CSc 453
advertisement

University of
Arizona
'
Slide 19–1
Slide 19–3
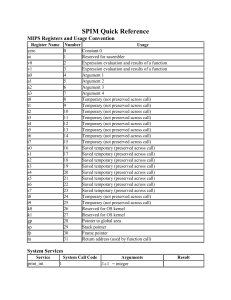
• Registers $at (1), $k0 (26), and $k1 (27) are reserved for use
by the assembler and operating system.
CSc 453
Register Use Conventions:
&
• Register $0 is always ≡ 0.
'
$
&
%
• The CPU contains 32 general registers numbered 0–31.
Compilers and Systems Software
Constant 0
Reserved for assembler
Expression evaluation and
results of a function
Argument 1-4
Temporary (not preserved across call)
Saved temporary (preserved across call)
Temporary (not preserved across call)
Reserved for OS kernel
Pointer to global area
Stack pointer
Frame pointer
Return address (used by function call)
November 18, 2002
0
$1
$2
$3
$4–$7
$8–$15
$16–$23
$24–$25
$26–$27
$28
$29
$30
$31
Christian Collberg
zero
at
v0
v1
a0
t0
s0
t8
k0
gp
sp
fp
ra
Usage
MIPS
Number
c 2002 C. Collberg
Copyright Slide 19–2
Name
'
&
CPU Registers
• Registers $a0–$a3 (4–7) are used to pass the first four
arguments to routines (remaining arguments are passed on
the stack).
• Registers $v0 and $v1 (2, 3) are used to return values from
functions.
• A MIPS processor consists of an integer processing unit and
two coprocessors: coprocessor (0) handles traps, exceptions,
and the virtual memory system; coprocessor (1) handles
floating point processing.
• Registers $t0–$t9 (8–15, 24, 25) are caller-saved registers
used for temporary quantities that do not need to be
preserved across calls.
$
%
$
%
abs Rdest, Rsrc
Absolute Value
Put the absolute value of the integer from Rsrc in Rdest.
†
• Register $fp (30) is the frame pointer.
• Register $ra (31) is written with the return address for a
call by the jal instruction.
• Register $gp (28) is a global pointer that points into the
middle of a 64K block of memory in the heap that holds
constants and global variables. The objects in this heap can
be quickly accessed with a single load or store instruction.
add Rdest, Rsrc1, Src2
Addition (with overflow)
addi Rdest, Rsrc1, Imm
Addition Immediate (with overflow)
Put the sum of the integers from register Rsrc1 and Src2 (or
Imm) into register Rdest. Same for sub.
Move
• MIPS is a load/store architecture, which means that only
load and store instructions access memory.
• Computation instructions operate only on values in registers.
Slide 19–5
Slide 19–7
neg Rdest, Rsrc
Negate Value (with overflow)
Put the negative of the integer from register Rsrc into register
Rdest.
†
Addressing Modes
$
'
move Rdest, Rsrc
Move the contents of Rsrc to Rdest.
%
&
$
'
%
&
Integer Arithmetic II
• Registers $s0–$s7 (16–23) are callee-saved registers that
hold long-lived values that should be preserved across calls.
• Register $sp (29) is the stack pointer, which points to the
first free location on the stack.
Slide 19–4
Slide 19–6
• The assembler will translate the more general form of an
instruction (e.g., add) into the immediate form (e.g., addi) if
the second argument is constant.
CPU Registers. . .
'
• Src2 is a register or an immediate value (a 16 bit integer).
&
'
&
Integer Arithmetic I
†
Format
div Rsrc1, Rsrc2
Divide (with overflow)
Divide the contents of the two registers. Leave the quotient in
register lo and the remainder in register hi.
Address Computation
(register)
contents of register
imm
immediate
imm (register)
immediate + contents of register
symbol
address of symbol
symbol ± imm
address of symbol + or − immediate
symbol ± imm
(register)
address of symbol + or − (immediate + contents
of register)
$
%
$
%
sll Rdest, Rsrc1, Src2
Shift Left Logical
sra Rdest, Rsrc1, Src2
Shift Right Arithmetic
srl Rdest, Rsrc1, Src2
Shift Right Logical
Shift the contents of register Rsrc1 left (right) by the distance
indicated by Src2 (Rsrc2) and put the result in register Rdest.
