aún existe: en los distritos que se gasta más, puede que
sean usuarios que generalmente compran más en eBay, independiente de si hay publicidad.
B) Considere que eBay normalmente no gasta en avisaje en Internet en distritos que no representan interés
económico para la empresa. Escriba la formulación matemática del efecto causal esperado 𝐸𝐶 del
avisaje (𝐸𝐶 = 𝐸(𝑌𝑖 (1)|𝐷𝑖 = 0 − E(𝑌𝑖 (0)|𝐷𝑖 = 0)) , en función del efecto esperado que observarían en
sus datos al comparar distritos con y sin avisaje, y el sesgo de selección. ¿Cómo se interpreta este sesgo
de selección? Recuerde primero definir el significado de los resultados potenciales y tratamiento en este
caso (𝑌𝑖 (0), 𝑌𝑖 (1) y 𝐷𝑖 ). .
● 𝑌𝑖 (1): Ventas que hubiera tenido el distrito si hubiera tenido publicidad.
● 𝑌𝑖 (0): Ventas que hubiera tenido el distrito si no hubiera tenido publicidad. 𝑖 (0):
● 𝐷𝑖 = 1 : El distrito tiene publicidad.
● 𝐷𝑖 = 0 : El distrito no tiene publicidad.
● 𝐸(𝑌𝑖 (1)|𝐷𝑖 = 0 representa el valor esperado en ventas en los distritos que no tuvieron gasto en
publicidad, si hubieran tenido publicidad.
● 𝐸(𝑌𝑖 (1)|𝐷𝑖 = 1) − E(𝑌𝑖 (0)|𝐷𝑖 = 0) = 𝐸(𝑌𝑖 (1)|𝐷𝑖 = 1) − E(𝑌𝑖 (0)|𝐷𝑖 = 1) + E(𝑌𝑖 (0)|𝐷𝑖 = 1) −
E(𝑌𝑖 (0)|𝐷𝑖 = 0)
𝐸𝑓𝑒𝑐𝑡𝑜 𝑜𝑏𝑠𝑒𝑟𝑣𝑎𝑑𝑜 = 𝑒𝑓𝑒𝑐𝑡𝑜 𝑝𝑟𝑒𝑑𝑖𝑐ℎ𝑜 + 𝑠𝑒𝑠𝑔𝑜
El sesgo de selección corresponde a las diferencias en el valor esperado de ventas entre distritos que
tienen y los que no tienen avisaje pagado, si no hubieran tenido avisaje pagado. Es decir, si ambos
distritos no hubieran tenido publicidad, ¿qué diferencias tienen? Muchas, ya que claramente hay un
sesgo de selección: aquellos que no reciben publicidad no son de interés de eBay por alguna razón
económica (por ejemplo, hay menos Internet en esos distritos, o no hay penetración en compras online).
Por ende, se espera que el sesgo de selección sea positivo con esta definición (i.e., más ventas en
aquellos distritos que tienen avisaje pagado, aun cuando no hubiera avisaje).
C) Compare los resultados de ambas tablas (Tabla 2 y 3). ¿Qué puede concluir?
Al comparar las tablas 2 y 3 se confirma lo estipulado en (a): no existía un efecto causal de gastar más
en avisaje (esto se ve en la tabla 3, ya que el efecto no es significativamente distinto a 0).
Al usar asignación aleatoria, ahora el sesgo de selección se hace 0, y por ende el coeficiente de
EsDistritoTratado no está sesgado, como si debe haber estado el de logGasto en la tabla 2.
Se concluye que para eBay es mejor no gastar en publicidad, ya que los usuarios compran de todas
formas; al buscar un artículo de consumo, de todas formas, la página de eBay aparece en el buscador,
aún sin avisaje, por lo que gastar recursos en publicidad era, en promedio, innecesario (y por ende una
mala inversión dado estos resultados). El R2 no entrega información relevante. Es más, en la tabla 2 es
mayor, pero eso no importa si el coeficiente está sesgado.
D) Discuta la validez interna y externa de ambos resultados (de Tabla 2 y 3).
Para el estudio de la tabla 2:
La validez externa se refiere a resultados que se puedan generalizar para lugares parecidos a EEUU
(aunque este al ser un mercado importante, es relevante por sí solo). De cualquier forma, eBay es una
empresa estadounidense y la extrapolación de los resultados a otros países puede depender de los
comportamientos de compra de los usuarios.
