Skittles Term Project
advertisement

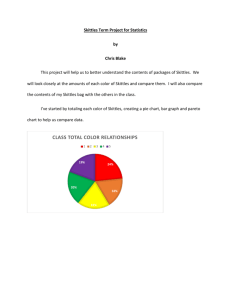
Boman Farrer Skittles Term Project Math 1040 Professor Brenda Santistevan Skittles Project For this project we, as a class, each got a 2.17 oz. bag of regular skittles. With the bag, we counted the total number of skittles, as well as how many of each color skittle were in the bag. From there, we took the data and submitted the information to our professor to be compiled, recorded, and sent out to the class. We now have the total number of skittles and total number of each color skittle for our entire class (25 bags of skittles). The goal of this project is to determine a variety of statistics for a bag of skittles, such as the mean number of skittles per bag, standard deviation between bags and colors and to see how these statistics look on a variety of graphs. The following two graphs (pie and pareto chart) show the proportion of each color skittles in our sample. There were 25 bags of skittles with 1511 individual skittle candies. As the pie chart shows, each color is pretty evenly distributed throughout the bags of candies. There are 5 colors in each bag and the proportion of each color totaled to be about 20 percent of the sample data. When I first read over the project, that is what I expected. However, when i opened my bag of skittles, my data didn’t reflect that at all. There were significant differences in the numbers of each color candies in my bag. For example I had 19 orange candies and only 7 green candies and 7 purple candies. It seems that by collecting more data, the proportion of the five colors gets closer to 20 percent. Below is a table comparing the data collected from my bag of and the data collected from the entire class’s bags of candies. My bag had a variety of different proportions ranging from 11.5% to 31.1%. It is interesting that the proportion of colors in my bag would be so different, because the proportion of colors in the entire class’s sample is all very close to 20%, which is what I would expect it to be. Color Number of Candies (My Sample, one bag) Number of Candies (Class Totals, 25 bags) Red 16 (.262 of total) 321 (.212 of total) Orange 19 (.311 of total) 292 (.193 of total) Yellow 12 (.197 of total) 306 (.203 of total) Green 7 (.115 of total) 316 (.209 of total) Purple 7 (.115 of total) 276 (.183 of total) TOTAL CANDIES 61 1511 Below are some summary statistics for the data collected by the class from the 25 bags of skittles. After compiling all the data from the class’s 25 bags of skittles, it its interesting to see that only 60 percent of the bags of skittles had between 60 and 65 candies in them. I would think that there would be more consistency in packaging the candy. According the the graphs below, the shape of the distribution is skewed right. The box plot shows the minimum, first quartile, median, third quartile and the maximum. It also shows the outliers. There were three bags that were below the lower fence and one bag about the upper fence. The data collected from my personal bag had some similarities but also some differences. Fore example; my bag of skittles had 61 candies in it which is very close to the class mean, but the standard deviation for my bag was 5.36 which is an entire candy more than the classes standard deviation. In this project we have dealt with quantitative data and categorical. Quantitative data is something you can measure or count such as number of candies, height, weight etc. Categorical data is data that fits into “categories” such as color, gender, vehicle type etc. For each different type of data, a different graph may be more appropriate. For example; with categorical data, using graphs such as a Pareto diagram or bar graph and pie chart will be more fitting because it displays and organizes the data into categories to better explain the data. For quantitative data, a histogram, stem and leaf plot, or box plot will be more appropriate because it uses quantities to organize the data. Frequency counts can be used for both quantitative data and categorical data. Because quantitative data can be ordered, added together and counted, all of the summary statistics, including; mean, median, mode, minimum, maximum, range and standard deviation, can be used. With categorical data, calculations are more limited because with the exception of frequency, there are no numbers to go into a calculation. However, there are a few calculations that can be made including; mode and median and the minimum and maximum frequencies of the categorical data. PART 2 For the next part of out skittles project, we have been asked to construct different confidence interval estimates for the true proportion of yellow candies, for the true mean number of candies per bag and for the standard deviation of the number of candies per bag. A confidence interval is a range of values that are determined by an amount of uncertainty. By finding the appropriate data and using a confidence level, you can determine a range of numbers where the statistic is most likely to fall. The higher your confidence level, the more sure you are that your statistic will fall within that range of numbers. The first confidence interval estimate we had to do was to find the true proportion of yellow candies. We were to use a 99% confidence level to determine the range of numbers. The proportion of yellow candies from our sample came out to