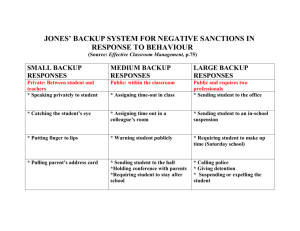
VOL3 - Eurescom
advertisement

Project P817-PF Database Technologies for Large Scale Databases in Telecommunication Deliverable 1 Overview of Very Large Database Technologies and Telecommunication Applications using such Databases Volume 3 of 5: Annex 2 - Data manipulation and management issues Suggested readers: - Users of very large database information systems - IT managers responsible for database technology within the PNOs - Database designers, developers, testers, and application designers - Technology trend watchers - People employed in innovation units and R&D departments. For full publication March 1999 EURESCOM PARTICIPANTS in Project P817-PF are: BT Deutsche Telekom AG Koninklijke KPN N.V. Tele Danmark A/S Telia AB Telefonica S.A. Portugal Telecom S.A. This document contains material which is the copyright of certain EURESCOM PARTICIPANTS, and may not be reproduced or copied without permission. All PARTICIPANTS have agreed to full publication of this document The commercial use of any information contained in this document may require a license from the proprietor of that information. Neither the PARTICIPANTS nor EURESCOM warrant that the information contained in the report is capable of use, or that use of the information is free from risk, and accept no liability for loss or damage suffered by any person using this information. This document has been approved by EURESCOM Board of Governors for distribution to all EURESCOM Shareholders. 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Preface (Edited by EURESCOM Permanent Staff) The Project will investigate different database technologies to support high performance and very large databases. It will focus on state-of-the-art, commercially available database technology, such as data warehouses, parallel databases, multidimensional databases, real-time databases and replication servers. Another important area of concern will be on the overall architecture of the database and the application tools and the different interaction patterns between them. Special attention will be given to service management and service provisioning, covering issues such as data warehouses to support customer care and market intelligence and database technology for web based application (e.g. Electronic Commerce). The Project started in January 1998 and will end in December 1999. It is a partially funded Project with an overall budget of 162 MM and additional costs of around 20.000 ECU. The Participants of the Project are BT, DK, DT, NL, PT, ST and TE. The Project is led by Professor Willem Jonker from NL. This is the first of four Deliverables of the Project and is titled: “Overview of very large scale Database Technologies and Telecommunication Applications using such Databases”. The Deliverable consists of five Volumes, of which this Main Report is the first. The other Volumes contain the Annexes. Other Deliverables are: D2 “Architecture and Interaction Report”, D3 “Experiments: Definition” and D4 “Experiments: Results and Conclusions”. This Deliverable contains an extensive state-of-the-art technological overview of very large database technologies. It addresses low-cost hardware to support very large databases, multimedia databases, web-related database technology and data warehouses. Contained is a first mapping of technologies onto applications in the service management and service provisioning domain. 1999 EURESCOM Participants in Project P817-PF page i (xi) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Executive Summary This annex contains a part of the results of the literature study to database technologies for very large databases. The other parts can be found in other annexes. This document is subdivided in three parts viz.: Transaction Processing Monitors: describing the concepts and added-value of transaction processing monitors together with available products Retrieval and Manipulation: describing aspects of data retrieval and manipulation in distributed databases, plus an overview of current commercial database systems. Backup and Recovery: describing backup and recovery strategies and their necessity in the context of high-available very large database applications. Transaction Processing Monitors reside between the client and the (database) server. Their main goals are to ensure that transactions are correctly processed, often in a heterogeneous environment, and that workload is equally distributed among available systems in compliance with security rules. The most mature products are Tuxedo, Encina, TOP END and CICS. Grip and Microsoft Transaction Server (MTS) lack some features and standards support. If you are looking for enterprise-wide capacity, consider Top End and Tuxedo. If your project is medium sized, consider Encina as well. If you look for a product to support a vast number of different platforms then Tuxedo may be the product to choose. If DCE is already used as underlying middleware then Encina should be considered. Regarding support of objects or components MTS is clearly leading the field with a tight integration of transaction concepts into the COM component model. Tuxedo and Encina will support the competing CORBA object model from the OMG. There seems to be a consolidation on the market for TP Monitors. On the one hand Microsoft has discovered the TP Monitor market and will certainly gain a big portion of the NT server market. On the other side the former TP Monitor competitors are merging which leaves only IBM (CICS and Encina) and BEA Sytems (Tuxedo and TOP END) as the old ones. The future will heavily depend on the market decision about object and component models such as DCOM, CORBA and JavaBeans and the easy access to integrated development tools. Retrieval and manipulation of data in different database architectures has various options for finding optimal solutions for database applications. In recent years many architectural options have been discussed in the field of distributed and federated databases and various algorithms have been implemented to optimise the handling of data and to optimise methodologies to implement database applications. Nevertheless, retrieval and manipulation in different architectures apply similar theoretical principals for optimising the interaction between applications and database systems. Efficient query and request execution is an important criterion when retrieving large amounts of data. This part also covers a number of commercial database products competing in the VLDB segment, most of which run on various hardware platforms. The DBMSs are generally supported by a range of tools for e.g. data replication and data retrieval. Being able to backup and recover data is essential for an organisation as no system (not even a fault-tolerant one) is free of failures. Moreover, errors are not only caused by hard- and software failures but also by (un)willfull wrong user actions. Some types of failures can be corrected by the DBMS immediately (e.g. wrong user operations) page ii (xi) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues but others need a recovery action from a backup device (e.g. disk crashes). Depending on issues like the type of system, the availability requirements, the size of the database etc., one can choose from two levels of backup and recovery. The first is on the operating system level and the second on the database level. Products of the former are often operating system dependent and DBMS independent and products of the latter the other way around. Wich product to choose depends on the mentioned issues. 