Disordered Eating, Menstrual Irregularity, and Bone Mineral Density
advertisement

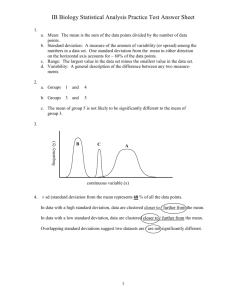
Basic Statistical Principles for the Clinical Research Scientist Kristin Cobb October 13 and October 20, 2004 Statistics in Medical Research 1. Design phase: Statistics starts in the planning stages of a clinical trial or laboratory experiment to: – establish optimal sample size needed – ensure sound study design 2. Analysis phase: Make inferences about a wider population. Common problems with statistics in medical research Sample size too small to find an effect (design phase problem) Sub-optimal choice of measurement for predictors and outcomes (design phase problem) Inadequate control for confounders (design or analysis problem) Statistical analyses inadequate (analysis problem) Incorrect statistical test used (analysis problem) Incorrect interpretation of computer output (analysis problem) **Therefore, it is essential to collaborate with a statistician both during planning and analysis! Additionally, errors arise when… The statistical content of the paper is confusing or misleading because the authors do not fully understand the statistical techniques used by the statistician. The statistician performs inadequate or inappropriate analyses because she is unclear about the questions the research is designed to answer. **Therefore, clinical research scientists need to understand the basic principles of biostatistics… Outline (today and next week) 1. Primer on hypothesis testing, p-values, confidence intervals, statistical power. 2. Biostatistics in Practice: Applying statistics to clinical research design Quick review Standard deviation Histograms (frequency distributions) Normal distribution (bell curve) Review: Standard deviation Standard deviation tells you how variable a characteristic is in a population. example, how variable is height in the US? Variance is For the average Standard deviation is the squared distance from the square root of variance mean. (roughly the average distance A standard deviation of height represents the average from the mean). distance that a random person is away from the mean height in the population. n 2 Variance: ( xi ) 2 i 1 n The standard deviation (original units)= n ( xi ) 2 i 1 n 1 Review: Histograms Percent of total that fall in the 2inch interval. 64-66 66-68 Data are divided into 2inch groups (called “bins”). With only three woman <60 inches (5 feet), this bin represents only 2% of the total 150-women sampled. 62-64 68-70 60-62 58-60 70-72 Review: Histograms 1 inch bins Roughly, follows a normal distribution Mean height=65.2 inches Standard deviation (average distance Median height=65.1 inches from the mean) is 2.5 inches Review: Normal Distribution 68% of the data 95% of the data 99.7% of the data Review: Normal Distribution 62.7 AInperfect, fact, here, theoretical 101/150 (67%) normal distribution subjects have carries 68% heights of its between area within 62.7 and 1 standard 67.7 (1 deviation standardof deviation the mean. below and above the mean). -1 SD +1 SD 67.7 Review: Normal Distribution 60.2 AInperfect, fact, here, theoretical 146/150 (97%) normal distribution subjects have carries 95% heights of its between area within 60.2 and 2 standard 70.2 (2 deviations standard of the mean. deviations below and above the mean). -2 SD +2 SD 70.2 Review: Normal Distribution 57.7 -3 SD AInperfect, fact, here, theoretical 150/150 (100%) normal distribution subjects have carries 99.7% heightsofbetween its area within 57.7 and 3 standard 72.7 (1 deviations standard deviation of the mean. below and above the mean). +3 SD 72.7 Review: Applying the normal distribution If women’s heights in the US are normally distributed with a mean of 65 inches and a standard deviation of 2.5 inches, what percentage of women do you expect to have heights above 6 feet (72 inches)? 72 65 Z 2.8 2. 