PowerPoint
advertisement

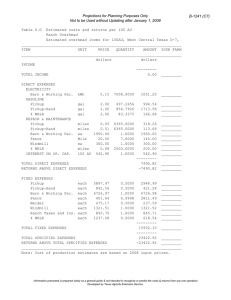
Lecture VI The order of proof of the normal distribution function is to start with the standard normal: 1 x2 2 f x e 2 ◦ First, we need to demonstrate that the distribution function does integrate to one over the entire sample space, which is - to . This is typically accomplished by proving the constant. ◦ Let us start by assuming that I e 2 y 2 dy ◦ Squaring this expression yields I e 2 2 y 2 dy e 2 x 2 e y2 x2 2 dy dx dx Polar Integration: The notion of polar integration is basically one of a change in variables. Specifically, some integrals may be ill-posed in the traditional Cartesian plane, but easily solved in a polar space. ◦ By polar space, any point (x,y) can be written in a trigonometric form: r x y 2 2 x y y r cos x r sin tan 1 ◦ As an example, take f x 15 x 1 x 2 2 Some of the results for this function are: x F(x) r theta -5.00 -4.00 -3.00 -2.00 -1.00 -0.50 -0.25 0.00 0.25 0.50 1.00 2.00 3.00 4.00 5.00 -2.5000 3.0000 7.5000 11.0000 13.5000 14.3750 14.7188 15.0000 15.2188 15.3750 15.5000 15.0000 13.5000 11.0000 7.5000 5.5902 5.0000 8.0777 11.1803 13.5370 14.3837 14.7209 15.0000 15.2209 15.3831 15.5322 15.1327 13.8293 11.7047 9.0139 0.4636 -0.6435 -1.1903 -1.3909 -1.4969 -1.5360 -1.5538 1.5544 1.5383 1.5064 1.4382 1.3521 1.2220 0.9828 r 2.5 2.0 1.5 1.0 0.5 theta 8 10 12 14 ◦ The workhorse in this proof is Greene’s theorem. We know from univariate calculus that b a d f t dt f b f a dt ◦ In multivariate space, this becomes N S x M y dx dy Mdx Ndy N S x M y dx dy N x dx dy M y dx dy S S N dy M dx ◦ Primary function 2 x f x exp 2 1.0 0.8 0.6 0.4 0.2 4 2 2 4 r 3.0 2.5 2.0 1.5 1.0 0.5 theta 1.5 2.0 2.5 3.0 M x, y y f x, t dt , N x, y 0 x f dx dy N S x i 1 i S f dx dy S M y dx dy M dx 4 S d b f r dr d f r cos , r sin r dr d a c I2 e 2 y 2 dy e x 2 2 e y2 x2 2 dx dy dx y 2 x 2 r 2 cos 2 r 2 sin 2 r 2 cos 2 sin 2 r2 dy dx r dr d I 2 2 0 0 re r 2 2 2 dr d d 2 0 I 2 2 1 y 2 e dy 1 2 The expression above is the expression for the standard normal. A more general form of the normal distribution function can be derived by defining a transformation function. y a bx ya x b ◦ By the change in variable technique, we have 1 f x e 2 y a 2 2 2 b 1 b Definition 2.2.1. The expected value or mean of a random variable g(X) noted by E[g(X)] is g x f x dx if x is continuous E g X xX gx f x if x is discrete ◦ The most general form used in this definition allows for taking the expectation of the function g(X). Strictly speaking, the mean of the distribution is found where g(X)=X, or Ex x f x dx ◦ Example E x 1 0 xe x x xe x e 0 0 dx e 0 x dx ◦ Theorem 2.2.1. Let X be a random variable and let a, b, and c be constants. Then for any functions g1(X) and g2(X) whose expectations exist: E[a g1(X) + b g2(X) + c]= a E[g1(X)] + b E[g2(X)] + c. If g1(X) 0 for all X, then E[g1(X)] 0. If g1(X) g2(X) for all X, then E[g1(X)] E[g2(X)] If a g1(X) b for all X, then a E[g1(X)] b