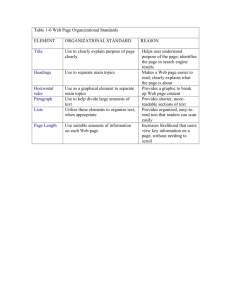
1979 LIDS-R-959 MULTIOBJECT TRACKING BY ADAPTIVE HYPOTHESIS TESTING* by
advertisement

December, 1979
LIDS-R-959
MULTIOBJECT TRACKING BY ADAPTIVE HYPOTHESIS TESTING*
by
Kenneth M. Keverian
Nils R. Sandell, Jr.
ABSTRACT
This report is concerned with a multiobject tracking problem in which
noise-corrupted position measurements are made on a number of moving targets. The number of targets, the association between measurements and
targets, and the track of each target must be deduced from the data. The
approach adopted is that of adaptive testing of data association hypotheses. Thus a decision tree of hypotheses is formed, and hypotheses
are accepted or deleted according to the nature of subsequent measurements.
A Kalman filtering approach is used to determine the target
tracks according to the various hypotheses,
and to determine their likelihood functions. The algorithm is implemented in the artificial intelligence language LISP, to permit flexible, dynamic data structure manipulation.
*The research supported herein was supported by the Office of Naval
Research under Contract ONR/N00014-77-C-0532.
Laboratory for Information and Decision Systems
Massachusetts Institute of Technology
Cambridge, Mass. 02139
-2TABLE OF CONTENTS
Page
ABSTRACT
1
1.
INTRODUCTION
3
2.
TECHNICAL DISCUSSION
9
2.1
Data Structure and Hypothesis Formation
9
2.2
Algorithm Overview
24
2.3
Tracking Equations
32
2.4
Results
44
3.
SUGGESTED FUTURE RESEARCH
APPENDIX - ALGORITHM DETAILS
REFERENCES
61
63
114
-31.
INTRODUCTION
In the past twenty years a considerable literature has developed
on recursive tracking algorithms.
These algorithms are generally based
on Kalman filtering theory with various extensions to handle such difficulties as nonlinear relationships between sensor signals and track
parameters, missing and false measurements, and maneuvering targets.
The algorithms have generally been rather successful for the class of
applications for which they were developed, namely a single sensor such
as a radar or sonar tracking a single object.
However, there are many applications, often in the area of military
surveillance systems, which require the tracking of multiple objects
using signals obtained from a variety of sensors
servers).
(including human ob-
Of course, if the sensors are accurately registered and their
resolution is very high compared to object spacing, the problem can be
effectively handled by the techniques developed for single-sensor,
single-object problems, with perhaps some ad hoc modifications for
such difficulties as those caused by crossing objects.
But there remain
many situations in which data association, i.e., determining which object gave rise to a given sensor signal, is a fundamental issue.
issue can arise in two closely related ways.
This
First, it is necessary to
associate the signals from a given sensor with those obtained from the
same sensor at an earlier time.
Second, it is necessary to associate
the signals from different sensors to determine which of them came-
1
See, e.g.,
[1] for a textbook treatment.
-4from the same object.
Recently, there has been an increasing interest in the multiobject
tracking problem [2] - [91
.
The algorithms proposed for this problem
can be categorized in various ways.
Some provide a probabilistic
data
association, in which the same sensor signal may be associated with
more than one track according to some probabilistic weighting, while
others make a hard decision associating each sensor signal with a unique
track.
Some algorithms are based on a Bayesian framework in which a
priori probability distributions for such quantities as target density
must be specified while others do not require this information.
Finally,
some algorithms immediately make a data association decision for each
sensor signal, while others defer the decision until subsequent
are received.
scan
signals
Algorithms in this latter category are termed multiple
or track splitting algorithms.
The algorithm described in this report is most closely related to
that of Reid 14].
Reid's algorithm is a
nonprobabilistic data associ-
ation, Bayesian, multiple scan algorithm.
Our algorithm is nonBayesian,
and differs in the details of its hypothesis deletion strategies.
But
perhaps the most interesting difference is that we have chosen to implement our algorithm in the artificial intelligence language LISP instead
of FORTRAN as in Reid's implementation.
This choice permits a natural,
1
Some of these references treat the single object problem with false
measurements, which might in fact come from other objects.
2
The terminology is from radar-based tracking systems, but the idea
clearly applies to systems incorporating other types of sensors.
-5transparent, and flexible implementation.
Moreover, it suggests the
possibility of developing more sophisticated versions of the algorithm
that utilize information of a discrete character
(e.g., "the ship carries
radar X") together with continuous, position-related sensor information.
From a technical point of view, the data association problem can
be formulated as a statistical hypothesis testing problem.
In addition
to the previous work in multiobject tracking, the development of the
algorithm reported herein has been influenced by work in hypothesis
testing for dynamic systems
colleagues at M.I.T.
[8],
,
especially that of ourselves and our
[10] - [22].
This work has largely centered
on the so-called multiple-model adaptive estimation (MMAE) algorithm,
(Fig. 1-1) first derived by McGill in 1965
[23].
The MMAE algorithm provides an optimal nonlinear filter for an estimation problem with observations coming from one of a finite set of
possible linear systems.
In Bayesian form, the algorithm recursively
computes the probabilities of the hypotheses that the actual system is
one of the possible linear systems, and produces the optimal (conditional
expectation) estimate of the system state.
It can be shown under reason-
able assumptions that the MMAE algorithm asymptotically identifies which
of the possible linear systems is the actual system
,
and converges to
the optimal (Kalman) filter for that system.
See Chapter
10 of
l1].
2
More generally, it can be shown that the MMAE algorithm identifies the
linear model' closest to the true system, which may be nonlinear and
high order, where the measure of closeness is provided by a certain
information distance 1i9].
-6-
4J
0k
.,--
U)
0
.,
,-o
.,10
:E:
i
1--
r4
__
__I_
-7As applied to the multi-object tracking problem, the set of possible
linear systems generating the measurements corresponds to the set of
objects being tracked.
However, the number of objects is not known
in advance, and since measurements come from all of the objects rather
than just one, the number of hypotheses is not fixed but grows rapidly
with time.
Although the MMAE algorithm can be formally extended to
this case, as a practical matter it is necessary to have an algorithm
with enough intelligence to create and delete hypotheses as required
by the evolving situation.
Such a data-driven algorithm is adaptive in
a higher sense and will be termed an adaptive hypothesis testing algorithm.
The present report describes the development of such an algorithm and
its application to the multiobject tracking problem.
Since our objective is to explore the feasibility of the adaptive
hypothesis testing approach, we have considered the simplest meaningful
multiobject tracking problem in order to focus on the issue of hypothesis creation and deletion.
Thus planar, straight-line, non maneuvering
target motion in Cartesian coordinates is assumed, with periodic position measurements of each target. 1
believed to be critical.
None of the these assumptions is
Consideration of maneuvering targets and
nonlinear measurements of target state is common in single object
tracking problems, and the extension to multiobject tracking is conceptually straightforward.
More interesting would be the consideration
of the issues associated with random intervals between measurements, and
non-position related, discrete valued measurements.
Although we will not
However, false and missing measurements are considered.
-8-
investigate these issues in the sequal, we feel firmly that the adaptive
hypothesis testing framework is the appropriate one for such an investigation.
In the remainder of this report, we will develop the ideas summarized in this introductory section in detail.
Section 2 contains the main technical discussion.
We begin by
discussing our hypothesis generation procedure and the data structure
that represents the hypotheses.
We then give an overview of the
algorithm that creates and deletes the hypotheses, and discuss the
reasons why LISP is a natural language to implement the algorithm.
The details of the computation of likelihood functions for the various
hypotheses are then elaborated upon.
Finally, we present some simulation
results that show how the algorithm performed in various test cases.
Section 3 contains the summary and suggestions for future research.
Finally, in the Appendix
a more detailed description of the algori-
thm including a listing is provided.
-9-
2.
2.1
TECHNICAL DISCUSSION
Data Structure and Hypothesis Formation
As discussed in the introduction, we are considering straight line
target motion with noise corrupted position measurements.
We assume that
a set of measurements, said to be in a given scan, is periodically supplied
to the tracking algorithm.
The tracking algorithm must determine the
number of objects present, and maintain a track on each object detected.
We will assume that a measurement has three possible origins: it is
a false alarm, a previously hypothesized target, or a newly detected target.
As the number of previously hypothesized targets can be quite large, so
The question that confronts us is
can the measurement's possible origins.
how to represent each hypothetical association of measurement to target
in an efficient data structure.
A method that comes immediately to mind
is to update target tracks for each hypothesis.
We define a track as a
set of measurements from successive scans which hypothesize the motion of
a single target.
A hypothesis is then a collection of possible tracks which
explain the origins of all the measurements taken.
scans are shown with three measurements in each.
target tracks over the three scan period.
In Fig. 2.1-1, three
The dotted lines represent
Hypotheses A,B, and C represent
three possible associations of the measurements to targets.
We assume that
any measurement can come from at most one target in a scan.
Thus, a meas-
urement can be associated with one and only one track per scan.
The total
number of hypotheses is in this case surprisingly large (in fact greater than
40,000), and grows quite rapidly as the number of scans increases.
There are at least two distinct approaches to representing different hypotheses in a data structure.
_____
Under a tanget oriented approach
-10-
--
,Y
Y
I
,
.
o'
I
I
I
#
1
.
.1
0
HYPOTHESIS A
:
Y
l II
x!
II
,'
j
I
I
%
%
0
I
I
I
-
0
HYPOTHESIS B
% ,
V
!
-- "
Al
I
%0O
HYPOTHESIS C
Filg.
~~
III--1911-111----
1
_IL..--___C-
21-1
Three Possible Data Associations
--
~~~~~~~~~~~~~~~~~~-----TI
II
31P~~~~~~~P--- --
-------
--~~~~~~-1-1
-
-11-
we construct a tree
where each level represents a target and each node
a different measurement.
Each path through the tree from the initial
to a terminal node then represents a complete data association hypothesis,
and each node corresponds to a measurement originating from the target
at that level.
This is shown in Fig. 2.1-2.
Note that a hypothesis
indicating that a target did not show up during a given scan is indicated by putting an "x" at the appropriate node.
scan
For the initial
(top figure) we are expanding from an initially empty tree, so the
possible tracks are all new targets or false alarms (denoted by "0").
the second scan, the possible tracks are the old targets
new targets) as well as newtargets
On
(last scan's
Thus, the number
and false alarms.
of levels added after each scan equals the number of old tracks plus the
number of new tracks plus 1.
The track oriented approach to hypothesis
representation is in-
efficient compared to the measurement oriented scheme.
In this
approach we assign each different measurement in a scan to a different
level, and place targets at nodes to imply that the target gave rise to
the measurement at that level.
Consider Fig. 2.1-2.
Measurement "ml"
occupies level 1, and is hypothesized to have given rise to either
target 1 or 0 (false alarm).
The number of levels of our hypothesis
tree is identical to the total number of measurements taken so far.
Notice as well that there is no redundant information in our measurement
oriented tree.
In the target oriented tree "x"'s must be inserted to
denote the non-appearance of a target, and the last level contains all
those measurements hypothesized to be false alarms.
oriented
The measurement
tree has no such redundant nodes, and is much smaller than
the target oriented
tree, especially after a few scans are processed.
The terminology is due to Reid [4].
-12-
TARGET ORIENTED
TARGET
1
MEASUREMENT ORIENTED
LEVELS
2
3
MEASUREMENT
LEVELS
0
m3
1
m2
I
m3-X
ml1.
X
7
(
NX/m3--
(m3)
m2)
X
(m2,m3)
jm3- (ml)
m2
x.
m3-
(ml,m3)
(ml,m2)
X-- (ml,m2,m3)
After first scan
After first scan
Variables in nodes represent measurements.
"X" indicates that no measurement is
associated with the target, "0" is a
false alarm
Numbers in nodes represent targets. "0"
is a false alarm
Tree structure after second scan
Tree structure after second scan
.
.
Hypothesis Generation
Fig. 2.1-2
(a)
-·P··----·-··--·IIF-··CI-------
(b) measurement oriented hypotheses
target oriented hypotheses
------- · · · ICI··-·
----
-----
I·
---- ·
---
Il-·C---
b
-
-
-·-Llb·-
---
-
-
I
-13On the other hand, the measurement oriented tree suffers from the defect
that many of its hypotheses may contain identical or nearly identical
tracks, but there is no convenient way to detect this situation.
However,
the measurement oriented tree will be used in the sequel because of its
compactness.
Now that we have discussed the general structure of hypothesis
generation, we consider the measurement oriented approach in more detail.
Two definitions will be helpful:
Def. 1.
A confirmed target is a target which has at some time occupied all
nodes in at least one level of the tree.
Def. 2.
A tentative target is a target which is not confirmed.
Nodes on a given level in the tree represent the possible targets giving
rise to the measurement assigned to that level.
If all possible targets
are the same, then we can deduce that the given measurement originated
from that target.
In a sense we have proven the target's existence, and
thus it is called a confirmed target.
If on the other hand, a target
has never been confirmed, then it's existence is uncertain and it is
called a "tentative target".
For an existing hypothesis, the possible
targets giving rise to a measurement are:
1)
all the confirmed targets,
2)
tentative targets assumed by the hypothesis,
3)
a new target, and
4)
a false alarm
For each measurement and each
xisting hypothesis we form branches in
our hypothesis tree corresponding to the above cases.
Since a tree of
-14branching order equal to the number of above possibilities would explode
quickly, much of our work will be in pruning out unlikely branches.
The first pruning rule that we follow is that a target can be
associated with at most one measurement per scan for each hypothesis.
This simply says that any target could not have produced more than one
measurement in a scan.
Figure 2.1-3 illustrates the' tree formation for
two scans, each with two measurements.
On the first scan there are no
prior confirmed or tentative targets, so each measurement
(denoted by a
subscripted "m") could have come from either a new target or a false
alarm.
Note that new target numbers mirror the subscript of the measure-
ment's name.
Thus, the degree of branching in our initial scan is 2,
i.e. we have a binary tree.
In processing our next scan, each branch
has tentative targets from the past scan, which possibly account for
the new measurements.
Thus our degree of branching in scan 2 will in
general be greater than or equal to 2.
Upon each branching we branch
to a new target, a false alarm, and all tentatives on that hypothesis
which have not yet been assigned on the present scan.
If confirmed
targets existed at this time, we would branch to them as well.
As we
expand further in a given scan, each branch uses up more and more
possible targets, and thus our branching degree may only decrease, not
increase.
This assumption is appropriate in the case of a single radar, but not
in most others. The assumption is of course inessential for the
adaptive hypothesis testing approach, but illustrates one type of
constraint on hypothesis formation that is readily incorporated.
-15-
MEASUREMENTS FROM
SCAN 1
0
MEASUREMENTS FROM
VSCAN 2
,,
tn,..
.
(a) Two measurement scans
I
2
.
. .
'
first scan
m4
1
".'
(b) Hypothesis ree after
...............