5 2.8 standard deviations above normal! From standard normal chart or computer Z of +2.8 corresponds to a right tail area of .0026; expect 2-3 women per 1000 to have heights of 6 feet or greater. Statistics Primer Statistical Inference Sample statistics Sampling distributions Central limit theorem Hypothesis testing P-values Confidence intervals Statistical power Statistical Inference The process of making guesses about the truth from a sample. Truth (not observable) Sample (observation) Make guesses about the whole population EXAMPLE: What is the average blood pressure of US post-docs? 1. We could go out and measure blood pressure in every US post-doc (thousands). 2. Or, we could take a sample and make inferences about the truth from our sample. Using what we observe, 1. We can test an a priori guess (hypothesis testing). 2. We can estimate the true value (confidence intervals). Statistical Inference is based on Sampling Variability Sample Statistic – we summarize a sample into one number; e.g., could be a mean, a difference in means or proportions, an odds ratio, or a correlation coefficient – E.g.: average blood pressure of a sample of 50 American men – E.g.: the difference in average blood pressure between a sample of 50 men and a sample of 50 women Sampling Variability – If we could repeat an experiment many, many times on different samples with the same number of subjects, the resultant sample statistic would not always be the same (because of chance!). Standard Error – a measure of the sampling variability Examples of Sample Statistics: Single population mean Difference in means (ttest) Difference in proportions (Z-test) Odds ratio/risk ratio Correlation coefficient Regression coefficient … Variability of a sample mean The Truth (not knowable) The average systolic blood pressure in US post-docs at this moment is exactly 130 mmHg Random Postdocs 110 mmHg 150 mmHg 105 mmHg 135 mmHg 140 mmHg 129 mmHg Variability of a sample mean The Truth (not knowable) The average systolic blood pressure in US post-docs at this moment is exactly 130 mmHg Random samples of 5 post-docs 125 mmHg 137 mmHg 123 mmHg 141 mmHg 134 mmHg 122 mmHg Variability of a sample mean The Truth (not knowable) The average systolic blood pressure in US post-docs at this moment is exactly 130 mmHg Samples of 50 Postdocs 129 mmHg 134 mmHg 131 mmHg 130 mmHg 128 mmHg 130 mmHg Variability of a sample mean The Truth (not knowable) The average systolic blood pressure in US post-docs at this moment is exactly 130 mmHg Samples of 150 Postdocs 131.2 mmHg 130.2 mmHg 129.7 mmHg 130.9 mmHg 130.4 mmHg 129.5 mmHg How sample means vary: A computer experiment 1. Pick any probability distribution and specify a mean and standard deviation. 2. Tell the computer to randomly generate 1000 observations from that probability distributions – E.g., the computer is more likely to spit out values with high probabilities 3. Plot the “observed” values in a histogram. 4. Next, tell the computer to randomly generate 1000 averages-of-2 (randomly pick 2 and take their average) from that probability distribution. Plot “observed” averages in histograms. 5. Repeat for averages-of-5, and averages-of-100. Uniform on [0,1]: average of 1 (original distribution) Uniform: 1000 averages of 2 Uniform: 1000 averages of 5 Uniform: 1000 averages of 100 ~Exp(1): average of 1 (original distribution) ~Exp(1): 1000 averages of 2 ~Exp(1): 1000 averages of 5 ~Exp(1): 1000 averages of 100 ~Bin(40, .05): average of 1 (original distribution) ~Bin(40, .05): 1000 averages of 2 ~Bin(40, .05): 1000 averages of 5 ~Bin(40, .05): 1000 averages of 100 The Central Limit Theorem: If all possible random samples, each of size n, are taken from any population with a mean and a standard deviation , the sampling distribution of the sample means (averages) will: 1. have mean: x 2. have standard deviation: x n 3. be approximately normally distributed regardless of the shape of the parent population (normality improves with larger n) Example 1: Weights of doctors Experimental question: Are practicing doctors setting a good example for their patients in their weights? Experiment: Take a sample of practicing doctors and measure their weights Sample statistic: mean weight for the sample IF weight is normally distributed in doctors with a mean of 150 lbs and standard deviation of 15, how much would you expect the sample average to vary if you could