Team 2: The House Party Blackjack Mohammad Ahmad Jun Han

Team 2: The House
Party Blackjack
Mohammad Ahmad
Jun Han
Joohoon Lee
Paul Cheong
Suk Chan Kang
Team Members
Hwi Cheong (Paul) hcheong@andrew.cmu.edu
Mohammad Ahmad mohman@cmu.edu
Joohoon Lee jool@ece.cmu.edu
Jun Han junhan@andrew.cmu.edu
SukChan Kang sckang@andrew.cmu.edu
Baseline Application
Blackjack game application
User can create tables and play Blackjack.
User can create/retrieve profiles.
Configuration
Operating System: Linux
Middleware: Enterprise Java Beans (EJB)
Application Development Language: Java
Database: MySQL
Servers: JBOSS
J2EE 1.4
Baseline Architecture
Three-tier system
Server completely stateless
Hard-coded server name into clients
Every client talks to HostBean (session)
Fault-Tolerant Design
Passive replication
Completely stateless servers
No need to transfer states from primary to backup
All states stored in database
Only one instance of HostBean (session bean) needed to handle multiple client invocations efficient on server-side
Degree of replication depends on number of available machines
Sacred machines
Replication Manager (chess)
mySQL database (mahjongg)
Clients
Replication Manager
Responsible for server availability notification and recovery
Server availability notification
Server notifies Replication Manager during boot.
Replication Manager pings each available server periodically.
Server recovery
Process fault: pinging fails; reboot server by sending script to machine
Machine fault (Crash fault): pinging fails; sending script does nothing; machine has to be booted and server has to be manually launched.
Replication Manager (cont’d)
Client-RM communication
Client contacts Replication Manager each time it fails over
Client quits when Replication Manager returns no server or Replication Manager can’t be reached.
Evaluation of Performance (without failover)
Observable Trend
Failover Mechanism
Server process is killed.
Client receives a RemoteException
Client contacts Replication Manager and asks for a new server.
Replication Manager gives the client a new server.
Client remakes invocation to new server
Replication Manager sends script to recover crashed server
Failover Experiment Setup
3 servers initially available
Replication Manager on chess
30 fault injections
Client keeps making invocations until 30 failovers are complete.
4 probes on server, 3 probes on client to calculate latency
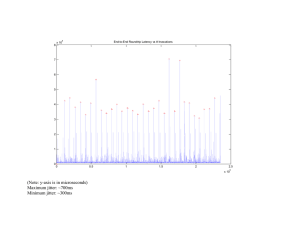
Failover Experiment Result
8 x 10
5 End-to-End Roundtrip Latency vs # Invocations
7
6
5
4
3
2
1
0
0 0.5
1
Invocation #
1.5
2 2.5
x 10
5
Failover Experiment Results
Maximum jitter: ~700ms
Minimum jitter: ~300ms
Average failover time: ~ 404ms
Failover Pie-chart
Most of latency comes from getting an exception from server and connecting to the new server
Failure Induced
1% 2%
97%
Query Naming Service
Detection of Failure + Reconnecting to new Server
Normal Run time
Real-time Fault-Tolerant Baseline
Architecture Improvements
Fail-over time Improvements
Saving list of servers in client
Reduces time communicating with replication manager
Pre-creating host beans
Client will create host beans on all servers as soon as it receives list from replication manager
Runtime Improvements
Caching on the server side
Client-RM and Client-Server
Improvements
Client-RM and Client-Server communication
Client contacts Replication Manager each time it runs out of servers to receive a list of available servers.
Client connects to all servers in the list and makes a host beans in them, then starts the application with one server
During each failover, client connects to the next server in the list.
No looping inside list
Client quits when Replication Manager returns an empty list of servers or Replication Manager can’t be reached.
Real-time Server
Caching in server
Saves commonly accessed database data in server
Use Hashmap to map query to previously retrieved data.
O(1) performance for caching
Real-time Failover Experiment Setup
3 servers initially available
Replication Manager on chess
30 fault injections
Client keeps making invocations until 30 failovers are complete.
4 probes on server, 5 probes on client to calculate latency and naming service time
Client probes
Probes around getPlayerName() and getTableName()
Probes around getHost() – for failover
Server probes
Record source of invocation – name of method
Record invocation arrival and result return times
Real-time Failover Experiment Results
Invocation #
Real-time Failover Experiment Results
Average failover time: 217 ms
Half the latency without improvements (404 ms)
Non-failover RTT is visibly lower (shown on graphs below)
End-to-End Roundtrip Latency vs # Invocations
6
5
4
3
8 x 10
5
7
2
1
0
0 1 1.5
2 0.5
Before Real-Time Implementation
2.5
x 10
5
After Real-Time Implementation
Real-time Failover Experiment Results
Open Issues
Blackjack game GUI
Load-balancing using Replication Manager
Multiple number of clients per table (JMS)
Profiling on JBoss to help improve performance
Generating a more realistic workload
TimeoutException
Conclusions
What we have accomplished
Fault-tolerant system with automatic server detection and recovery
Our real-time implementations proved to be successful in improving failover time as well as general performance
What we have learned
Merging code can be a pain.
A stateless bean are accessed by multiple clients.
State can exist even in stateless beans and is useful if accessed by all clients cache!
What we would do differently
Start evaluation earlier…
Put more effort and time into implementing timeout’s to enable bounded detection of server failure.