,~/S',~~~~~~~~~~~~~~~~~~~~/,',,,-,'j,.ji,,
v
. ' .'.'-i
'"
--at.,,
1
/
2
H;
4~~
~~O
.
I
3
:
o
a
o
,.-
-:
--7
4-4
;
..
·
1~~~
'3
-~'
"--~- 0I4~~
.'
O
i
:
4
'
O
.,·
22
4·~--0
3
IiI I
(cHy4poheis
Hypothesis tree'a eW I,,;
seccnd scan
iii; -1i:
i
''
',
:
. ......
''''
;"'""
'''2
.................
-;·
:
·
.
ii
::
. .
;::
(
A
0
...............................
(c
~;
I·· '
··.
·
..
I
.
-;;:i;.:·-~.,1,
.
o
·
-.
,:I,':,
.....
4
fe...".....
--
-
0 ~Igld
J
-
-
,
ig9,,,r.S,
-x-,
-.
,
;-
,-ft
=-
.1
;;..,,,,,..~,;..,,,.
~
··
· i··Car
At
19
,
N
~ii'""
4R
........- .
~rr'----~"--~~-
-i~w3~i~~.~-
,
i;·
-:~l
Fig.
....--
-.--
u1lr
-
2.1-3. -
=;4
1-1
--
-
Tree
Formation
- -- ~ ,-
-W~
;..a.
i~-A:Iljlii:
l
·
W>.Ewmn1aI
t-1- a-r- 1-1
-
;.. - .
.............
vx, - I-` r .ii
rr..-lnt;.;
1
i·:
i
NI
11i,
l, i!1-111iT-,,,,,
i. vA ilkiLP 11r,,
i,]PI
i!";ld
IV41":!
I ii 11,11,k
1f4",
j1j11,04
I I1R,
1
I,Intrinsic
M.
t,I
1:1
., I,I, "
L,
:,.··,.
!)_
,1;1
6·.,ni-
-16-
As mentioned in the introduction, we take a multiple scan approach
to the multiobject tracking problem.
what we mean by this statement.
Let us now discuss in more detail
In most cases, considering all the
possible data associations of one scan gives us many likely hypotheses.
Often there are many hypotheses which seem just as likely as the next,
and deciding among them would be arbitrary at best.
An N-scan algorithm
attempts to solve this problem as follows; before it decides on the
association for the present scan, it will wait N more scans and then
chose the association which is most likely in light of the subsequent
measurements.
This principle is illustrated in Fig. 2.1-4.
Suppose
that at scan 2 the existence of a target whose track consists of
measurements
(ml, m2) has been determined.
Now, on scan 3 we have two
very likely possibilities; namely that the target is at m3 or m4.
With
an N-scan algorithm we postpone this decision until collecting data for
N more scans.
In Fig. 2.1-4.b we see that by the fifth or sixth scan
the assumed straight line motion of a target better fits the choice
of m3 than m4.
Thus, by using subsequent data we may be able to decide
on the best association for any scan.
While N-scan algorithms are useful in helping to chose past data
associations, we are not guaranteed that an obvious decision will
result after waiting N scans.
Consider Fig. 2.1-5 for example.
Assume
that by scan 3 we have 2 targets consisting of (ml, m3, m5) and (m2, m4,
m6).
cross.
Now on scan 4 the measurements are very close since the tracks
It is virtually impossible to tell which track the measurements
belong to.
Even after waiting N scans, the conflict is not resolved.
While the tracks become once again distinguishable after they pass each
-17-
&I
SC
%SC
1%
Nu
N
N
N
Three scans of measurements,
ambiguous tracking decision
(a)
I
I
I
II
I
I I II I
II
SCA.
N.
N%
N1
4h
%qb.
(b) Six scans of measurements,
clear tracking decision
Fig. 2.1-4
~- -------
"
-~I-
I
-~----------
N-Scan Approach
-18-
-
m12 0
ml
SCAN 6
mlO
SCAN 5
\om9
SCAN 4
m7 om8
SCAN 3
/m5
SCAN 2
SCAN
\om6
m4
/oml
*
\om2
~~~~~I
Fig. 2.1-5
III
IIIII
IIII
Crossing Tracks
I
a
II
II
25
.7 1
*- -2 ~ o -
II
I
0o
<
e-
An identified scan
Fig. 2.1-6
I
°-22 1
II
(a)
I
2
(b) An unidentified scan
Scan IdentificatIon
-19-
other, we are never able to confidently assign the measurements of scan
4.
However, the important thing is to maintain the track, not to neces-
sarily identify each and every measurement; so the fact that scan 4 remains ambiguous is not harmful to our final solution.
The important point
in the above discussion is that waiting N scans to identify a scan can
be quite powerful.
Some scans are identified almost immediately and thus
require little waiting while others remain unidentified regardless of the
amount of waiting.
The N-scan approach most commonly used in track splitting algorithms
is to wait a constant number of scans before identifying a scan.
Recog-
nizing, however, that some scans identify faster than others it seems
that we should wait only long enough to identify the scan, with of course
some maximum waiting period.
1
We begin our discussion of our variable
N-scan algorithm by defining an identified scan:
Def. 3.
An identified measurement is a measurement containing identical
hypothesized targets.
Def. 4.
An identified scan is one which contains only identified
measurements.
Fig. 2.1-6 contrasts tree structures for identified and non-identified
scans.
By definition of an identified measurement, an identified scan
contains confirmed targets only, for each measurement is uniquely assigned
to a target.
Now our implementation of the variable N-scan algorithm will
store scans in a FIFO (first in, first-out) buffer.
The oldest scan stays
in the FIFO either until it identifies (after a finite number of subsequent scans) or until the FIFO becomes full.
1
If the oldest scan identifies,
In the parlance of Artificial Intelligence theory, a variable depth decision
tree search strategy is desired.
-20-
we drop it off the FIFO and update a target state list of the most
recently identified scans.
If the oldest scan never identifies and the
FIFO becomes full, we pick the best association for the oldest scan,
update the target state list with this association, and drop the scan
off the FIFO.
Notice that we must store a particular scan only as long
as it remains in the FIFO.
Once
we update the target state list and
drop the scan off the FIFO we never refer to it again.
the FIFO with our hypothesis tree is now simple.
Implementing
We limit the size of
the FIFO by allowing the tree to contain some maximum number of nodes,
and we bump a scan off the tree by collapsing all nodes of that scan
into the root node of the tree.
Fig. 2.1-7 steps through the expansion
and shrinking of our FIFO tree structure.
nodes signify a hypothesis being pruned
likelihood.
Note that "x"'s at terminal
out due to a relatively low
This and other methods of pruning will be discussed next.
As mentioned, without strong pruning the size of the hypothesis
tree quickly explodes.
In determining the amount of pruning there is
a tradeoff between computational demands and optimal hypothesis selection.
With more pruning, fewer hypotheses will be explored, and the probability that we may drop the correct hypothesis is higher.
On the other
hand, with less pruning, many different hypotheses will be explored at
the expense of loading the computer.
pruning techniques are used.
In the present work two main
direct
The first represents a modification to the
list of possible targets to branch to
"in incorporating a new measurement.
Remember that these possible targets are:
confirmed targets, tentative tar-
gets on the hypothesis branch, a new target, and a false target. We change this
-21.
-
I
SCAN 1
OAKI
I
H I
-
FIFO:
FIFO:
(b) Scan 2 enters the FIFO
(a ) Scan 1 enters the FIFO
Q"An M
IAE
FIFO:
C
N
m
d
(c) Scan 1 becomes identified; and
is bumped off the FIFO
SCAN 5
I
I
X
l
I
I
k Nc
FIFC
SI
c I C
AIAI
N INI
4
3
FIFO:
A
N
2
6
SCAN
I
I
-
(f)
I
I
tf
I,
I
I
I
mA
Scan 2 remains unidentified; FIFO can
not accept another scan without
bumping scan 2 off
(e)
(d) Assume that after pruning,all measurements but one become identified; scans
3 and 4 are identified but can not bump
off FIFO till scan 2 does
A
I
~I
I!
~
!
!
/
I
I
S
A
N
6
-
After bumping scan 2 off the FIFO,scans 3,4, and 5 bump off because they are
identified; the remaining tree consists only of scan 6
O= identified measurement
X = pruned hypothesis
Fig. 2.1-7
1
--r
-
----
--
------
-
----
FIFO Tree Structure
-L1*--·II--·---b
-----
q·-gilll·ii_1·--^-·--·-1·sl·1
------·
FI___·----__·
---
-22-
slightly by only including those confirmed and tentative targets for which
the measurement is sufficiently close to its predicted
past measurements on the target (Fig. 2.1-8a).
value given the
This pruning constraint im-
mediately eliminates very unlikely hypotheses, and thus greatly reduces the
average branching degree of the tree.
pruning.
It can be regarded as a first pass
The second pruning constraint involves simply pruning hypotheses
with low likelihood values.
As is discussed subsequently, the likelihood
function of each hypothesis is calculated after each branching.
At any
scan, we keep only the M most likely hypotheses, simply dropping the
others from further consideration.
Now the choice of the breadth para-
meter M is critical, with a similar complexity vs. optimality tradeoff
as discussed for the N-scan FIFO setup.
A consequence of dropping past scans off the tree is that many
hypotheses become identical.
This may result when two hypotheses are
exactly alike except for a minor difference occurring a few scans back.
Once that old scan is bumped off the tree the two hypothesis branches
have identical entries (although the corresponding tracks estimates will
differ slightly) and thus it would be wasteful to carry them both along.
In this case we say that the two hypotheses are "fully identical" and
drop one of the redundant branches.
We say that two hypotheses are
"1-1 identical" when they are "fully identical" except for a one to one
renaming of tentative targets.
The 1-1 renaming of tentative targets
may occur if two hypotheses start to track an object one scan out of
phase.
The hypotheses will assign the object different names, and this
difference will be propagated throughout both hypotheses.
If they are
-23-
-
o
o
m8
c
%
X~~~
\ 0
CAN
\ SCA%N2 SCAN3
SCAN3
SCAN I SCAI
(a)
SCAN4
SCAN 4
SCAN5
SCAN5
First pass pruning by assigning to
measurements only those targets which
contain the measurement in an " N-sigma"
probability region; only m5 and m7 Nould
branch to target 1
x
x
x
x
(b)
Pruning out all but the five
most likely hypotheses
( c)
Resulting tree after pruning
_
Fig. 2.1-8
--------
_
Pruning Techniques
-24-
otherwise identical, than they will become "1-1 identical" as soon as
the scan with the original difference is bumped off the tree.
hypotheses can be merged as in the fully identical case.
Thus the
The merging
technique cuts down redundant expansion of the tree, (Fig. 2.1-9).
The goal of the tree oriented data structure we have described
has been to efficiently represent hypotheses.
Forming unlikely or re-
dundant hypotheses can cause tremendous growth of the tree and thus must
be minimized.
Techniques discussed to minimize tree growth have been
1)
the "measurement oriented" tree structure,
2)
the variable N-scan FIFO approach
3)
hypothesis pruning, and
4)
hypothesis merging.
As we will see in the sequel, these techniques succeed in limiting both
the depth and breadth of an otherwise exponentially growing hypothesis
tree.
2.2
Algorithm Overview
In this section we present an algorithm which implements the pre-
viously described data structure.
Throughout the discussion here, we
will refer to manipulations on an arbitrary tree of hypotheses.
The
association between tree properties and the tracking problem should be
kept in mind.
The overall algorithm is presented in the flow chart of Fig. 2.2-1.
Very roughly, the algorithm involves:
1)
tree expansion and pruning,
2)
FIFO maintenance, and
3)
hypothesis merging.
-25-
-
_
-
__
__
<,G<3
(a)
Hi
H2
H3
H4
H5
He
H7
H8
H9
H,,
H11
Hypothesis tree after dropping scan 1.
Notice the fully identified hypotheses:
(H 3 =H 8 ),(H-H ),(H H IO)-HH 1 1 )
(b)
Hypothesis tree after two scans
have been processed
and the 1-1 identical hypotheses:
(H 1 1 H 3 ,H 8, H4 ) and (H 2 H, s , H9 )
3 H1
3 HH3,HsH
o H2
33HH3,H8
I H4
.o H2 ,H5sH
O H,Hq
*3 H6, H10
3 H6HtO
Hypothesis tree after arbitrarily
choosing one of the 1-1 identical
branches to represent the hypothesis,
and pruning the others
(d)
Hypothesis tree after dropping
redundant,fully identical branches
i
2.1-9
Fig.
I
_
9
HH11
o H.H..
(c)
4
Hypothesis Merging
_
C
C
11
q
-26-
TREE
)
EXPANSION
I
Il
CSF:
IEXPANSIO
N
I
I
I
I
I
IIFIFO
II MAINTENANCE
Ii
I
)
Fig. 2.2-1
Algorithm Flow Chart
III
II
I
I
-27-
Refer to Fig. 2.2-1.
After completing an initialization routine we
enter the main control loop of the algorithm.
The first thing done is to
incorporate the pending measurement scan by assigning each measurement a
variable name.
Next the tree is expanded in the FINDNOD routine.
Each
node can branch to a set of possible new nodes as outlined previously.
For each such branching we update the state vector estimates and error
covariance matrices (see Section 2.4) of our targets as well as the
likelihood
function of the-new hypotheses.
In implementing the pruning
techniques a branch-and-bound type method is used.
Since
we keep only
the M most likely hypotheses, we keep a list of the current M most likely
hypotheses in the tree.
Initially, we let the list fill up by including
the first M new hypotheses formed.
Henceforth, we compare the smallest
likelihood function of the M with the likelihood function at the present
node of expansion.
Since likelihood functions can only decrease, (see
Section 2.4) if the present node is already less than the minimum of the
M, we know that its successor nodes will be even worse, and thus we prune
it out immediately.
However, if its likelihood function is greater than
the minimum of the M and we have finished branching, then we replace the
minimum likelihood node of the previous M with the new node, pruning out
the one we replaced.
tinue branching.
If neither
conditions are satisfied, we just con-
The branch and bound method corresponds to a depth first
expansion of the tree, meaning we expand the tree roughly one hypothesis
at a time.
Hypotheses with low likelihood functions will be discovered
quickly and be discarded.
This saves us from having to explore down paths
found at any point to be worse than the M best so far.
-28-
After expanding the hypothesis tree we check to see whether our
pruning has caused any targets to become confirmed, and if so we update
a confirmed targets list.
from the tree.
Then we determine whether to drop any scans
This is our FIFO maintenance section.
In BOTCHECK we
check whether our bottom scan is identified, i.e. if all hypotheses give
the same data association for the bottom scan.
If so, we update a confirmed
states file which contains the estimated state of all confirmed targets
at the time of the last bottom scan identification.
We then bump the
scan off the tree and check to see whether the new bottom scan is identified.
As soon as we find one that is not, we proceed to check whether the FIFO
is full; that is, if the number of nodes in the tree exceeds some upper
bound.