repeat the experiment over and over? Relative frequency of 1000 observations of weight mean= 150 lbs; standard deviation = 15 lbs Standard deviation reflects the natural variability of weights in the population doctors’ weights standard error of the mean 15 average 1000 weight doctors’ fromweights samples of 2 2 10.6lbs standard error of the mean 15 10 4.74lbs average weight from samples of 10 standard error of the mean 15 average weight from samples of 100 100 1.5lbs Using Sampling Variability In reality, we only get to take one sample!! But, since we have an idea about how sampling variability works, we can make inferences about the truth based on one sample. Experimental results Let’s say we take one sample of 100 doctors and calculate their average weight…. Expected Sampling Variability for n=100 if the true weight is 150 (and SD=15) What are we going to think if our 100-doctor sample has an average weight of 160? average weight from samples of 100 Expected Sampling Variability for n=100 if the true weight is 150 (and SD=15) If we did this experiment 1000 times, we wouldn’t expect to get 1 result of 160 if the true mean weight was 150! average weight from samples of 100 “P-value” associated with this experiment “P-value” (the probability of our sample average being 160 lbs or more IF the true average weight is 150) < .0001 Gives us evidence that 150 isn’t a good guess average weight from samples of 100 The P-value P-value is the probability that we would have seen our data (or something more unexpected) just by chance if the null hypothesis (null value) is true. Small p-values mean the null value is unlikely given our data. The P-value By convention, p-values of <.05 are often accepted as “statistically significant” in the medical literature; but this is an arbitrary cut-off. A cut-off of p<.05 means that in about 5 of 100 experiments, a result would appear significant just by chance (“Type I error”). Hypothesis Testing The Steps: 1. Define your hypotheses (null, alternative) The null hypothesis is the “straw man” that we are trying to shoot down. Null here: “mean weight of doctors = 150 lbs” Alternative here: “mean weight > 150 lbs” (one-sided) 2. Specify your sampling distribution (under the null) If we repeated this experiment many, many times, the sample average weights would be normally distributed around 150 lbs with a standard error of 1.5 15 100 1.5 3. Do a single experiment (observed sample mean = 160 lbs) 4. Calculate the p-value of what you observed (p<.0001) 5. Reject or fail to reject the null hypothesis (reject) Errors in Hypothesis Testing Your Statistical Decision Reject H0 True state of null hypothesis (H0) H0 True H0 False Type I error (α) Correct Correct Type II Error (β) Do not reject H0 Errors in Hypothesis Testing Type-I Error (false positive): – Concluding that the observed effect is real when it’s just due to chance. Type-II Error (false negative): – Missing a real effect. **POWER (the complement of type-II error): – The probability of seeing a real effect (of rejecting the null if the null is false). Beyond Hypothesis Testing: Estimation (confidence intervals) We’d estimate based on these data that the average weight is somewhere closer to 160 lbs. And we could state the precision of this estimate (a “confidence interval”)… 95% confidence interval average weight from samples of 100 Confidence Intervals (Sample statistic) (measure of how confident we want to be) (standard error) Confidence interval (more information!!) 95% CI for the mean: 160±1.96*(1.5) = (157 – 163) “Z/2”=1.96 corresponds to a type I error of 5% for a twotailed test. 1.96 standard deviations away from the mean leaves 2.5% area in the tail of a standard normal curve. The standard error here. 1.96 What Confidence Intervals do They indicate the un/certainty about the size of a population characteristic or effect. Wider CI’s indicate less certainty. Confidence intervals can also answer the question of whether or not an association exists or a treatment is beneficial or harmful. (analogous to pvalues…) e.g., since the 95% CI of the mean weight does not cross 150 lbs (the null value), then we