1999 EURESCOM Participants in Project P817-PF page iii (xi) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 List of Authors Part 1 Berend Boll Deutsche Telekom Berkom GmbH, Germany Part 2 Frank Norman Tele Danmark Wolfgang Müller Deutsche Telekom Part 3 Sabine Gerl Deutsche Telekom Berkom GmbH, Germany Andres Peñarrubia Telefonica, Spain page iv (xi) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Table of Contents Preface ............................................................................................................................ i Executive Summary ....................................................................................................... ii List of Authors .............................................................................................................. iv Table of Contents........................................................................................................... v Abbreviations ................................................................................................................ ix Definitions .................................................................................................................... xi Part 1 Transaction Processing Monitors ................................................................... 1 1 Introduction................................................................................................................. 1 2 Concepts of Transactions ........................................................................................... 1 2.1 ACID Properties ............................................................................................... 1 2.2 Two Phase Commit Protocol ........................................................................... 1 3 Concepts of TP Monitors ............................................................................................ 2 3.1 Why should you use a TP Monitor? ................................................................ 2 3.2 Standards and Architecture .............................................................................. 4 3.3 Transaction management ................................................................................. 6 3.4 Process management ........................................................................................ 7 3.4.1 Server classes ...................................................................................... 7 3.4.2 Reduced server resources ................................................................... 7 3.4.3 Dynamic load balancing ..................................................................... 8 3.5 Robustness ....................................................................................................... 8 3.6 Scalability ........................................................................................................ 9 3.6.1 Shared process resources .................................................................... 9 3.6.2 Flexible hardware requirements ......................................................... 9 3.7 Performance ..................................................................................................... 9 3.8 Security .......................................................................................................... 10 3.9 Transaction profiles ....................................................................................... 10 3.10 Administration ............................................................................................. 11 3.11 Costs ............................................................................................................. 11 3.12 3-tier architecture framework ...................................................................... 12 3.13 When not to use a TP Monitor ..................................................................... 12 4 Commercial TP Monitors ......................................................................................... 13 4.1 BEA Systems Inc.'s Tuxedo ........................................................................... 13 4.1.1 Summary ........................................................................................... 13 4.1.2 History .............................................................................................. 14 4.1.3 Architecture ...................................................................................... 15 4.1.4 Web Integration ................................................................................ 16 4.1.5 When to use ...................................................................................... 17 4.1.6 Future plans ...................................................................................... 17 4.1.7 Pricing ............................................................................................... 18 4.2 IBM's TXSeries (Transarc's Encina) .............................................................. 18 4.2.1 Summary ........................................................................................... 18 4.2.2 History .............................................................................................. 19 4.2.3 Architecture ...................................................................................... 19 4.2.4 Web Integration ................................................................................ 21 1999 EURESCOM Participants in Project P817-PF page v (xi) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 4.2.5 When to use ....................................................................................... 21 4.2.6 Future plans ....................................................................................... 22 4.2.7 Pricing ............................................................................................... 22 4.3 IBM's CICS..................................................................................................... 22 4.3.1 Summary ........................................................................................... 22 4.3.2 History ............................................................................................... 