La validez interna está altamente amenazada por los motiva entregado en (a): no podemos establecer una
relación causal.
Para el estudio de la tabla 3:
Mismo comentario para la validez externa, mientras la muestra de distritos sea representativa de la
población objetivo.
La validez interna debiera ser alta en este caso, ya que la asignación aleatoria nos permite
cancelar el sesgo de selección, y obtener una relación causal.
E) Escriba un modelo de regresión lineal que pueda identificar si el número histórico de compras en
eBay es importante al momento de evaluar el efecto del avisaje, y escriba el test de hipótesis
respectivo para determinar si existe heterogeneidad.
𝑙𝑜𝑔𝑉𝑒𝑛𝑡𝑎𝑠𝑖 = 𝑎 + β1 * EsTratado𝑖 + β2 * NumeroHist 𝑖 +β3 * NumeroHist 𝑖 * EsTratado𝑖 +u𝑖
El test de hipótesis para testear heterogeneidad sería H0: B3 = 0
Más problemas (no necesariamente han aparecido en controles de años anteriores)
1. Suponga que mediante una encuesta recolecta usted datos sobre salarios, educación, experiencia y
género. Solicita también información sobre uso de la marihuana. La pregunta original es “¿cuántas
veces fumó marihuana el mes pasado”?
(i)
Escriba la especificación que permita estimar el efecto de fumar sobre el salario, controlando por los
demás factores. La ecuación deberá permitir hacer afirmaciones como “se estima que fumar cinco
veces al mes hace que el salario varía x%”.
Queremos tener un modelo de semi-elasticidad constante, por lo que una ecuación de salarios
estándar con el efecto del tabaco sería:
𝑙𝑜𝑔𝑆𝑎𝑙𝑎𝑟𝑖𝑜𝑖 = β0 + β1 * Cajetillas𝑖 + β2 * Educ𝑖 +β3 * Exper𝑖 +β4 * 𝐸𝑥𝑝𝑒𝑟𝑖2 +β5 ∗ Mujer𝑖 +u𝑖
Entonces al aumentar una cajetilla que se fuma al mes, esperamos que el salario cambie en
aproximadamente β1 ∗ 100%.
(ii)
Formule una especificación que permita probar si fumar tiene efectos diferentes sobre los salarios
de hombres y mujeres. ¿Cómo puede probarse que los efectos del cigarrillo no son diferentes entre
hombres y mujeres?
Hay que añadir un término de interacción entre la cantidad de cajetillas y la variable mujer.
𝑙𝑜𝑔𝑆𝑎𝑙𝑎𝑟𝑖𝑜𝑖 = β0 + β1 Cajetillas𝑖 + β2 Educ𝑖 +β3 Exper𝑖 +β4 𝐸𝑥𝑝𝑒𝑟𝑖2 +β5 Mujer𝑖 + β6 Cajetillas𝑖 ∗
Mujer𝑖 + u𝑖
Efecto de fumar si Mujer = 1:
Efecto de fumar si Mujer = 0:
Diferencia entre hombre y mujer: B1+B6-B1=B6
¿Cómo probamos que fumar tiene efectos diferentes entre hombres y mujeres? Realizamos un test
de significancia con la hipótesis nula de que el efecto de uso del tabaco no difiere por género es
H0: B6=0. Se calcula el t estadístico t6 y se ve busca en la tabla.
(iii)
Suponga que en vez de contar con datos sobre el número de cajetillas de cigarros al mes, se cuenta
con cuatro categorías de fumadores: no usuario, usuario suave (1 a 5 cajetillas por mes), usuario
moderado (6 a 10 cajetillas por mes) y usuario fuerte (más de 10 cajetillas por mes). Ahora, diseñe
un modelo que permita estimar el efecto de fumar sobre el salario.