If so, we update the confirmed states file for the bottom scan
using the most likely hypothesis and bump the bottom scan off the tree.
In the last part of the algorithm, we list any hypotheses which
are either 1-1 or fully identical.
This is done in MATCH.
Once we
find these, we prune out all redundant hypotheses, keeping only the most
likely one for each group.
Finally, we again check to see whether con-
firmed targets have manifested due to MATCH prunings and we update our
list if necessary.
Having thus finished processing a data scan, we
go back, wait for the next scan to arrive, and repeat the process.
While only the major blocks of the algorithm have been presented
here, more detailed descriptions and the actual program listings can
be found in the Appendix.
LISP Implementation
As mentioned in the introduction, one of the novel aspects of our
approach to the multiobject tracking problem is the use of LISP for
-29-
implementing our algorithm.
At first thought it might seem that -the
choice of a computer language has little to do with the underlying
algorithm.
While this is true in an abstract sense, the syntactical
power of a language determines in a very real sense the computational
complexity and expandability of any algorithm.
In the target tracking
case, LISP turns out to be an extremely natural and powerful environment
in which to construct and evaluate hypothesis trees; it is much more
powerful than more conventional languages like FORTRAN.
The final choice
of LISP was treated as an important design decision when considering the
computational and programming tradeoffs in the development of our algorithm.
In what follows, we discuss the advantages and disadvantages of LISP in
light of the needs of the multiobject tracking problem.
Historically, LISP has developed as the primary computer language
for writing programs implementing artificial intelligence theoretic
concepts.
Artificial intelligence theory [24]
is concerned with deter-
mining the knowledge necessary to deal with a given problem domain, and
with efficiently representing and drawing inferences from that knowledge
so that problems apparently requiring human intelligence for their solution can be solved by a computer.
Many of these problems involve tree-
like data structures, and since LISP has been developed--with the specific
purpose of dealing with such problems, it is a very natural language for
them.
Recognizing the similarities of the multiobject tracking problem
to tree searching problems in artificial intelligence theory is a step
in its solution.
The desired algorithm must make decisions based on past
and future data.
If a clear decision is not evident, it must wait a few
scans, hoping that the situation will clarify.
In addition, it must
evaluate the quality of different hypotheses and only consider the best.
-30-
The decision analysis used throughout is based on statistical models.
Of
course, the quality of decision making can not be better than our statistical formulation.
Here, however, we can rely on a considerable body of
statistical theory and research to guide our development .
However,
the way in which we use our model to make decisions is where artificial
intelligence technology becomes useful.
Let us now discuss some of the
features of LISP which make it a suitable vehicle for multiobject tracking.
Specifically, two features of LISP make it suitable for the multiobject tracking problem.
These are LISP's recursive nature and its
natural tree structure.
Recursive solutions to problems can often be
written in relatively few lines of code, since they allow procedures to
be written that call themselves while automatically handling the nested
storage of variables needed.
In the hypothesis generation portion of
the algorithm we have developed, the recursive approach permitted the
development of very general, flexible, and succinct code.
An iterative
approach would in general weight the program down with subscripts, do
loops, and bookkeeping, thus discouraging experimentation with the data
structure and program logic.
In contrast recursion allows an almost
effortless kind of solution.
This greatly enhances the case of develop-
ment and use of the program.
The second advantage of LISP, its inherent tree structure, is
important in our tree oriented tracking problem.
constructed in a variety of ways.
Trees in LISP can be
One way is to use LISP's natural
Other languages, for example PL/1, have similar features.
-31structure of lists.
A list is an ordered collection of elements, each of
which may be a single variable or a list itself.
f (g h)) is a list of four elements.
For example:
(a (c d)
If we consider each element to be
a descendant of the root of the tree, the above list represents the following tree:
c
g
d
k
LISP is make up largely of powerful functions on lists such as sorts,
searches, mapping, etc.
This creates a very high level environment in
which to scan and operate on trees and lists.
Another way of creating trees in LISP is to use a construct known
as a property list.
To each variable, the user can assign different
attributes and corresponding values.
For instance, the variable ANODE
may have a property called LIKELIHOOD, whose value we set to be (0.75).
Using properties, trees can be constructed by assigning to each node a
SONS property whose value is a list of immediate descendants on the tree.
Likewise, values of likelihood and state estimates can be carried on each
hypothesis as values of properties.
By carrying attributes of each hypo-
thesis on property lists, we have an efficient means of characterizing
each hypothesis.
In fact, this was the method used for implementing our
-32-
hypothesis tree structure.
While we have mentioned some advantages of using LISP in our multiobject tracking problem, there are a few disadvantages.
uncompiled
LISP tends to run very slowly.
First of all,
LISP is an interpretive language,
which in effect means that the LISP operating system evaluates commands as
soon as they are typed on the terminal.
LISP's control loop for supplying
input and recognizing commands makes it very slow.
To get around this
problem, however, one could compile a LISP program and then run directly
in machine language.
Another strong disadvantage of LISP for numerical
problems is that LISP has almost no high level numerical operators.
example,
For
defining iiatrices is somewhat awkward and functions such
as matrix multiplication or addition do not exist and must be written by
the programmer.
A final disadvantage or inconvenience of LISP stems from
its unique nature.
Because of its strong recursive basis and unusual list
functions, the language seems obscure to the uninitiated user.
Becoming
accustomed to LISP's unorthodox nature and learning to think in LISP's
recursive style can be a substantial hurdle for the prospective user.
The
benefits, however, can be far reaching.
In our opinion, LISP's natural advantages relative to the multiobject
tracking problem outweigh the disadvantages mentioned.
In choosing LISP
we obtain more than just a convenient language for programming; we obtain
increased expressive power for constructing our algorithm.
2.3
Tracking Equations
As briefly mentioned in the preceeding sections, the decisions made
in our multiobject tracking algorithm concerning which hypotheses to
-33to accept and which to reject are based on statistical principles.
Thus
we postulate stochastic models for target motion and the resulting sensor
signals so that a joint probability distribution function of all the 6b-:
servations obtained can be derived for each hypothesis, and the maximum
likelihood hypothesis testing procedure invoked.
approach are developed in this section.
The details of this
We reiterate that the goals of
this research were to investigate the feasibility of the adaptive
hypothesis testing approach and not to develop an algorithm for any specific application area.
Consequently, we restrict attention to the simplest
interesting models of target motion and sensor observations.
The assumption we make concerning target motion is that all targets
move in straight lines in 2-dimensional space.
Incorporating maneuvering
models is an extension in principle easily handled within our present
framework.
Now given a hypothetical association between sensor measure-
ments and targets, we must estimate the state of each target from the present
and past measurements.
One approach is to perform a least squares re-
gression after each scan, and thus determine the desired target state
estimates and error covariance matrices.
This however is time consuming
and requires that we save all previous measurements.
What is preferable
is a sequential form of least squares regression which requires only last
state estimate, error covariance matrix, and the present measurement
to perform the update.
The appropriate algorithm is the Kalman filter
Since we consider only two dimensional motion, the state of each target
is given by its x position, x velocity, y position, and y velocity.
1
Depending on the application, maneuvering targets can be handled by adding
process noise to the target model or, alternatively, by various adaptive
filtering techniques.
-34-
Further, if we assume that motion in the x and y directions is independent,
we can decouple each target's motion in the two directions.
measurement equations for each target are of the form
systems theory
x(t+l) =
The state and
found in linear
systems
1theory
(2.3-1)
(t)x(t) + G(t)w(t)
(2.3-2)
y(t) = H(t)x(t) + v(t)
where x(t) and y(t) are our state and measurement vectors at time t, and
further:
E(x(O)) =m (0)
(2.3-3)
E(w(t)) = 0
(2.3-4)
T
E(w(t)w (t))
El(x(0) - m
(2.3-5)
= Q(t)
(0)) (x(0) - m (0 ))T] = PO
(2.3-6)
E(v(t)) = 0
(2.3-7)
E(v(t)vT(t)) = R(t)
(2.3-8)
and x(O), v(O), w(O), v(l), w(l).... are all zero mean gaussian random
variables.
From this model, the Bayes linear least squares regression
can be written in Kalman form:
(O I -l ) = m- (0)
1The various matrices and vectors in
sequently in this section.
(2.3-9)
(2.3-1) - (2.3-9) are specified sub-
-35-
P(01-1)
(2.3-10)
= P
_(tjt) =
x(t+llt) =
(tlt-1) + K(t)fy(t)
(t)
(2.3-11)
- H(t)x(tjt-l)]
(2.3-12)
(tlt)
(2.3-13)
P(tjt) = [I - K(t)H(t)]P(tlt-l)
K(t) = P(tt-1)HT (t) [H(t)P(t t-l)T
(2.3-14)
t) + R(t)]
P(t+ljt) = (t)P(tlt)T (t) + G(t)Q(t)G T (t)
where
(2.3-15)
(t+llt) denotes the estimate of x(t+l) given the observations y(O),
y(1),..., y(t).
The above recursive algorithm produces an estimate of the target state,
and moreover allows a likelihood function to be evaluated for each hypothesized data association.
Under the maximum likelihood approach we adopt,
no "a priori" information about such quantities as the expected number
of targets is assumed.
Instead, the likelihood of each hypothesized
data association is determined by how well it fits the observations.
A Bayesian approach, on the other hand, would require assumptions to be
made concerning the distribution of targets.
Although the algorithm described herein-could certainly be adapted
to a Bayesian approach, we have preferred to avoid the problem of
specifying a priori -distributions and have instead taken a maximum likelihood approach.
We now proceed to derive an expression for the likelihood function
of each hypothesis under our stated linear model.
First, note that each
hypothesis involves the motion of a number of targets.
Thus, when we
-36-
assign a target to a certain measurement, we must update that individual
target's state estimate and error covariance matrix, as well as the likelihood of the hypothesis.
We can view each hypothesis as a collection of
tracks, and thus a collection of individual Kalman Filters.
One composite
likelihood value is updated for each hypothesis, which represents the
"goodness of fit" of all tracks on that hypothesis.
In our present
scheme where many different hypotheses can exist, the total number of
Kalman filters equals the sum of tracks in each hypothesis over the number
of hypotheses (see Fig. 2.3-1).
Now the probability density give hypothesis
H. is defined as:
1
Density of
data association
under H i
= P{y(T), y(T-l),...,y(0)jH.}
(2.3-16a)
where y(t) is the vector of (x,y) measurement pairs collected on the scan
at time t.
Breaking this down to reflect the measurement to target
assignments, we get:
Density of
data association
under Hi
= P[ yL(T)
y(T),...,y
(2.3-16b)
(T)),{y (T-l),y(T-l),...,y(T-1)1,...
{y (),
(°0),...,y (0)}Hi.]
(2.3-16c)
=
P[{
1
(T), y1 (T-l),...y--l(0),
*..*.,{
T)
{y (T), y 2 (T-l),...y
, (¢T-), ...
, (O)}|Hi]
where yj (t) represents the measurement pair assigned to target j at
time t.
Note that going from (2.3.16a) to (2.3.-16c) we have merely
grouped the measurements into individual tracks.
Now, assuming that
the motion of any target is independent of all other targets, we can
write equation (2.3.16c) as:
2
(0)},...
-37KALMAN FILTER
HYPOTHESIS 1
LIKLIHOOD
VALVE; H 1
KALMAN FILTER
HYPOTHESIS 2
LIKLIHOOD
VALVE; H2
KALMAN FILTER
HYPOTHESIS N
LIKLIHOOD
VALVE; HN
Fig. 2.3-1
Filtering Scheme
-38-
Density of
) J
data association1=
P
under Hi
F
(T),
Yj(T-)...,y(O)lHi)
j
for J the highest numbered target on the hypothesis.
(2.3-16d)
By use of Bayes'
rule we can simplify the density expression for any target j:
P(
y(T), y(T-l),...,j
PP(y.
(O), HH)
(T-l)y.(T-2),..., y (O),
*-
i
H)
-
T
=
t=l
where y
(t)
P(Yj
(t)IY(t), H.)
P
(OHi)
(2.3-17)
represents all measurements assigned to target j up to and
including time t.
Recognizing P(yj (t) y t-
,
H ) as the innovations
density of the Kalman Filter for target j at time t, we obtain,
T
[
T
P(y.(
y(t)
t 1)' Hi) =T
P(V (t)Hi)
(2.3-18)
t=l
t=l
where V. (t) is the innovations and:
-3
v. (t) =
.(t)
(t) -
(tIt-l)
(2.3-19a)
N(0, S (t))
(2.3-19b)
S.(t) = E(V. (t)VT(t)) = R(t) + Hj(t)Pj(tlt-1)H
J
-j
J
3
where Rj(t), Hj(t) and P (tlt-l)
filtering equations.
(t)
(2.3-19c)
are the matrices defined in our Kalman
Since V (t) is a gaussian random vector, we can write
-39-
its distribution function:
P(v. (t))
3
T
-1
expt-V (t)S (t)vj (t)/2])
-J
21S j (t) I
27TI
where we have dropped the H
)
(Density of
)track j under =
(2.3-20)
Now from (2.3-17) we have
for brevity.
T
TTP(V.(t))
P(y(0)IHi)
(2.3-21)
the expression for the likelihood function of track j, which is just
the probability density function of all
under hypothesis i.
measurements assigned to target j
It is convenient to consider the negative log
likelihood function, which will serve as our measure of fit.
Lower
values of this new function correspond to hypotheses that fit the
measurements better.
Using equations (2.3-17),
(2.3-18), and (2.3-21)
as:
we define the negative log likelihood of hypothesis H
-log
likelih°ood
= -An
P(yj
ff(t=;T
- -Rn;j=1
En{
-= E
l
j=l
j=l
/n
(T),
y(T-l),...
y (O
H.)
p(v .(t)t
P
P Y (0),Hi I
P(v (t))
P+Rn[P(Yj0)
nP(V
(
(2.3-21a)
(2 3-21b)
i]}
Yn[P(y
(0) IHiJ (2.3-21d)
)
t)) +
t=l
J
jEl |El
(t)
pa(t)
2
+knP( (0)
J
+
i)
n 2
I Sj (t)1/2
+
(2.3-21e)
-40-
Notice that (2.3-21.e) can be calculated sequentially.
The increment to
the negative log likelihood function for target j at time T is just:
nI Sj (t)I
+
n 2
+
,
t > o0
2
A(-log likelihood) I
target j
time t
; t= 0
(2 qv
So far we have established the state estimate equations and likelihood functions for a general dynamic :hypothesis testing problem.
We
must now, however, make a few modifications to fit the multiobject
tracking problem.
We consider two distinct cases of track update:
initiation and track maintenance.
track
Track initiation occurs for the first
two measurements of a proposed target, and beyond that we have track
maintenance.
In developing state estimate and likelihood function up-
dates for initializing a target, we resort to special forms as opposed
to the equations previously given.
Immediately after the first two
scans in which any newly detected target appears, its estimated track is
simply the straight line joining the associated measurements, for we
need at least two measurements to determine a track.