reject the null at p<.05. Expected Sampling Variability for n=2 What are we going to think if our 2-student sample has an average weight of 160? average weight from samples of 2 Expected Sampling Variability for n=2 P-value = 17% i.e. about 17 out of 100 “average of 2” experiments will yield values 160 or higher even if the true mean weight is only 150 average weight from samples of 2 Expected Sampling Variability for n=10 P-value = 2% i.e. about 2 out of 100 “average of 2” experiments will yield values 160 or higher even if the true mean weight is only 150 Two sided pvalue=4% average weight from samples of 100 Statistical Power We found the same sample mean (160 lbs) in our 100-doctor sample, 10-doctor sample, and 2-doctor sample. But we only rejected the null based on the 100-doctor and 10-doctor samples. Larger samples give us more statistical power… Can we quantify how much power we have for given sample sizes? Null Distribution: mean=150; sd=10.6 Rejection region. Any value >= 171 (150+10.6*1.96) Z/2 =1.96 gives 2.5% area in each tail (=.05) Z/2=1.96 gives 2.5% area in each tail (=.05) Power= chance of being in the rejection region if the alternative is true=area below Clinically relevant alternative: mean=160; sd=10.6 average weight from samples of 2 Rejection region. Any value >= 171 (150+10.6*1.96) 171 160 11 Z 1 10.6 10.6 Area 16% Only 16% power Power= chance of being in the rejection region=area below Null Distribution: mean=150; sd=4.74 Clinically relevant alternative: mean=160; sd=4.74 Rejection region. Any value >= 159.5 (150+4.74*1.96) Power= chance of being in the rejection region=area below average weight from samples of 10 Rejection region. Any value >= 159.5 (150+4.74*1.96) 159.5 160 Z .10 4.74 Area 50 % 50% power Power= chance of being in the rejection region=area below Rejection region. Any value >= 152.7 (150+1.37*1.96) Null Distribution: mean=150; sd=1.37 Power= chance of being in the rejection region if alternative is true Clinically relevant alternative: mean=160; sd=1.37 average weight from samples of 100 Nearly 100% power! Factors Affecting Power 1. Size of the difference (10 pounds higher) 2. Standard deviation of the characteristic (sd=15) 3. Bigger sample size 4. Significance level desired 1. Bigger difference from the null mean average weight from samples of 100 2. Bigger standard deviation average weight from samples of 100 3. Bigger Sample Size average weight from samples of 100 4. Higher significance level Rejection region. average weight from samples of 100 Examples of Sample Statistics: Single population mean Difference in means (ttest) Difference in proportions (Z-test) Odds ratio/risk ratio Correlation coefficient Regression coefficient … Example 2: Difference in means Example: Rosental, R. and Jacobson, L. (1966) Teachers’ expectancies: Determinates of pupils’ I.Q. gains. Psychological Reports, 19, 115-118. The Experiment (note: exact numbers have been altered) Grade 3 at Oak School were given an IQ test at the beginning of the academic year (n=90). Classroom teachers were given a list of names of students in their classes who had supposedly scored in the top 20 percent; these students were identified as “academic bloomers” (n=18). BUT: the children on the teachers lists had actually been randomly assigned to the list. At the end of the year, the same I.Q. test was readministered. The results Children who had been randomly assigned to the “top-20 percent” list had mean I.Q. increase of 12.2 points (sd=2.0) vs. children in the control group only had an increase of 8.2 points (sd=2.0) Is this a statistically significant difference? Give a confidence interval for this difference. Difference in means Sample statistic: Difference in mean change in IQ test score. Null hypothesis: no difference between “academic bloomers” and “normal students” Explore sampling distribution of difference in means Simulate 1000 differences in mean IQ change under the null hypothesis (both academic bloomer and controls improve by, let’s say, 8 points, with a standard deviation of 2.0) “academic bloomers” SE 2 18 .47 As expected, out of 1000 simulated experiments, most yielded a mean between 7.1 and 8.9 (±2 se) “normal students” SE 2 90 .21 As expected, out of 1000 simulated experiments, most yielded a mean between 7.5 and 8.5 (±2 se) Difference: academic bloomers-normal students Notice that most experiments yielded a difference value between –1.1 and 1.1 (wider than the above sampling distributions!) 