23 4.3.3 Architecture ....................................................................................... 23 4.3.4 Web integration ................................................................................. 25 4.3.5 When to use ....................................................................................... 26 4.3.6 Future plans ....................................................................................... 26 4.3.7 Pricing ............................................................................................... 27 4.4 Microsoft Transaction Server MTS ............................................................... 27 4.4.1 Summary ........................................................................................... 27 4.4.2 History ............................................................................................... 27 4.4.3 Architecture ....................................................................................... 28 4.4.4 Web Integration................................................................................. 29 4.4.5 When to use ....................................................................................... 29 4.4.6 Future plans ....................................................................................... 29 4.4.7 Pricing ............................................................................................... 29 4.5 NCR TOP END .............................................................................................. 30 4.5.1 Summary ........................................................................................... 30 4.5.2 History ............................................................................................... 30 4.5.3 Architecture ....................................................................................... 31 4.5.4 Web Integration................................................................................. 32 4.5.5 When to use ....................................................................................... 33 4.5.6 Future plans ....................................................................................... 33 4.5.7 Pricing ............................................................................................... 34 4.6 Itautec's Grip................................................................................................... 34 4.6.1 Summary ........................................................................................... 34 4.6.2 History ............................................................................................... 34 4.6.3 Architecture ....................................................................................... 35 4.6.4 Web Integration................................................................................. 36 4.6.5 When to use ....................................................................................... 36 4.6.6 Future plans ....................................................................................... 36 4.6.7 Pricing ............................................................................................... 37 5 Analysis and recommendations................................................................................. 37 5.1 Analysis .......................................................................................................... 37 5.2 Recommendations .......................................................................................... 37 References .................................................................................................................... 38 Part 2 Retrieval and Manipulation .......................................................................... 39 1 Introduction ............................................................................................................... 39 1.1 General architecture of distributed Databases ............................................... 39 1.1.1 Components of a distributed DBMS ................................................. 39 1.1.2 Distributed versus Centralised databases .......................................... 41 1.2 General architecture of federated Databases .................................................. 41 1.2.1 Constructing Federated Databases .................................................... 42 1.2.2 Implementing federated database systems ........................................ 44 1.2.3 Data Warehouse Used To Implement Federated System .................. 46 1.2.4 Query Processing in Federated Databases ........................................ 47 page vi (xi) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues 1.2.5 Conclusion: Federated Databases ..................................................... 47 2 Organisation of distributed data ............................................................................... 48 2.1 Schema integration in Federated Databases .................................................. 48 2.2 Data Placement in Distributed Databases ...................................................... 49 2.2.1 Data Fragmentation .......................................................................... 50 2.2.2 Criteria for the distribution of fragments.......................................... 50 3 Parallel processing of retrieval ................................................................................. 51 3.1 Query Processing ........................................................................................... 51 3.2 Query optimisation......................................................................................... 51 4 Parallel processing of transactions ........................................................................... 52 4.1 Characteristics of transaction management .................................................. 52 4.2 Distributed Transaction.................................................................................. 52 5 Commercial products ................................................................................................ 53 5.1 Tandem........................................................................................................... 53 5.1.1 Designed for scalability .................................................................... 53 5.1.2 High degree of manageability ........................................................... 53 5.1.3 Automatic process migration and load balancing............................. 53 5.1.4 High level of application and system availability ............................ 53 5.2 Oracle ............................................................................................................. 54 5.2.1 Oracle8.............................................................................................. 