Consequently, we
add no increment to the likelihood function value because we have no basis
to penalize a track before more than two measurements are obtained.
Thus, we modify (2.3-22a) to read:
V (T)S '2 (T)V(T)
+
-1
+
A(-log likelihood)
target j
time T
n 2
+
+
S(t)L
2;
T>2
)
0
; T<2
(2.3-22b)
-41-
However, we immediately delete a hypothesis if the two measurements
associated with the hypothesized new target imply a velocity above some
maximum value;
j .(t+l)
i.e. for yj(t)
= (xj(t), yj(t)), if we have
- x.(t))2 + (y (t+l)
AT-AT
y.(t))2
--
> V
(2.3-23)
max
then we delete any hypotheses that attempt to associate y (t) and yj (t+l)
with the track of a new target.
Finally, if on the scan after its
hypothesized detection a new target fails to appear, we delete any hypotheses
associated with that target.
This approach helps to prevent the algorithm
from continually assuming new targets.
If in fact a real new target is
dropped, the target will be detected again on subsequent scans.
Two additional issues must be addressed, namely, the problems of
false targets and targets that fail to appear on a given scan.
When a
measurement is hypothesized to be false alarm, we obviously have no
state estimate to update, and thus cannot update the likelihood function
as usual.
A false alarm, like any other association, should increment
the negative log likelihood function in some fashion, or else declaring
all measurements to be false alarms would always be the most likely
hypothesis.
The
How then should we increment the likelihood function?
approach taken is to assume that a given measurement is a false alarm
This allows us to calculate our increment
with some probability Pf.
to the likelihood function as:
A(-log likelihood)!
= -n
false
alarm
Pf
f
(2.3-24)
(2.3-24)
-42Similarly, when a target does not appear in a given scan, how should
we update its state estimate and its likelhood function?
that no measurement is observed contains
incorporated into our calculations.
The fact
information which should be
For example, if a hypothesis as-
sociates no measurements to a target for many scans we would probably
want to delete that hypothesis from consideration.
Similar to our
assumption for false alarms, we assume the probability of a target being
missed on a scan is P , so that we have
m
A(-log likelihood)I
= -knP
missed
target
.
(2.3-25)
We update the state estimate of a missed target by running our Kalman
filter open loop, i.e., by not incorporating any measurement.
Now we can write our final likelihood function increment equation
to incorporate the above modifications
; T>2
false alarm
; T>2
missed target
A(-log likelihood)I
target j
time T
`
tn S(T)
2
T>2
' neither
of above
; T<2
--
(2.3-26)
We now specify the matrices in our general state space model
(2.3-1) and (2.3-2).
Target motion is specified by
xl1 (t+l) = x l(
1 t) + vxl(t)AT
Xl
((2.3-27a)
-43-
x2 (t+l) = x2 (t) + vx2(t)AT
(2.3-27b)
for a two dimensional position vector
xl(t) and v
v
(t).
(x , x2 ) and
corresponding velocities
Our state, then, is comprised of four components, namely
(x1 , x2 ) and(vxl, v 2).
Writing (2.3-1) and
(2.3-2) to reflect this, we
have:
1
AT
0
0
0
1
0
0
O
0
1
AT
0
0
0
1
x (t+l) =
(2.3-28a)
and our measurement equation is
y(t)
=
ElY(tX
1
y2(t)
(2.3-28b)
xl(t)
°
1
Vxl(t
+(t)
x2(t)
2
Vx2(t
where
(v1, v 2 ) is the measurement noise of our filter.
For our Kalman
filtering equations we set:
E(v(t)vT (t)) = R(t) =
1
which represents the covariance matrix of the measurement noise.
(2.3-29)
As noted
earlier, target motion along the two coordinate axes is decoupled, and thus
we can implement the above equations for each coordinate separately.
Finally, in Section 2.1 we mentioned that one of our hypothesis
formation constraints was that the measurement lie within a certain region
-44-
of an already hypothesized target
associated with that target.
(see Fig. 2.3-8a) in order to be
This is implemented by requiring that the
measurement residual have a maximum allowed size; i.e., we require that
we require that
V
T
-1
(t)S(t)- V(t) <
20)
(2.3-30)
where V(t) is given by (2.3-19a).
2,4
Results
In this section we describe our algorithm's behavior on four
separate tracking examples.
The first two examples highlight ' track
initiation, and involve a single target with noise corrupted
measurements and false-alarms.
The third example illustrates FIFO
expansion for two crossing targets.
The final example shows the algorithm
tracking three targets in a densely cluttered environment.
Before presenting the results a word is in order concerning the
examples,
First of all, the measurement covariance matrix R, was taken
as a 2x2 identity matrix.
Further, the data was generated by adding
fairly uniform noise over
-.5, +.5]
to each (x,y) position.
A maximum
initial velocity of 100.0 was assumed and probabilities of false alarms
and missed targets were set at .01.
Finally, only the five most likely
hypotheses were kept after each expansion,
i.e., the breadth of the
hypothesis tree was at most five.
Note that the theory requires a Gaussian noise distribution. Thus the
examples illustrate the lack of sensitivity to this assumption.
-45-
Example 1:
The first example illustrates FIFO maintenance with track initiation.
In Fig. 2.4-1 we have plotted both the measurements and the position
estimates of the filter.
The solid line represents the actual linear
motion of the target, while the dashed lines connect the noise corrupted
measurements.
Further, each scan consists of only one measurement,
starting from ml at scan 1, to m8 at scan 8.
Notice that on our second
scan m2 does not fall near the track, but is at (12.0 12.0).
from the subsequent data, m2 is clearly a false alarm.
As seen
In addition,
there is a good chance that on scan 2 we failed to detect a measurement
between ml and m3.
The results of the algorithm are exactly as expected.
The algorithm names measurements ml and m2 false alarms, and then picks
up the track at m3.
ml is named a false alarm because the filter re-
quires that a new target be followed immediately by another measurement.
The only measurement following ml is m2 at (12.0 12.0), but after a few
scans we drop the possibility of this track.
tracking our target from m3
on.
Thus, the filter begins
The hypothesis tree and the cor-
responding FIFO are presented in Fig. 2.4-2.
The maximum scan depth
of our tree is seven, and the maximum breadth is 5.
For the first
five scans we fail to identify the first scan, and thus the FIFO
grows.
At scan 6 we finally identify ml as a false alarm and bump it
out of the FIFO.
By scan 7, we have received four sequential measure-
ments approximately lying on a straight line, and thus we identify the
four bottom scans in the FIFO, including m2 as the false alarm.
At
scan 8 we identify m6 and thus reduce to a FIFO size of two scans.
-46-
-I
m8
I
8
7
6
5
4
3
2
1
1
2
3
Fig. 2.4-1
^'-----------------
4
Example 1
5
6
7
8
-47-
f
SCAN 2
SCAN
SCAN 3
m2
mU
ml,
1
ml1, t
I
I
I
I1
,
m<
I
I
F
C
3
FI
A
N
F
- -
_
F
0
I
A
~Cc
A
F
MNW
21
0
m3 i
m45
m4
Ir
3
In'
,
'I
Z/iA
I
M I
/I
"-h:
I, .k~
F
F
0
S
CICIC
.S
S
0h
.
SCAN 7
--
~ ~
~
SCAN 8
I
mS
~
6
3
IA
I
e
i
I
i
-
0 b&
~
II I
aA
'A
F
-
3
nn
L
41
!
I a
A
N
3
A
N
2
O = identified meas
m2 is a false alarm
'm ,m8
;m7:
m2im3 m4
10
, 7
N
No
I
'
7
t,
I
'
11
---
C
C
~ =1U'IN
"
S"
---- --- -
-
Fig. 2.4-2
--·-
I
,.,,-,
l~
'
-
m6
'm4 m5
3
!13
F
LLLLW1
I
351415 cl
NA
I
A IAI
INI
NI
IN
21
l
I
N INININI
_
-
F
AIAIAA
__
-
m24--
I
0 -
:
A
2
SCAN 6
im1
3
t 3
I
m
,
AA
~3
n
SCAN 5
SCAN 4
'
,,
I
0
I
1I 21
t
'
IK
3 I1
Example 1
_
-48-
Assuming no more false alarms
or missed measurements, the FIFO size
will most likely remain at two from here on.
In general, Fig. 2.4-2 illustrates a basic concept of the algorithm,
i.e. tracking conflicts can often be resolved by waiting N scans in the
future.
The FIFO grows until either the conflict is resolved, or the
FIFO fills, at which time the most likely association is chosen
In
the example above, FIFO decisions were never forced by the FIFO filling,
rather scans were identified on their own accord.
Example 2:
In our second example, a few more spurious measurements are included
to illustrate some other points.
Fig. 2.4-3 gives the-measurements and
the estimated trajectory of our target.
Once again, the solid line
represents the target's actual motion, the dashed lines connect the noise
corrupted measurements, and the x's are the position estimates.
scans except for scan 2 have a single measurement.
measurements, m2 and m3.
All
Scan 2 has two
Further, m7 and m8 do not fall on the track,
but are positioned as indicated.
Using a depth three FIFO, the algorithm
manages to track the single object present in spite of the somewhat
ambiguous second scan, and the missing measurements at scans 6 and 7.
Fig. 2.4-4 illustrates the FIFO maintenance.
Note that a depth of three
means that after growing to a maximum of three scans, the FIFO will
immediately bump off the bottom scan.
The third scans then enters into
the hypothesis expansion before the oldest scan is bumped.
scans 1 and 2 enter the FIFO.
Initially,
At scan 2, we hypothesize, among other
things, that ml has moved to either m2 or m3.
At this point in time,
-49-
12
measurement
- track
=position
estimate
_- -
10
ml ,
I j
m9
10
8
,.
m8 at(l.O 1.0)
le se
6
m7 at(40.0 40.0)
4
..........
*0-
e-
®® 0
· rem6
4
%m5
m4
2
0
2
4
Fig.
---
-----
--
6
2.4-3
-----·^---·---·--i-·1
Example 2
8
10
12
-50____
- -
-
:
:-
l
SCAN
SCAN 2
ml '
1:
SCAN 3
SCAN 4
m3
I
ml m2
I
I
I
m4
mlm2 m3
m2 m3 m4, m5,
m2
-g 4
i
I
1 -- 2
I0
I
l~z1
!
!
!
I
I
I
2
II
I
I
i
I
I
II
S
F 0
F
A
N
2
F
0
i
0
j
A
N
1
I
SCAN 5
Im 5'
m4
It
I
I
N
IC
F
F
A
N
0II
'C
A
N
F
S
S
F
N
N
6
5
I
SCAN 9
II
I
< 81
I
10--10-t0--
m9
1I
I
6
F
O
A
A
N
N
9
8
F
I'1S1sq
F
__
__
SCAN 1
iniOt
intIl
I
0 I
12-I-- 12
I
I
I
F
S
C
S
C
F
S |
F
O
N
N
F
N
10
9
0 !
Fig. 2.4-4
I
I
I
I
I
Example 2
1
N
F [a
t
I
I
I
!
S
sA
.NN
T ]
I
O = identified moeas.
m12 I
i
[
I
I
.I
I '0
I
12'
I0
I
10
I
I
0 7
_
I
I
sS
i
ImlO --iaI
I
13,
I I
I
mI
I
10 I
'-6 I
F S
F!
SCAN 10
mlO,
,1O
im9
Im8I
I
$7
I
I
SCAN 8
I
m
I
N
3
N
4
I
am7 i m8
m6,
°l IIcA,,,I IcI C
A
4
F
SCAN 7
01 7
F E
c
-
II
I
I
1
F c
O
a
I
,m6m6, m7II
mSI
I
I
I
I
I
io
Fo
0
III
I
1
s
SCAN 6
m6
15
F
S
C
s
C
I
'
I
N
io
$
,I
!
= forced decision
when FIFO is
full
m8
m3, m7
are false alarms
-51-
there is not enough information to decide which track is the correct one.
On scan 3, the FIFO fills up, but we manage to identify the bottom
scan, i.e., the three scans of data have determined the existence of a
target at ml, and we bump scan 1 off the FIFO.
At scan 4, the FIFO
fils up, and since the bottom scan is not identified, the filter is
forced to decide the association of scan 2.
Choosing the most likely
hypothesis, the filter assigns m2 to our target ml and calls m3 a false
alarm.
Scan 2 is then bumped off the FIFO.
At scan 5, another valid
measurement m6, is obtained and thus the filter identifies
scan 3 with our target.
and m8 respectively.
Scans 6 and 7 include two false measurements m7
Notice that as long as m7 and m8 remain on the
tree, the FIFO is force to chose the bottom association.
As soon as
m8 is bumped off the FIFO at scan 10, the bottom scan once again
identifies on its own occord.
An important point is brought out by
comparing the present case with our previous example.
In example 1 we
were never forced to decide on the bottom scan's association because
the FIFO was large enough
accord.
to identify the association on its own
In this example, the FIFO size has been
identification decisions must at times be forced.
halved, and thus
In many cases such
as the present one, the forced decision is identical to that obtained
by waiting.
Example 3:
The third example involves two crossing tracks.
Fig. 2.4-5 depicts
the actual track, the observations and the estimated track.
The in-
teresting aspect of this example is the method in which the algorithm
-52-
-
-
m19
10.0
5.0
5.0
Fig. 2.4-5
L___
il _ICI
Example 3
10.0
-53-
resolves the ambiguity of the measurements at the crossing point.
The
algorithm has no problem tracking the two targets for the first four
scans, however at the fifth scan the tracks cross, and either measurement
association seems as likely as
the-other.
As a result of the ambiguous
association, the FIFO fills up and we are forced to make a decision about
As soon as that decision is made, the subsequent scans,
the fifth scan.
which have already become identified, are permitted to bump off the
FIFO.
Notice in Fig. 2.4-5 that the algorithm resolves the fifth scan's
ambiguity nicely by picking the associations which fall closest to the
actual target motion.
A detailed description of the FIFO maintenance is presented in Fig.
2.4-6.
In this example, we use a FIFO of depth five.
The first three
scans fill up the FIFO, and on the forth scan we identify the two tracks
comprised of scans 1-3.
scan is can 5.
Refering back to Fig. 2.4-5, the ambiguous
Notice that scan 5 enters the FIFO and remains
there
until a forced decision is made at scan 9 when the FIFO fills up.
Further,
at scan 8 we have already identified three measurements subsequent to
scan 5.
What has happened is that the algorithm has easily identified
the measurements for scans before and after the crossing point.
The
ambiguous scan 5 is kept in the FIFO with the hope of clearing up its
ambiguity.
As the FIFO fills up before the conflict is resolved, a
decision is forced, after which the subsequent clear associations enable the tree to be quickly reduced in size.
Finally, at scan 10 all the
past scans have identified, and we are left with only the present
scan in the FIFQ,
-54-
|
~~~~~~~~~~~
I
qD-NN
I
0
In
o
o U
I
z
E
O-
tl
oII
00
I
I
I II
III
III
II
I
I
--- --
w-
- qlP
NN
£
nE
a,
0
9
N
t-
E V
m) ed_'~--·
.. )
o
It
\/
)9
CqJ
.
