Amino Acids Proteins, and Enzymes
advertisement

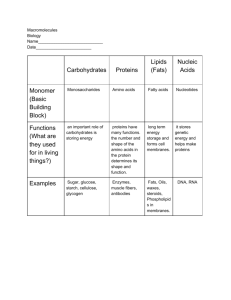
Chapter 3: Amino Acids, Peptides, and Proteins Dr. Clower Chem 4202 Outline (part I) Sections 3.1 and 3.2 Amino Acids Chemical structure Acid-base properties Stereochemistry Non-standard amino acids Formation of Peptide Bonds Amino Acids The building blocks of proteins Also used as single molecules in biochemical pathways 20 standard amino acids (a-amino acids) Two functional groups: carboxylic acid group amino group on the alpha (a) carbon Have different side groups (R) Properties dictate behavior of AAs R side chain | H2N— C —COOH | H Zwitterions Both the –NH2 and the –COOH groups in an amino acid undergo ionization in water. At physiological pH (7.4), a zwitterion forms Both + and – charges Overall neutral Amphoteric Amino group is protonated Carboxyl group is deprotonated Soluble in polar solvents due to ionic character Structure of R also influence solubility Classification of Amino Acids Classify by structure of R Nonpolar Polar Aromatic Acidic Basic Nonpolar Amino Acids Hydrophobic, neutral, aliphatic Polar Amino Acids Hydrophilic, neutral, typically H-bond Disulfide Bonds Formed from oxidation of cysteine residues Aromatic Amino Acids Bulky, neutral, polarity depend on R Acidic and Basic Amino Acids Acidic R group = carboxylic acid Donates H+ Negatively charged Basic R group = amine Accepts H+ Positively charged His ionizes at pH 6.0 Acid-base Properties Remember H3PO4 (multiple pKa’s) AAs also have multiple pKa’s due to multiple ionizable groups pK1 ~ 2.2 (protonated below 2.2) pK2 ~ 9.4 (NH3+ below 9.4) pKR (when applicable) Table 3-1 Note 3-letter and 1-letter abbreviations Amino acid organization chart pH and Ionization Consider glycine: O H3N CH C O OH O OH- OH- H3N CH C O + H3O H3O H Glycine ion at acidic pH (charge = 1+) H2N H Zwitterion of glycine (charge = 0) CH C + H Glycine ion at basic pH (charge = 1-) Note that the uncharged species never forms O Titration of Glycine pK1 pK2 [cation] = [zwitterion] [zwitterion] = [anion] First equivalence point Zwitterion Molecule has no net charge pH = pI (Isoelectric point) pI = average of pKa’s = ½ (pK1 + pK2) pIglycine = ½ (2.34 + 9.60) = 5.97 Animation pI of Lysine For AAs with 3 pKa’s, pI = average of two relevant pKa values Consider lysine (pK1 = 2.18, pK2 = 8.95, pKR = 10.53): O O O pK1 H3N CH C OH CH2CH2CH2CH2NH3+ O pK2 H3N CH C O pKR H2N CH2CH2CH2CH2NH3+ CH C O CH2CH2CH2CH2NH3+ Which species is the isoelectric form? So, pI = ½ (pK2 + pKR) H2N CH C CH2CH2CH2CH2NH2 = ½ (8.95 + 10.53) = 9.74 O Note: pKR is not always higher than pK2 (see Table 3-1 and Fig. 3-12) Learning Check Would the following ions of serine exist at a pH above, below, or at pI? O H3N CH C O O H3N CH C O OH H2N CH CH2 CH2 CH2 OH OH OH C O Stereochemistry of AAs All amino acids (except glycine) are optically active Fischer projections: D and L Configurations d = dextrorotatory l = levorotatory D, L = relative to glyceraldehyde Importance of Stereochemistry All AA’s found in proteins are L geometry S enantiomer for all except cysteine D-AA’s are found in bacteria Geometry of proteins affects reactivity (e.g binding of substrates in enzymes) Thalidomide Non-standard Amino Acids AA derivatives Modification of AA after protein synthesized Terminal residues or R groups Addition of small alkyl group, hydroxyl, etc. D-AAs Bacteria CHEM 2412 Review Carboxylic acid + amine = ? O O heat R C OH + H2N R R Structure of amino acid R H2N C H CO2H C NH R + H2O The Peptide Bond Chain of amino acids = peptide or protein Amino acid residues connected by peptide bonds Residue = AA – H2O The Peptide Bond Non-basic and non-acidic in pH 2-12 range due to delocalization of N lone pair O O C N H N Rigid restricted rotation H Amide linkage is planar, NH and