54 5.2.2 A Family of Products with Oracle8 .................................................. 55 5.3 Informix ......................................................................................................... 60 5.3.1 Informix Dynamic Server ................................................................. 60 5.3.2 Basic Database Server Architecture ................................................. 60 5.3.3 Informix Dynamic Server Features................................................... 62 5.3.4 Supported Interfaces and Client Products ........................................ 64 5.4 IBM ................................................................................................................ 66 5.4.1 DB2 Universal Database................................................................... 66 5.4.2 IBM's Object-Relational Vision and Strategy .................................. 69 5.4.3 IBM’s Business Intelligence Software Strategy ............................... 71 5.5 Sybase ............................................................................................................ 73 5.5.1 Technology Overview: Sybase Computing Platform ....................... 73 5.5.2 Sybase's Overall Application Development/Upgrade Solution: Customer-Centric Development ................................................... 76 5.5.3 Java for Logic in the Database ......................................................... 77 5.6 Microsoft ........................................................................................................ 79 5.6.1 Overview........................................................................................... 79 5.6.2 Microsoft Cluster Server .................................................................. 81 5.7 NCR Teradata ................................................................................................ 83 5.7.1 Data Warehousing with NCR Teradata ............................................ 83 5.7.2 Teradata Architecture ....................................................................... 84 5.7.3 Application Programming Interfaces ................................................ 85 5.7.4 Language Preprocessors ................................................................... 85 5.7.5 Data Utilities ..................................................................................... 86 5.7.6 Database Administration Tools ........................................................ 86 5.7.7 Internet Access to Teradata .............................................................. 86 5.7.8 NCR's Commitment to Open Standards ........................................... 86 5.7.9 Teradata at work ............................................................................... 87 6 Analysis and recommendations ................................................................................ 87 1999 EURESCOM Participants in Project P817-PF page vii (xi) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 References .................................................................................................................... 88 Part 3 Backup and Recovery..................................................................................... 91 1 Introduction ............................................................................................................... 91 2 Security aspects ......................................................................................................... 91 3 Backup and Recovery Strategies ............................................................................... 93 3.1 Recovery ......................................................................................................... 95 3.2 Strategies ........................................................................................................ 96 3.2.1 Requirements .................................................................................... 96 3.2.2 Characteristics ................................................................................... 97 4 Overview of commercial products ............................................................................ 97 4.1 Tools ............................................................................................................... 98 4.1.1 PC-oriented backup packages ........................................................... 98 4.1.2 UNIX packages ................................................................................. 98 4.2 Databases ...................................................................................................... 100 4.2.1 IBM DB2 ......................................................................................... 100 4.2.2 Informix........................................................................................... 101 4.2.3 Microsoft SQL Server ..................................................................... 102 4.2.4 Oracle 7 ........................................................................................... 102 4.2.5 Oracle 8 ........................................................................................... 103 4.2.6 Sybase SQL Server ......................................................................... 105 5 Analysis and recommendations............................................................................... 105 References .................................................................................................................. 106 Appendix A: Backup and Restore Investigation of Terabyte-scale Databases .......... 107 A.1 Introduction ................................................................................................. 107 A.2 Requirements ............................................................................................... 107 A.3 Accurate benchmarking ............................................................................... 107 A.4 The benchmark environment ....................................................................... 108 A.5 Results ......................................................................................................... 109 A.5.1 Executive summary ........................................................................ 109 A.5.2 Detailed results ............................................................................... 111 A.6 Interpreting the results ................................................................................. 113 A.7 Summary ...................................................................................................... 113 Appendix B: True Terabyte Database Backup Demonstration .................................. 115 B.1 Executive Summary ..................................................................................... 