22 22 SE(diff ) .52 18 90 Observed difference=4.0 P<.0001 Confidence interval (more information!!) 95% CI for the difference: 4.0±1.99(.52) = (3.0 – 5.0) Does not cross 0; We estimated the standard deviation of improvement on theat IQ.05. therefore, significant test, adding uncertainty; this gives us slightly wider cut-off’s for 95% area (t=1.99) than a normal curve (Z=1.96) 95% confidence interval for the observed difference: 4 ±2*.52=3-5 Critical value= 0+.52*1.96=1.04 Clearly lots of power to detect a difference of 4! How much power to detect a difference of 1.0? Critical value= 0+.52*1.96=1.04 Power closer to 50% now. Example 3: Difference in proportions Experimental question: Do men tend to prefer Bush more than women? Experimental design: Poll representative samples of men and women in the U.S. and ask them the question: do you plan to vote for Bush in November, yes or no? Sample statistic: The difference in the proportion of men who are pro-Bush versus women who are pro-Bush? Null hypothesis: the difference in proportions = 0 Observed results: women=.36; men=.46 Explore sampling distribution of difference in proportions Simulate 1000 differences in proportion preferring Bush under the null hypothesis (41% overall prefer Bush, with no difference between genders) men The standard error of a sample proportion is: p(1 p) n .41(1 .41) SE .07 50 Under the null hypothesis, most experiments yielded a mean between .27 and .55 women SE .41(1 .41) .07 50 Under the null hypothesis, most experiments yielded a mean between .27 and .55 Difference: men-women Observed difference: .41(1 .41) .41(1 .41) SE .10 50 50 Under the null hypothesis, most experiments yielded difference values between -.20 (women preferring Bush more than men) and .20 (men preferring Bush more) .46-. 36=10% (=1 standard error above the null mean) we’d expect to see a difference between genders this big 32% of the time just by chance What if we had 200 men and 200 women? men .41(1 .41) SE .035 200 Most of 1000 simulated experiments yielded a mean between .34 and .48 women SE .41(1 .41) .035 200 Most of 1000 simulated experiments yielded a mean between .34 and .48 Difference: men-women SE .41(1 .41) .41(1 .41) .05 200 200 Notice that most experiments will yield a difference value between -.10 (women preferring Bush more than men) and .10 (men preferring Bush more) Observed difference=10%; we can reject the null hypothesis of no difference at p<.05 What if we had 800 men and 800 women? men .41(1 .41) SE .017 800 Most experiments will yield a mean between .38 and.44 women SE .41(1 .41) .017 800 Most experiments will yield a mean between .38 and.44 Difference: men-women .41(1 .41) .41(1 .41) SE .025 800 800 Notice that most experiments will yield a difference value between -.05 (women preferring Bush more than men) and .05 (men preferring Bush more) A difference 5% or more would be statistically significant If we sampled 1600 per group, a 2.5% difference would be “statistically significant” at a significance level of .05. If we sampled 3200 per group, a 1.25% difference would be “statistically significant” at a significance level of .05. If we sampled 6400 per group, a .625% difference would be “statistically significant” at a significance level of .05. BUT if we found a “significant” difference of 1% between men and women, would we care if we were Bush or Kerry?? Limits of hypothesis testing: “Statistical vs. Clinical Significance” Consider a hypothetical trial comparing death rates in 12,000 patients with multi-organ failure receiving a new inotrope, with 12,000 patients receiving usual care. If there was a 1% reduction in mortality in the treatment group (49% deaths versus 50% in the usual care group) this would be statistically significant (p<.05), because of the large sample size. However, such a