CO are anti Polypeptides Linear polymers (no branches) AA monomers linked head to tail Terminal residues: Free amino group (N-terminus) Draw Free carboxylate group (C-terminus) Draw on left on right pKa values of AAs in polypeptides differ slightly from pKa values of free AAs Naming Peptides Name from the free amine (NH3+) Use -yl endings for the names of the amino acids The last amino acid with the free carboxyl group (COO-) uses its amino acid name (GA) Amino Acid Ambiguity Glutamate (Glu/E) vs. Glutamine (Gln/Q) Aspartate (Asp/D) vs. Asparagine (Asn/N) Converted via hydrolysis Use generic abbreviations for either Glx/Z Asx/B X = undetermined or nonstandard AA Learning Check Write the name of the following tetrapeptide using amino acid names and three-letter abbreviations. CH3 CH3 H3N S CH CH3 SH CH2 CH3 O CH O CH2 O CH2 O CH C N CH C N CH C N CH C O H H H - Learning Check Draw the structural formula of each of the following peptides. A. Methionylaspartic acid B. Alanyltryptophan C. Methionylglutaminyllysine D. Histidylglycylglutamylalanine Outline (part II) Sections 3.3 and 3.4 Separation and purification Protein sequencing Analysis of primary structure Protein size In general, proteins contain > 40 residues Minimum needed to fold into tertiary structure Usually 100-1000 residues Percent of each AA varies Proteins separated based on differences in size and composition Proteins must be pure to analyze, determine structure/function Factors to control pH Presence of enzymes Control denaturation (0-4°C) Control activity of enzymes Thiol groups May affect structure (e.g. proteases/peptidase) Temperature Keep pH stable to avoid denaturation or chemical degradation Reactive Add protecting group to prevent formation of new disulfide bonds Exposure to air, water Denature or oxidize Store under N2 or Ar Keep concentration high General Separation Procedure Detect/quantitate protein (assay) Determine a source (tissue) Extract protein Suspend cell source in buffer Homogenize Break into fine pieces Cells disrupted Soluble contents mix with buffer Centrifuge to separate soluble and insoluble Separate protein of interest Based on solubility, size, charge, or binding ability Solubility Selectively precipitate protein Manipulate Concentration of salts Solvent pH Temperature Concentration of salts Adding small amount of salt increases [Protein] Salt shields proteins from each other, less precipitation from aggregation Salting out Salting-in Continue to increase [salt] decreases [protein] Different proteins salt out at different [salt] Other Solubility Methods Solvent Similar theory to salting-out Add organic solvent (acetone, ethanol) to interact with water Decrease solvating power pH Proteins are least soluble at pI Isoelectric precipitation Temperature Solubility is temperature dependent Chromatography Mobile phase Mixture dissolved in liquid or solid Stationary phase Porous solid matrix Components of mixture pass through the column at different rates based on properties Types of Chromatography Paper Stationary phase = filter paper Same theory as thin layer chromatography (TLC) Components separate based on polarity High-performance liquid (HPLC) Stationary phase = small uniform particles, large surface area Adapt to separate based on polarity, size, etc. Hydrophobic Interaction Hydrophobic groups on matrix Attract hydrophobic portions of protein Types of Chromatography Ion-exchange Stationary phase = chemically modified to include charged groups Separate based on net charge of proteins Anion exchangers Cation groups (protonated amines) bind anions Cation exchangers Anion groups (carboxylates) bind cations Types of Chromatography Gel-filtration Size/molecular exclusion chromatography Stationary phase = gels with pores of particular size Molecules separate based on