115 B.1.1 Definitions ...................................................................................... 116 B.2 Detailed Results ........................................................................................... 116 B.2.1 Demonstration Environment .......................................................... 116 B.2.2 Results ............................................................................................ 117 B.3 Interpreting the Results ................................................................................ 118 B.4 Summary ...................................................................................................... 119 page viii (xi) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Abbreviations ACID Atomicity, Consistency, Isolation, Durability ACL Access Control List. Used to define security restictions for objects/resources COM Microsoft's Component Object Model CORBA OMG's Common Object Request Broker Architecture DBA Database Administrator DBMS Database Management System DBS Data Base System DCE Open Group’s Distributed Computing Environment DCOM Microsoft's Distributed Component Object Model DDL Data Definition Language DML Database Manipulation Language DRM Disaster Recovery Manager DSA Database Server Architecture DTP Model Distributed Transaction Processing Model, defined by the Open Group. FDBS Federated Database System GIF Graphics Interchange Format HSM Hierarchical Storage Management HTML Hypertext Markup Language IDL Interface Definition Language JDBC Java Database Connectivity LOB Line-Of-Business MDBS Multi Database System MOM Message-Oriented Middleware MPP Massively Parallel Processing NCA Network Computing Architecture ODBC Open Database Connectivity OLAP Online Analytical Processing OMG Object Management Group Open Group None-profit, vendor-independent, international consortium. Has created the DTP Model and the XA Standard for Transaction Processing. ORB Object Request Broker ORDBMS Object-Relational DBMS 1999 EURESCOM Participants in Project P817-PF page ix (xi) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 PDF Portable Document Format RDBMS Relational DBMS RPC Remote Procedure Call SMP Symmetric Multiprocessing TLI Transport Layer Interface (APIs such as CPI-C the SNA peer-topeer protocol and Named Pipes) TP Monitor Transaction Processing Monitor TPC Transaction Processing Performance Council tpmC Transaction Per Minute measured in accordance with TPC's C standard (TPC-C). UDF User-defined Function UDT User-defined Data Type ULL United Modeling Language VLDB Very Large Database VLDB Very Large Database VLDB Very Large Database XA API used to co-ordinate transaction updates across resource managers page x (xi) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Definitions ACID properties the four transaction properties: atomicity, consistency, integrity, durability. Conversational Kind of communication. Unlike request-response each request in a conversation goes to the same service. The service remains state information about the conversation. There is no need to send state information with each client request. Publish-Subscribe Kind of communication. (Publisher) Components are able to send events and other components (Subscribers) are able to subscribe to a special event. Everytime the subsribed event happens within the publisher component the subscriber component gets notified by a message. Queue Kind of communication. A queue provides time-independent communication. Request and Responses are stored in a queue and could be accessed asynchronously. Request-response Kind of communication. The client issues a request to a service and then waits for a response before performing other operations (an example is a RPC) Resource managers a piece of software that manages shared resources server class a group of processes that are able to run the code of the application program. two-phase commit Protocol for distributed transactions 1999 EURESCOM Participants in Project P817-PF page xi (xi) Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Part 1 Transaction Processing Monitors 1 Introduction "The idea of distributed systems without transaction management is like a society without contract law. One does not necessarily want the laws, but one does need a way to resolve matters when disputes occur. Nowhere is this more applicable than in the PC and client/server worlds." - Jim Gray (May, 1993) 2 Concepts of Transactions Transactions are fundamental in all software applications, especially in distributed database applications. They provide a basic model of success or failure by ensuring that a unit of work must be completed in its entirety. From a business point of view a transaction changes the state of the enterprise, for example a customer paying a bill which constitutes in changes of the order status and a change on balance sheets. From a technical point of view we define a transaction as "a collection of actions that is governed by the ACID-properties" ([5]). 2.1 ACID Properties The ACID properties properties describe the key features of transactions: Atomicity. Either all changes to the state happen or none do. This includes changes to databases, message queues or all other actions under transaction control. Consistency. The transaction as a whole is a correct transformation of the state. The actions undertaken do not violate any of the integrity constraints associated with the state. Isolation. Each transaction runs as though there are no concurrent transactions. Durability. The effects of a committed transaction survive failures. Database and TP systems both provide these ACID properties. They use locks, logs, multiversions, two-phase-commit, on-line dumps, and other techniques to provide this simple failure model. 2.2 Two Phase Commit Protocol The two-phase commit protocol is currently the accepted standard protocol to achieve the ACID properties in a distributed transaction environment. Each distributed transaction has a coordinator, who initiates and coordinates the transaction. In the first phase the coordinator (root node) informs all participating subordinate nodes of the modifications of the transaction. This is done via the prepare-to-commit message. Then the coordinator waits for the answers of the subordinate nodes. In case of success he gets a ready-to-commit message from each of the subordinate nodes. The root node logs this fact in a safe place for recovery from a root node failure. 