small difference in death rates may not be clinically important. Example 4: The odds ratio Experimental question: Does smoking increase fracture risk? Experiment: Ask 50 patients with fractures and 50 controls if they ever smoked. Sample statistic: Odds Ratio (measure of relative risk) Null hypothesis: There is no association between smoking and fractures (odds ratio=1.0). The Odds Ratio (OR) Smoker NonSmoker Fractured a b Control c d Odds of fracture among smokers OR a c b d ad bc Odds of fracture among nonsmokers Example 3: Sampling Variability of the null Odds Ratio (OR) (50 cases/50 controls/20% exposed) If the Odds Ratio=1.0 then with 50 cases and 50 controls, of whom 20% smoke, this is the expected variability of the sample ORnote the right skew The Sampling Variability of the natural log of the OR (lnOR) is more Gaussian Standard error = 1 1 1 1 a b c d Sample values far from lnOR=0 give us evidence of an association. These values are very unlikely if there’s no association in nature. Statistical Power Statistical power here is the probability of concluding that there is an association between exposure and disease if an association truly exists. – The stronger the association, the more likely we are to pick it up in our study. – The more people we sample, the more likely we are to conclude that there is an association if one exists (because the sampling variability is reduced). Part II: Biostatistics in Practice: Applying statistics to clinical research design From concept to protocol: Define your primary hypothesis Define your primary predictor and outcome variables Decide on study type (cross-sectional, case-control, cohort, RCT) Decide how you will measure your predictor and outcome variables, balancing statistical power, ease of measurement, and potential biases Decide on the main statistical tests that will be used in analysis Calculate sample size needs for your chosen statistical test/s Describe your sample size needs in your written protocol, disclosing your assumptions Write a statistical analysis plan: Briefly, describe descriptive statistics that you plan to present Describe which statistical tests you will use to test your primary hypotheses Describe which statistical tests you will use to test your secondary hypotheses Describe how you will account for confounders and test for interactions Describe any exploratory analyses that you might perform Consult with a statistician. Powering a study: What is the primary hypothesis? Before you can calculate sample size, you need to know the primary statistical analysis that you will use in the end. What is your main outcome of interest? What is your main predictor of interest? Which statistical test will you use to test for associations between your outcome and your predictor? Do you need to adjust sample size needs upwards to account for loss to follow-up, switching arms of a randomized trial, accounting for confounders? – Seek guidance from a statistician Overview of statistical tests The following table gives the appropriate choice of a statistical test or measure of association for various types of data (outcome variables and predictor variables) by study design. e.g., blood pressure= pounds + age + treatment (1/0) Continuous outcome Continuous predictors Dichotomous predictor Types of variables to be analyzed Predictor variable/s Outcome variable Statistical procedure or measure of association Cross-sectional/case-control studies Dichotomous Dichotomous Categorical Continuous Multivariate (categorical and continuous) Categorical Continuous Ranks/ordinal T-test Mann-Whitney U test Continuous Continuous ANOVA* Simple linear regression Continuous Multiple linear regression Categorical Chi-square test (or Fischer’s exact) Dichotomous Dichotomous Odds ratio, risk ratio Multivariate Dichotomous Logistic regression Cohort Studies/Clinical Trials Dichotomous Dichotomous Categorical Time-to-event Multivariate Time-to-event Risk ratio Kaplan-Meier curve/ logrank test Cox-proportional hazards regression, hazard ratio Comparing Groups T-test compares two means – (null hypothesis: difference in means = 0) ANOVA compares means between >2 groups – (null hypothesis: difference in means = 0) Non-parametric tests are used when normality assumptions are not met – (null hypothesis: difference in medians = 0) Chi-square test compares proportions between groups – (null hypothesis: categorical variables are independent) Simple sample size formulas/calculators available: Sample size for a difference in means Sample size for a difference in proportions – Can roughly be used if you plan to calculate risk ratios, odds ratios, or to run logistic regression or chi-square tests Sample size for a hazard ratio/log-rank test – If you plan to do survival analysis: Kaplan- Meier methods (log-rank test), Cox regression Types of variables to be analyzed Predictor variable/s Outcome variable Statistical procedure or measure of association Cross-sectional/case-control studies Dichotomous Dichotomous Categorical Continuous Multivariate (categorical and continuous) Categorical Dichotomous Multivariate Continuous Ranks/ordinal T-test Mann-Whitney U test Continuous Multiple linear regression Use sample size calculator Continuous ANOVA* for: difference in means Simple linear regression Continuous Categorical Chi-square test (or Fischer’s calculatorexact) Use sample size Odds ratio, risk ratio Dichotomous for: difference in proportions Dichotomous Logistic regression Cohort Studies/Clinical Trials Dichotomous Categorical Multivariate Dichotomous Risk ratio Kaplan-Meier curve/ logTime-to-event Use sample size calculator rank test for: hazard ratio Cox-proportional hazards Time-to-event regression, hazard ratio The pay-off for sitting through the theoretical part of these lectures! Here’s where it pays to understand what’s behind sample size/power calculations! You’ll have a much easier time using sample size calculators if you aren’t just putting numbers into a black box! RECALL: DIFFERENCE IN TWO MEANS Critical value= 0+standard error (sample statistic)*Z/2 Power= area to right of Z= Z critical value - alternative difference (here 1) standard error e.g. here :Z 0 ; power 50% standard error Power= area to right of Z= Z critical value - alternative difference (here 1) standard error Z/2 * standard error - difference Z standard error(diff) difference Z Z/2 standard error(diff) difference Z Z/2 standard error(diff) 2 s.e.(diff ) n1 2 n2 if ratio r of group 2 to group 1 : s.e.(diff ) Z difference 2 n1 2 rn1 ( Z Z/2 ) ( 2 Z/2 Z difference (r 1) 2 rn1 )2 difference (r 1) 2 rn1 2 n1 Z/2 2 rn1 ( r 1) ( Z Z/2 ) rn1difference 2 2 2 rn1difference2 (r 1) 2 ( Z Z/2 ) 2 ( r 1) ( Z Z/2 ) 2 n1 2 rdifference2 (r 1) ( Z Z/2 ) n1 2 r difference 2 If r 1 (equal groups), then n1 2 2 2 ( Z Z/2 ) 2 difference2 If this look complicated, don’t panic! In reality, you’re unlikely to have to derive sample size formulas yourself but it’s critical to understand where they come from if you’re going to apply them yourself. Formula for difference in means (r 1) ( Z Z/2 ) n1 2 r difference 2 2 where : n1 size of smaller group r ratio of larger group to smaller group standard deviation of the characteristic diffference clinically meaningful difference in means of the outcome Z corresponds to power (.84 80% power) Z / 2 corresponds to two - tailed significan ce level (1.96 for .05) Formula for difference in proportions (r 1) ( p)(1 p)(Z Z/2 ) n1 2 r (p1 p2 ) 2 where : n1 size of smaller group r ratio of larger group to smaller group p p1n1 p2 rn1 (average proportion ) (r 1)n1 p1 p2 clinically meaningful difference in proportion s Z corresponds to power (.84 80% power) Z / 2 corresponds to two - tailed significan ce level (1.96 for .05) Formula for hazard ratio/logrank test 1 1 ( Z / 2 Z ) n1 ( ) 2 rpc pt (ln HR) 2 n1 size of smaller group r ratio of control to treatment (unexposed to exposed) pc proportion of controls who will have the outcome pt proportion of treatment who will have the outcome pt 1 (1 pc ) HR HR clinically meaningful hazard ratio Z corresponds to power (.84 80% power) Z / 2 corresponds to two - tailed significan ce level (1.96 for .05) Recommended sample size calculators! http://hedwig.mgh.harvard.edu/sample_size/ size.html http://vancouver.stanford.edu:8080/clio/inde