size Small molecules caught in pores Large molecules pass through Types of Chromatography Affinity Matrix chemically altered to include a molecule designed to bind a particular protein Other proteins pass through UV-Vis Spectroscopy Absorbance used to monitor protein concentrations of each fraction l = 280 nm Absorbance of aromatic side groups Electrophoresis Migration of ions in an electric field Electrophoretic mobility (rate of movement) function of charge, size, voltage, pH The positively charged proteins move towards the negative electrode (cathode) The negatively charged proteins move toward the positive electrode (anode) A protein at its pI (neutral) will not migrate in either direction Variety of supports (gel, paper, starch, solutions) Protein Sequencing Determination of primary structure Need to know to determine 3D structure Gives insight into protein function Approach: Denature protein Break protein into small segments Determine sequences of segments Animation End group analysis Identify number of terminal AAs Number of chains/subunits Identify specific AA Dansyl chloride/dabsyl chloride Sanger method (FDNB) Edman degradation (PITC) Bovine insulin Dansyl chloride Reacts with primary amines N N-terminus Yields dansylated polypeptides Dansylated polypeptides hydrolyzed to liberate the modified dansyl AA Dansyl AA can be identified by chromatography or spectroscopy (yellow fluorescence) Useful method when protein fragmented into shorter polypeptides O + H2N CH C R SO2 Cl N N H3O+ HCl + + other free AAs O SO2 HN CH R C O SO2 HN CH R C OH Dabsyl chloride and FDNB Same result as dansyl chloride N O N N S O Dabsyl chloride 1-Fluoro-2,4dinitrobenzene (FDNB) Sanger method Cl Edman degradation Phenylisothiocyanate (PITC) Reacts with N-terminal AA to produce a phenylthiocarbamyl (PTC) Treat with TFAA (solvent/catalyst) to cleave N-terminal residue Does not hydrolyze other AAs Treatment with dilute acid makes more stable organic compound Identify using NMR, HPLC, etc. Sequenator (entire process for proteins < 100 residues) Fragmenting Proteins Formation of smaller segments to assist with sequencing Process: Cleave protein into specific fragments Chemically or enzymatically Break disulfide bonds Purify fragments Sequence fragments Determine order of fragments and disulfide bonds Cleaving Disulfide Bonds Oxidize with performic acid O H C O OH Cys residues form cysteic acid Acid can oxidize other residues, so not ideal Cleaving Disulfide Bonds Reduce by mercaptans (-SH) 2-Mercaptoethanol HSCH2CH2OH Dithiothreitol (DTT) HSCH2CH(OH)CH(OH)CH2SH Reform cysteine residues Oxidize thiol groups with iodoacetete (ICH2CO2-) to prevent reformation of disulfide bonds Hydrolysis Cleaves all peptide bonds Achieved by After cleavage: Enzyme Acid Base Identify using chromatography Quantify using absorbance or fluorescence Disadvantages Doesn’t give exact sequence, only AAs present Acid and base can degrade/modify other residues Enzymes (which are proteins) can also cleave and affect results Enzymatic and Chemical Cleavage Enzymatic Enzymes used to break protein into smaller peptides Endopeptidases Catalyze hydrolysis of internal peptide bonds Chemical Chemical reagents used to break up polypeptides Cyanogen bromide (BrCN) An example Fundamentals of Protein Structure Our life is maintained by molecular network systems Molecular network system in a cell (From ExPASy Biochemical Pathways; http://www.expasy.org/cgi-bin/show_thumbnails.pl?2) Proteins play key roles in a living system Three examples of protein functions Alcohol dehydrogenase oxidizes alcohols to aldehydes or ketones Catalysis: Almost all chemical reactions in a living cell are catalyzed by protein enzymes. Transport: Some proteins transports various substances, such as oxygen, ions, and so on. Information