Speech Coding

Human Speech Communication
message linguistic code (~ 50 b/s) motor control speech production
SPEECH SIGNAL (~50 kb/s)
speech perception cognitive processes linguistic code (~ 50 b/s) message
PCM (Pulse Code Modulation)
• Transmit value of each speech sample
– dynamic range of speech is about 50-60 dB
• 11 bits/sample
– maximum frequency in telephone speech is 3.4 kHz
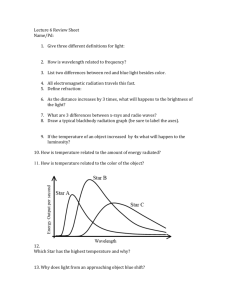
• sampling frequency 8 kHz
8000 x 11 = 88 kb/s
Simple and universal but not very efficient
Better quantization ?
• Less quantization noise for weaker signals
IN
OUT
Logarithmic PCM (
m
-law, A-law)
m - law
A - law
• Finer quantization for each individual small amplitude sample
– how about small signal samples surrounded by large ones?
– it is the instantaneous signal energy which should determine the step
?
Differential coding
current sample time
• For many natural signals, the difference between successive samples quantizes better than samples themselves
• Even better, predict the current sample from the past ones and transmit the error of the prediction
Differential predictive coding
• DPCM
– a single predictor reflecting global predictability of speech
– predictor order up to 4-5
– delta modulation - gross quantization of prediction error into 1 bit (typically requires up-sampling well over the Nyquist rate)
• adaptive DPCM
– new predictor for every new speech block
– predictor needs to be transmitted together with the prediction error
Speech Coders
Linear model of speech production
A.G. Bell got it almost right
linear model of speech source filter speech changes slowly
long-term prediction current sample short-term prediction time short-term - resonance of vocal tract long-term - periodicity of voiced speech (vocal cord vibration)
LPC vocoder
• The same principle as in H. Dudley’s Vocoder
• Used by US Government (LPC-10) - 2.4 kbs
Residual Excited LPC (RELP)
• Transmitter:
– Simplify prediction error (low-pass filter and down-sample
• Receiver
– re-introduce high frequencies in the simplified residual
(nonlinear distortion)
Analysis-by-synthesis
• Identical synthesizer in coder and in decoder
– change parameters in coder
– use for synthesizing speech
– compare synthesized speech with real speech
– when “close enough”, send parameters to the receiver
Future in speech coding?
• No need to transmit what we do not hear
– study human hearing, especially masking
• No need to transmit what is predictable
– speech production mechanism
– speaker characteristics
– linguistic code (recognition-synthesis)
– thought-to-speech
Automatic recognition of speech
prior knowledge
( textbook ) knowledge acquired knowledge
( data ) linguistic message reduce information = decrease entropy electric signal
(more than 50 kb/s) phoneme string
(below 50 b/s)
• Automatic speech recognition (ASR)
– derive proper response from speech stimulus
• Auditory perception
– how do biological systems respond to acoustic stimuli
• Knowledge of auditory perception ?
Principle of stochastic ASR
• Using a model of speech production process, generate all possible acoustic sequences w i for all legal linguistic messages
• Compare all generated sequences with the unknown acoustic input x to find which one is the most similar w
arg i max ( P (M( w i
) | x ))
1. What is the model
M ( w i
)
?
2. Form of the data x
?
One (simple) model
h e l o hello world u w o r l d
• Two dominant sources of variability in speech
1. people say the same thing with different speeds ( temporal variability )
2. different people sound different, communication environment different, ( feature variability)
• “Doubly stochastic” process (Hidden Markov Model)
– Speech as a sequence of hidden states - recover the state sequence
1. never know for sure in which state we are
2. never know for sure which data can be generated from a given state
Hidden Markov Model
f
0
=160 Hz 170 Hz 160 Hz 170 Hz 200 Hz 110 Hz 140 Hz 240 Hz170 Hz 190 Hz hi hi hi hi hi hi hi hi hi hi m f m m m m m f m m
The model p
1m p m m p m-f p f f p f-m
P(sound|gender) m f f
0 sequence of male and female groups?
160 170 160 170 200 110 140 240 170 190 m f m
x
f m units of speech
(phonemes)
What the x should be ?
Speech signal ?
• Reflects changes in acoustic pressure
– its original purpose is reconstruction of speech
– does carry relevant information
• always also carry some irrelevant information
– additional processing is necessary to alleviate it
histogram
speech signal
correlations
Where Is The Message ?
Isaac Newton
/u/ /o/ /a/ / e
/ /iy/ l/4 beer averaged fft spectra of some vowels from
3 hours of fluent speech
/uw//ao//ah//eh//ih
//iy/
•
it is in the spectrum !!
Inertia in engineering
Internal Combustion Engine (2003) Steam Engine (1769)
Short-term Spectrum
10-20 ms get spectral components
/ j/ /u/ /a r
/ /j/ /o/ /j/ /o/ time time
short-term speech spectral envelope
histogram correlations
logarithmic short-term speech spectral envelope
histogram correlations
cosine transform of logarithmic short-term speech spectral envelope
(cepstrum)
histogram correlations
What Is Wrong With the Short-term
Spectrum ?
