ucf-talk - Department of Computer and Information Science and
advertisement

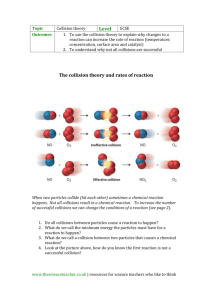
Interacting With Dynamic Real Objects in a Virtual Environment Benjamin Lok February 14th, 2003 Outline • Motivation • Incorporation of Dynamic Real Objects • Managing Collisions Between Virtual and Dynamic Real Objects • User Study • NASA Case Study • Conclusion Why we need dynamic real objects in VEs How we get dynamic real objects in VEs What good are dynamic real objects? Applying the system to a driving real world problem Assembly Verification • Given a model, we would like to explore: – Can it be readily assembled? – Can repairers service it? • Example: – Changing an oil filter – Attaching a cable to a payload Current Immersive VE Approaches • Most objects are purely virtual – User – Tools – Parts • Most virtual objects are not registered with a corresponding real object. • System has limited shape and motion information of real objects. Ideally • Would like: – Accurate virtual representations, or avatars, of real objects – Virtual objects responding to real objects – Haptic feedback – Correct affordances – Constrained motion • Example: Unscrewing a virtual oil filter from a car engine model Dynamic Real Objects • Tracking and modeling dynamic objects would: – Improve interactivity – Enable visually faithful virtual representations • Dynamic objects can: – Change shape – Change appearance Thesis Statement Naturally interacting with real objects in immersive virtual environments improves task performance and presence in spatial cognitive manual tasks. Previous Work: Incorporating Real Objects into VEs • Non-Real Time – Virtualized Reality (Kanade, et al.) • Real Time – Image Based Visual Hulls [Matusik00, 01] – 3D Tele-Immersion [Daniilidis00] • Augment specific objects for interaction – Doll’s head [Hinkley94] – Plate [Hoffman98] • How important is to get real objects into a virtual environment? Previous Work: Avatars • Self - Avatars in VEs – What makes avatars believable? [Thalmann98] – What avatars components are necessary? [Slater93, 94, Garau01] • VEs currently have: – Choices from a library – Generic avatars – No avatars • Generic avatars > no avatars [Slater93] • Are visually faithful avatars better than generic avatars? Visual Incorporation of Dynamic Real Objects in a VE Motivation • Handle dynamic objects (generate a virtual representation) • Interactive rates • Bypass an explicit 3D modeling stage • Inputs: outside-looking-in camera images • Generate an approximation of the real objects (visual hull) Reconstruction Algorithm 1. Start with live camera images 2. Image Subtraction 3. Use images to calculate volume intersection … … 4. Composite with the VE Visual Hull Computation • Visual hull - tightest volume given a set of object silhouettes • Intersection of the projection of object pixels Visual Hull Computation • Visual hull - tightest volume given a set of object silhouettes • Intersection of the projection of object pixels Volume Querying • A point inside the visual hull projects onto an object pixel from each camera Implementation • 1 HMD-mounted and 3 wall-mounted cameras • SGI Reality Monster – handles up to 7 video feeds • Computation – Image subtraction is the most work – ~16000 triangles/sec, 1.2 gigapixels • 15-18 fps • Estimated error: 1 cm • Performance will increase as graphics hardware continues to improve Results Managing Collisions Between Virtual and Dynamic Real Objects Approach • We want virtual objects respond to real object avatars • This requires detecting when real and virtual objects intersect • If intersections exist, determine plausible responses Assumptions • Only virtual objects can move or deform at collision. • Both real and virtual objects are assumed stationary at collision. • We catch collisions soon after a virtual object enters the visual hull, and not as it exits the other side. Detecting Collisions Resolving Collisions Approach 1. Estimate point of deepest virtual object penetration 2. Define plausible recovery vector 3. Estimate point of collision on visual hull Resolving Collisions Approach 1. Estimate point of deepest virtual object penetration 2. Define plausible recovery vector 3. Estimate point of collision on visual hull Resolving Collisions Approach 1. Estimate point of deepest virtual object penetration 2. Define plausible recovery vector 3. Estimate point of collision on visual hull Resolving Collisions Approach 1. Estimate point of deepest virtual object penetration 2. Define plausible recovery vector 3. Estimate point of collision on visual hull Resolving Collisions Approach 1. Estimate point of deepest virtual object penetration 2. Define plausible recovery vector 3. Estimate point of collision on visual hull Results Results Collision Detection / Response Performance • Volume-query about 5000 triangles per second • Error of collision points is ~0.75 cm. – Depends on average size of virtual object triangles – Tradeoff between accuracy and time – Plenty of room for optimizations Spatial Cognitive Task Study Study Motivation • Effects