Total time: 12 cycles
advertisement

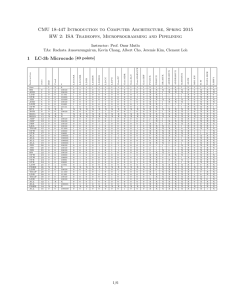
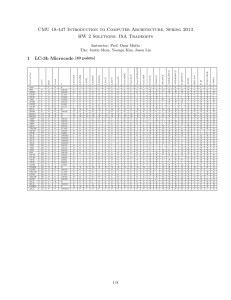
Question 13.2 S/N 0 1 2 3 4 5 6 7 8 9 10 Instruction add r3, r1, r2 load r6.[r3] and r7,r5,3 add r1,r6,r0 srl r7,r0,8 or r2,r4,r7 sub r5,r3,r4 add r0,r1,r10 load r6,[r5] sub r2,r1,r6 and r3,r7,15 IF 0 1 2 3 4 5 6 7 8 9 10 ID 1 2 3 4 5 6 7 8 9 10 11 EX 2 4 5 10 6 8 9 12 13 19 14 WB Comments 3 9 6 11 7 10 12 13 18 20 15 Clock cycles = 21 b. No out-of-order capability: S/N 0 1 2 3 4 5 6 7 8 9 10 Instruction add r3,r1,r2 load r6,[r3] and r7,r5,3 add r1,r6,r0 srl r7,r0,8 or r2,r4,r7 sub r5,r3,r4 add r0,r1,r10 load r6, [r5] sub r2,r1,r6 and r3,r7,15 IF 0 1 2 3 4 5 6 7 8 9 10 Now needs 25 clock cycles. ID 1 2 3 4 5 6 7 8 9 10 11 EX 2 4 5 10 11 13 14 15 16 22 23 WB Comments 3 9 6 11 12 14 15 16 21 23 24 c. Superscalar Instr0 add r3, r1, r2 load r6,[r3] add r1,r6,r0 sub r5,r3,r4 load r6,[r5] sub r2,r1,r6 IF0 0 1 2 3 4 5 Total clock cycles = 16 ID0 1 2 3 4 5 6 EX0 2 4 10 5 7 14 WB0 3 9 11 6 13 15 Instr1 and r7, r5, 3 srl r7, r0, 8 or r2,r4,r7 add r0,r1,r10 and r3,r7,15 IF1 0 1 2 3 4 ID1 1 2 3 4 5 EX1 2 3 5 12 6 WB1 3 4 6 13 7 Question 13.3 i. Floating point instructions take very long to execute a. Desirable to execute them first to save time ii. Floating point instructions are likely to be independent of other integer instructions (since they write to their own set of registers) and can be taken out ahead of integer instructions. iii. Hence taking out a floating point instruction and processing it ahead of other integer instructions is not only possible but very beneficial to amortize the cost of processing. iv. For branches, since branch prediction is used it is always possible to execute branches ahead of comparison results: a. If it turns out that branching is the correct decision, can just continue with fetching and executing target instructions. b. If wrong decision, must take corrective action. v. For other integer instructions, simpler and cheaper to take from bottom of queue since benefits will not be so great due to higher degrees of dependency. Simplifies dispatch logic. Question 13.6 a. Dependencies: i1: load r1, a i2: add r2, r1 i3: add r3, r4 i4: mul r4, r5 i5: comp r6 i6: mul r6, r7 i) ii) iii) True dependency between i1 and i2 Anti-dependency between i3 and i4 True dependency between i5 and i6 b. In order issue / In order completion CC 0 1 2 3 4 5 6 7 8 9 10 11 12 13 IF1 i1 i3 i5 i5 ID1 i1 i3 i3 i3 i3 i5 IF2 i2 i4 i4 i4 i6 i6 ID2 i2 i2 i2 i4 i4 i6 i6 i6 IF3 ID3 Mul Add Log Ld S1 S2 i1 i1 i4 i4 i4 i2 i2 i3 i3 i2 i5 i3 i4 i6 i6 i6 i6 i5 Total time: 14 cycles c. In order issue / Out of order completion CC 0 1 2 3 4 5 6 7 8 9 10 11 12 IF1 i1 i3 i5 i5 ID1 i1 i3 i3 i3 i3 i5 IF2 i2 i4 i4 i6 i6 i6 ID2 IF3 ID3 i2 i2 i4 i4 i4 i6 i6 Mul Add Log Ld S1 S2 i1 i1 i4 i4 i4 i6 i6 i6 i2 i2 i3 i3 i2 i5 i3 i4 i5 i6 Total time: 12 cycles d. Out-of-order issue out-of-order completion CC 0 1 2 3 4 5 6 7 8 9 10 IF1 i1 i4 ID1 i1 i4 IF2 i2 i5 i5 Total Time: 11 cycles ID2 i2 i2 i5 IF3 i3 i6 ID3 Mul Add i4 i4 i4 i3 i3 i2 i2 i3 i6 i6 Log Ld S1 S2 i1 i1 i3 i5 i4 i5 i2 i6 i6 i6