Relative humidity
advertisement

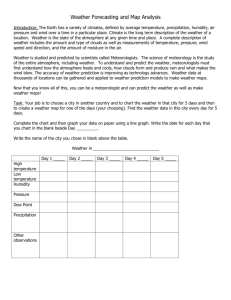
•Air Pressure: The weight of the air in the atmosphere pressing down. •At sea level the air pressure is 1013.2 mb (millibars) = 1 atmosphere 1 atmosphere = 14 lbs of air pressured per 1 square inch. How is air pressure Measured? • Barometer: Instrument that measures air pressure. Air pressure units can be in inches and millibars. Characteristics of High and Low Pressure • High Pressure – Cooler – – Dry – Associated with clear skies and cooler temperatures. • Low Pressure – Warm – – Humid/moist – Associated with stormy, cloudy, rainy weather. When air pressure is falling a storm is approaching. • In a high the winds move out and clockwise • In a low they move in and counter clockwise. • Wind move from high pressure to low pressure Wind Blows from areas of High Pressure to Areas Of low pressure Wind speed: The greater the difference in air pressure the faster the wind speed. Wind moves from areas of high pressure to areas of low pressure. This is shown with closely spaced isobars. Isobars are lines on a map that connect points of equal air pressure Sea Breeze: During the day, the land warms up faster than the water. The warm air (Low pressure) over the land rises, while the cooler air (High Pressure air) over the water sinks down and moves in to replace the warm air. Land Breeze: At night, dry land cools faster than water, Since the land cools faster than the water, the air above the water is now warmer and less dense than the air above the dry land. The Low pressure air over the water rises and the high pressure air over the land sinks and blows from the land to the sea. How is wind measured? Anemometer: Measures wind speed Wind Vane: Shows the direction of the wind INSOLATION: INCOMING SOLAR RADIATION The sun is the main source of energy for Earth. The transfer of heat and light from the sun is called radiation. Isotherms are lines on a map that connect points of equal Air temperature. Condensation Precipitation Evaporation Evaporation • When water absorbs enough heat energy it will change state and become water vapor. • Most water is evaporated for the oceans and large lakes. Factors that increase the rate of evaporation • Increased Heat: more heat more evaporation • Increased Wind: Wind provides a steady supply of dry air • Surface area: The more surface area exposed to the heat, more water will evaporate. • Water will evaporate faster on a warm, dry, windy day Humidity: Refers to the amount of water vapor in the air. Relative humidity (%): compares the actual amount of water vapor in the air with the amount of water vapor the air can hold. Saturated Air: When the air cannot hold any more water vapor. 100 % humidity. * Warm air can hold more water vapor than cold air. Condensation • When water vapor rises to cooler temperatures in the atmosphere and condenses back into a liquid. • Condensation droplets stick to tiny dust particles to form clouds. • How do clouds form? When warm humid air rises, expand, cool and condense (stick) onto condensation nuclei, forming clouds. • Condensation Nuclei: Tiny particles in the atmosphere that water vapor sticks to. As the air rises it will cool to dew point temperature Psychrometer: This instrument measures Relative humidity and Dew point (see chart) The wet bulb’s temperature decreases when you spin it because water will evaporate and evaporation has a cooling effect. Precipitation • As more and more water vapor condenses the water droplets become heavier and fall back to Earth. • Precipitation can be in the form of rain, sleet, ice or snow. • Precipitation can help remove pollutants from the atmosphere. Skills you need to know 1. Read and interpret a station model. 2. Know how to read a wet and dry bulb thermometer to determine dew point and relative humidity. Know how to read dew point and relative humidity chart. 3. Draw isobars/isotherms 4. use the temperature and air pressure conversion chart. 5. Read and interpret the Layers of the atmosphere chart. The following pages show some of these charts or you can find them in your workbook. How to use a psychrometer Step 1: Read and record the dry bulb temperature. Step 2: Spin psychrometer Step 3: Read and record the wet bulb. Step 4: Find the difference. Step 5: Match the difference and the dry bulb on the chart to find relative humidity and dew point. There are four main layers of the atmosphere. These layers have been divided by temperature changes. Facts to know: The troposphere contains most water vapor. The ozone layer is in the stratosphere. The ozone absorbs ultra violet radiation from the sun.