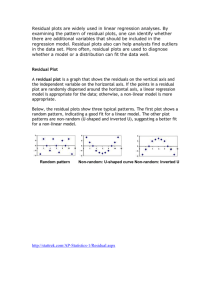
STAT 511 Solutions to Homework 3 Spring 2004 1. > X <- matrix(c(1,1,rep(c(rep(0,6),1),3),1),6,4)
advertisement
,1),3),1),6,4)")
STAT 511 Solutions to Homework 3 Spring 2004 1. > X <- matrix(c(1,1,rep(c(rep(0,6),1),3),1),6,4) > Y <- c(2,1,4,6,3,5) > V1 <- c(1,4,4,1,1,4) > fit <- lm(Y~X-1,weights=1/V1) > fit$coefficients X1 X2 X3 X4 1.8 4.0 6.0 3.4 2. > homes <- read.table("homes.txt", header=T) > dim(homes) # The dimension of the matrix is: 88 rows and 15 columns [1] 88 15 > Y <- as.matrix(homes[,1]) > X <- as.matrix(homes[,c(2,5,10,11,13)]) > X0 <- rep(1,length(Y)) > X <- cbind(X0,X) > library(lattice) > splom(~homes[,c(1,2,5,10,11,13)],aspect="fill") The first plot in the last row suggests that size might be the best single predictor of price. This scatterplot matrix shows no clear evidence of multicollinearity. 10000 15000 15000 10000 Land 5000 10000 1200 600800 1000 1200 1000 800 600 600 FinishedBsmt 400 200 0 200400600 1200 8001000 1200 1000 800 Basement 600 400 200400600 5 3 4 200 5 4 3 BedRooms 3 2 1 2 3 1 1500 2000 2000 1500 Size 1500 1000 1000 1500 150000 2e+05 2e+05 150000Price150000 1e+05 1e+05 150000 Scatter Plot Matrix Figure 1: Scatterplot matrix for y, x1 , x2 , . . . , x5 1 0 10000 5000 > round(cor(homes[,c(1,2,5,10,11,13)]),4) Price Size BedRooms Basement FinishedBsmt Land Price 1.0000 0.6649 0.2974 0.3597 0.3152 0.4353 Size 0.6649 1.0000 0.4647 0.4028 0.2044 0.1975 BedRooms 0.2974 0.4647 1.0000 0.1794 -0.0268 -0.0240 Basement 0.3597 0.4028 0.1794 1.0000 0.3153 -0.0157 FinishedBsmt 0.3152 0.2044 -0.0268 0.3153 1.0000 0.0854 Land 0.4353 0.1975 -0.0240 -0.0157 0.0854 1.0000 > qr(X)$rank [1] 6 > b <- solve(t(X)%*%X)%*%t(X)%*%Y > yhat <- X%*%b > e <- Y-yhat 20000 −40000 −20000 0 Residual 40000 60000 80000 Residual Plot 60000 80000 100000 120000 140000 160000 180000 200000 Predicted Y Figure 2: Residuals versus Fitted values To answer what does fin=c(6.0,6.0) inside the command par() do, one can type help(par) or type help.start() which opens a browser in ”C:\Program Files\R\rw1080\doc\html\rwin.html” and then type par in the Search box. ’fin’ A numerical vector of the form ’c(x, y)’ which gives the size of the figure region in inches. > MSE <- (t(e)%*%e)/(dim(X)[1]-qr(X)$rank) > MSE [1,] 624915133 > cov.b <- as.numeric(MSE)*solve(t(X)%*%X) > labels <- c("Intercept","Size","BedRooms","Basement","FinishedBsmt","Land") > results <- round(cbind(b,sqrt(diag(cov.b))),4) > tmp <- cbind(labels,results) > colnames(results) <- c("Estimate","Std Error") > colnames(tmp) <- c(" ","Estimate ","Std Error") > library(MASS) > write.matrix(tmp,"hw03.out") Estimate Std Error #hw03.out Intercept -20167.0441 16406.6402 Size 56.4467 10.2605 BedRooms 2888.6011 4081.838 Basement 21.446 16.7706 FinishedBsmt 21.4798 10.7385 Land 3.847 0.8769 2 1500 2000 1 2 3 4 5 200 400 600 800 1000 Residual Plot Residual Plot Normal Probability Plot 400 600 800 FinishedBsmt Sample Quantiles −40000 −20000 0 Residual 0 −40000 −20000 0 200 20000 40000 60000 80000 Basement 20000 40000 60000 80000 BedRooms 20000 40000 60000 80000 Size −40000 −20000 0 20000 40000 60000 80000 −40000 −20000 0 Residual 20000 40000 60000 80000 −40000 −20000 −40000 −20000 1000 Residual Residual Plot 0 Residual 20000 40000 60000 80000 Residual Plot 0 Residual Residual Plot 4000 8000 12000 16000 −2 Land −1 0 1 2 Theoretical Quantiles Figure 3: Residual plots and Normal probability plot When we change the smoothing parameter in loess() from 0.9 to 0.5, we obtain a less smooth line. 3. > fit <- lm(Price~Size+BedRooms+Basement+FinishedBsmt+Land,data=homes) > summary(fit) Estimate Std. Error t value Pr(>|t|) (Intercept) -2.017e+04 1.641e+04 -1.229 0.2225 Size 5.645e+01 1.026e+01 5.501 4.18e-07 *** BedRooms 2.889e+03 4.082e+03 0.708 0.4812 Basement 2.145e+01 1.677e+01 1.279 0.2046 FinishedBsmt 2.148e+01 1.074e+01 2.000 0.0488 * Land 3.847e+00 8.769e-01 4.387 3.39e-05 *** Residual standard error: 25000 on 82 degrees of freedom Multiple R-Squared: 0.5778, Adjusted R-squared: 0.5521 F-statistic: 22.45 on 5 and 82 DF, p-value: 4.105e-14 3