†
lui Rdest, imm
Load Upper Immediate
Load the lower halfword of the immediate imm into the upper
halfword of register Rdest. The lower bits of the register are set
to 0.
div Rdest, Rsrc1, Src2
Divide (with overflow)
Put the quotient of the integers from register Rsrc1 and Src2
into register Rdest.
†
mulo Rdest, Rsrc1, Src2
Multiply (with overflow)
Put the product of the integers from register Rsrc1 and Src2
into register Rdest.
†
Logical Operations I
$
'
Load Immediate
Slide 19–9
Slide 19–11
li Rdest, imm
Move the immediate imm into register Rdest.
mult Rsrc1, Rsrc2
Multiply
Multiply the contents of the two registers. Leave the low-order
word of the product in register lo and the high-word in register
hi.
%
&
$
'
%
&
Shifts & Rotations I
Integer Arithmetic III
'
Slide 19–8
Slide 19–10
rol Rdest, Rsrc1, Src2
Rotate Left †
ror Rdest, Rsrc1, Src2
Rotate Right †
Rotate the contents of register Rsrc1 left (right) by the distance
indicated by Src2 and put the result in register Rdest.
&
'
&
Shifts & Rotations I
and Rdest, Rsrc1, Src2
AND
andi Rdest, Rsrc1, Imm
AND Immediate
Put the logical AND of the integers from register Rsrc1 and
Src2 (or Imm) into register Rdest. Same for or, xor, nor.
not Rdest, Rsrc
NOT †
Put the bitwise logical negation of the integer from register Rsrc
into register Rdest.
$
%
$
%
Slide 19–12
Slide 19–14
jal label
Jump and Link
jalr Rsrc
Jump and Link Register
Unconditionally jump to the instruction at the label or whose
address is in register Rsrc. Save the address of the next
instruction in register 31.
jr Rsrc
Jump Register
Unconditionally jump to the instruction whose address is in
register Rsrc.
seq Rdest, Rsrc1, Src2
Set Equal †
Set register Rdest to 1 if register Rsrc1 equals Src2 and to be 0
otherwise. Same for sge, sgt, sle, slt, sne.
Comparison Instructions II
bczf label
Branch Coprocessor z False
Conditionally branch to the instruction at the label if
coprocessor z’s condition flag is true (false).
Slide 19–13
Slide 19–15
lb Rdest, address
Load Byte
Load the byte at address into register Rdest. The byte is
sign-extended. Same for ld (Load Double-Word [64 bits]), lh
(Load Half-Word [16 bits]), and (Load Word [32 bits]).
beq Rsrc1, Src2, label
Branch on Equal
Conditionally branch to the instruction at the label if the
contents of register Rsrc1 equals Src2. Same for bge, bgt,
ble, blt, bne¿
beqz Rsrc, label
Branch on Equal Zero
Conditionally branch to the instruction at the label if the
contents of Rsrc equals 0. Same for bgez, bgtz, blez, bltz,
bnez.
sb Rsrc, address
Store Byte
Store the low byte from register Rsrc at address. Same for sd
(64 bits), sh (16 bits), and sw (32 bits).
†
$
'
†
• Branch instructions use a signed 16-bit offset field; hence
they can jump 215 − 1 instructions forward or 215
instructions backwards.
• The jump instruction contains a 26 bit address field.
%
&
la Rdest, address
Load Address
Load computed address, not the contents of the location, into
register Rdest.
Comparison Instructions I
b label
Branch instruction
Unconditionally branch to the instruction at the label.
$
'
%
&
Load & Store Instructions
'
Jump
&
j label
Unconditionally jump to the instruction at the label.
'
&
Comparison Instructions III
†
$
%
$
%
• Two 32-bit registers are required to hold doubles. Floating
point operations only use even-numbered
registers—including instructions that operate on singles.
