07153916 - Introduction - University of Hertfordshire
advertisement

UNIVERSITY OF HERTFORDSHIRE
Faculty of Engineering & Information Sciences
MSc in DATA COMMUNICATIONS AND NETWORKS
Project Report
A PARALLEL MATRIX MULTIPLIER FOR 3D
TRANSFORMATIONS
Sun Zhengzheng
August 2008
School of Electronic, Communications and Electrical Engineering
MSc Project Report
DECLARATION STATEMENT
I certify that the work submitted is my own and that any material derived or quoted from the
published or unpublished work of other persons has been duly acknowledged (ref. UPR
AS/C/6.1, Appendix I, Section 2 – Section on cheating and plagiarism)
Student Full Name: Sun Zhengzheng
Student Registration Number: 07153916
Signed: …………………………………………………
Date: 31 August 2008
1
School of Electronic, Communications and Electrical Engineering
MSc Project Report
ABSTRACT
Matrix multiplication is frequently used in many areas including image and signal processing. But
signal processing and image processing involve large matrix multiplications. Unfortunately, the
complexity of matrix multiplication algorithms is O(N3), and hence the algorithms requires
significant computation time. Parallel matrix multiplication has been proposed for this reason,
which complexity reduced to O(N3/p). A parallel 3*3 matrix multiplier using nine PEs is presented
in this report. And it can be used in 3D transformations to accelerate these computationally
intensive operations. The multiplier has been developed and implemented on the Xilinx ISE
development platform. Results show that the FPGA-based parallel multiplier provides a
significant reduction in total computation time and resource utilization over sequential matrix
multiplier.
2
School of Electronic, Communications and Electrical Engineering
MSc Project Report
ACKNOWLEDGEMENTS
I would like to take this opportunity to thank many people without whose support and help this
project would not have achieved such a successful solution.
Firstly, my sincere gratitude to my project supervisor, Dr. Faycal Bensaali, whose expert
knowledge and understanding of the subject and his constant support throughout the project
ultimately helped me shape and give direction to the project.
Next, many thanks to my previous teachers in China. They answered me many questions.
I would also like to thank my parent. They mail some books from China to help me learning the
necessary knowledge related my project.
Further, I would like to extend my gratitude to our lab assistant Mr. John Wilmott for his prompt
support in all of the organizational work in the project lab.
3
School of Electronic, Communications and Electrical Engineering
MSc Project Report
TABLE OF CONTENTS
ABSTRACT
ACKNOWLEDGEMENT
TABLE OF CONTENTS
LIST OF FIGURES
LIST OF TABLES
GLOSSARY
1
INTRODUCTION
1.1 Project Objectives
1.2 Report Outline
2
LITERATURE REVIEW
2.1 3-D Transformations
2.2 Matrix Multiplication
2.3 Xilinx ISE
2.4 VHDL
2.5 Field Programmable Gate Arrays (FPGAs)
3
PROPOSED ARCHITECTURE
3.1 Parallel Architecture
3.2 Compare with Sequential Architecture
4
HARDWARE IMPLEMENTATION
5
RESULTS AND DISCUSSION
5.1 Complete Proposed Environment
5.2 Observations
5.2.1
PE Test
5.2.2
Architecture Test
5.3 Improving Performance Bottlenecks and Future Work
6
CONCLUSION
REFERENCES
4
School of Electronic, Communications and Electrical Engineering
MSc Project Report
BIBLIOGRAPHY
APPENDIX A: SOURCE CODE (CD)
APPENDIX B: MULT18×18
APPENDIX C: Time Management
5
School of Electronic, Communications and Electrical Engineering
MSc Project Report
LIST OF FIGURES
Figure 2-1: Xilinx design flow
Figure 3-1 Parallel architecture for matrix multiplication
Figure 4-1 Hardware implementation flow
Figure 5-1 PE simulation
Figure 5-2 Matrix simulation
Figure 5-3 A better architecture
Figure A-1 Time plan
6
School of Electronic, Communications and Electrical Engineering
MSc Project Report
LIST OF TABLES
Table 2-1 Free design and simulation packages for VHDL
Table 3-1 The performance of two matrix multiplier
Table 4-1: Macro statistic
Table 4-2: The sequence of output data
Table 5-1: PE test bench file
Table 5-2: Architecture test bench file
7
School of Electronic, Communications and Electrical Engineering
MSc Project Report
GLOSSARY
ASICs
Application Specific Integrated Circuit: An integrated circuit (IC) customized
for a particular use
EDIF
Electronic Data Interchange Format: An industry standard file format
for specifying a design netlist.
EDA
Electronic Design Automation: A generic name for all methods of entering
and processing digital and analog designs for further processing,
simulation, and implementation.
FPGA
Field Programmable Gate Array.
