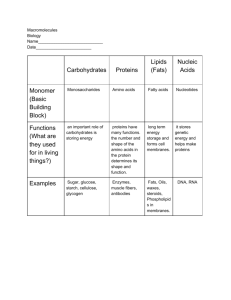
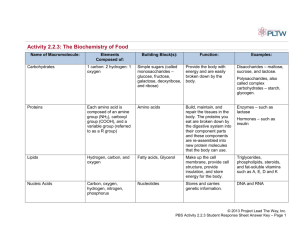
Proteins: Cell Overview & Core

Proteins: Structure and Function
Proteins
1.
Cellular Overview
1. Functions
2. Key Properties
2.
Core Topics
1. Amino Acids: properties, classifications, pI
2. Primary Structure, Secondary Structure, and
Motifs
3. Tertiary Structure
1. Fibrous vs. Globular
4. Quaternary Structure
Amazing Proteins: Function
1.
Catalysts (Enzymes)
•The largest class of proteins, accelerate rates of reactions
DNA Polymerase Catalase
2.
Transport & Storage
CK2 Kinase
Hemoglobin Serum albumin
Ion channels
Ovalbumin Casein
Amazing Proteins: Function
4.
Structural
Collagen Keratin
5.
Generate Movement
Silk Fibroin
Actin Myosin
Amazing Proteins: Function
5.
Regulation of Metabolism and Gene Expression
6.
Protection
Insulin Lac repressor
Immunoglobulin
Thrombin and
Fibrinogen
Venom Proteins
Ricin
Amazing Proteins: Function
7.
Signaling and response (inter and intracellular)
Membrane proteins
Signal transduction
Apoptosis
Amazing Proteins: Properties
• Biopolymers of amino acids
• Contains a wide range of functional groups
• Can interact with other proteins or other biological macromolecules to form complex assemblies
• Some are rigid while others display limited flexibility
a-
Amino Acids: Protein Building Blocks
R-group or side-chain a
-amino group
R
H
3
N
+
C
H
O
C
O
-
Carboxyl group acarbon
Amino acids are zwitterionic
• “Zwitter” = “hybrid” in German
R
1 O
H
2
N C C
H
OH O
-
• Fully protonated forms will have specific pKa’s for the different ionizable protons
• Amino acids are amphoteric (both acid and base)
Stereochemistry of amino acids
Stereochemistry of amino acids (AA)
• AA’s synthesized in the lab are racemic mixtures.
AA’s from nature are “L” isomers
• These are all optically-active except for glycine
(why?)
Synthesis of Proteins
R
1
H
3
N
+
C
H
O
C
O
-
+
R
2
H
3
N
+
C
H
O
C
O
-
R
1
O
H
3
N
+
C C
H peptide bond
NH
R
2
C
H
O
C
O
-
+ H
2
O
Synthesis of Proteins
R
1
O
H
3
N
+
C C
H
R
2
NH C
H
O
C
O
-
+
R
3
H
3
N
+
C
H
O
C
O
-
R
1
O
H
3
N
+
C C
H
NH
R
2
O
C C
H
NH
R
3
C
H
O
C
O
-
Synthesis of Proteins
R
1
O
H
3
N
+
C C
H
NH
R
2
C
O
C
H
NH
R
3
C
H
O
C
O
-
+
H
3
N
+
R
4
C
H
O
C
O
-
R
1
O
H
3
N
+
C C
H
NH
R
2
C
O
C
H
NH
N-Terminal End
R
3
C
H
O
C
NH
R
4
C
H
O
C
O
-
C-Terminal End
Synthesis of Proteins
R
1
O
H
3
N
+
C C
H
NH
R
2
C
O
C
H
NH
R
3
C
H
O
C NH
R
4
C
H
O
C
O
-
R
4
O
H
3
N
+
C C
H
NH
R
2
O
C C
H
NH
R
3
C
H
O
C NH
R
1
C
H
O
C
O
-
Synthesis of Proteins
R
1
O
H
3
N
+
C C
H
NH
R
2
C
O
C
H
NH
R
3
C
H
O
C NH
R
4
C
H
O
C
O
-
R
1
O
H
3
N
+
C C
H
NH
R
3
C
O
C
H
NH
R
2
C
H
O
C NH
R
4
C
H
O
C
O
-
Synthesis of Proteins
R
1
O
H
3
N
+
C C
H
R
4
O
H
3
N
+
C C
H
R
1
O
H
3
N
+
C C
H
NH
R
2
C
O
C
H
NH
≠
NH
R
2
C
O
C
H
NH
≠
NH
R
3
C
O
C
H
NH
R
3
C
H
O
C NH
R
2
C
H
R
3
C
H
O
C NH
O
C NH
R
4
C
H
O
C
O
-
R
1
C
H
O
C
O
-
R
4
C
H
O
C
O
-
COMMON AMINO ACIDS
20 common amino acids make up the multitude of proteins we know of
Amino Acids With Aliphatic Side Chains
Amino Acids With Aliphatic Side Chains
Amino Acids With Aliphatic Side Chains
Amino Acids With Aromatic Side Chains
Amino Acids with Aromatic Side Chains Can Be
Analyzed by UV Spectroscopy
Amino Acids With Hydroxyl Side Chains
Amino Acid with a Sulfhydryl Side Chain
Disulfide Bond Formation
Amino Acids With Basic Side Chains
Amino Acids With Acidic Side Chains and Their
Amide Derivatives
There are some important uncommon amino acids we shall still encounter later on.
pH and Amino Acids
Net charge: +1 Net charge: 0 Net charge: -1
Characteristics of Acidic and Basic Amino Acids
• Acidic amino acids
▫ Low pK a
▫ Negatively charged at physiological pH
▫ Side chains with –COOH
▫ Predominantly in unprotonated form
• Basic amino acids
▫ High pK a
▫ Function as bases at physiological pH
▫ Side chains with N
We use different “levels” to fully describe the structure of a protein.