• Values are moved in or out of these registers a word
(32-bits) at a time by lwc1, swc1, mtc1, and mfc1 l.s, l.d,
s.s, and s.d pseudoinstructions.
cvt.w.s FRdest, FRsrc
Convert Single to Integer
Convert the single precision floating point number in register
FRsrc to an integer and put it in register FRdest.
• The flag set by floating point comparison operations is read
by the CPU with its bc1t and bc1f instructions.
†
s.s FRdest, address
Store Floating Point Single
Store the floating point single in register FRdest at address.
†
Floating Point Instructions I
$
'
l.s FRdest, address
Load Floating Point Single
Load the floating float single at address into register FRdest.
Slide 19–17
Slide 19–19
mov.s FRdest, FRsrc
Move Floating Point Single
Move the floating float single from register FRsrc to register
FRdest.
%
&
$
'
%
&
Floating Point Instructions III
• The MIPS has a floating point coprocessor that operates on
single precision (32-bit) and double precision (64-bit)
floating point numbers.
'
cvt.s.w FRdest, FRsrc
Convert Integer to Single
Convert the integer in register FRsrc to a single precision
number and put it in register FRdest.
Floating Point Instructions
• This coprocessor has its own registers, numbered $f0–$f31.
Slide 19–16
Slide 19–18
c.eq.s FRsrc1, FRsrc2
Compare Equal Single
Compare the floating point single in register FRsrc1 against the
one in FRsrc2 and set the floating point condition flag true if
they are equal. Same for c.le.s.
&
'
&
Floating Point Instructions II
abs.s FRdest, FRsrc
Floating Point Absolute Value Single
Compute the absolute value of the floating float double (single)
in register FRsrc and put it in register FRdest.
neg.s FRdest, FRsrc
Negate Single
Negate the floating point single in register FRsrc and put it in
register FRdest.
add.s FRdest, FRsrc1, FRsrc2 Floating Point Addition Single
Compute the sum of the floating float singles in registers FRsrc1
and FRsrc2 and put it in register FRdest. Same for div.s,
mul.s, sub.s
$
%
$
%
'
Memory Layout
Slide 19–20
Slide 19–22
• The frame pointer points just below the last argument
passed on the stack. The stack pointer points to the first
word after the frame.
&
'
&
Procedure Call
• A stack frame consists of the memory between the frame
pointer ($fp), and the stack pointer ($sp).
• At the bottom of the user address space (0x400000) is the
text segment (instructions).
• As typical of Unix systems, the stack grows down.
• The program stack ( 0x7fffffff) grows down, towards the
data segment.
$
'
Memory Layout. . .
Slide 19–21
Slide 19–23
1. Pass the arguments. The first four arguments are passed in
registers $a0–$a3. The remaining arguments are pushed on
the stack.
%
&
$
'
%
&
Procedure Call—At the call site
2. Save the caller-saved registers. This includes registers
$t0–$t9, if they contain live values.
• Above the text segment is the data segment ( 0x10000000).
The static data portion contains objects whose size and
address are known to the compiler and linker. Dynamic data
is allocated by malloc through the sbrk system call.
3. Execute a jal instruction.
$
%
$
%
Service
print int
print float
print string
read int
read float
exit
Code
1
2
4
5
6
10
Args
Res
$a0
$f12
$a0
2. Save the callee-saved registers in the frame. $fp is always
saved. $ra needs to be saved if the routine itself makes calls.
$s0–$s7 (if used by the callee) need to be saved.
3. Establish the frame pointer by adding the stack frame size
to the address in $sp.
$v0
$f0
Procedure Call—Returning from the call
$
'
%
&
$
'
%
&
System Calls. . .
'
• System calls return values in register $v0.
Procedure Call—At the called routine
1. Build the stack frame by subtracting the frame size from the
stack pointer.
Slide 19–24
Slide 19–26
• Load the system call code into register $v0 and the
arguments into registers $a0. . .$a3.