HDL
Hardware Description Language: A language that describes circuits in
textual code. The two most widely accepted HDLs are VHDL and Verilog.
ISE
Integrated Software Environment.
LUT
Look-up Table
MAC
Multiply Accumulator
PE
Processing Element
UUT
Unit Under Test
VHDL
VHSIC Hardware Description Language
8
School of Electronic, Communications and Electrical Engineering
MSc Project Report
1 INTRODUCTION
Matrix multiplication is frequently used in many areas including image and signal processing. But
signal processing and image processing involve large matrix multiplications. Unfortunately, the
complexity of matrix multiplication algorithms is O(N3), where N is the dimension of a square
matrix, and hence the algorithms requires significant computation time for large N[7]. Parallel
matrix multiplication has been proposed for this reason, which complexity reduced to O(N3/p),
when using p parallel processors[7].
At the same time, the latest FPGA technology provides more advanced features in process speed,
flash memory and other functions which provide new possibilities for implementing a more
complicated parallel matrix multiplication algorithm.
Xilinx Integrated Software Environment (ISE) provides a development platform of hardware,
which much shorter the design cycle and minimum software involvement once the hardware is
implemented. The proposed parallel matrix multiplier has been finished the design,
implementation and simulation stages on the Xilinx ISE platform. And the architecture
accelerates these computationally intensive operations in 3D transformations.
The report focuses on discussing the theory of the proposed matrix multiplier including compare
with sequential matrix multiplier, and describing the design and implementation flow for a 3*3
parallel matrix multiplier, also giving the simulation result and analysis. Finally, based on the
practical work, the limitations of the proposed architecture and recommendation for future work
are identified.
1.1 Project Objectives
The aim of this project is to propose and implement a parallel matrix multiplier on Field
Programmable Gate Array (FPGA) for 3D transformations. The multiplier will be used in a
hardware/software environment for viewing and manipulating 3D objects. The environment
should consist of a host application (Graphical User Interface), a 3D object database, the Open
Graphics Library (OpenGL) and an FPGA coprocessor. The GUI which can be implemented using
Visual C++ or Borland C++ builder, gives the user the ability to select a 3D model from the 3D
9
School of Electronic, Communications and Electrical Engineering
MSc Project Report
object database, and display it on a 3D viewer. The user can apply different algorithms on the
object, such as texture, lighting, transformations and antialiasage, which involve calls to OpenGL
functions. In the case of the transformations, these operations can be performed using OpenGL
(software implementation) or an FPGA (Hardware implementation).
1.2 Report Outline
Chapter 2 - LITERATURE REVIEW: This chapter explains the background knowledge and
relative concepts that are useful in later chapters of the report. Mainly reviews the
function of Xilinx ISE and VHDL and the theory behind matrix multiplication algorithm.
Finally, briefly introduces FPGA technology.
Chapter 3 – PROPOSED ARCHITECTURE: This chapter describes a proposed architecture
of parallel matrix multiplication and overview the concepts.
Chapter 4 – HARDWARE IMPLEMENTATION: This chapter goes through the VHDL design
flow, an overview of the proposed architecture implemented and the logic involved.
Chapter 5 – RESULTS AND DISCUSSION: This chapter examines the simulation results.
Then assesses the performance of the architecture. This section also discusses the
performance limitation of the hardware used and gives some improvement suggestion.
Chapter 6 – CONCLUSION: This chapter concludes the work carried out in the project,
the aim completed successfully.
Appendices – The source code, test code and other relevant files are attached.
10
School of Electronic, Communications and Electrical Engineering
MSc Project Report
2 LITERATURE REVIEW
This chapter explains the background knowledge and relative concepts that are useful in
later chapters of the report. Mainly reviews the function of Xilinx ISE and VHDL and the
theory behind matrix multiplication algorithm. Finally, briefly introduces FPGA technology.
