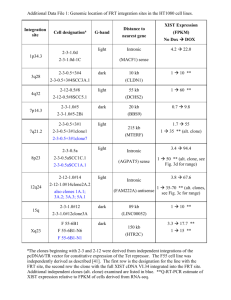
What are “Data Clones”?
advertisement

DATA CLONE DETECTION AND VISUALIZATION IN SPREADSHEETS Felienne Hermans, Ben Sedee, Martin Pinzger, and Arie van Deursen Delft University of Technology, Infotron Netherlands 1 AGENDA Introduction Motivation Part A – Data Clone Detection Part B – Clone Visualization Implementation and Evaluation Case Study Conclusion 2 AGENDA Introduction Motivation Part A – Data Clone Detection Part B – Clone Visualization Implementation and Evaluation Case Study Conclusion 3 ABOUT THE PAPER • Spreadsheets are widely used in industry • Spreadsheets are error-prone • Numerous companies have lost money because of spreadsheet errors One of the causes – “Copy-pasting” • In this paper: – Study cloning (copy-pasting) in spreadsheets – Provide an approach to detect and visualize clones in spreadsheet – Evaluate the proposed approach 4 Introduction INITIAL RESEARCH PROJECT • Study the “Gap” between business users and Programmers • Surprising finding – Some programmers were heavily involved in Business In Excel 5 Introduction NEW RESEARCH INTEREST Impact of Spreadsheets on Business • 95% of all US firms use spreadsheets for Financial reporting • 90% of all analysts in industry perform calculations in spreadsheets • 50% of spreadsheets form the basis for decisions Finding – Impact of spreadsheets grow over time 6 Introduction SPREADSHEETS ARE “UNDER THE RADAR” • • • • No lists of spreadsheets No tracking Do not have clear owner No proper documentation Complex spreadsheets without documentation can lead to serious errors 7 Introduction PREVIOUS RESEARCH ON SPREADSHEETS • Focused on analyzing and testing the “Formulas” • “Data” on spreadsheet calculations was “Overshadowed” 8 Introduction CLONE DETECTION IN SOURCE CODE • Text-based techniques - perform little or no transformation to the raw source code before attempting to detect identical lines of code • Token-based techniques - apply a lexical analysis (tokenization) to the source code and, subsequently, use the tokens as a basis for clone detection • AST-based techniques - use parsers to obtain a syntactical representation of the source code, typically an abstract syntax tree (AST). The clone detection algorithms then search for similar subtrees in this AST • PDG-based approaches – Program dependence graphs (PDGs) contain information of a semantical nature, such as control and data flow of the program. 9 Introduction HORROR STORIES • In 2003 TransAlta lost US$24 Million because of copy-paste error in spreadsheets • Federal Reserve made a copy-paste error in their customer credit statement – Could have led to difference of US$4 Billion 10 Introduction 11 Introduction 12 Introduction AGENDA Introduction Motivation Part A – Data Clone Detection Part B – Clone Visualization Implementation and Evaluation Case Study Conclusion 13 CO-RELATION TO CLONES IN SOFTWARE • Clones in spreadsheets have similar effect as of clones in software system – They make it error – prone – Have negative effect on Quality and Maintenance – Can lead to severe unexpected behavior 14 Motivation AIM • Do not aim to change user’s behavior • Follow an approach to mitigate risks by detecting and visualizing the copy-pasting relationships • Understand the impact and develop a strategy to automatically detect data clones in spreadsheets 15 Motivation THREE RESEARCH QUESTIONS 1. How often do data clones occur in spreadsheets? 2. What is the impact of data clones on spreadsheet quality? 3. Does our approach to detect and visualize data clones in spreadsheets support users in finding and understanding data clones? 16 Motivation AGENDA Introduction Motivation Part A – Data Clone Detection Part B – Clone Visualization Implementation and Evaluation Case Study Conclusion 17 WHAT ARE “DATA CLONES”? • Clones of Formula results copied as Data on other parts of spreadsheet 18 Part A – Data Clone Detection SOME TERMS TO REMEMBER • Clone • Clone Cluster • Matching Clone Clusters • Near-miss Clone Clusters 19 Part A – Data Clone Detection EXAMPLE USED IN FOLLOWING SLIDES Worksheet Name: Problem Data Copied Data Worksheet Name: Eff4 Worksheet that contains the formula 20 Part A – Data Clone Detection CLONE DETECTION TECHNIQUE The technique is based on existing text-based clone detection algorithm Algorithm steps: • Cell Classification – Divide the cells into data cells, formula cells and empty cells • Lookup creation – A lookup table of all cells is created, with the cell value as key and a list of locations as the value • Pruning – Remove all values from the lookup table that do not occur both in a formula and a constant cell • Cluster finding – The algorithm looks for clusters of neighboring cells that are all contained in a clone, and that are all either formula cells or constant cells • Cluster matching - Each formula cluster is matched with each constant cluster. 