&
• You can communicate with the OS through the system call
(syscall) instruction.
'
&
System Calls
printf("the answer = %s", 5)
.data
.asciiz "the answer = "
.text
li $v0, 4
# system call code for print_str
la $a0, str
# address of string to print
syscall
# print the string
li $v0, 1
li $a0, 5
syscall
1. Place the returned value into $v0 (if a function).
Slide 19–25
Slide 19–27
str:
2. Restore any callee-saved registers that were saved upon
entry (including the frame pointer $fp).
3. Pop the stack frame by adding the frame size to $sp.
4. Return by jumping to the address in register $ra.
# system call code for print_int
# integer to print
# print it
$
%
$
%
Exit the simulator.
read "file"
Read file of assembly language commands into
SPIM. Also load "file".
run
Start running a program.
step
Step the program 1 instruction.
continue
Continue without stepping.
print $N
Print register N .
print addr
Print the contents of memory
. reinitialize
Clear memory and registers.
breakpoint addr
Set a breakpoint.
FP0
FP2
FP4
FP6
(r0)
(at)
(v0)
(v1)
(a0)
(a1)
(a2)
(a3)
00000000
00000000
00000000
00000000
00000000
00000000
00000000
00000000
R8
R9
R10
R11
R12
R13
R14
R15
=
=
=
=
0.000000
0.000000
0.000000
0.000000
FP8
FP10
FP12
FP14
(t0)
(t1)
(t2)
(t3)
(t4)
(t5)
(t6)
(t7)
=
=
=
=
=
=
=
=
=
=
=
=
quit
load
run
step
clear
print
breakpt
help
terminal
mode
set value
Slide 19–29
Slide 19–31
Control
Buttons
=
=
=
=
=
=
=
=
Cause = 0000000 BadVaddr = 00000000
LO
= 0000000
General Registers
00000000 R16 (s0) = 0000000 R24 (t8) = 00000000
00000000 R17 (s1) = 0000000 R25 (s9) = 00000000
00000000 R18 (s2) = 0000000 R26 (k0) = 00000000
00000000 R19 (s3) = 0000000 R27 (k1) = 00000000
00000000 R20 (s4) = 0000000 R28 (gp) = 00000000
00000000 R21 (s5) = 0000000 R29 (gp) = 00000000
00000000 R22 (s6) = 0000000 R30 (s8) = 00000000
00000000 R23 (s7) = 0000000 R31 (ra) = 00000000
Double Floating Point Registers
0.000000 FP16
= 0.00000 FP24
= 0.000000
0.000000 FP18
= 0.00000 FP26
= 0.000000
0.000000 FP20
= 0.00000 FP28
= 0.000000
0.000000 FP22
= 0.00000 FP30
= 0.000000
Single Floating Point Registers
Text Segments
User and
Kernel
Text
Segments
[0x00400000]
[0x00400004]
[0x00400008]
[0x0040000c]
[0x00400010]
[0x00400014]
[0x00400018]
[0x0040001c]
0x8fa40000
0x27a50004
0x24a60004
0x00041090
0x00c23021
0x0c000000
0x3402000a
0x0000000c
lw R4, 0(R29) []
addiu R5, R29, 4 []
addiu R6, R5, 4 []
sll R2, R4, 2
addu R6, R6, R2
jal 0x00000000 []
ori R0, R0, 10 []
syscall
Data Segments
Data and
Stack
Segments
[0x10000000]...[0x10010000] 0x00000000
[0x10010004] 0x74706563 0x206e6f69 0x636f2000
[0x10010010] 0x72727563 0x61206465 0x6920646e
[0x10010020] 0x000a6465 0x495b2020 0x7265746e
[0x10010030] 0x0000205d 0x20200000 0x616e555b
[0x10010040] 0x61206465 0x65726464 0x69207373
[0x10010050] 0x642f7473 0x20617461 0x63746566
[0x10010060] 0x555b2020 0x696c616e 0x64656e67
[0x10010070] 0x73736572 0x206e6920 0x726f7473
.byte b1, ..., bn Store the n values in successive bytes of
memory.