2.1 3D Transformations
Three-dimensional transformations involve rotation, scaling, shear and translation. These
transformations can be represented as a subset of matrix multiplications.[1]
x* A D G J x
y* B E H K y
*
z
C
F
I
L
z
1 0 0 0 1 1
(2.1)
The general matrix for transformations can be divided into four function blocks:[2]
[
Scaling and rotation
translation
]
Part of the homogeneous representation
1
A set of vertices or 3-D points belongs to and object can be transformed into another set of
points by a linear transformation.[2]
V* = D + V
V* = S × V
V* = R × V
(2.2)
Where D is a translation vector, S and R are the scaling and rotation matrices
11
School of Electronic, Communications and Electrical Engineering
MSc Project Report
V * S V
Sx
0
S
0
0
0
Sy
0
0
0
Sz
0
0
0
0
0
1
V * R V
0
0
1
0
cos
sin
RX
0 sin cos
0
0
0
cos
0
0
0
Ry
sin
0
1
0
0 sin 0
cos sin 0 0
1
0
0
sin cos 0 0
Rz
0 cos 0
0
0
1 0
0
0
0
1
0
0 1
Translation can be treated as a matrix multiplication operation, like the other two
transformations[2]:
V * D V
x* 1
y* 0
*
z 0
1 0
0
1
0
0
0 Tx x
x
0 Ty y
y
T
z
1 Tz z
1
0 1 1
2.2 Matrix Multiplication
The algorithm of matrix multiplication is frequently used in the areas of digital image/signal
processing including compression and beamforming applications. And a close examination of
the matrix algorithm reveals that many of the fundamental actions involve matrix or vector
operations. But signal processing and graphical processing require enormous computing
power and involve large matrix multiplication. Unfortunately, the complexity of matrix
12
School of Electronic, Communications and Electrical Engineering
MSc Project Report
multiplication algorithm is O(N3), where N is the dimension of a square matrix, and
consequently the algorithm requires enormous computation time for large N[7]. Hence, how
to reduce this complexity and improve the performance becomes a challenging problem for
researchers.
One way of improving performance in matrix multiplication is to use parallel computers.
However, for the reason of cost, lacking stability and software support, parallel machines
have not been used widely.[7]
The other way of obtaining higher performance is to use DSP processor, which include
Application Specific Integrated Circuits (ASICs) and Field Programmable Gate Array (FPGAs).
Though ASICs offer the maximum achievable performance, they lack of flexibility, plus of the
high cost of manufacturing and the relatively longer development cycle [7]. Therefore,
re-configurable hardware solutions in the form of FPGAs become a better selection to
perform matrix algorithms.
The project is concerned with the design and implementation of a parallel matrix multiplier
on re-configurable hardware.
Let’s define the product C:
Consider A is N×M matrix and B is M×P matrix. The product C of A by B is given by
Cij= ∑𝑁−1
𝑘=0 AIkBkJ
(2.1)
Where AIJ, Bij and Cij are the elements in the ith row and jth column of the respective matrix.
The size of matrix C satisfy (N×M)(M×P) = N×P
Parallel architectures have been proposed for this reason, which complexity reduced to
O(N3/p), when using p parallel processors.[1]
2.3 Xilinx ISE
Xilinx Integrated Software Environment (ISE) software provides a hardware design and
simulation platform, which much shorter the design cycles for hardware. A standard design
13
School of Electronic, Communications and Electrical Engineering
MSc Project Report
flow using Xilinx ISE comprises the following steps[5]:
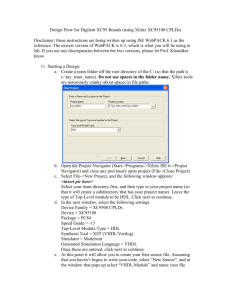
1, Design entry and synthesis: in this step, you create your circuits using a schematic editor, a
hardware description language (HDL) or both of them for text-based entry.
2, Design Implementation: is the process of translating, mapping, placing, routing, and
generating a bit file for the design. The stages detailed described as follows:[11]
(i)
Translating: to merge all of the netlists and design constraint information into a Xilinx
database file.
(ii)
Mapping: mapping a logical design to a target FPGA
(iii)
Placing and routing: placing and routing the FPGA, and produce output for the
bitstream generator.
3, Design Verification: using a gate-level simulator to ensure the design meets your timing
requirements and functions properly[5].
Through each of above steps, the results can be verified. Some problems would be detected
and dealt with during these stages. Xilinx development system allows iterative process of
entering, implementing, and verifying your design until it is correct and complete[11].
14
School of Electronic, Communications and Electrical Engineering
MSc Project Report
Figure 2-1: Xilinx design flow
2.4 VHDL
VHSIC Hardware Description Language (VHDL) is one of the Hardware Description Language
(HDL) used to model electronic systems. And it was originally developed by the US
Department of Defence in 1980’ in order to document the behaviour of the Application
Specific integrated Circuit (ASICs) in Electronic Design Automation (EDA) of digital circuit and
popularly used as a design-entry language for Field Programmable Gate Arrays (FPGA). VHDL
changed the traditional design method and reduced the time of design cycle and saved the
developed cost.[4]
VHDL is similar to the Verilog language. It is possible to use the VHDL to write the test bench
file and simulate on the host computer. Therefore, users can verify the functionality of the
design and compares the results with those expected.
It is possible to design hardware in a VHDL IDE, such as Xilinx, to generate the RTL schematic
of a respected circuit. Then, the produced schematic can be verified using ModelSim or ISE
15
School of Electronic, Communications and Electrical Engineering
MSc Project Report
simulation, either of them displays the waveforms of inputs and outputs of the circuit if
generating the appropriate test bench file. The inputs should be defined correctly, for
example, clock input, a loop process or an interactive statement, etc. [4]
Nearly all FPGA design and simulation flows support VHDL.