21 Part A – Data Clone Detection STEP 1: CELL CLASSIFICATION Data Cells 22 Formula Cells Part A – Data Clone Detection STEP 2: LOOK UP CREATION Cell Value as Key List of Locations as Value 23 Part A – Data Clone Detection STEP 3: PRUNING Remove: Not a clone 24 Part A – Data Clone Detection STEP 4: CLUSTER FINDING 25 Part A – Data Clone Detection STEP 5: CLUSTER MATCHING 26 Part A – Data Clone Detection INPUT PARAMETERS • StepSize – Indicates the search radius in terms of numbers of cells. Used in 4th Step (Finding Clusters) • MatchPercentage – 100% means the values have to match exactly, lower percentages allow for the detection of nearmiss clones. Used in 5th Step (Match Clusters) • MinimalClusterSize – Sets the minimal number of cells that a cluster has to consist of • MinimalDifferentValues – Represents the minimal number of different values that have to occur in a clone cluster • Define region for finding clones – Indicate whether clones are found within worksheets, between worksheets between spreadsheets or a combination of those 27 Part A – Data Clone Detection AGENDA Introduction Motivation Part A – Data Clone Detection Part B – Clone Visualization Implementation and Evaluation Case Study Conclusion 28 WAYS TO VISUALIZE CLONES • First Way – Dataflow Diagrams – Showing relations between worksheets • Second Way – Add pop-ups indicating Source and Copied Data 29 Part B – Clone Visualization DATA FLOW DIAGRAM Rectangles indicate Worksheets Arrows indicate Formula Dependencies Dashed Arrows indicate Data Clone Dependencies 30 Part B – Clone Visualization DATA FLOW DIAGRAM Eff4 Problem Data 31 Part B – Clone Visualization POP-UPS 32 Part B – Clone Visualization AGENDA Introduction Motivation Part A – Data Clone Detection Part B – Clone Visualization Implementation and Evaluation Case Study Conclusion 33 IMPLEMENTATION • Spreadsheet Analysis Tool – Breviz • Implemented using – C# 4.0 using Visual Studio 2010 – Utilizes Gembox component to read Excel Files • Also available as-a-service on Infotron’s Website 34 Implementation and Evaluation EVALUATION • Two approaches: – Quantitative Analyzed a subset of EUSES corpus – Qualitative Studied two real life cases 35 Implementation and Evaluation QUANTITATIVE EVALUATION • Goal: – To answer first research question: 1. How often do data clones occur in spreadsheets? – Evaluate algorithm performance in terms of execution time and in terms of the precision 36 Implementation and Evaluation SPREADSHEETS FROM THE EUSES CORPUS • Used by several researchers to evaluate spreadsheet algorithms • 11 different domains like educational, financial, inventory, biology • 4223 real-life spreadsheets • 1711 spreadsheets contain formulas 37 Quantitative Evaluation PARAMETERS FOR EVALUATION • MinimalClusterSize - Different Values • MinimalDifferentValues – Different Values • MatchPercentage – 100% • Search for clones not performed between domains 38 Quantitative Evaluation : EUSES Corpus DETERMINING FALSE POSITIVES • Manual Detection by inspecting clones and determining whether: – Clone clusters detected indeed have same value – One clone cluster has formula and other indeed has copied data – Headers of the clone clusters match 39 Quantitative Evaluation : EUSES Corpus FINDINGS • Precision: – % of Spreadsheets in which clone was Verified Total Number of Spreadsheets Detected – Results: For MinimalClusterSize = 5, MinimalDifferentValues = 3 (Lowest meaningful values) No. of spreadsheets detected = 157 No. of verified spreadsheets = 86 Precision = 54.8% Precision rises for higher values of two given parameters 40 Quantitative Evaluation : EUSES Corpus FINDINGS 41 Quantitative Evaluation : EUSES Corpus FINDINGS 42 Quantitative Evaluation : EUSES Corpus FINDINGS (CONTD.) • False Positives: – Header values – When values of two input