x.html Traverse protocol wizard These sample size calculations are idealized •We have not accounted for losses-to-follow up •We have not accounted for non-compliance (for intervention trial or RCT) •We have assumed that individuals are independent observations (not true in clustered designs) •Consult a statistician for these considerations! Applying statistics to clinical research design: Example You want to study the relationship between smoking and fractures. Steps: Define your primary hypothesis Define your primary predictor and outcome variables Decide on study type Applying statistics to clinical research design: Example predictor: smoking (yes/no or continuous) outcome: osteoporotic fracture (time-toevent) Study design: cohort From concept to protocol: Decide how you will measure your predictor and outcome variables Decide on the main statistical tests that will be used in analysis Calculate sample size needs for your chosen statistical test/s Types of variables to be analyzed Predictor variable/s Outcome variable Statistical procedure or measure of association Cross-sectional/case-control studies Dichotomous Dichotomous Categorical Continuous Multivariate (categorical and continuous) Categorical Continuous Ranks/ordinal T-test Mann-Whitney U test Continuous Continuous ANOVA* Simple linear regression Continuous Multiple linear regression Categorical Chi-square test (or Fischer’s exact) Dichotomous Dichotomous Odds ratio, risk ratio Multivariate Dichotomous Logistic regression Cohort Studies/Clinical Trials Dichotomous Categorical Multivariate Dichotomous Risk ratio Kaplan-Meier curve/ logTime-to-event Use sample size calculator rank test for: hazard ratio Cox-proportional hazards Time-to-event regression, hazard ratio Formula for hazard ratio/logrank test 1 1 ( Z / 2 Z ) n1 ( ) 2 rpc pt (ln HR) 2 n1 size of smaller group r ratio of control to treatment (unexposed to exposed) pc proportion of controls who will have the outcome pt proportion of treatment who will have the outcome pt 1 (1 pc ) HR HR clinically meaningful hazard ratio Z corresponds to power (.84 80% power) Z / 2 corresponds to two - tailed significan ce level (1.96 for .05) Example: sample size calculation Ratio of exposed to unexposed in your sample? – 1:1 Proportion of non-smokers who will fracture in your defined population over your defined study period? – 10% What is a clinically meaningful hazard ratio? – 2.0 Based on hazard ratio, how many smokers will fracture? – 1-90%^2 = 19% What power are you targeting? – 80% What significance level? – .05 Formula for hazard ratio/logrank test 1 1 (1.96 .84) n1 ( ) 250 per group .10 .19 (ln 2) 2 2 You may want to adjust upwards for loss to follow-up. E.g., if you expect to lose 10%, divide the above estimate by 90%. From concept to protocol: Describe your sample size needs in your written protocol, disclosing your assumptions Write a statistical analysis plan Types of variables to be analyzed Predictor variable/s Outcome variable Statistical procedure or measure of association Cross-sectional/case-control studies Dichotomous Dichotomous Categorical Continuous Multivariate (categorical and continuous) Categorical Continuous Ranks/ordinal T-test Mann-Whitney U test Continuous Continuous ANOVA* Simple linear regression Continuous Multiple linear regression Categorical Chi-square test (or Fischer’s exact) Dichotomous Dichotomous Odds ratio, risk ratio Multivariate Dichotomous Logistic regression Cohort Studies/Clinical Trials Dichotomous Dichotomous Categorical Time-to-event Multivariate Time-to-event Risk ratio Kaplan-Meier curve/ logrank test Cox-proportional hazards regression, hazard ratio Statistical analysis plan Descriptive statistics – E.g., of study population by smoking status Kaplan-Meier Curves (univariate) – Describe exploratory analyses that may be used to identify confounders and other predictors of fracture Cox regression (multivariate) – What confounders have you measured, and how will you incorporate them into multivariate analysis? – How will you explore for possible interactions? – Describe potential exploratory analysis for other predictors of fracture