be 20.3%, meaning of all the candies in our bags of skittles, 20.3% of them were yellow. We used that data to establish the true proportion of yellow candies for all skittles. We determined that we could be 99% sure that the true proportion of all yellow skittles would be somewhere between 17.6% and 23.0%. This matches up well with our data since our proportion was within that range of numbers. Below are the calculations for the confidence interval estimate. The second confidence interval estimate we had to do was to estimate the true mean number of candies per bag. In our sample of skittles, we found that the mean number of candies per bag for 25 bags of skittles was 60.44 skittles per bag. After using a confidence level of 95%, we found that the true mean for all bags of skittles was between 58.64 candies and 62.24 candies per bag, with 95% confidence. Below are the calculations for the confidence interval estimate. The third confidence interval estimate we were to create was to find the standard deviation for the number of candies per bag. For this one we used a 98% confidence level. The standard divination for our sample data came out to be 4.36. After calculating the true standard deviation we found that with 98% confidence, it was with in the range of 3.26 to 6.48. Below are the calculations for the confidence interval estimate. For the next part of our skittles project, we tested claims with hypothesis tests. A hypothesis test is a way to use statistical data to determine whether to reject or fail to reject a claim made. By using a hypothesis test you can verify claims made about products to determine whether or not you are getting what you paid for. This can also be useful for quality control in manufacturing. The first hypothesis test we had to do was to test the claim that 20% of all skittle candies are red. With the data collected from our sample, our proportion of red skittles came to 21.2%. After calculating the critical values with a 0.05 significance level and the z-score , we found that a 20% proportion of red skittles is very plausible and therefore we failed to reject the claim. Below are the calculations for the hypothesis test. The second hypothesis test we were to complete was to test the claim that the mean number of candies in a bag of skittles is 55. As discussed in the second confidence interval estimate we did, our sample mean was 60.44 and with a 95% confidence interval we determined that the true mean was between 58.64 and 62.24. With that information we had a pretty good idea that we would be rejecting the claim. By calculating the critical test statistic with a 0.01 significance level we found that in order for that claim to be true, our t value must fall between 2.797 and 2.797. In reality, the t value came out to be 6.14, which is way outside the range of acceptable numbers, therefore, we reject the claim that the mean number of candies in a bag of skittles is 55. Below are the calculations for the hypothesis test. To get accurate statistics while determining an interval estimate and preforming a hypothesis test, there are certain requirements that must be met. For constructing a confidence interval estimate for a population proportion the requirements are as follows; he sample is a simple random sample, the conditions for the binomial distribution are satisfied, there are at least five successes and at least 5 failures. For constructing a confidence interval estimate for a population mean the requirements include; the sample is a simple random sample, and the population is normally distributed or n>30. For constructing a confidence interval estimate for a population standard deviation the requirements are; the sample is a simple random sample, and the population must have normally distributed values even if the sample is large. For testing a claim about a population proportion the requirements are; the sample observations are a simple random sample, the conditions for a binomial distribution are satisfied, and the conditions np>/=5 and nq>/=5 are both satisfied. For testing a claim abut a population mean the requirements are; the sample is a simple random sample, and the population is normally distributed or n>30. For those requiring conditions for a binomial distribution to be satisfied, that means that there is a fixed number of independent trials having constant probabilities and each trial has to outcome categories of success or failure. One possible error that occurs from using this data has to do with our sample size. We only used 25 bags of skittles and one of the requirements, because our sample is not normally distributed, is that our sample size needs to be greater than 30. Another possible error could occur from inaccurate information, whether the data was recorded wrong, or some students got the wrong size bag of skittles. This sample could be improved by using a larger sample size, and also by verifying the data submitted. Students could count the skittles in class and have another classmate double check their work to be sure the data was submitted correctly. It is very interesting and helpful to see all how these math problems are applicable to real life. This seems like a very effective way to determine the quality control of a product a manufacture is supplying. It is also helpful to see how a consumer can verify that they are getting the right amount of product they are paying for.