The following table indicates some free design and simulation packages for VHDL:
Vendor
Actel
Trial Software
License
Libero gold
Synthesizer
One year free
ModelSim Actel
Synplify Actel
license
edition
Edition
Active
One year free
Aldec (mixed
All Syntheis
–HDL(Student
license
language)
(interfaces)
Aldec
Edition)
Altera
Simulator
RTL
Gate
view
view
No
yes
yes
yes
yes
yes
No
yes
Student
Quartus II web
6 months
ModelSim Altera
Altera Quartus
edition
renewable free
Edition
II
ispLever starter
6 months
Precision/Synpli
renewable free
fy Lattice
license
Edition
license
Lattice
Dolphin
none
Free seduction
SMASH
no
6 months
ModelSim PE
no
yes
yes
renewable free
Student Edition
Xilinx XST
yes
yes
no
Via
no
license
Mentor
none
license
Xilinx
ISE webpack
Free license
ISE Simulator
Blue
BlueHDL
Free license
BlueSim
GHDL
GPL
GHDL
Pacific
GHDL
GTKWa
ve
Table 2-1
Free design and simulation packages for VHDL
Resource from [4]
The benefit of using VHDL:
Firstly, which allows the user to describe the required system and simulate before synthesis
16
School of Electronic, Communications and Electrical Engineering
MSc Project Report
tools translate the design into real hardware, such as FPGA.
The other advantage of VHDL is that it supports the function of description of a concurrent
system. And VHDL is a dataflow language and it is all run sequentially, one instruction at a
time, this is not similar to the C programming language which is a procedural computing
language.[4]
2.5 Field Programmable Gate Arrays (FPGAs)
FPGA is a high-speed re-configurable logic circuits packaged as high-density commodity chips.
The logical layout is suited for rapid implementation of state machines and sequential logic.
FPGA is organized into sequential logic which detects the input then generates the outputs
plus a lookup table for state memories and transition maps. Integrated glue logic – buffer
register, decoders and multiplexers can be implemented efficiently in FPGA.FPGA can be
used for complex processes, such as correlation, convolution and filtering. Their flexibility,
ability to reduce part count and most important of their economic price attracted continues
investment. This results the clock rates and gate densities obtain continues increasing.[10]
17
School of Electronic, Communications and Electrical Engineering
MSc Project Report
3 PROPOSED ARCHITECTURE
Signal processing and image transformation require significant computing power. And most
of these operations involve matrix multiplication algorithm. But the complexity of a matrix
multiplication algorithm is O(N3). Hence, a parallel matrix multiplication has been proposed
on image processing technology, which complexity reduced to O(N3/p)
This section describes a 3*3 parallel matrix multiplier implemented with nine PEs.
3.1 Parallel Architecture
The mathematical model:
Consider two 3*3 matrices: A=[Aij] and B=[Bij].
A00
A =(A10
A20
A01
A11
A21
A02
A12 )
A22
B00
B =(B10
B20
The product C = [Cij] is given by
A00
C =A×B=(A10
A20
A01
A11
A21
B01
B11
B21
B02
B12 )
B22
Cij = ∑2𝑘=0 A𝑖𝑘B𝑘𝑗
A02
B00
A12 )×(B10
B20
A22
B01
B11
B21
B02
C00
B12 ) = (C10
B22
C20
C01
C11
C21
C02
C12 )
C22
And a parallel architecture can be expressed as Figure 3-1.
18
School of Electronic, Communications and Electrical Engineering
Input Data
Buffe r
B02m
b1 3
Bb01m
12
B12
b2m3
m
B11
b
22
B22
b3m3
B21m
b
m
Bb001 1
m
b
B2101
m
b
B20
31
Aa00
m
13
m
12
00
Aa10
02
Aa12
a
A11
23
22
PE 2 1
PE 2 2
PE 2 3
11
Aa20
12
a
A21
31
C22 C21 C20
PE 1 3
01
10
c2m3 c2m2 c2m1
c3m3 c3m2 c3m1
13
PE 1 2
21
C12 C11 C10
Aa 02
12
PE 1 1
m
11
32
A01
a
11
Cc02 Cc01 Cc00
MSc Project Report
Aa22
32
33
PE 3 1
PE 3 2
20
PE 322
3
21
O utput Data
Buffe r
PE structure
a ij
Bij
Multiplier Accumulator
CSAS
bijm
co u t
Cin
Clock
+
FF
Register
Aij
Cout
c
in
Figure 3-1 Parallel architecture for matrix multiplication [6]
The architecture consists of nine identical PEs. Each PE comprises a multiplier, a full adder for
adding the output of the multiplier and the result generated from the previous PE, and a
register that saves the carry bit.