1) inconsistent (same message, different representation) short-term spectrum frequency auditory-like modifications
“auditory-like” spectrum
Pitch of the tone (Mel scale)
• Frequency resolution of human ear decreases with frequency
Emulating frequency resolution of human ear with FFT
FFT t f
S
“critical-band energy”
Equal Loudness Curves
Perceptual Linear
Prediction (PLP)
[Hermansky 1990]
• Auditory-like modifications of short-term speech spectrum prior to its approximation by all-pole autoregressive model
– critical-band spectral resolution
– equal-loundness sensitivity
– intensity-loudness nonlinearity
• Today applied in virtually all state-of-the-art experimental
ASR systems
Spectral Basis from LDA
LDA gives basis for projection of spectral space
/j/ /u/ /a r
/ /j/ /o/ /j/ /o/ time
LDA vectors from Fourier Spectrum
63 % 16 %
Spectral resolution of LDAderived spectral basis is higher at low frequencies
Critical bands of human hearing are narrower at lower frequencies
12 % 2 %
Sensitivity to Spectral Change
(Malayath 1999)
Cosine basis LDA-derived bases Critical-band filterbank
Combination of channel and signal spectrum should be as flat (as randomlike) as possible.
– Shannon, Communication in presence of noise (1949) level of noise in the channel energy of the signal resource space energy of the signal if the receiver could be controlled
– put more resources (introduce less noise) where there is more signal
– biological system optimized for information extraction from sensory signals
if signal could be controlled (e.g. in communication)
– put more signal where there is less noise
– sensory signal optimized for a given communication channel level of noise in the channel resource space
What Is Wrong With the Short-term Spectral Envelope?
2) Fragile (easily corrupted by minor disturbances) spectrum f additive band-limited noise ignore the noisy parts of the spectrum f f linear (high-pass) filtering remove means from parts of the spectrum
threshold of perception of the tone
Simultaneous Masking band-pass filtered noise centered at f tone at f critical bandwidth
• Nonlinear frequency resolution of hearing
– Critical bands
• up to ~600 Hz constant bandwidth
• above 1 kHz constant Q noise bandwidth
More Important Outcome of Masking Experiments
• What happens outside the critical band does not affect detection of events within the band !!!
• Independent processing of parts of the spectrum ?
S ( frequency ) p f1 p f2 p f3 p f4 p f5 p f6
( Hermansky, Sharma and Pavel 1996, Bourlard and Dupont 1996 )
{p(f)}
Replace spectral vector by a matrix of posterior probabilities of acoustic events frequency
What Is Wrong With the Short-term Spectral Envelope?
3) Coarticulation (inertia of organs of speech production) h e l o coarticulation u w o r l d human auditory perception
Masking in Time
masker time t signal increase in threshold stronger masker
0 t
200 ms
• suggests ~200 ms buffer in auditory system
– also seen in perception of loudness, detection of short stimuli, gaps in tones, auditory afterimages, binaural release from masking, …..
– what happens outside this buffer, does no affect detection of signal within the buffer
Short-term Features?
~
10 ms time processing time longer time span ?
(~250 ms?) data x
Cortical Receptive Fields
• time-frequency distribution of the linear component of the most efficient stimulus that excites the given auditory neuron
Average of the first two principal components ( 83% of variance ) along temporal axis from about 180 cortical receptive fields ( from D. Klein 2004, unpublished )
Data for Deriving Posterior Probabilities of Speech Events
250-1000 ms
1-3 critical bands
FREQUENCY
TIME [s]
How to Get Estimates of Temporal Evolution of Spectral Energy ?
- with M. Athineos, D. Ellis (Columbia Univ), and P. Fousek (CTU Prague) time
10-20 ms
200-1000 ms data x
1-3 Bark
200-1000 ms time all-pole model of part of time-frequency plane
200-1000 ms
1-3 Bark
DCT of the signal
Hilbert envelope of the signal all-pole model of the Hilbert envelope
All-pole Model of Temporal Trajectory of Spectral Energy spectral domain LP conventional LP the signal signal power spectrum all-pole model of the power spectrum
All-pole Models of Sub-band Energy Contours low frequency prediction all-pole model of lowfrequency
Hilbert envelope signal discrete cosine transform high frequency prediction all-pole model of high-frequency
Hilbert envelope
Critical-band Spectrum From FFT
Critical-band Spectrum From All-pole Models time
Of Hilbert Envelopes in Critical Bands time
Putting It All Together
• TRAP-TANDEM
– data-guided features based on frequency-independent processing of relatively long spans of signal
• with S. Sharma, P. Jain, S. Sivadas, ICSI Berkeley and TU Brno data data class posteriors processing
( trained NN ) processing
( trained NN ) processing
( trained NN ) some function of phoneme posteriors time