Assembler Directives. . .
$
'
R0
R1
R2
R3
R4
R5
R6
R7
= 00000000
= 00000000
.asciiz str Store the string in memory and null-terminate it.
%
&
Register
Display
EPC
HI
.align n Align the next datum on a 2n byte boundary.
.data The following data items should be stored in the data
segment.
'
$
&
%
xspim
PC
= 00000000
Status= 00000000
Slide 19–28
Slide 19–30
exit
Assembler Directives
'
# Execute ’prog’
&
> spim -file prog.as
> spim
(spim)
'
&
SPIM Terminal Interface
.float f1, ..., fn Store the n floating point single precision
numbers in successive memory locations.
.space n Allocate n bytes of space in the data segment.
.text The next items are put in the user text segment.
.word w1, ..., wn Store the n 32-bit quantities in successive
memory words.
0x726f6e67
0x74707572
0x6e67696c
0x6e69206e
0x00205d68
0x64646120
0x00205d65
SPIM Version 3.2 of January 14, 1990
SPIM
Messages
$
%
$
%
.data
.word 10
.word 20
.word 30
.asciiz "The result is: "
.asciiz "\n"
.text
.globl main
Slide 19–33
Slide 19–35
to 1
1
_p
_i
# Beginning of loop: Load p and i. p = p * i.
$32:
lw
$24, _p
lw
$25, _i
mul
$8, $24, $25
sw
$8, _p
Example – System Calls. . .
main:lw
lw
addu
sw
li
la
syscall
li
lw
syscall
li
la
syscall
li
syscall
$2,_b
$3,_c
$2,$2,$3
$2,_a
$v0, 4
$a0, res
#
#
#
#
#
#
load b
load c
add
store in a
syscall 4
(print_str)
$v0, 1
$a0, _a
# syscall 1
# (print_int)
$v0, 4
$a0, nl
# syscall 4
# (print_str)
$v0, 10
# syscall 10
# (exit)
$
'
%
&
$
'
%
&
.data
.word 0
.word 0
.asciiz "\n"
.text
.globl main
main:
# Initialize p and i
li
$14,
sw
$14,
sw
$14,
Example – System Calls
'
(spim) reinitialize
(spim) load "fac.sp"
(spim) run
1
2
6
24
120
720
5040...
_p:
_i:
_nl:
_a:
_b:
_c:
res:
nl:
Slide 19–32
Slide 19–34
Assembly and Execution:
&
main () {
int i, p=1;
for(i=1; i<=10; i++) { p = p * i; printf(p); }
}
'
&
Example 2 – Branching
$
%
$
%
The Virtual MIPS Code:
lw
li
addu
sw
main
Slide 19–36
Slide 19–38
_a:
_b:
main:
.globl
.word 0
.word 0
$2,_b
$3,0x0012d687 # 1234567
$2,$2,$3
$2,_b
li $v0, 10
syscall
Example – Procedure Call
void P (a,b) int a,b; {int c=a+b;}
main () {P(5,6);}
'
$
%
&
• Some of the assembly instructions we’ve seen are actually
virtual instructions – they are not actually implemented by
the hardware. Instead, the assembler translates them into
“real” instructions.
'
$
&
%
Example 4 – Large Ints. . .
# Print p.
li
$v0, 1
move
$a0, $8
syscall
# Print a newline.
li
$v0, 4
la
$a0, _nl
syscall
# Load i. Increment i. Store i. Loop if i is <= 10.
lw
$9, _i
addu
$10, $9, 1
sw
$10, _i
ble
$10, 10, $32
# Exit program.
li $v0, 10
syscall
'
&
main () {
int b; b = b + 1234567;
}
'
&
Example 4 – Large Ints
The MIPS Code:
Slide 19–37
Slide 19–39
• There is no instruction to load a 32-bit address or literal
integer into a register (why?). Instead, the assembler
translates li $3,0x0012d687 into two instructions: one
loads the upper 16 bits, one the lower 16 bits.