parameters are below 6 – When some data are calculations while others are input – Array Formulas 43 Quantitative Evaluation : EUSES Corpus FINDINGS (CONTD.) • Performance: For 1711 Spreadsheet files in EUSES corpus, running time = 3 Hours, 49 Minutes and 14 Seconds = 8.1 Sec/file On an Average 44 Quantitative Evaluation : EUSES Corpus FINDINGS (CONTD.) • Clone occurrence: 1711 Spreadsheet files in EUSES corpus contain Formulas Which means around 5% (86/1711) of all spreadsheets contain verified clones 45 Quantitative Evaluation : EUSES Corpus FINDINGS (CONTD.) • Observations: – Cannot yet conclude impact of cloning on quality – Mostly, one spreadsheet is used for calculations, while other is used for reporting – Copies are used to sort – Sometimes, format of clones did not match 46 Quantitative Evaluation : EUSES Corpus QUALITATIVE EVALUATION • Goal: – To answer second and third research question: 2. What is the impact of data clones on spreadsheet quality? 3. Does our approach to detect and visualize data clones in spreadsheets support users in finding and understanding data clones? – Evaluate data clone detection and visualization approach 47 Implementation and Evaluation AGENDA Introduction Motivation Part A – Data Clone Detection Part B – Clone Visualization Implementation and Evaluation Case Study Conclusion 48 SETUP • Two Case Study : South-Dutch FoodBank and Delft University • Analyzed real-life spreadsheets in both case studies • Asked owner following questions – – – – – Is this a real clone, in other words: did you copy this data? Did this clone lead to errors or problems? Could this clone be replaced by a formula link? Asked questions about clones and the approach: • Do you know why no direct links were used initially? • How did the pop-ups help you in understanding the found data clones? • How did the dataflow diagrams help you in understanding the found data clones? 49 Case Study SOUTH-DUTCH FOODBANK • Use spreadsheets to keep track of food processed per month at distribution centers • Average processing of 130 KGs of food/month • Supplies to 27 local foodbanks • Problem: Result did not balance and food remained in center • Possible Cause: Copy-pasting practice • Received 31 sheets for analysis 50 Case Study FINDINGS • Settings: 31 spreadsheets MinimalClusterSize = 9 MatchingPercentage = 80% MinimalDifferentValues = 9 StepSize = 2 • • • • Performance: 3 Hrs, 9 Mins and 39 Secs = 6 Mins/file 145 Clones detected, 61 were near-miss False-positives: 1 Near-miss: Some updated values were correct. 25 of 61 near-miss clones were actual errors. • One Exact Clone was actually an error (Data copied into wrong column) • Result of Analysis: After fixing the clones the overall results were balanced 51 Case Study: FoodBank DELFT UNIVERSITY • Budget spreadsheet had to be created for grant proposal • Spreadsheet calculates salary costs of different employee • Salaries are raised every year and creator of the spreadsheet calculated it once and copied in different places in the spreadsheets 52 Case Study FINDINGS • Settings: 15 worksheets MinimalClusterSize = 9 MinimalDifferentValues = 9 MatchingPercentage = 80% StepSize = 2 • Performance: 3 Secs • 8 exact clones • No errors but analysis is very useful for improving the spreadsheet 53 Case Study: Delft University AGENDA Introduction Motivation Part A – Data Clone Detection Part B – Clone Visualization Implementation and Evaluation Case Study Conclusion 54 RESEARCH QUESTION REVISITED 1. How often do data clones occur in spreadsheets? A. Both EUSES case and the case studies suggest that clones occur often in spreadsheets 2. What is the impact of data clones on spreadsheet quality? A. Clones matching 100% mainly impact perspective, while Near-miss causes trouble 3. Does our approach to detect and visualize data clones in spreadsheets support users in finding and understanding data clones? A. Visualization aided users to quickly get an overview of the, otherwise hidden, copy dependencies 55 Conclusion CONCLUSION • Data clones in spreadsheets are common • Data clones in spreadsheets often indicate problems and weaknesses in spreadsheets • Algorithm is capable of detecting data clones quickly with 80% precision • Approach supports spreadsheet users in finding errors and possibilities for improving a spreadsheet 56 Conclusion QUESTIONS? Conclusion 57