of – Interacting with real objects – Visual fidelity of self-avatars • On – Task Performance – Presence • For spatial cognitive manual tasks Spatial Cognitive Manual Tasks • Spatial Ability – Visualizing a manipulation in 3-space • Cognition – Psychological processes involved in the acquisition, organization, and use of knowledge Hypotheses • Task Performance: Participants will complete a spatial cognitive manual task faster when manipulating real objects, as opposed to virtual objects only. • Sense of Presence: Participants will report a higher sense of presence when their selfavatars are visually faithful, as opposed to generic. Task • Manipulated identical painted blocks to match target patterns • Each block had six distinct patterns. • Target patterns: – 2x2 blocks (small) – 3x3 blocks (large) Measures • Task performance – Time to complete the patterns correctly • Sense of presence – (After experience) Steed-Usoh-Slater Sense of Presence Questionnaire (SUS) • Other factors – (Before experience) spatial ability – (Before and after experience) simulator sickness Conditions Purely Virtual • All participants did the task in a real space environment. • Each participant did the task in one of three VEs. Real Space Hybrid Vis. Faithful Hybrid Conditions Sense of presence Avatar Fidelity Visually Generic faithful Task performance Interact with Real objects HE Virtual objects PVE VFHE Real Space Environment • Task was conducted within a draped enclosure • Participant watched monitor while performing task • RSE performance was a baseline to compare against VE performance Purely Virtual Environment • Participant manipulated virtual objects • Participant was presented with a generic avatar Hybrid Environment • Participant manipulated real objects • Participant was presented with a generic avatar Visually-Faithful Hybrid Env. • Participant manipulated real objects • Participant was presented with a visually faithful avatar Task Performance Results 120.00 Time (seconds) 100.00 80.00 Real Space Purely Virtual Hybrid Visually Faithful Hybrid 60.00 40.00 20.00 0.00 Small Large Small Pattern Time (seconds) Large Pattern Time (seconds) Mean S.D. Mean S.D. Real Space (n=41) 16.8 6.3 37.2 9.0 Purely Virtual (n=13) 47.2 10.4 117.0 32.3 Hybrid (n=13) 31.7 5.7 86.8 26.8 Visually Faithful Hybrid (n=14) 28.9 7.6 72.3 16.4 Task Performance Results 120.00 Time (seconds) 100.00 80.00 Real Space Purely Virtual Hybrid Visually Faithful Hybrid 60.00 40.00 20.00 0.00 Small Large Small Pattern Time Large Pattern Time T-test p T-test p Purely Virtual vs. Vis. Faithful 3.32 0.0026** 4.39 0.00016*** Purely Virtual vs. Hybrid 2.81 0.0094** 2.45 0.021* Hybrid vs. Vis. Faithful Hybrid 1.02 0.32 2.01 0.055 * - significant at the =0.05 level ** - =0.01 level *** - =0.001 level Sense of Presence Results Mean Sense of Presence Score SUS Sense of Presence Score 3.5 3.0 2.5 2.0 1.5 1.0 0.5 0.0 PVE HE VFHE VE Condition SUS Sense of Presence Score (0..6) Mean S.D. Purely Virtual Environment 3.21 2.19 Hybrid Environment 1.86 2.17 Visually Faithful Hybrid Environment 2.36 1.94 Sense of Presence Results Mean Sense of Presence Score SUS Sense of Presence Score 3.5 3.0 2.5 2.0 1.5 1.0 0.5 0.0 PVE HE VFHE VE Condition Sense of Presence T-test p Purely Virtual vs. Visually Faithful Hybrid 1.10 0.28 Purely Virtual vs. Hybrid 1.64 0.11 Hybrid vs. Visually Faithful Hybrid 0.64 0.53 Debriefing Responses • They felt almost completely immersed while performing the task. • They felt the virtual objects in the virtual room (such as the painting, plant, and lamp) improved their sense of presence, even though they had no direct interaction with these objects. • They felt that seeing an avatar added to their sense of presence. • PVE and HE participants commented on the fidelity of motion, whereas VFHE participants commented on the fidelity of appearance. • VFHE and HE participants felt tactile feedback of working with real objects improved their sense of presence. • VFHE participants reported getting used to manipulating and interacting in the VE significantly faster than PVE participants. Study Conclusions • Interacting with real objects provided a quite substantial performance improvement over interacting with virtual objects for cognitive manual tasks • Debriefing quotes show that the visually faithful avatar was preferred, though reported sense of presence was not significantly different. • Kinematic fidelity of the avatar is more important than visual fidelity for sense of presence. Handling real objects makes task performance and interaction in the VE more like the actual task. Case Study: NASA Langley Research Center (LaRC) Payload Assembly Task NASA Driving Problems • Given payload models, designers and engineers want to evaluate: – Assembly feasibility – Assembly training – Repairability • Current Approaches – Measurements – Design drawings – Step-by-step assembly instruction list – Low fidelity mock-ups Task • Wanted a plausible task given common assembly jobs. • Abstracted a payload layout task – Screw in tube – Attach power cable Task Goal • Determine how much space should be allocated between the TOP of the PMT and the BOTTOM of Payload A Videos of Task Results The tube was 14 cm long, 4cm in diameter. Participant #1 (Pre-experience) How much space is 14 cm necessary? #2 14.2 cm #3 #4 15 – 16 cm 15 cm (Pre-experience) How much space would you actually allocate? 