(Note: y-axis is in microseconds) Maximum jitter: ~700ms Minimum jitter: ~300ms
advertisement
 Maximum jitter: ~700ms Minimum jitter: ~300ms")
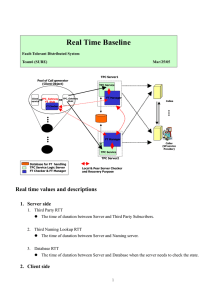
5 8 End-to-End Roundtrip Latency vs # Invocations x 10 7 6 5 4 3 2 1 0 0 0.5 1 1.5 2 2.5 5 x 10 (Note: y-axis is in microseconds) Maximum jitter: ~700ms Minimum jitter: ~300ms 5 7.5 Failover time vs # Failures Injected x 10 7 6.5 6 5.5 5 4.5 4 3.5 3 0 5 (Note: y-axis is in microseconds) Average failover time: ~ 404ms 10 15 20 25 30 Failure Induced 1% 2% Query Naming Service 97% Detection of Failure + Reconnecting to new Server Normal Run time FaultFree server latency middleware latency 31% 69% Strategies to reduce spikes 1. To keep the naming server query time low, the client will keep a list of available servers. When the client cannot connect to any of them, it’ll ask the replication manager for an updated list. 2. Before the client reissues its invocation, it creates another instance of HostBean on the new server that it failed over to. The failover time consists of 1) connecting to a new HostBean, and 2) reissuing invocation and waiting for reply. To reduce the time for 1), we’ll pre-create HostBean’s on servers that are on the “list of available servers.” 3. To reduce the time for 2) (reissuing invocation and waiting for reply), we can implement caching on the server side. 4. We can implement active replication for faster failover.