3.2 Compare with Sequential Architecture
Table 3-1 shows the performance obtained for the proposed parallel matrix multiplier and
the sequential matrix multiplier.
Table 3-1
The performance of two matrix multiplier
Matrix Multiplier
Time Complexity
Latency
Proposed matrix multiplier
N3
1
Sequential matrix multiplier
N3/p
N
19
School of Electronic, Communications and Electrical Engineering
MSc Project Report
Where N is the dimension of a square matrix, p is the number of parallel processors.
There is one function can be used in each sequential matrix multiplications:
If A is N×N matrix, and B is N×N matrix, then the size of product C is N×N.[9]
void mutmat (matrix C, matrix A, matrix B){
int I, j, k;
for (i = 0; i<N; i++)
for (j=0; j<N; j++) {
C[i] [j]=0;
for (k=0; k<N; k++)
C[i] [j] = C[i] [j] + A[i] [k] * B [k] [j];
}
}
Based on the above algorithm, i, j, k do N times loops respectively and hence the time
complexity is N3.
20
School of Electronic, Communications and Electrical Engineering
MSc Project Report
4 HARDWARE IMPLEMENTATION
The proposed matrix multiplier has been designed using VHDL language and compiled
using .Xilinx ISE 9.2.04i.
Input
Data
B0
B02
B01
B00
B1
Cout00
A01
PE00
A10
Cout10
A20
C2
reg0
reg1
reg2
Cout20
"00"
Cout01
Cout11
PE01
A0
Cout02
A1_reg
A1
A2_reg
A2
PE02
A12
PE11
A21
PE20
A0_reg
A02
A11
PE10
C1
B22 reg0
B21 reg1
B20 reg2
B12
B11
B10
A00
C0
B2
Cout12
PE12
A22
PE21
Cout21
Cout22
"01"
"10"
PE22
CWEL_reg
Output
Data
* CWEL controls the output of A_reg.
Figure 4-1 Hardware implementation flow chart
A hierarchical design method used to the project. A PE block file firstly be created using VHDL
module (The source code please refer to the appendix B). The PE block is consisted of one
16-bit multiplier(using the component : MULT 18×18 from the Xilinx library, refer to
Appendix B), one 34-bit adder for signal <sum> and one 34-bit register for signal <Cout>.
Next, building an architecture file using VHDL module which contains the PE component, and
through map to build a nine-PE architecture as shown in the Figure 5-2. The code in
matrix.vhd as Figure 4-2. It is worth to mention that more PE can be easily added by just
21
School of Electronic, Communications and Electrical Engineering
MSc Project Report
adding one VHDL code line.
--/*9 parallel PE
architecture */
PE00: PE port map( A => A00, B => B0_reg2, C => Cout01,Cout => Cout00,CLK=> CLK ,RST => RST);
PE01: PE port map( A => A01, B => B1_reg2, C => Cout02,Cout => Cout01,CLK=> CLK,RST => RST);
PE02: PE port map( A => A02, B => B2_reg2, C => (others=>'0'),Cout => Cout02,CLK=> CLK,RST =>
RST);
PE10: PE port map( A => A10, B => B0_reg2, C => Cout11,Cout => Cout10,CLK=> CLK,RST => RST);
PE11: PE port map( A => A11, B => B1_reg2, C => Cout12,Cout => Cout11,CLK=> CLK,RST => RST);
PE12: PE port map( A => A12, B => B2_reg2, C => (others=>'0'),Cout => Cout12,CLK=> CLK,RST =>
RST);
Figure
4-2 The
code of,Cout
nine-PE
architecture
PE20: PE port map( A => A20,
B => B0_reg2,
C =>Cout21
=> Cout20,CLK=>
CLK,RST => RST);
PE21: PE port map( A => A21, B => B1_reg2, C => Cout22,Cout => Cout21,CLK=> CLK,RST => RST );
And the ISE sources window will display like this:
PE22: PE port map( A => A22, B => B2_reg2, C => (others=>'0'),Cout => Cout22,CLK=> CLK,RST =>
RST);
Figure 4-3 The source window
To implemented the proposed architecture, there use three-level registers as the input and
output data buffer. And using three-levels pipeline to transfer the output of every PE.