*
0u
I
I
I
--
U
o
o-
0LLo
z
c
O
--
-J
2.
(/)
:
"'
°-E1
0
U.
L
L.
-
EI
Ill
0
-
o
SeeI-1
0E
m
z
-~~~
CU
N
-
----
r
I
Na
.. I
Ea
iL~*
CU).
N
0
C)
U.
1
V
LL
I
-H
Iu
.H
z
E V
<
u>
o
0
C/)
I
-N
00El
F14
ll II_
I
I
1U)
E
2V
-
-
Cm
- 0-
£
E
C,,--I -
(a,
TI
n n
0
z
L.
I:
Ll.
0
IL
z
i
o
r,
2
0
-N
-
IL
L.
cli
,)
(7
vn
l
U)
ui
,~~~
t
O ___S9_
-N
In
-----EE)
I---
0
N
_r
E
cC
I III
III
I I
I
I
I
_
I
_
____
_I
E
___I
I
I_
_
-55-
Example 4;
The past three examples have illustrated the problems of track
initiation, false alarms, and ambiguous decisions.
In the final example
we illustrate multiple issues by considering a dense, three target
tracking problem.
In Fig. 2.4-7 we present the raw measurement data as might be presented to a human observer.
moving upwards with time.
Each scan has three measurements which are
It is clear that a visual solution of the
tracking problem in time is difficult.
is at scans 4 and 5.
One of the biggest problem areas
The measurements are clustered so closely together
that the incoming targets could take any of the outgoing paths, which
are themselves unclear.
Fig. 2.4-8 gives the actual track and and the observations of the
three targets.
Two targets are moving at an angle to the right, while
the third travels directly upward.
The observations have been obtained
by corrupting the actual tracks with noise, which clutters the picture.
Of course, the actual solution of the tracking problem in 2.4-8 would not
in practice be known to any observer or tracking algorithm.
Fig. 2.4-9
presents the tracking results obtained from a depth three and breadth
five tree search.
As can be seen, the algorithm correctly associates
each reasurement without getting lost in the crowded area around scans
4 and 5,
algorithm,
Because of the smoothing effects of the Kalman filtering
the estimated tracks are closer to the actual tracks than
the new observations.
In Fig. 2.4-10, a similar run is shown with the same data as before
but with a FIFO of length one (i.e.,
a depth 1 search).
Because of
-56-
Scan
13
27
26
Scan
12
24
Scan
22
Scan
20
10
10
18
Scan
9
16
Scan
-
* ·
0
Scan
7
Scan
6
14
12
Scan
5
10
Scan
8
6
4
2
n
.
Scan
·
4
0
e
2-
Scan
~
I
*
I
2
3
Fig.
I_
_________
__
__111_____1_·ls______·P___Y
l-I1IS
2.4-7
4
5
Example 4
II
--
-
6
-57-
2
2
2
2
*
2
1
1
1
I
11
II
I
¢
1
2
3
4
Fig. 2.4-8 Example 4
_RI_(_I______________1
5
6
-58-
27
26
24
22
20
18
16
14
12
10
8
De pth
6
0
4
0
=
Breadth = 5
2
0
4
Fig. 2.4-9
____________________________
__
Example 4
v
-59-
27
26
24
22
20
18
16
14
12
10
8
Depth = 3
Breadth =5
6
4
2
0
1
2
Fig. 2.4-10
I
4
Example 4
5
6
-60the constraint on hypothesis tree depth, a decision on each scan is
forced immediately after it is obtained, and thus the FIFO always
shrinks back to empty after each scan.
in initializing the tracks.
rectly assumed.
were forced.
The problem in this case was
On the first scan three targets were cor-
However on scan 2 decisions on the targets' whereabouts
Any decision without at least a third measurement is com-
pletely arbitrary, for there is no velocity estimate at this time.
a result, the algorithm in fact crossed two of the tracks.
As
From this
point on, the track estimates had to reverse direction to pick up the
measurements again.
It happened in this case that by the time the esti-
mates reversed direction, their original targets were close by, and thus
the initially erring estimates ended up on their original tracks.
The
single scan run is included to point out the necessity of an N-scan
approach.
It is of course impossible to portray every different kind of
situation in a small set of tracking examples.
What we have attempted
to do here is highlight some of the basic properties of the algorithm.
Clearly, more extensive testing and development would be desirable..
-613.
SUGGESTED FUTURE RESEARCH
Clearly, the adaptive hypothesis testing technology used to construct
the multiobject tracking algorithm described herein is only in its initial
stages of development, and it has an extremely broad range of potential
applications.
Consequently, there are a number of extremely interesting
directions for future research, some of which are briefly mentioned.
The most direct extension of the work conducted herein would be a
more extensive testing of the algorithm.
only on a handful of test cases;
The algorithm has been tried
more experiments should be carried out
to collect statistics, observe the effect of changing various parameters,
and determine the computational limitations of the approach.
A priori statistical characterization of the performance of the
algorithm would be desirable, but is quite difficult in view of its
complexity.
However, it should be possible to analyze certain simple test
cases; if these are well-chosen then the various thresholds in the
algorithm could be more systematically specified.
An important issue is the track versus measurement oriented approach
to hypothesis generation.
It isn't completely clear at this point
exactly what the tradeoffs between the two approaches are.
the
More generally,
use of efficient hypothesis representation in adaptive hypothesis
algorithms is basic.
These algorithms have memory, and thus have an
associated state set, but the structure of this set seems to dynamically
change in a data-dependent fashion.
Perhaps the most interesting direction of extension would be to
generalized
the algorithm to accept
addition to continuous-valued position
discrete-valued information in
information.
LISP is well-
-62suited to such a task.
Such an development would greatly extend the
range of problems to which automated tracking algorithms could be applied.
-63APPENDIX - ALGORITHM DETAILS
We present here a much more detailed account of the algorithm
described in general in this report.
Our aim is not to comment on each
line of code of the program, but rather to discuss the input/output
characteristics of functions which make up the major blocks.
As mentioned previously, the algorithm naturally divides into four
main blocks:
initialization, hypothesis generation, FIFO maintenance,
and hypothesis merging.
We discuss the makeup of each block separately:
INITIALIZATION
IN IT:
Before calling the tracking program certain variables must be
defined and initialized.
The "init" function handles this.
The following
is a list of the variables defined, their descriptions, and the default
values set by "init".
1.
prunefactor=2.0
.
this is used in a second pass pruning after FINDNOD.
surviving FINDNOD whose
(-) likelihood values are greater than "prunefactor"
times the minimum (-) likelihood hypotheses are pruned
2.
All hypotheses
out.
markX=t
these are flags which determine whether certain variables or trees are
to be printed out during a "track" run; if set to "nil", printing is
inhibited;
3.
if set to anything but "nil", printout occurs.
mez=O
the total number of measurements input since the last "init" call.
-64-
4.
nnumb=0
the current node subscript for the nodes in the hypothesis tree.
5.
fifoscans=(0)
a list whose elements are the last measurement subscripts for each scan
(e.g. (4,2,0) implies that the FIFO contains 2 scans with scan 1 = meas's
1 & 2 and scan 2 = meas's 3 & 4.
6.
terminals=(nO)
a list of the terminal nodes of our tree.
Initially we include only the
root node nO.
7.
n0=nil
the root of our hypothesis tree.
It is initially given a likelihood
value of 0.0, and assigned to measurement number ('meznum) 0, a placebo
measurement.
8.
conf=nil
a list of confirmed targets
9.
scanmax = 3
the maximum number of scans allows in the FIFO.
10.
R=2x2 identity matrix
the covariance matrix of our observations.
11.
Vmax = 100.0
a maximum velocity allowed for initializing targets.
12.
gate=5000.0
the n of equation (2.3-30)
-65-
13.
keepnum=5
the numberaf the most likely hypotheses to be kept by FINDNOD.
This
value sets the maximum bredth of the tree.
14.
Pf=.Ol
probability of a false alarm
15.
Pm=.Ol
probability of missing a target
16.
keepnodz=nil
the terminal nodes kept after FINDNOD
17.
nodzprune=nil
the nodes to be pruned out after FINDNOD.
Note that variables 1,2,9-15 can be set to the user's desires.
In addition to setting up the above variables, "init" calls two
functions:
(initree 64) and
(initcsf).
The former erases the property
lists of the first 64 nodes of the tree (if more than 64 nodes were used
on the last run, (initree n) should be called manually).
"initcsf"
initalizes the confirmed states file.
ASSIGN:
After calling "init" manually, the processing of measurements is
performed by (track).
"track" serves as our main control loop.
The
very first thing we do in track is assign each measurement a measurement
name of the form m..
The measurements are (x,y) pairs and are stored in
the variable "data" before calling track (see the section on Usage).
-66-
If no measurements have been set up, we abort, else
(x,y) pair the name mi
ASSIGN assigns each
where i is the running count stored in "mez".
The final value of "mez" is then the total number of measurements input
since the last "init".
HYPOTHESIS GENERATION
FINDNOD:
"findnod" is a recursive program which expands the hypothesis tree
using branch and bound techniques.
"nil"
The variable "terminals" is set to
before calling "findnod", and is updated to include the new terminal
nodes after expansion. "findnod" is called with the past terminals as its
argument, for we expand our tree from the old terminals onward.
Before further discussion of "findnod" we must discuss the implementation of our hypothesis tree.
As previously mentioned, a LISP vari-
able can be assigned properties, which in turn can be given values.
Each
node of the tree is a variable called "ni" which has a "branches" and a
"parent" property.
The value of its "branches" property is a list of
nodes which are its direct descendants, i.e. a list of pointers to
children nodes.
of the node.
Conversely, the "parent" value is the direct ancestor
With these two properties,
each node has forward and back-
wards pointers which allow easy bi-directional traversal of the tree.
A representation of a general property list is given in Fig. A.1.
We now describe the various properties and their values:
1.
branches: a list of direct descendant nodes.
2.
parent: the variable name of the direct anscestor
3.
target: a number representing the hypothesized target of
the node.
-674.
meznum:
the measurement number of the node (each lvel is
assigned to one and only one measurement)
5.
likelihood: the negative log likelihood of the hypothesis
This value is propagated along the hypothesis branch
during expansion, and is finally left only on the terminal
node of the hypothesis.
6.
states: a list giving the hypothesis' state and covariance
estimate for each target on the hypothesis.
((targeti (estimate))
(targetj
The form is:
(estimate))...)
or
((1((XlvxlYlVyl)(PxOOPx01oPx10Pxll) (Py00Py01PyloPyll)) )(2(...)))
Which says that target 1 has position and velocity estimates
(xl,Vxl,yl,vyl), and covariance matricies for the x position
is:
xO10
and likewise for y.
Pxll
Like "liklihood", the "states"
property is propagated along during the "findnod" expansion
and is left only on terminal nodes.
7.
tentatives:
branch.
a list of the tentative targets on the hypothesis
Again this is a propagated property which ends up
only on terminal nodes.
In addition to those properties which are always present on the tree,
some properties are created and erased while implementing various
functions.
Because of their transient nature they are not discussed
here.
We are now in a better position to describe the expansion of
the hypothesis tree.
To expand from any node we must decide how many
-68-
_W
I,
*cn
clJ
o
0
I,-
to
-.
°
Z
W,
F-
C,
om
pi
IJ
a)
-0
cn
E-4
o
*0
0
0
I
'.
I.
..
--
W
r
a)
wu
o 0O
-O
0
ow r:.a
0O
.-if,
z
I----1----I-- C
C
t-IHX
Q
4
Nu
N
x
w
C
W
w
r
I4
(A
(4-
0
0
0
C
tm
r_
0
C
0
-6
c
C
0E
m
z
w
o_
C
C
0Z
cr
z
II
C
0
I
t
z
__
Cm
C
mo
mL
I
__
·rH
44
U,
w
-69-
nodes to branch to.
We decide this by creating a list called "possible"
which contains all the confirmed targets, the tentative targets of that
a new target, and 0 (a false alarm).
hypothesis,
Those confirmed and
tentative targets which have already been used on the branch in the
present scan are then deleted.
The resulting list then represents the
possible targets which occupy the next level of the tree.
For each
target, we create and branch to a separate new node, while listing
these nodes on our "branches" property.
For each one-level expansion we
call the routine "kalman" which updates the targets' state estimates
to account for the new target-measurement association.
We store these
updated estimates in the "states" property of our new node.
If the
(-) likelihood value of any of the new nodes exceeds the maximum
(-)
likelihood value of the present "keepnum" most likely hypotheses,
then we stop any further expansion from that node; the hypothesis'
(-) likelihood value can only increase and thus decrease the likelihood
of the hypothesis.
the tree.
In this manner we inhibit senseless expansions within
The halted node is added to a list of nodes to be pruned
(nodzprune).
When we are done with the expansion, the "keepnum"
most likely hypotheses are left on the tree, a list of which can be
found in both "keepnodz" and "terminals".
Having now expanded our tree to account for the new measurements,
we erase the nodes to be pruned by calling "pruneout".
"pruneout"
deletes all "dead-end" nodes from the "branches" property of live nodes
and de-allocates the storage created for them.
then performed in "threshprune".
A second pass pruning is
"threshprune" prunes out all of the
-70remaining hypotheses whose (-) likelihood values are greater than that
of the best hypothesis by a factor greater than "threshold".
Finally, we must recognize any newly confirmed targets which may
have resulted from the above pruning.
A routine called "confind" checks
for confirmed targets by at each level of the tree seeing if all hypothesized targets are identical.
If so, that target is a confirmed
target, and is added to the "conf" list if not already there.
After
finding the newly confirmed targets, we must then go back and delete
them from all "tentatives" properties on the terminal nodes.
Thus ends the expansion block of our algorithm.
In summary we
have expanded the tree, pruned out "unlikely" hypotheses and propagated
up-to-date state estimates.
F IFO MAINTENANCE
In this next block we maintain the dynamic size of the hypothesis
tree.
In maintaining the tree as a FIFO of scans we must bump the
oldest scan off the FIFO in two specific instances: when the FIFO is
full, and when the oldest scan is identified.
FIFO FULL
The FIFO
(tree) is allowed to expand such that it contains "scanmax"
number of scans, but as soon as it does so, it bumps the bottom scan
off the FIFO.
We check for the FIFO being full by checking the length
of the list "fifoscans".
As mentioned, "fifoscans" contains the ending
measurement numbers of each scan, and from this we easily infer the
number of scans in the FIFO.
three functions:
If the FIFO is full we call the following
-71-
1.
CSF.
This routine updates our "confirmed states file".
Remember, the confirmed states file stores the state estimates
of all confirmed targets at each time the FIFO bumps off a scan.
If the FIFO has filled up, then the bottom scan is probably not
identified and we must somehow decide which confirmed targetmeasurement associations to update the CSF with.
This decision
is made simply by using the association of the most likely hypothesis.