Tomamos el grupo base como aquel que no consume ninguna cajetilla (no usuario). Entonces,
necesitamos variables binarias para los otros tres grupos: suave, mod y fuerte. Suponiendo que no
hay efecto interactivo con el género, el modelo sería:
𝑙𝑜𝑔𝑆𝑎𝑙𝑎𝑟𝑖𝑜𝑖 = β0 + β1 Cajetillas𝑖 + β2 Educ𝑖 +β3 Exper𝑖 +β4 𝐸𝑥𝑝𝑒𝑟𝑖2 +β5 Mujer𝑖 + β6 Suave𝑖 ∗
β7 Mod𝑖 + β8 Fuerte𝑖 + u𝑖
2. El Ministerio de Salud tiene como objetivo para este año disminuir el porcentaje de fumadores en el
país, por lo que le piden a usted que realice un análisis estadístico con el fin de comprobar si el aumento
de los precios del tabaco podría influir en la probabilidad de fumar. Para esto tiene una base de datos
que contiene información sobre personas de distintas zonas de Chile, incluyendo características
personales y el precio de cigarrillos promedio en las regiones donde residen.
(i)
Proponga un modelo de regresión que le permita analizar la influencia del precio del tabaco en la
probabilidad de fumar especificando cual es la variable dependiente. Justifique la inserción de las
variables escogidas.
Fumador ∈ {0,1}, la edad máxima no superaría los 100 y la educación máxima no superaría los 20
años; mientras que Pcig2017 está en el orden de 2000 e ingreso en el orden de 200.000 a 2.000.000
aprox. Para hacer todas las variables comparables se le aplica logaritmo a estas dos últimas
(comparar peras con peras y manzanas con manzanas). También se podrían incluir dummies por
regiones dejando una como caso base y el sexo, siempre que sea bien justificado.
𝐹𝑢𝑚𝑎𝑑𝑜𝑟𝑖 = β0 + β1 Edad𝑖 + β2 log (Ingreso)𝑖 +β3 Educ𝑖 +β4 log (𝑃𝑐𝑖𝑔2017)𝑖 +u𝑖
(ii)
A partir del modelo propuesto en la parte (i) proponga una forma de calcular la probabilidad de
fumar.
Donde 𝛽̅ contiene a todos los parámetros 𝛽 y X incluye a las variables del modelo.
Un compañero de trabajo estima el siguiente modelo de regresión:
(iii)
Interprete los resultados.
Significancia: Las variables de edad y educación son significativas a un 5% de significancia,
mientras que la variable de precio es solo significativa a un 10%. Ingreso no es una variable
significativa. Intepretación: La interpretación de los coeficientes no es directa como en la
regresión lineal, pues la elasticidad de una variable, digamos Xj, depende de las otras
covariables. Por esto, para interpretar el coeficiente de una variable será necesario fijar el valor
de las otras variables. Lo único que puede interpretarse directamente es como influye el signo
del coeficiente sobre el log del odd ratio a favor de P(y = 1|X) a medida que el valor de X
cambia en 1 unidad. Se puede decir que la edad, la educación y el precio tienen un efecto
negativo sobre la probabilidad de fumar; sin embargo, el logaritmo del ingreso tiene un efecto
positivo.
(iv)
¿En cuánto cambia la probabilidad de fumar aumentar en 1 el precio promedio de una cajetilla
de 1999 pesos, para una persona de 18 años, enseñanza media completa, e ingreso de 276.000
pesos mensuales?
Se tiene que la probabilidad de fumar para una persona de 18 años, enseñanza media completa,
e ingreso de 276.000 pesos mensuales es de:
1
P(y=1|Pcig2017=1999, Educ=12,Ingreso=276000,Edad=18) =1+exp (−β′X) = 0,929419.
Con 𝛽 ′𝑋 = 2.745 − 0.022 · ln(1999) − 0.09 ·∗ 12 + 4.72𝑒 · 10 − 6 · ln(276000) − 0.021 · 18
Haciendo lo mismo pero con Pcig2017=2000 (Se le sube 1 unidad para ver la variación) se
tiene lo siguiente:
1
P(y=1|Pcig2017=2000,E duc=12,Ingreso=276000,Edad=18) = 1+exp (−β′X) = 0,929418.
Con 𝛽 ′𝑋 = 2.745 − 0.022 · 𝑙𝑛(2000) − 0.09 ·∗ 12 + 4.72𝑒 · 10 − 6 · 𝑙𝑛(276000) − 0.021 · 18
Por lo que se puede concluir que el aumento de precio tiene una influencia negativa en la
probabilidad, pero que el aumento en $1 de una cajetilla de $1999, no hace la gran diferencia
sobre la probabilidad (una diferencia de 0,000001) de fumar de una persona de 18 años, 12 años
de educación y sueldo mínimo.