Consequently the complete multiplication requires 9 clock cycles. The sequence of output
data describes in Table 4-2. For the whole architecture, Table 4-1 gives a macro statistic:
22
School of Electronic, Communications and Electrical Engineering
MSc Project Report
Table 4-1: Macro statistic
DEVICE
SIZE
NUMBER
Adders
34-bit
9
41
Registers
1-bit
1
16-bit
21
2-bit
1
34-bit
18
3
Counter
Down counter
2-bit
1
Up counter
2-bit
1
4-bit
1
--1
A00*B00
A10*B00
A20*B00
--2
--3
A01*B10+(A00*B00)
A02*B20+(A01*B10+A00*B00)
C00
A11*B10+(A10*B00)
A12*B20+(A11*B10+A10*B00)
C10
A21*B10+(A20*B00)
A22*B20+(A21*B10+A20*B00)
C20
--4
--5
--6
A00*B01
A01*B11+(A00*B01)
A02*B21+(A01*B11+A00*B01)
C01
A10*B01
A11*B11+(A10*B01)
A12*B21+(A11*B11+A10*B01)
C11
A20*B01
A21*B11+(A20*B01)
A22*B21+(A21*B11+A20*B01)
C21
--7
--8
--9
A00*B02
A01*B12+(A00*B02)
A02*B22+(A01*B12+A00*B02)
A10*B02
A11*B12+(A10*B02)
A12*B22+(A11*B12+ A10*B02)
A20*B02
A21*B12+(A20*B02)
A22*B22+(A21*B12+A20*B02)
C02
C12
C22
Table 4-2: The sequence of output data
23
School of Electronic, Communications and Electrical Engineering
MSc Project Report
5 RESULTS AND DISCUSSION
This section shows the simulation results of implementing the proposed architecture.
Furthermore, based on the simulation results, the computation time, its speed and many
other parameters and performance will discuss and analysis. Finally, depending on the
project result, some suggestion will give in this section.
5.1 Complete Proposed Environlment
Synthesis Tool: XST (VHDL/Verilog)
Simulator: ISE Simulator (VHDL/Verilog)
Preferred Language: VHDL
5.2 Observations
According the synthesis report written by Xilinx ISE, the maximum frequency achieves
101.379MHz. Below gives the simulation results of PE test and architecture test.
5.2.1 PE Test
The section 4 explained PE block was successfully implemented. The simulation result as
shown in Figure5-1. There gives the test code to verify the PE block. The test codes write
with VHDL and using VHDL test bench to execute the simulation.
PE Test Bench File
tb : PROCESS
BEGIN
-- Set clock cycle
WAIT FOR 100 ns;
CLK <= NOT CLK ;
END PROCESS;
tc : PROCESS
BEGIN
-- Set RST
WAIT FOR 200 ns;
RST <= '0';
24
School of Electronic, Communications and Electrical Engineering
MSc Project Report
END PROCESS;
data : PROCESS
BEGIN
WAIT FOR 200 ns;
A <= "0101010101010101" ;
B <= "1010101010101010"
;
C <= "0000000000000000000000000000000000"
;
WAIT FOR 200 ns;
A <= "1111111111111111"
;
B <= "0000000000000001"
;
C <= "0000000000000000000000000000000001"
;
WAIT FOR 200 ns;
A <= "1111111111111111"
;
B <= "1111111111111111"
;
C <= "0011111111111111111111111111111111"
;
END PROCESS ;
There input three groups of numbers.
Table 5-1: PE test bench file
¶
group 1
group 2
group 3
Figure 5-1 PE simulation
Result analysis:
The first group of data::
25
School of Electronic, Communications and Electrical Engineering
MSc Project Report
Cout = a*b + c = 16’h5555*16’hAAAA + 34’h000000000 = 34’h038E31C72
The second group of data:
Cout = a*b + c = 16’hFFFF*16’h0001 + 34’h00000001 = 34’h000010000
The third group of data:
Cout = a*b + c = 16’hFFFF*16’hFFFF + 34’h0FFFFFFFF = 34’h01FFFE0000
According the above calculation, the simulation results are respected.
Total computation time: one clock cycle.
5.2.2 Architecture Test
The section 4 explained system was successfully implemented. There gives the test code to
verify the architecture. The test codes write with VHDL and using VHDL test bench to execute
the simulation.
Architecture Test Bench File
tb : PROCESS
BEGIN
-- set clock cycle
WAIT FOR 200 ns;
CLK <= NOT CLK ;
-- Place stimulus here
-- will wait forever
END PROCESS;
tc : PROCESS
BEGIN
-- set RST
WAIT FOR 500 ns;
RST <= '0';
END PROCESS;
data : PROCESS
BEGIN
WAIT FOR 400 ns;
CWEL <= "00" ;
A0 <= "0000000000000001" ;
-- A0->A00, , via A0_reg
26
School of Electronic, Communications and Electrical Engineering
A1 <= "0000000000000010"
;
-- A1->A10
via A1_reg
A2 <= "0000000000000011"
;
-- A2->A20
via A2_reg
B0 <= "0000000000000001"
;
--B00 -> B0_reg0
B1 <= "0000000000000010"
;
-- B10 -> B1_reg0
B2 <= "0000000000000011"
;
-- B20 ->B2_reg0
MSc Project Report
WAIT FOR 400 ns;
CWEL <= "01" ;
A0 <= "0000000000000100"
;
-- A0->A01 via A0_reg
A1 <= "0000000000000101"
;
-- A1->A11 via A1_reg
A2 <= "0000000000000110"
;
-- A2->A21 via A2_reg
--During this time B0_reg0 -> B0_reg1, B1_reg0 -> B0_reg1, B2_reg0 -> B2_reg1.