Using these associations, we call "kalman" and update
the CSF in a similar manner to updating a node of the tree.
CSF is itself a tree of breadth one.
where i corresponds to the scan.
CSF tree
-
(tree).
C3
C2
C!
)'-)
SCAN
BUMP.
Scan i has the node in the
The CSF thus looks like:
(( )(
2.
The -nodes are names "Ci"
(at level i), and each node has its scans' total
state estimate.
Co
The
(( )(
) ...) - - -
SCAN 2
This function
bumps the bottom scan off the FIFQ
It does this by changing the "branches" property of
the root node "nO" to include those nodes beginning the second
scan in the tree.
It then de-allocates the memory assigned
to the first scan.
3.
CLEANUP.
Bumping a scan off the tree may delete the
occurances of tentative targets on a hypothesis branch.'
"cleanup"
-72-
traverses through each branch of the tree, creates a new "tentative"
list for each branch, and stores that list on the "tenatives"
property of the associated terminal node.
In sumimary, upon detecting a full FIFO, we have completely bumped the
oldest scan off the tree, and updated the CSF.
BOTTOM IDENTIF IED
After checking whether the FIFO is full, we can now see if the new
bottom scan is identified.
and then bump
1,
it off the FIFO as well.
BOTCHECK.
or not.
If so, we want to update the CSF for this scan
This function checks
if the bottom scan is identified
As defined in chapter 2, an "identified scan" is a scan with
all "identified measurements".
Further, an
is a measurement with one and only one
its level in the tree.
"identified measurement"
target assigned to it on
BOTCHECK then checks each level in the
bottom scan; if each level is an "identified measurement"then the
bottom scan is identified and BOTCHECK returns true (t);
then it returns false (nil).
if not,
If BTCHECK return nil, we continue
on to the hypothesis merging block.
If it returns t, we bump the
bottom scan and update the CSF by calling "CSF", "BUMP", and
"CLEANUP",
exactly as we did when the FIFO was full.
We then loop
back and check for the new bottom scan to be identified.
This way,
we bump off as many bottom identified scans as the tree has.
-73HYPOTHESIS MERGING
MATCH
Our final block's purpose is to trim redundant hypotheses off the
tree.
As discussed in chapter 2, some live hypothesis branches may be
identical due to past differences being dropped off the tree.
hypotheses can be either "exact" or "1-1' identical.
Identical
"exact" identical
hypotheses have the exact same targets along their branches.
"1-1"
identical hypotheses differ only in a 1-1 renaming of tentative targets.
In the present block we first identify the groups of exact identical
branches, trim all but one of each group, and then do the same for
1-1 identical branches. The main control function for these processes is
the function "match".
"match" and its subfunctions represent a substantial
amount of the algorithm's code.
EXACT
Identifying identical hypotheses is done in a multi-pass method.
With
each pass we reduce or subdivide lists of possible identical hypothesis
using some criteria for "identicalness".
To find exactly identical branches,
a two pass method is used:
PASS 1: TENTAMATCH
For branches to be identical, they must have the same number of tentative targets.
"tentamatch" creatsa list "matchlist" whose entries
are lists of terminal nodes which have identical numbers of tentatives
on their branches,
PASS 2: EXACTMATCH
Our final pass, "exactmatch", starts from the terminal nodes, and
by traversing the tree one level at a time, reduces "matchlist" down
-74to include identical branches at each stage.
When the root node
is reached, the final list, "nextsame" contains lists of exactly
identical branches.
EXACTPRUNE
Having grouped our identical branches, we trim out all but one
hypothesis from each group.
Since the hypotheses were spawned
from different origins, their likelihood values will be close,
but not exact.
smallest
We keep that branch of each group with the
(-) likelihood value.
This determination and the
pruning operation is performed by "exactprune".
1-1
IDENTICAL
Finding and eliminating 1-1 identical hypotheses is similar to the
method used for exact hypotheses.
Our goal here is much more difficult
howerver, for we must find hypotheses which are exactly identical except for a one-to-one mapping of tentative targets from brench to branch.
To avoid an exhaustive brute force approach, a four pass method was
used for determining our 1-1 branches.
PASS1: TENTAMATCH
As described above, "tentamatch" creates a list "matchlist" of
groups of branches with identical numbers of different tentative
targets.
PASS 2: ELSAME
This routine subdivides "matchlist" into a list "nextsame" containing groups of branches which are identical except for their
tentative targets (i.e.,
identical confirmed targets and false
-75alarms are in the same levels).
PASS 3: SUBFILTER
"subfilter" subdivides "nextsame" into a list "nextsame3" containing groups of branches which have the same number of occurances
of individual tentative targets (e.g. if hypothesis n7 has tenative
targets 18, 19, 20 with frequencies on its branch of 1,1,3 respectively, and hypothesis n8 has tentative targets 21,22,23 with frequencies
of 1,3,1, then n7 and n8 would still be grouped together after subfilter).
PASS 4: FINMATCH
This subdivides "nextsame3" into a list "finsame" containing the
1-1 identical groups of hypotheses.
EXACTPRUNE
As described above, "exactprune" prunes out all but the most
likely branch of the 1-1 identical groups.
Finally, after trimming the tree of redundant hypotheses, we call "confind"
to find any newly created confirmed targets.
We then loop back to the
beginning of our "track" control loop and check if there is another
measurement scan to process.
PROGRAM USAGE
Running the tracking program requires minimum set-up from the user.
Here we outline the procedures for processing data:
-76-
STEP 1: type "(init)"
this initializes the environment and sets all parameters to
the default values listed above.
At this time, any change of
parameters can be keyed in by the user.
As described above, if
intermediate print-out is not desired then typing "(unmark)" after
If more than 64 nodes must be erased from pre-
init is necessary.
vious runs, "(initree n)" must be typed, for n equal the number of
nodes to be erased.
STEP 2: type "(setq data(?))"
We must set-up our measurements in the list "data".
"data" is
structured as follows:
Each measurement scan is a separate list in "data".
A scan's measure-
ment list in turn is comprised of the (x,y) measurement pairs; e.g.
if we wanted to process only one data scan we would type:
'(((1.3 4.7)))).
'(((1.3 4.7))(7.4
Processing two scans would require:
12.3)))).
(setq data
(setq data
To generate data following linear motin
with superimposed noise we use the "line" function:
(line 'x 'y xslope yslope)
which would increment x and y by xslope and yslope respectively.
The output is then an (x,y) pair containing the new (x,y) with noise
uniformly distributed over
-.5,+.5] added on.
Thus, for (x,y)
initially (5.0 7.0), (line 'x 'y 1 2) would give us ((6 + noise)
(9 + noise)).
-77-
STEP 4: TYPE "(track)"
"track" processes the measurements in "data".
A list of control
messages and the targets for each branch of the tree are printed
out.
GO TO STEP
TO CONTINUE ENTERING DATA
GO TO STEP 1 IF A NEW EXAMPLE IS TO BE RUN
4
ti
-78-
:; t'1::, :,
d.i;.?:. ii ' (:, ,:i
i.:.~
I:.! .
:-- : ' i
.i i.
eiZ(:.-
:' :"
A.
)(,AMPLE
R/v'
:i . . i --
S:·r',c
~,.e
!:1sl 'be
i:;",',
.- ,
l[;
i
i
e
II,. ' . 't'
'".I-.
ii((10
o.
w~r'~y '6.:, ::·i'
msv[-:
.:1
c, :{...........
i ':C,... :in
a, f
b1]. 'i:, t-:-,l
A ,
:.
.t;;
i>
:r'§
dr':'il;
.
'
j..
':.
b -It'i, l.
Pvri;·r'b----ou
o',' ', l T 1''§
l uo', i'fi
'I:,, l , -,lot,:.
''
tt.';'..:..I" i ie '
. i i-.
:.. t
---
'' 0
'- ... ' -
-. 0
e'i 0i ;:....
1,
(
.v el
!
ttrj.--,>""' w0 I,';!X-r.
u,
"
'
.i
'i~~~,
At.*$c.Aj j 'o
'' ].i l
I
'.
e
''
r-:
Lhe4
i
,i
n,si
i
i f' s' t
---
di
....>
"i Irl;..
"i:.:,f' u!"~ u. :r :i.:l
e r.u'\\ t..:(Ii- 3.:i.¢.>
( Ii :i.J s. LL t:!. r'~,:: ".
J 'L (., ,:...',t',
J . %
_
0i 3 0
'
't'~ee.:.:~'
466666
1.
6
0.6
F
oi
i ? 'the
i.:0).)S)
, :.':: c.r' s .-I '
jj 'ir'''i;¢fl
i
a'..!'.!
J
fs,,,:.
('
-
0
,:-'z,..
: i ,? }¢7
"'D.;;
'
/':.
!
J
J.
))'., ))'
d
C
-79-
(((
..!
0 ,-.0.98"
7:S3 )'
))
te
v'K..:.c.
i.>c set.u
"e
t=
!now
'e.d'.i
:.c:,r"o~ess
( :. r E'
i.
o
i
i;
re
l i
(n 0 · ·
+ 4 ' i
r : t..
J. d:
trt :i. ei
j
d
i e 'rU....
((4
0:B.3'.4.':;,;
T0)
(().5:4:~:-::3
()o9E4·
(4 3
+
4
4
7
0;.
70
-
ile 5 li.vin:! . t ,.ck
t 4:'re
7.t the
'- ;,,ee.
te
te s
;.'.:i
l
iind .
.
vale:
;,' "o1
ode'e ec c
be-.tween
; IeJ f.>renitl
, ' ,e iF b
h : '- .
(e<
eC
iv
o
reent.
.
the
i.
't
"-..."
"
t-.:,
"ee
.
-80-
..:..!................. ..................
"-
.*~c!
__ _*.+,,
,+_....
.,,* ~
.............
...."...i,,,
, e _ :,........
'.
!.......~.,....
_t~
. "
..·
t i i ', : i t.
at
'
Fi ilii; i.
Cj,
I
' ';
' i
cTCCii
ii
.3 j
1 i
. i ): i
;
,)
1vi
.I, i .
i
- J.
f':,
i,':.
1;
.S6 { 1 J
('
5
1 '3:i.'..
i li d
0o0 r(.
.: t t: .' r .i ..i ' 1 e4
-9j
(: 3
.(:-.,' im~~i....
._...._ .......
.......
..............
.._......._..
.-_.
_
:..o-.:
..
_......................
....
L7
.,
0 (i
C:1.66667)
T +-
1 ++ + .i + . +..
r '.i.
s.0
i
,r.n
..
n
00
'
.{:i4.n
'CF
-..n
+ ++ + +(2o:L5
+ -, + +..+. +
+ rA L
.j, .. r
i + :. , ++++I
,-jo8:L66I67)
+.' 3.."
2,
........
,
C,0)
+
:
+-t+++++++.
..
+++
n 1i ) e
.
':.;.)s j; ; .? si
;ryO ,
"
!
:.
2
;i
? .:.i iJT
:.
,': T
it
9
i
.
.
-81-
Y~~;I
\
.....
:tl
"- rO r;·
)
(se s:;fr; -. '4-
ii
s
r
.
1
3, )
Pset
,
I 0E
tLI0
ir'..
t7 $,,
,1
Nr.,
4
-(s-tci
-
.C'
?
(',,ta".:: r. :.
. .'ti 7r_
S
(str,,t t
%
S
( t .
V/
iir,
_ P
W.cr¢rrf,
-
tu.,
i
)5
n
¢
nil
ri
t: .'Z
f
'i
Li;
"I
if·~,'.
L nt.7
-
756
-82-
(
Cs
Tecl
e s
t([r~oS_:'
3
''
·
.1
F
rvLr . 9; .ri}
'wtt.i .: C
-. ' ifl;}'r
,s eta ii:.
c,
nI '
.
~
-- '
.
''
,(Fr;.
(set
_ Ei; >
,, 5~.
I
r j' ' ou
' . e.is
,(.~9;d
- i ;:
.·7
(s'eto
:.:k
(an d (not
fiiA'f"Z
,I i !-'"
Ct_.is-l t.....
r' -- . '
(tf;t
irct' .i
cc'i(l
'':-:.,}
s
-
,'
'"i
"' * r',I
f,(eir!d
'1u
b---
W.
: i
,.:'-ioi.
'b1sach
, es)f
;
f
..o.i
i.d
;9
z
,t
0.
i k .
.'
ts
.'".
ii
iftdet
W- i
'dPr
(;:..:,;
''
( .. su i.'*, (eet
, fi.....
._
((eou_:.l
se.,
.i..'d 'j,,
l~. . :'P, ,..;
(bu~:t
,rfti
C,;
,
'n
.~:.t.t-f
,-, ,
f
:
IC
*
,!)?,,
:- t'i ....... j
.-
S
:::s
..
si.f
:lil
I
:¢
--
-83-
':i
_ tr e<
i.at..:,'
+ 4i._-.::[i
..................
ir
t.
',
;F;rr&
'"
'.*
....
.
t.nf
.
;
I$,
r ,-E(, , ,
,EEfi
, ;,, ;,; i
i .I- t 'i ; e
EFiT5
;?;Ixi- -; -I~~t.l·;.tt.
i
r iit.;
;;z~
- -;---.--- t~~~~~~~~~~~
i s et.~
.....
.
ir'i.,Z a;-.';, t~;
,''
', :'..e' .'''-',s:
'"*sl--------·--·ll--
---
·
-
--
-84-
Ir
s r-I
E
:. I
e
.
,.n~:,-7:-
~
411Z'
1
?7-_
-
i_.L,.'
:i
;;t;
.
+
;;
1
f
'.
rF5t-
t·
i
¶
.F .
rrSW_\;-
.-·
--
,
i '! ¢_1
..
-: .
Ii
1
:ci15r4''
.
.t .(t: ";-t.:
.F..
ii
"-"'.'
':
.'
'
<n,'.;
,;'---i
., I,.
,[_:tfc.-+
"
',,-' ''-:..=r ,r'.
i .:,s;
:,,_
_,t
_ ,-;'; tF:F r,,i.,-,,,u
(.,, .r:
i
. r
.'Frit
rrn
st
.
'
,
)
I'1in
intiri
: ,t
,i
.'oi-~il.tI-
'!
..':).'
1
ii': r ..
'-rir~f.
:
t;i· ?;.::
i
~;-
l_s_s
-·lllrC -----
__I--
'-,C-
I
.l4)
i, ,
i .'):
:
:I
I'
; '
;x --;:
i
(~-'~qt
5 r(tii.-'t
i ;:'r:5
-
'
...
"-..
;
---
--
4
;
I 1l / i .
P
7."
'7
I
-I i-
-i
,;.
-85-
'
,:.
E
Ix
p,.Z-
SA
('.Ad:,.]
["..-.F;Cd
(i:
q
X _
f.-
2
,'
,
L__
L'd·- T
( ?. nt
D'i
t.-
._
_
t
~
P.
55
bu
i---
r tt
':-. X,'.::
'i. ":..ra'* C]_ '-l
-,
-t
-----~
I.~
~ ~ ~~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ----
-86-
t: 4
J
(furI~~{..