• Similarly, each branch/jump/call instruction has a delayed
branch slot. This is an instruction that in the program looks
like it comes after the jump, but which actually gets
executed before the jump is made. The assembler
automatically fills these delay slots.
P:
main:
.text
subu
addu
sw
addu
j
$sp,
$14,
$14,
$sp,
$31
subu
sw
li
li
jal
$sp, 32
$31, 28($sp)
$4, 5
$5, 6
P
8
$4, $5
4($sp)
8
$
%
$
%
You can only use even-numbered floating-point registers (i.e. $f0
$f2 $f4...) for single-precision numbers.
Can odd-numbered floating-point registers be used for some other
kind of number? If so, what kind? If not, what is the point in
having them?
# Load 1234567 into $3. First the upper 16 bits, then the lower.
lui $1, 18
; li $3,0x0012d687 # 1234567
ori $3, $1, -10617
if a > b then --Slide 19–41
Slide 19–43
when a and b are floating point number? When I try ”bczt label ”
or ”bc1t label” I got spim parse error
spim: (parser) syntax error on line 21
bczt
L10
^
Attempt to execute non-instruction at ...
You use ’c.le.s’ etc to compare two floating point numbers. This
sets the floating point coprocessor condition flag. See page 19 of
the spim manual. Then use ’bc1t label’ to jump (page 15 of the
manual).
Confused Student Email I
'
$
&
%
$
'
%
&
What is the instruction for branch
# Load the value of b. First the upper 16 bits of
# b’s address is loaded, then the lower 16 bits are
# added in, and b’s value is loaded into $2.
lui $1, 64
; lw $2,_b
lw $2, 36($1)
# Perform the add. Then load the address of b and store $2.
addu $2, $2, $3
; addu $2,$2,$3
lui $1, 64
; sw
$2,_b
sw $2, 36($1)
Double precision (64-bit) FP numbers are stored in registers
$f0+$f1, $f2-$f3, etc.
Confused Student Email V
Example 4 (C) – The Real MIPS Code
'
&
Slide 19–40
Slide 19–42
When SPIM was executing the assembly language instruction
mul.s $f2, $f0, $f1 it give the message Bit 0 in FP reg
spec and stopped execution. Could you tell me what this message
means and why it is coming up? Thank you.
'
&
Confused Student Email II
Dr.collberg: I am quiet confused about: ’.align 2’ usage. In
manual it says ”.align n aligns the next datum on a 2n byte
boundary”.What does it really use for?(ie.why we need it?) when
we should use it?
On the Mips, every variable has to be aligned (start on) an
address that is a multiple of the variable’s size. So, a 4 byte
variable has to be allocated to an address that is a multiple of 4,
e.g. 4,8,12,16,20,....
$
%
$
%
How could I load the value of Char from memory so I can do "<"
operation ? Because if I generate
.data
.float 0.0
.data
Slide 19–44
Slide 19–46
PROGRAM P1;
VAR F1 : REAL;
BEGIN
F1 := 4.14;
END.
main:
F4.14:
la $8, F1
.data
.float 4.14
.text
l.s $f2, F4.14
swc1 $f2, ($8)
.data
address: .asciiz "a"
lw $1,address
I got a error message from spim:
----Unaligned address in inst/data fetch:
Exception 4 [Unaligned address in inst/data fetch]
occurred and ignored---
And I have no idea about that .
Confused Student Email VI. . .
$
'
%
&
'
$
&
%
Homework
Confused Student Email VI
'
F1:
&
How do I load a floating point literal?
'
&
Confused Student Email VIII
• Try out spim and xspim.
Slide 19–45
Slide 19–47
• Write some small MIPS programs and execute them
using spim.
• Single step through a program. Try both the virtual
and the bare (use spim -bare) machine.
CHARs are one byte long. Use ’lb’ and ’sb’ (load and store byte)
when you’re working on CHARs. ’lw’ loads a word (4 bytes). On
the Mips words have to be aligned on a 4 byte boundary, which
is why Spim complains.
$
%
$
%