WAIT FOR 400 ns;
CWEL <= "10" ;
A0 <= "0000000000000111"
;
-- A0->A02 via A0_reg
A1 <= "0000000000001000"
;
-- A1->A12 via A1_reg
A2 <= "0000000000001001"
;
-- A2->A22 via A2_reg
--During this time B0_reg1 -> B0_reg2, B1_reg1 -> B0_reg2, B2_reg1 -> B2_reg2
WAIT FOR 400 ns;
B0 <= "0000000000000100"
;
--B01 -> B0_reg0
B1 <= "0000000000000101"
;
-- B11 ->B1_reg0
B2 <= "0000000000000110"
;
-- B21-> B2_reg0
--The reason for waiting three clock cycles to input B01, B11, B21: waiting the previous outputs from the
PE02, PE12, and PE22 achieve PE00, PE10 and PE20, then adding.
WAIT FOR 1200 ns;
-- refer to above reason
B0 <= "0000000000000111"
;
-- B02 ->B0_reg0, ,.
B1 <= "0000000000001000"
;
--B12 ->B1_reg0
B2 <= "0000000000001001"
;
-- B22-> B2_reg0
WAIT FOR 800 ns;
- refer to above reason
END PROCESS ;
Table 5-2: architecture test bench file
The simulation result as follows:
27
School of Electronic, Communications and Electrical Engineering
1 2
MSc Project Report
3 4 5
6 7 8 9
Figure 5-2 Matrix simulation
Result analysis:
The respected output:
1 + 8 + 21
4 + 20 + 42
7 + 32 + 63
1 4 7
1 4 7
(2 5 8) × (2 5 8) = (2 + 10 + 24 8 + 25 + 48 14 + 40 + 64)
3 + 12 + 27 12 + 30 + 54 21 + 48 + 81
3 6 9
3 6 9
30 66 102
= (36 81 126)
42 96 150
OUTPUT DATA
------------------------------------------------------------------------------1
1
(2)
3
--2
1+8 = 9
9
(2 + 10 = 12) = (12)
3 + 12 = 15
15
--3
1 + 8 + 21
30
C00
(2 + 10 + 24) = (36) = (C10)
3 + 12 + 27
42
C20
--4
8 + 21 + 4
33
( 10 + 24 + 8 ) = (42)
12 + 27 + 12
51
28
School of Electronic, Communications and Electrical Engineering
--5
21 + 4 + 20
45
( 24 + 8 + 25 ) = (57)
27 + 12 + 30
69
--6
4 + 20 + 42
66
C01
( 8 + 25 + 48 ) = (81) = (C11)
12 + 30 + 54
96
C21
--7
20 + 42 + 7
69
(25 + 48 + 14) = ( 87 )
30 + 54 + 21
105
--8
42 + 7 + 32
81
(48 + 14 + 40) = (102)
54 + 21 + 48
123
--9
7 + 32 + 63
102
C02
( 14 + 40 + 64 ) = (126) = (C12)
921 + 48 + 81
150
C22
MSc Project Report
-------------------------------------------------------------------------------
According the above calculation, the simulation results are respected. And the total
computation time achieves nine clock cycles.
5.3 Improving Performance Bottlenecks and Future Work
As can be seen from the test results, there still remain some areas for further research. The
bottlenecks of the proposed architecture can be summarised as follows:
The total computation time is nine clock cycles. This means every nine clock cycles, we can
obtain a group of valid numbers for output. Furthermore, the maximum frequency is
101.379MHz. Therefore, the performance of the proposed architecture is not very efficient.
Based on the above limitations, there give a better architecture to optimise the structure of
pipelining.
29
School of Electronic, Communications and Electrical Engineering
B0
Input
Data
B1
B2
B20
B21
B20
B10
B11
B10
B02
B01
B00
A00
Output
Data
A01
PE00
A10
A02
PE01
A11
PE10
A20
PE02
C02 C01 C00 X X
PE12
C12 C11 C10 X X
PE22
C22 C21 C20 X X
A12
PE11
A21
PE20
MSc Project Report
A22
PE21
Figure 5-3 A better architecture
As shown in the above architecture, the latency will actually archieve three clock cycles, and
the computation time will reduced to three clock cycles compare with the nine clock cycle of
the proposed architecture.