21 cm 16 cm 20 cm 15 cm Actual space required in VE 15 cm 22.5 cm 22.3 cm 23 cm (Post-experience) How much space would you actually allocate? 18 cm 16 cm (modify tool) 25 cm 23 cm Results Participant Time cost of the spacing error Financial cost of the spacing error #1 #2 #3 #4 days to months 30 days days to months months $100,000s $1,000,000+ largest cost is huge hit in schedule $100,000s $1,000,000+ $100,000s • Late discovery of similar problems is not uncommon. Case Study Conclusions • Object reconstruction VEs benefits: – Specialized tools and parts require no modeling – Short development time to try multiple designs – Allows early testing of subassembly integration from multiple suppliers • Can get early identification of assembly, design, or integration issues that results in considerable savings in time and money. Conclusions Overall Innovations • Presented algorithms for – Incorporation of real objects into VEs – Handling interactions between real and virtual objects • Conducted formal studies to evaluate – Interaction with real vs. virtual object (significant effect) – Visually faithful vs. generic avatars (no significant effect) • Applied to real-world task Future Work • Improved model fidelity • Improved collision detection and response • Further studies to illuminate the relationship between avatar kinematic fidelity and visual fidelity • Apply system to upcoming NASA payload projects. Current Projects at UNC-Charlotte with Dr. Larry Hodges • Digitizing Humanity – If a virtual human gave you a compliment, would it brighten your day? – Do people interact with virtual characters the same way they do with real people? (carry over from reality -> virtual) Diana Current Projects at UNC-Charlotte with Dr. Larry Hodges • Digitizing Humanity – Basic research into virtual characters • What is important? • How does personality affect interaction? – Applications: • Social situations • Human Virtual-Human Interaction • Virtual Reality – Basic Research: • Incorporating Avatars • Locomotion Effect on Cognitive Performance – Applications: • Balance Disorders (w/ Univ. of Pittsburg) Current Projects at UNC-Charlotte with Dr. Larry Hodges • Combining Computer Graphics with: – Computer Vision • Dr. Min Shin – Human Computer Interaction • Dr. Larry Hodges, Dr. Jee-In Kim – Virtual Reality • Dr. Larry Hodges – Graduate and Undergraduate Research • Future Computing Lab has 4 PhD, 3 MS, and 6 undergraduates Collaboration on Research • Digital Media – Applying VR/Computer Graphics to: – Digital Archaeology (Digital records of historic data) – Digital Media Program (Getting non-CS people involved in VR) – Mixed Reality • Computer Vision/Image Processing – Using VR technology to aid in object tracking – Using computer vision to augment VR interaction • Computer Graphics Lab – Photorealistic Rendering • Novel Visualization – Evolutionary Computing Lab – Central Florida Remote Sensing Lab Future Directions • Long Term Goals – Enhance other CS projects with Graphics, Visualization, VR. – Computer Scientists are Toolsmiths – Help build the department into a leader in using graphics for visualization, simulation, and training. – Effective Virtual Environments (Graphics, Virtual Reality, and Psychology) – Digital Characters (Graphics & HCI) • Additional benefit of having nearby companies (Disney) and military – Assistive Technology (Graphics, VR, and Computer Vision) Thanks Thanks Collaborators Dr. Frederick P. Brooks Jr. (PhD Advisor) Dr. Larry F. Hodges (Post-doc advisor) Prof. Mary Whitton Samir Naik Danette Allen (NASA LaRC) UNC-CH Effective Virtual Environments UNC-C Virtual Environments Group For more information: http://www.cs.uncc.edu/~bclok (VR2003, I3D2003) Funding Agencies The LINK Foundation NIH (Grant P41 RR02170) National Science Foundation Office of Navel Research Object Pixels • Identify new objects • Perform image subtraction • Separate the object pixels from background pixels current image - background image = object pixels Volume Querying • Next we do volume querying on a plane Volume Querying • For an arbitrary view, we sweep a series of planes. Detecting Collisions Approach For virtual object i Volume query each triangle N Done with object i Y Are there real-virtual collisions? Determine points on virtual object in collision Calculate plausible collision response Research Interests • Computer Graphics – computer scientists are toolsmiths – Applying graphics hardware to: • 3D reconstruction • simulation – Visualization – Interactive Graphics • Virtual Reality – What makes a virtual environment effective? – Applying to assembly verification & clinical psychology • Human Computer Interaction – 3D Interaction – Virtual Humans • Assistive Technology – Computer Vision and Mobile Technology to help disabled