·C
oin1.d
(t
I
- r. ~L i tv3. -er
,;
in-,r
(i n
X9;rr:-o
'tI=
r't
J
d
trtex
,"e
ciKt
.fr. "C¢'-V~
U(c
(f ,ff:f!
rf
CI
iCI
, Ii : I
ar.
·{- , '...t.~'
-i-.'.;
.'
-
(ist :
r
(tri
;V.- )
-4
-s
drs
.
(<i~$<r;;li
tr
U':-
' )
'
er
"'
, n't .,a
r,~-
.1.9
I_
';
d
- i;-;j, )
3
-Al, a
I-
-87-
·
~i· --
~.q~
,,.f~ rnF
.
I"
r : ,,'
.: ( ,t.c::.
- K
r
t'Sr,
,t'f
1 1 i,
::l
__
t ! ,;
! .r ' .- . !ri F=
i
.:t
r¢.- - Czi u-i :
',:
; .4re' ,
,' s - 1
ft
d ('
d(,fr..Uttrj7
f.
;-.rru¢'
,
_ig']7i
.
'-----ar-----r--3
l
ll.l
i,. i-
'7.
III----·-----·
i
?-*-r
+ i1i ,-r
**, ?.I ;
r,,; i'e
l_.X¢l
i•e(
d(8(
.
.
I
i 'eir. ,C(c;:..__
F \u,_ c.t
.,,r
,('j~r,:e
,'
,:!i;-l (C07;S
t~'rt
-,
! ?
'
f>
f..
^
)
Tor
tt ,z )
r.
i
4,
'.
..
*
ri'
,,i
i.
x ./~
--
---
..
·
-88-
17
'((:.::,
_t,
t i
s.
e
(
:rr':=:
",
.,;en
iti (:at lnil))))
rr~,
-¢~:t-i t:.r
!
it; F
(,.::
;:
et frf,isea.O
-
vfC
i)T
,
4
.
~--c>' e ) rure
' f: : '7 .-.4:P;r ,(x:e I,.I
u
".
ist
u!a
P -t
'
cr
_.).)
2...
.
Ice
( . . .,) E
'U<.s.
,
_
*
t_
,n>j{',,. (.f_'t'i
'r'ieri[:."s
Ss',i?-jlq
( i
: o,',,
s-:t')'llfri?-''
/
$.l i
I-
- (C'SP
?", ti-,:~,c
(I(st.~-··-'
t_7F'j
t F.
er'OP
j
So
..,if
1sk i.
i' .
tC t,
f~
(dF~f~s~i-is'';l,
...rt;'":)r·l
:a
--
:.
-~
7r1)
. ' nil))
.C. - ;i
r';
:
r,,.
lif-
t]
~"
=-CP--
---
--
---
·
-89-
!.
'r:.. ...hZ"
(..et,
?
*
Y
se..I
-t
:"~'i;.
xse;G
RruriHE7
u1e Zn.
S st~~hz)~~' ets)
(CL'.d (r
fLs~ist.
"-".,_,
(sete runfl~
If5.i:-1,
nil )
jm a . i c
=hLf.5@.
_ iti>W
ist
(i r
cum'e
'IJr
r ie:
i,
C
r
o
(SE+.3 PNOset-t t))))
''
' S Z8. )
f. c,.CA.S mrCur~f 1.s
(;P-utP.
)
Source
'derd
r'IC
Csetn(fl
O
1i
(t (.utproo source
q (..
Nrid re!r (ke
eitd (or (t
( bSt L,tl.:s
i
15 io
.s.;.h rsource))
rie~
'
s OU:TcE e e .'-Z
-?
c:.-
). '...) 0 ,)
'(stll~r
;!.
r1|nj .......
' z(~t"rs7
:-"4
(sero
'X ss~
s
;
li .'s4l3
-X
,,r
(
-orz
: ,"':;"
C
-
sli
tc . n-v
il
,;a-~
, ..
( ,
(c...
,
)
E-.
, i,
,eii;.--I
f-:n-'r :
(B~o
1..r. ti '.u:,
. --
.
J
Er.-
.
,-
(iJ,.::.
-:."r
::O';T~
Iz
r(X
.
:a,)
rI:ZrO.e
_~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~,;iz
-90*at i
F.>i ,
~ ~ .2i
!~.~.
-~
l
;,
aar------
.
..
;
.
1
. ;! ,
}s
ij.
-I-.
L:·-· -;;··--;·----·-_---·- ·
I --·:---·- -:_----
-91-
g
r.
IiEt (IEj
"-'.(i-f'
.
#
;
e- :4
-.
... 1
.
;
~'..ii
Xx4
.,
(.r il .
*(- f i !.. ,t
c
- -r
t~ .i;....
,
f_~i:_I
w ;:
'R.
, I
7---------
1--·
-; ) ii -
-
fr
t
(',
-~
,
.
·,,e
(
r;
'-~· _ ·
.
.
.i. ..
..
,;..
.
'i
'r,{ r
.
\'.
i,
.
r;
...
.
.
~
;
..,or'.;
.'
. r.
~
s
;8,
,r,*s-t
't
:-fel_
-.. >v
11-·11le
·---------
---- I
------ra
--- --
-1-
--
x·-- ,m;
-92-
-- -.
Z,'.aPF'~:s
f, i, ..I
2
-.,p:
f.,
{,
1
s. Foi fnlrfil!
i'P'?
t
F' . f>'
{.,t~t*-l;-'';n
41~t
-.
(F
-PII
; . ) ,, l
-A
9.,gi3'
{'i-t'
av
I'~. -I5
r
T!t
sour(..S..,
*£- .
f
:
s
-
r
ist'))
,± ,h.
-(c-V
L
r'
sf'-'
r fl
(,b
,il sI )'S
,
S
- -·-·I
---
·-----
..
-93-
,,
:lkre (stn Ee i~l
,dfu
co3st,
~
(c!ism.
:.'t.bst nilt
t
t. (.
t . E, _
'4eC
nil
'sties))) ))
'rew)))
corn; ((e¢.l (cedr l)isti
(t rrs.uP .. :is't
(Iist. (f+(X 0) (X 1))
(X 1t)
i+$ (X2.,) ' 3,1
(X 3,)))
(set.a Xnr:
(set. Pnew
0. 01t
(list (+ (PIt
(71I. I ,)
(?' I 0)
(Pi 1.
r'* ,1
(P,
(
1ti
n t Li
1,')
(r
*
, 11
(PI1I:
))
(set.a P2iew
0. 0)
0, I,)
1. 0i)
1, 1.1))
0. 1.' (P2 I. I,))
1, 0.) (P2 1. 1,))
1.))
(list (+$ (P2
(P2
(P2
(P2
(+$ (P2
($s(P2
(P2 1
t (c;
(st3tco:s
list)
(subst nil
(list. Xnew
Flnew
P2,,,-,))))))
Xrw
p-ta list '.r Y) 0.0 (c=dr Y) 0,0))
'r:ews})'
t
F....,'iAt
f! I
z
('-tQ S: . 1li
( --.
E t'liStC-Y
(list
'lt (et. source 't ret) slist))
Et (>t s Urcs)
S e
,-
(to
,=.ic
tost
liston-)
(F'Ut;'~ sou.rce (Ubskt
·I_
__=
nil ril
C·
slistc.o.))
(listt
slltC¢~-) 'tmte5))
setistcics
a
(s,
L
_rll
-·-----··-·9------·--------
111 11-
-94:,e;.
i ,I
I
(- (c r
(X C',))
')
f, c.;..d
rY)
3-~
(,:.-d~
Y) (Y 2.))))
'defun re.uj. i
I(se
rr r .i
.r t
l)
r
'
.
.
..i ..t
J,
'
(•T(ind
'
'1
i 'f t c3.
4
-'I
-1
fetan
CC
(setG Xnew
r S P . .i))
(S ttU?
t
Xl
ub st
'-
.
.,
0 t;t(:i'
''tt
~v.
nov .°,0)
2
s't)
-$ (e{.s
g..'
'
iJkli{',ood),,-,f
, ,i
(seta ne~ (F.-.rId
a*aal---
i
ik
'l ! l-: ihccd
,
Ce tt '5 ' w.
''B-~!'4
e-ts..v. I,,
i
(s
ii . )}
S
';
(//$/jr. (exi
!
i ;
)I_
)
-'
Y)
.:)
uP ~
t-:t
'"-,fW
...
0 ~ )5
Xr-w Xh:l f))F.nzi
___
"t
'~sfls
I,
?),r
.*
-95-
i
r
I
~y
S.,
'''r,,i;'
'
ct
.
'.ca
(
' )
:;r
A)
C.FcEi2
,)
FcI
41~~~~~,r.I,0+
)
(list
I
) )
I
P!
(/1/ f
!*
11R
,
I OI
(i:- O
* ~ .)
I
Fc
-I
. r
(t (PCr , 0,)
"r 1" (+1c
1
$(<,'
O
,)
I (+$ ,Fc1 :,.
,
)))
, ,
I,
i.
..I
!.))I)
nil)))
ulpr~~~~~~~~~~--------~~~~~~~~~~~~~~~~~
-
-
-,
~
~
~
~
~
~
7F-
-"
-96-
¢
j- r 7 r-/ X
s
9
fi
r
-f'
<
t
*!/
197
~t
--.
t:J.
.?
,~
nf
3'c,''f:
It
c t r,
'. s
';
5_.JI ,S1 JI
oe
E't
-i f.i4-
"
.*:
4;
' _
'. '
i
(7i.:cl
i- . . 1
r.(I..
..
' . -+'
' '.r:,'neist)r
+ :i i
¢t:]'-Esh,.
t (+.
. -ys ,;:-,L ...
-_; ' ',,;... '-*'
'
Vc ... ,
.:r
,
i
'.
.,:i
t-"*~
';re.t))
(,-¢,
. -.r.r =. ,;- f
(ecel
'"~,1
i_.:
,,_
.:
( I i-+;...en'e Ir ,.ve'
__
II__IC_
__
z)
7
.
'
I ....t
4*7
n
_
_
__
-97-
"-*
'
i
F $i:
~
~
. m ' tc.r
t
2. i
t;
:,
+4;
"\ 5
_
u
,e r. c
_~S;'i
r
X(d
(1.
_ Nr , t
f
,~-.~..~,:
-
-
-t.:;',(c...'
---
t'u/ r!
..,
-
.1
.
t
rll.
es
t)
t>
t
.)
ist
in -od
-I,_
v
, t c. -.
f
czini1r,
''!
.-....
r*st ,r '
v
7S; .'.a
't~.~,ir?::! :
(( (,=..~'
d. [
: nu, t t?,(c
'
'?
)ri . r 9rt,e,
- -t
tit
t
,.'r
.,
t r So
f(1l(c
',j
A:
irE,.:.e)
) ;
.:
I
·_L__
-98-
,
":.:'.
r.,:.d:~.
~rt' ~= ,
s ,,,
~.,
IEV'j- Fewi
;; '.4'
: i·
I^r
..
~r-e
'b = '.
..
.~
-''
:t
,.r:
'C
'
'.--- h-'
sn - =
r
a.
,.-k r;:'' ' 't . i
t
t,
t
_a*
I
~-'
'
,;SeYT
. , t xl
~.,
.
i
'-u' C
li
..
. ll,.,
_ , )n)
. ,. ::=.
.......
(.",:- ~
i)
-pll-r·----r--nr··II(···IC-"··-·IP
;
-
'~:.
;c.-
_:st.:
,;,=, (~-'
't
Ve
i
i;~.
~~~~~~~~~~~~~~~~~~
-...
___. i-r
.5
.';
=,-*-e.)r
--a----
i-
-99-
G3/ 2'-3.?¢
LSF
(dI
r2r;
r,.l
.
7
?
t7'
_ici
r
'
_
i:;
1 -,r,;gl
(defurn CSF rni
(,~utr _
t;.r,
n.
, r.cr-'
- ri:,e
(~.,'i.-
;j
.C ff 'bOuc
¢'.,..
b.:
'
.ts)i,
-,
,r z
-C 5f._!T!
'~8;'er:.)
(sorr.
o r),.
(uer:d
.rc
(Futc
r.
1 .. t.
feer-rF:od' );
'
.o?. "' ... i k'1i
( e.
sb
ri, t
s t
I:
lf!:0;
'stte))
I.
,
1
11
, .
-i.....
, ,I
-
-
Op1P~rr:lF~
-100,3"
·.1-i.-.T
.
t:..?.- i'
a
:'!.
F ''
.:i,)
'. : *, U.1:
t
i
.. ·
i'1
(i
!i . t.
; i i.t,
. ).;.F
,-
a:
ni lo.::.;
( t)
ir. i.
(ut
r
rc,-.r Ic-, i.liet00 '1
(klImmr
ne csf
,
(
a
I
-------------·I----r·--
i .U d): )
...
r)
-.
(set,.list (sust
'buffcsfnil
t(uF-erd
s ) ':.:
..
,'~;rJ +.
;,+ 1
PA o(F
Ma, .9
ma.
i
il (!istecsf)
(et Ct
.('Jeeftc-nde
'F'i i,. .rrt..))
;-iu~c
~-,t._+.!!;,C¢,
,' t-rt
JFIij(
-ICiBQlsPa*Priri*1I·l--··slli
`
-101-
;''vsi.>.'-}Xt
ii
,I7',Z I~7
:.,i
' .---
t'-- "
Ii,
, `7r
',=f'?.,a'2§
1>r
,/;
9
I'72
ri'
4 J
FE!
......
'
''
...
IIa
Jt
,a-e :
'.
i;~R',
1-,,r-c..
':ii.
rli.
*-"
': .s.c..t.':
~:.w:
:
', l
,u U:.i..
tE ,(:'.::'.t
ril
'
';,:
(Crr,
(,
rr .,r..
'
!: tiltt·
1--3·--·-------·1·--·--11111111111
--·
llr
-
, 'r;.''
i:.'.':.;.¢,>
-i
*);)
..-u:t~6--irt
-
.. .J.i
t).Z 1s
p
'"'
;
·
.
- -----
E.
:, .-
--··lul^--"IIIPii- - --
.-·------ --·
_ _ I.
·
__
-102-
I
...
,g
-%
1:Q
i,,
_,
.
t E4.:
I ..I 11
I-,II IIm-., x.-
I.,. ,-iI.,
0I
.I
o";; .;; ;6
.I - . .- - ,
I I
, I.-
·.
-103-
~~*
E*,-'
' .,
W:t.~i:.~'
('ft±
i I.f..
.S.:
-^i-'-.
.'
.~
,"
:
r .
'
.I
/"" S.0
t,)
T
f r '".,;.* +-rn'"I; I
( .,i
ii?
_.J;s,'
:;-:!:.
IC.~,'J. I's','7i
P.t'
( e Ii '
4 ~!
7t
t
.