Future Work
According the time plan, to finish the objective stated in section 1.1 requires at least four
months. After I obtain 90 points and be allowed to start my project, the time only left 2.5
months. Consider the time limitation, my supervisor asked me to finish the main body of the
project – proposing and implementing a parallel matrix multiplier using Xilinx ISE. Therefore,
the rest of the objective is to combine the software/hardware environments created by
Achint to run the multiplier.
30
School of Electronic, Communications and Electrical Engineering
MSc Project Report
6 CONCLUSION
The proposed parallel matrix multiplier has been successfully proposed and implemented on
the Xilinx ISE platform. The main challenge in the project was to deal with the multiple
independent clocks on the hardware implementation stage. Most of the problems were
found during the test stages, e.g. time sequence arrangement.
The report presents a process of researching the proposed parallel architecture. A
background review of Xilinx ISE, VHDL and FPGA are covered. A critical review of 3D
transformations and matrix multiplications are specified. The design flow of the proposed
architecture is detailed described. The assessment for simulation results is executed and also
calculates the latency and total computing time for the architecture. In addition, bottlenecks
of the existing work were specified. The idea of improvement the performance for the
architecture is finally presented by this report.
31
School of Electronic, Communications and Electrical Engineering
MSc Project Report
REFERENCES
1.
F. Bensaali, A. Amira and A. Bouridane, ‘Accelerating matrix product on reconfigurable
hardware for image processing applications’. IEE Proc. Circuits Devices and Systems, 2005 June,
pp. 236-246
2. Lab 1: Introduction to Xilinx ISE Tutorial,
http://www.ece.gatech.edu/academic/courses/fpga/Xilinx.
3. Achint Varia, ‘An FPGA based System for 3D Transformations’. Final year project report,
School of Electronic, Communication and Electrical Engineering, University of Hertfordshire,
April 2008.
4.
http://en.wikipedia.org/wiki/VHDL
5.
ISE Tutorials, www.xilinx.com
6.
Chapter V, ‘Design and Implementation of Matrix Operations’
7.
F. Bensaali, A. Amira and A. Bouridane, ‘Accelerating matrix product on reconfigurable
hardware for image processing applications’. IEE Proc. Circuits Devices and Systems, 2005 June,
pp. 236-246
8.
F. Bensaali, Ing.d’Etat, ‘Accelerating matrix product on reconfigurable hardware for image
processing applications’, PhD thesis, School of Computer Science, The Queen’s University of
Belfast, May 2005.
9.
URL:
http://zh.wikipedia.org/w/index.php?title=%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84&
variant=zh-cn
10. Joseph Mitola III, ‘Software Radio Architecture’, John Wiley & Sons, Inc., 2000.
11. S. W. Song, J. D. Zheng, ‘Prototyping a Residential Gateway Using Xilinx ISE’. Available
from: http://ieeexplore.ieee.org
32
School of Electronic, Communications and Electrical Engineering
MSc Project Report
BIBLIOGRAPHY
1. F. Bensaali, and A. Amira, ‘Field programmable gate array based parallel matrix multiplier for
3D affine transformations’. IEE Proc. Circuits Devices and Systems, December 2006, pp.
739-746
2. Xilinx ISE Tutorial <Release Version: 8.2i>, Department of Electrical and Computer State
University of New York – New Paltz Engineering, 2006
3. Xilinx ISE/WebPack: Introduction to Schematic Capture and Simulation, February 2003.
4. Tariq Naqv,i ‘Tutorial #1 for ISE 8.1i Project Navigator Using Schematic Example’
5. Joseph Mitola III, ‘Software Radio Architecture’, John Wiley & Sons, Inc., 2000.
6. Reed, Jeffrey Hugh. Software radio : a modern approach to radio engineering
7. Latha Pillai, ‘3*3 Matrix multiplier for 3D Graphics and Video’, XAPP284 v1.0, May 14, 2001
8. Latha Pillai, ‘3*3 Matrix multiplier for 3D Graphics and Video’, XAPP284 v1.1, October, 2001
9.
Xin Chunyan, ‘VHDL language (Chinese)’, Guo Fang Press
10. Yan Shi, ‘Digital circuit technology (Chinese)’, Higher Education Press, 2006.
33
School of Electronic, Communications and Electrical Engineering
MSc Project Report
APPENDIX A: SOUCE CODE (CD)
A.
Architecture (VHDL)
B.
Test code (VHDL)
34
School of Electronic, Communications and Electrical Engineering
MSc Project Report
APPENDIX B: MULT18×18
35
School of Electronic, Communications and Electrical Engineering
MSc Project Report
APPENDIX C: Time Management
Time management is very important in MSc project. The time of the project was broken down to
many smaller tasks and were allocated corresponding time to finish each task as shown in Figure
A-1. The time plan was not followed because when I obtain 90 points and was allowed to start
the project, the time only left 2.5 months.
36
School of Electronic, Communications and Electrical Engineering
MSc Project Report
Figure A-1 Time plan
37