transfer: For example, hormones. Haemoglobin carries oxygen Insulin controls the amount of sugar in the blood Amino acid: Basic unit of protein R NH3 + C Amino group H Different side chains, R, determin the COO properties of 20 Carboxylic amino acids. acid group An amino acid 20 Amino acids Glycine (G) Alanine (A) Valine (V) Isoleucine (I) Leucine (L) Proline (P) Methionine (M) Phenylalanine (F) Tryptophan (W) Asparagine (N) Glutamine (Q) Serine (S) Threonine (T) Tyrosine (Y) Cysteine (C) Lysine (K) Arginine (R) Histidine (H) Asparatic acid (D) Glutamic acid (E) White: Hydrophobic, Green: Hydrophilic, Red: Acidic, Blue: Basic Proteins are linear polymers of amino acids R1 R2 NH3+ C COO + NH3+ C COO + ー ー H H H 2O A carboxylic acid condenses with an amino group with the release of a water H 2O R1 R2 R3 NH3+ C CO NH C CO NH C CO H A F Peptide bond G N S Peptide bond H T D K G H S A The amino acid sequence is called as primary structure Amino acid sequence is encoded by DNA base sequence in a gene DNA molecule = ・ G C G C T T A A G C G C ・ ・ DNA base C G sequence C G A A T T C G C G ・ Amino acid sequence is encoded by DNA base sequence in a gene T T A G Phe Leu Leu Ile Met Val TCT TCC TCA TCG CCT CCC CCA CCG ACT ACC ACA ACG GCT GCC GCA GCG Ser Pro Thr Ala TAT TAC TAA TAG CAT CAC CAA CAG AAT AAC AAA AAG GAT GAC GAA GAG G Tyr Stop His Gln Asn Lys Asp Glu TGT TGC TGA TGG CGT CGC CGA CGG AGT AGC AGA AGG GGT GGC GGA GGG Cys Stop Trp Arg Ser Arg Gly T C A G T C A G T C A G T C A G Third letter First letter C TTT TTC TTA TTG CTT CTC CTA CTG ATT ATC ATA ATG GTT GTC GTA GTG C Second letter A Gene is protein’s blueprint, genome is life’s blueprint DNA Genome Gene Protein Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein Gene is protein’s blueprint, genome is life’s blueprint Glycolysis network Genome Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Gene Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein Protein In 2003, Human genome sequence was deciphered! Genome is the complete set of genes of a living thing. In 2003, the human genome sequencing was completed. The human genome contains about 3 billion base pairs. The number of genes is estimated to be between 20,000 to 25,000. The difference between the genome of human and that of chimpanzee is only 1.23%! 3 billion base pair => 6 G letters & 1 letter => 1 byte The whole genome can be recorded in just 10 CD-ROMs! Each Protein has a unique structure Amino acid sequence NLKTEWPELVGKSVEE AKKVILQDKPEAQIIVL PVGTIVTMEYRIDRVR LFVDKLDNIAEVPRVG Folding! Basic structural units of proteins: Secondary structure α-helix β-sheet Secondary structures, α-helix and β-sheet, have regular hydrogen-bonding patterns. Three-dimensional structure of proteins Tertiary structure Quaternary structure Hierarchical nature of protein structure Primary structure (Amino acid sequence) ↓ Secondary structure (α-helix, β-sheet) ↓ Tertiary structure (Three-dimensional structure formed by assembly of secondary structures) ↓ Quaternary structure (Structure formed by more than one polypeptide chains) Close relationship between protein structure Hormone and its function Antibody Example of enzyme reaction receptor substrates A enzyme enzyme B Matching the shape to A enzyme A Binding to A Digestion of A! Protein structure prediction has remained elusive over half a century “Can we predict a protein structure from its amino acid sequence?” Now, impossible! Summary Proteins are key players in our living systems. Proteins are polymers consisting of 20 kinds of amino acids. Each protein folds into a unique three-dimensional structure defined by its amino acid sequence. Protein structure has a hierarchical nature. Protein structure is closely related to its function. Protein structure prediction is a grand challenge of computational biology.