Primary Structure
• Amino acid sequence
• Standard: Left to Right means N to C-terminal
• Eg. Insulin (AAA40590)
MAPWMHLLTVLALLALWGPNSVQAYSSQHLCG
SNLVEALYMTCGRSGFYRPHDRRELEDLQVEQ
AELGLEAGGLQPSALEMILQKRGIVDQCCNNI
CTFNQLQNYCNVP
• The info needed for further folding is contained in the 1 o structure.
Secondary Structure
• The regular local structure based on the hydrogen bonding pattern of the polypeptide backbone
▫ α helices
▫ β strands (β sheets)
▫ Turns and Loops
• WHY will there be localized folding and twisting? Are all conformations possible?
α Helix
•First proposed by Linus Pauling and Robert Corey in 1951.
•3.6 residues per turn, 1.5 Angstroms rise per residue
•Residues face outward
α Helix
• α-helix is stabilized by H-bonding between CO and NH groups
• Except for amino acid residues at the end of the α-helix, all main chain CO and NH are H-bonded
α Helix representation
β strand
• Fully extended
• β sheets are formed by linking 2 or more strands by H-bonding
• Beta-sheet also proposed by Corey and Pauling in 1951.
PARALLEL
ANTIPARALLEL
The Beta Turn
(aka beta bend, tight turn)
•allows the peptide chain to reverse direction
•carbonyl C of one residue is H-bonded to the amide proton of a residue three residues away
•proline and glycine are prevalent in beta turns
Mixed β Sheets
Twisted β Sheets
Loops
What Determines the Secondary Structure?
• The amino acid sequence determines the secondary structure
• The α helix can be regarded as the default conformation
– Amino acids that favor α helices:
Glu, Gln, Met, Ala, Leu
– Amino acids that disrupt α helices:
Val, Thr, Ile, Ser, Asx, Pro
What Determines the Secondary Structure?
• Branching at the β-carbon, such as in valine, destabilizes the α helix because of steric interactions
• Ser, Asp, and Asn tend to disrupt α helices because their side chains compete for H-bonding with the main chain amide NH and carbonyl
• Proline tends to disrupt both α helices and β sheets
• Glycine readily fits in all structures thus it does not favor α helices in particular
Can the Secondary Structure Be Predicted?
• Predictions of secondary structure of proteins adopted by a sequence of six or fewer residues have proved to be 60 to 70% accurate
• Many protein chemists have tried to predict structure based on sequence
▫ Chou-Fasman: each amino acid is assigned a
"propensity" for forming helices or sheets
▫ Chou-Fasman is only modestly successful and doesn't predict how sheets and helices arrange
▫ George Rose may be much closer to solving the problem. See Proteins 22, 81-99 (1995)
Modeling protein folding with
Linus (George Rose)
Tertiary Structure
• The overall 3-D fold of the polypeptide chain
• The amino acid sequence determines the tertiary structure (Christian Anfinsen)
• The polypeptide chain folds so that its hydrophobic side chains are buried and its polar charged chains are on the surface
▫ Exception : membrane proteins
▫ Reverse : hydrophobic out, hydrophilic in
• A single polypeptide chain may have several folding domains
• Stabilized by H-bonding, LDF, noncovalent interactions, dipole interactions, ionic interactions, disulfide bonds
Fibrous and Globular Proteins
Fibrous Proteins
• Much or most of the polypeptide chain is organized approximately parallel to a single axis
• Fibrous proteins are often mechanically strong
• Fibrous proteins are usually insoluble
• Usually play a structural role in nature
Examples of Fibrous Proteins
• Alpha Keratin: hair, nails, claws, horns, beaks
• Beta Keratin: silk fibers (alternating Gly-Ala-Ser)
Examples of Fibrous Proteins
• Collagen: connective tissuetendons, cartilage, bones, teeth
▫ Nearly one residue out of three is Gly
▫ Proline content is unusually high
▫ Unusual amino acids found:
(4-hydroxyproline, 3hydroxyproline , 5hydroxylysine)
▫ Special uncommon triple helix!
Globular Proteins
• Most polar residues face the outside of the protein and interact with solvent
• Most hydrophobic residues face the interior of the protein and interact with each other
• Packing of residues is close but empty spaces exist in the form of small cavities
• Helices and sheets often pack in layers
• Hydrophobic residues are sandwiched between the layers
• Outside layers are covered with mostly polar residues that interact favorably with solvent
An amphiphilic helix in flavodoxin:
A nonpolar helix in citrate synthase:
A polar helix in calmodulin:
Quaternary Structures
• Spatial arrangement of subunits and the nature of their interactions. Can be hetero and/or homosubunits
• Simplest example: dimer (e.g. insulin)
ADVANTAGES of 4 o Structures
▫ Stability: reduction of surface to volume ratio
▫ Genetic economy and efficiency
▫ Bringing catalytic sites together
▫ Cooperativity
Protein Folding
• The largest favorable contribution to folding is the entropy term for the interaction of nonpolar residues with the solvent
• CHAPERONES assist protein folding
▫ to protect nascent proteins from the concentrated protein matrix in the cell and perhaps to accelerate slow steps