*
Z ,i
-i r
.t,
-
ff
t
(
s<<vwiS i~s~~
d
(f~t
11 t0 ,st _irw't
iA )r
t/ 'rX
(sFet u
(IVbd~
-.
l.-;n2eizS
"~)
t'.qci,
(*tXf:f
t-t'lf
f
r_- ;M i
~~~~~~~~~v~~~~~~~
.
i
i;-s!,
ii
f
"- ~~~.^....
-.- .~~~~~L--
·
P~~~~~~~~-
-104-
-:
ki
~
:.J1t _ re_,
J T' 1,;
.J
,
' _.t
I''r;i,
(......
F·!;
r ix i
s.
t
N.,,lu/
.
l
-?i
i o-,
.I J-
--
'l.:·"'
--i;
F i s!.
'i
t
!
frIiifr
f
i;
zi<tSf
_ii
'
n2~
'fJ
.-
j '
.
,a-
,:;.;.t(o
,'1c: /
.
r
t
r,
C(cr
In
pi.i
=
:.'
-ri
list')
t
-
r- , t;
,)
:'!,-_
fS '
^
i St . i Ji-i,
-'t:.,
ri--\
s ,i
L!
· /
4;
s.. ;<
,-
e'
(~,~F'c-:r
:=.:.-,
ofj s
''
'.~.ctl)
--..
f2:
ti.
<s,
1"93il
I
-
i'e-:s\
_t.1.t~r.:ne
r - : (cdr
t {,it~fdefu
`:,,l"l I
" .I;,
·
s
f~:,~E:+li~t)
,~"-n
* _
.
!...-
'.ful
.
- r,7-r
$
- C;
.-_2 _ p iBW*~
4.I..
c s * t"
'
;
C.A
.. . - V
ICT~
-ez;·7r.
Q,17,
l",-, .-
.
1>.i".'
.
;~i
t
2
7r
i z-
Z+ N
L' r''ef,)
c
'r
s-c~,_~
-i. a
.-
e
.nr-,~=, E-2i-' s-t)~-
; st
-
r .,3,
' b r~.n-2es..)C
,
3
,
;
;:W-i;
,,
-
- r
._.
-1
'
;
.......
c! -,
"hes
i
i
i 1
.:
.~-f
IS.
D
tLf"fi
- ,1
_
r
CI
:IC.
t
3
,I _ _
_a I _
I
- t,. .'
eC-I·--· -·
---I ·
i~~~DII--------a~~~~~~~~~~lLI~~~~IIII*I--·~~~~~~~~C--
~
~
~
~
~ ~
~ ~ ~ ~ ~ --
-105-
C .
i_;
.'. ;
/*- * @ ri .
.
1.-.J. .
.-....
'~l
,
:
-:
'
_ j,t
(e:t, :'.- --+
,
A
L
,,
,
'
L.
te
-
t
r-..
L%
se q
I
, >
i ~-
iI
', .
; i.
'
'r
Sr.
_..,
.
: :'C'6
O',i'.
J
)
*^
Cj ';
_
_8-
t
4-I
. !-
._-zj,
-
r.5:^t
/.
-
o.
;t
---
X8*-¢
:
t
CS r
%
-.
*.
*, *:
t
i
!
)_:
i .,
,
_ _
_·
__
-106-
* _r -
j'
I!..
_7
rr------·-------·I-··,-L-
-
_ X, . .
,-C--'
, "
Jt.; tJ .,,
,,
x'.
· -
,-!1 ,.- .
,_
I.,
-..
, 1
""
--C---
'e
--;--LILL--
'_L
r
1
-107-
f;'
t t'
i'e
C-
..1r
t
(
i
,,
.S.
.
/i-Wf ---,.
E -
.
?.-. _ . i; 3
"--'
- '
}
1
I ,-v.
': LT!,
....
,
,u (t . ., .
Z.
..
:'~
f
en
.e
'Ee, (;?n'i
) ), ,
s.)
(fi-i'.t
t ,'r
r:)C
Et -.t i
t)r
tr)
E
J
"
: t£
.;
t
s
e,,u,~ -r.'
-
-rso!,llt
J
'"J
(' I
I-T iC·'JJi~ .'))---
11111-
:,,,;,
.'~'r
- i-.4
r .
FrE-zI
.
,
.; r u
I
A
.
t (~t '~e-' cr-r'- :--
(tr
t,
E
;. i .4eta
( ,,:T.. '...
(t-;.t te.
is
(cori:Jd,;
(:.si
*
lis
i
t
J,'(7
.
',
t-':
E
.r
''i"
'
4..-4
;
'--
k'
t
.
e-;i
ts s t i l
., . c:-,t .E.:
E"'U ,
...
:-
*
i
-
...
'--
)
;
- --,
- --
..
1---
-lil·-""---*`-..'-"-Z-L-----..
.
-108-
(_f rr
:
$S"
t_ i;
-
r-I.:'
t ,. *: r
t-
-
: ,-r- . ^ i.
t :
.1
vr.
t.:f-:.
'
t
i
M
icit
;,,
'
f?
JZ L i4
ti
0//
_
1
:.J
-i.,
,t
':r r,
pt. .' n(i lst
F r;i
(c-iI 3
'
V'_'-
o nrr
,; ,
~~~-~~--~~9·r~~i-~~---:--
I1 I
s
? i*;t)
-, .-;:iL'. r,
'~~i
-
.t-V
.
f.:5j. ,.
8
cuul,.
.T-T.
ii'
,rr
rt
te
.
.t,
(j~tO
.'.
t,
:-.,
t .t
?;
E.
,; ..- i-.
:..
S ;,
't (c.,.:~/it
-
, ',sE
-
f-.fSt
r
,
r- - I
,..,,
--
·-
'
-
-
-
·-
--
.
-109-
'.efu!-4tl
f
-..
r
t.:.
t
c.09
i",
...
";
*"
-(t..'
n
t'
;s t~, ....i
.
.
' i
4
i
...
.
.J
r
r
; .L
; \ijj
,.5
'
;
r:
E
S
-r
Z
;
i Ii
±...
,
r
.4,C , tlz
- s
i r,
.rt.
1I1
*
2
t8
L;'
,riiF
.)
,r;-z3j'
W
C:
'~j '~
-.
^
..
.
I
+: ...
.
t
'
v.,.
9
t jE
t
- <^1t
1Stri
1_.'
,;aj,
r-
. e
: ...
~ 4.,ii·
- ,r
1,
i
_
.;
_'46!f;>
-t;t;;L
,,
C;~r J _l,
;
~ t *-,'i'
_,
-
t
. t.
.. ; ...
t
i'
4I
vkt Z t it' 'ei
;.T t
,l.! "--
t
ur,_.
J
.. _I_
r
`
'd:'i
....
(tr- "t
!'
i
:
'
'
E ;_
_
4 eI ..-e
.
~"'""'-d
-' ,|il)(j;,-t 'n(OS
/
.
Cs P
.!/d
it:v
j )
.\
/
)
-110'
.
L.
i _
Jr
<
<,--
.c; e_
I:tt
(t
ri
R--C----------"------I----Di·IIBslllR
i
l
_ ':.4irI
.-' s
's '
k7-ilPl,,) C'
f
_
i
r
'-
.;; i
blOL
l!
~.¢~., .;,^,·.
t
r-s.:,
i*d;
-ii··
;,d ~
T* -
Zt
r
:.- d
.;C
.
,; : r ) _
r lC-E
_
a ,r
'i
'.
n.
-e
, t*"'-... .. :.
d
. .;
.t
.
...
.)
),.
---I
--. -----------*--·1----·------------ I--al·-r-rsncsas.aa-r;l----i-----·
_I_
-111-
.
(P C'.,
SS?;'(:'
i..b
iP
>'j
e(t')),r
t
(in eiit
(dFfUr fr'"'i
e.ir
t
.
r
t
(:~]8
. ,r
,
71>7
'(OP5
,
r'
>: .i r,';:,'~,,;.~r)r
. . I .
ii
,
3
ij{
,
'"* ....'*'
l (-'t
o:
.
:..
_i.; , t'~ "
; r 2.^t.
(defu ri i i r e,- ,rf,
(.;,Pi
l'-
it I~i::itu},inii. 3ir.
-
i
P~C';
...
V:
.
z-,
·
it x:del srIdel)
line ('n it -iri
(alur
(stef- . >dr i
.''evl
.u
.t
xir, t
:.:'d./
sii t).:.e).
. (s
+ .t (s~.
(t-. ( ,_;ir·i
-, ;.,... ,~:
....
(·~':1 xi.rit) -~..
(.'o,3s
'iout
(sitO
(;t1 i ..t.
},;ji
,
,.
i- e1
irit)
¢
(Pr ci-_ oa)l
,t
i.
\,,o
-
1------
·I·--·
--
--
---
-
·
-112-
r
irt
-Z
u,itrt ;ir .
C(d
C
c;
F. . P
t 3
i .-
0. '·e'GOrn
(,ut~rc~
'hoo
. ;)).
;riPr,: f
(:_0 1.iklie
t ti
( -trir,
)
i
~,:C..;
r-
_i ?t
sPee
(in
,
_
r_i r,-,d~
'__:..r.
n.~
tf
' r'~ )l
i., ____
t.
(t. .u.".
('rin"Ft 'Chir,
(Pe
_
_
_
__
_
i
it :;~-ll li'"-rl
.C~~~
c.,~~
f~~i '
(
.
tle
fe 'iel :
i -!i's
tiCt
C r::'~'
.......
t(~e
5;Pr
tit P
te
iC}
(>') . (-'Pr,
l-i
St ,,-'.:·~·r
'tre'
0t
-~
Si.it.~ S,)
)
'u,
(;'s ]
·1111111111111111111111111111111111111
r
)i
'
-
- ...
I-
-113-
I
(b a 1r."L
iE e
D Ji-
F I''"f
u
.'i . '.,:i'.... t r-.,:i+. '
L.
F.;
t;
't.]
;
*-ir;'
+
i}.
.it, (_c :,-......
( t ~c~r:
'
(t
I..
(cfun
nttrcks nil
(sir, t
'+2+~~f~fSff.f'f++f++4f+f+
(se
t
, .e;
,
! i
Set-,trs.m'int
7'f+'r+-?f
,ff:)
r ..
''.. nil)
<.Rs . :, '.
(seta '"
It
r ill
,
( e.t ...-..
'
<set~ . ...
,
i.'..
s
'.
.(__t_____i_j
-114-
REFERENCES
1.
F.C. Schweppe, Uncertain Dynamic Systems, Prentice-Hall, Englewood
Cliffs, N.J., 1973.
2.
R.W. Sittler, "An Optimal Data Association Problem in Surveillance
Theory," IEEE Trans. Military Electronics, Vol. MIL-8, Apr. 1964,
pp. 125-139.
3.
C.L. Morefield, "Application of 0-1 Integer Programming to Multitarget
Tracking Problems," IEEE Trans. Automatic Control, Vol. AC-22, June
1977, pp. 302-311.
4.
D.B. Reid, A Multiple Hypothesis Filter for Tracking Multiple Targets
in a Cluttered Environment, LMSC Report D-560254, Sept. 1977.
5.
D.B. Reid, "An Algorithm for Tracking Multiple Targets," to appear.
6.
Y. Bar-Shalom and E. Tse, "Tracking in a Cluttered Environment with
Probabilistic Data Association," Automatica, Vol. 11, 1975, pp. 451-460.
7.
Y. Bar-Shalom, "Tracking Methods in a Multitarget Environment," IEEE
Trans. Automatic Control, Vol. AC-23, August 1978, pp. 618-626.
8.
M. Athans, R.H. Whiting, and M. Gruber, "A Suboptimal Estimation
Algorithm with Probabilistic Editing for False Measurements with
Applications to Target Tracking with Wake Phenomena," IEEE Trans.
Automatic Control, Vol. AC-22, pp. 372-384, June 1977.
9.
F.N. Bailey, "Comments on 'Application of 0-1 Integer Programming to
Multitarget Tracking Problems,' "
IEEE Trans. Automatic Control,
Vol. AC-24, Feb. 1979, pp. 142-143.
10.
R.R. Tenney, R.S. Hebbert, and N.R. Sandell, Jr., "A Tracking Filter
for Maneuvering Sources," IEEE Trans. on Automatic Control, Vol. AC-22,
pp. 246-261, April 1977.
11.
A.S. Willsky and HoL. Jones, "A Generalized Likelihood Ratio Approach
to the Detection and Estimation of Jumps in Linear Systems," IEEE
Trans. on Automatic Control, Vol. AC-21, pp. 108-112, Feb. 1976.
12.
D, Willner, Observation and Control of Partially Unknown Systems,
Report ESL-R-496, M.I.T. Electronic Systems Laboratory, May 1973,
13.
M.A. Athans and C.B. Chang, Adaptive Estimation and Parameter
Identification Using the Multiple Model Estimation Algorithm,
ESD-TR-76-184, M.I.T. Lincoln Laboratory, June 1976.
-115-
14.
M. Athans, et.al., "The Stochastic Control of the F-8C Aircraft Using
a Multiple Model Adaptive Control (MMAC) Method," IEEE Trans. on
Automatic Control, Vol. ACC-22, pp. 768-780, Oct. 1977.
15.
Y. Baram and N.R. Sandell, Jr., "Consistent Estimation of Finite
Parameter Sets with Application to Linear Systems Identification,"
IEEE Trans. on Automatic Control, Vol. AC-23, pp. 451-454, June 1978.
16.
C.S. Greene, An Analysis of the Multiple Model Adaptive Control
Algorithm, Report ESL-TH-843, Electronic Systems Laboratory, M.I.T.,
Aug. 1978.
17.
M. Athans et.al., Investigation of the Multiple Model Adaptive Control
(MMAC) Method for Flight Control _Systems, NASA Contractor Report 3089,
May 1979.
18.
Y. Baram, Information, Consistent Estimation and Dynamic System Identification, Report ESL-R-718, Electronic
Systems Laboratory, M.I.T.,
Nov. 1976.
19.
Y. Baram and N.R. Sandell, Jr., "An Information Theoretic Approach to
Dynamic System Modeling and Identification," IEEE Trans. on Automatic
Control, Vol. AC-23, pp. 61-66, Feb. 1968.
20.
N.R. Sandell, Jr. and K. Yared, Maximum Likelihood Identification of
State Space Models for Linear Dynamic Systems, Report ESL-R-814,
Electronic Systems Laboratory, M.I.T., April 1978.
21.
K.I. Yared, On Maximum Likelihood Identification of Linear State Space
Models, Report LIDS-TH-920, Laboratory for Information and Decision
Systems, MIT,, July 1979.
22.
A.S. Willsky, "A Survey of Design Methods for Failure Detection in
Dynamic Systems," Automatica, Vol. 12, pp. 601-611, Nov. 1976,
'p
23.
D.T. Magill, "Optimal Adaptive Estimation of Sampled Processes," IEEE
Trans. on Automatic Control, Vol. AC-10, pp. 434-439, Oct. 1965.
24.
P.H. Winston, Artificial Intelligence, Addison-Wesley, Reading, MA., 1977.
--
---