1999 EURESCOM Participants in Project P817-PF page 1 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 If any of the subordinate nodes fails and does not send a ready-to-commit message to the root node then the whole transaction will be aborted. In the second phase the coordinator sends a commit message to all subordinate nodes. They commit their actions and answer with a complete message. The protocol is illustrated in the figure below. Coordinator (root node) Participant (subordinate root) Participant (subordinate root) start prepare Log file ready-to-commit ready-to-commit Phase 1 prepare commit complete complete Phase 2 commit complete Figure 1. Two-Phase Commit Protocol Most TP Monitors could easily handle transactions that spanned across 100 two-phase commit engines. However, the two phase commit has some limitations: Performance overhead. There is a message overhead, because the protocol does not distinguish for the different kind of transactions. That means also for readtransactions all the messages of the two-phase commit protocol will be sent, even if they are not really needed. Hazard windows. At special times a failure of a node can lead to a problem. For example, if the root node crashes after the first phase, the subordinate rotes may be left in disarray. There are workarounds, but they tend to be tricky. So the architecture should be built in a way, that the root node is located on a faulttolerant system. 3 Concepts of TP Monitors 3.1 Why should you use a TP Monitor? Based on the TPC ranking of February 1998, the success of TP Monitors was clearly demonstrated by the fact that every single test environment of the top 20 TPC-C benchmark results (ranked by transactions per minute) included a TP Monitor. If the same results are ranked by the price/performance ratio, 18 of the top 20 used a TP Monitor ([1], [12]). Why are TP Monitors so popular in modern architectures and what problems do they address? page 2 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues To understand this one has to take a look at how application architectures are build. All applications consist of three parts: presentation layer (GUI) which resides on the client application layer which could reside on a separate application servers data layer which could resides on a separate database severs. In many applications the is no clear separation of those layers within the code. The same code could do work for all three layers. Good structured applications separate these layers on the code (software) and on the hardware level. 2-tier applications are applications that have the application layer integrated within the presentation layer on the client and/or the data layer (as Remote Procedures) an the database server. 3-tier application separate the application and most often run them on special application servers. Still with a separation of an application layer one could run an application layer services physically on the client or on the database server. But the point is that there exists a separation and a possibility to redistribute the application layer services on special purpose machines based on workload and performance issues. Basically TP Monitors provide an architecture to build 3-tiered client/server applications. According to Standish Group, in 1996 57% of mission-critical applications were built with TP Monitors. This is because former 2-tiered architectures have the following problems: For each active client the databases must maintain a connection which consumes machine resources, reducing performance as the number of clients rises. 2-tiered applications scale well to a point and then degrade quickly. Reuse is difficult, because 2-tiered application code like stored-procedures is tightly bound to specific database systems Transactional access to multiple data sources is only possible via gateways. But gateways integrate applications on the data level which is "politically" and technically unstable and not adoptive to change ("politically" refers to the problem, that the owner of the data might not be willing to give access at the data level outside of his department). Database stored-procedures could not execute under global transaction control. They could not be nested and programmed in a modular basis. Also they are vendor-specific. Outside of trusted LAN environments the security model used in 2-tiered systems doesn't work well, because it focuses on granting users access to data. Once administrators give a user write or change access to a table, the user can do almost anything to the data. There is no security on the application level. There is no transaction mechanism for objects (CORBA) or components (COM, JavaBeans). TP Monitors address all of the above problems and despite their rare usage in average client/server-applications they have a famous history in the mainframe area. Nowadays they tend to raise more and more attention because of the development of commercial applications on the Internet. 1999 EURESCOM Participants in Project P817-PF page 3 (120) Volume 3: Annex 2 - Data manipulation and management issues 3.2 Deliverable 1 Standards and Architecture A TP Monitor could be described as an operating system for transaction processing. It delivers the architecture to distribute and manage transactions over a heterogeneous infrastructure. This implicitly forces the application architecture to be 3-tier, because a TP Monitor is a type of middleware. A TP Monitor does three things extremely well: Process management includes starting server processes, funneling work to them, monitoring their execution and balancing their workloads. Transaction management means that the TP Monitor guarantees the ACID properties to all the programs that run under its protection. Client/Server communication management allows clients (and services) to invoke an application component in a variety of ways - including requestresponse, conversations, queuing, publish-subscribe or broadcast. DBMS 1 Client DBMS 2 Client File handling System Business Logic / TP Monitor Client Message Queue Client Application Process 1 Application Process 2 Figure 2. 3-tier client/server with TP Monitor A TP Monitor consists of several components. The Open Group's Distributed Transaction Processing Model (1994) ([10]), which has achieved wide acceptance in the industry, defines the following components: The application program contains the business logic. It defines the transaction boundaries through calls it makes to the transaction manager. It controls the operations performed against the data through calls to the resource managers. Resource managers are components that provide ACID access to shared resources like databases, file systems, message queuing systems, application components and remote TP Monitors. The transaction manager creates transactions, assigns transaction identifiers to them, monitors their progress and coordinates their outcome. The Communication Resource Manager controls the communications between distributed applications. page 4 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Application Program (AP) RM API XATMI TX API TxRPC CPI-C Transaction Manager (TM) Resource Manager (RM) XA API XA+ API Communication Resource Managers (CRM) Figure 3. X/Open 1994 Distributed Transaction Processing Model The following interfaces exist between the components: RM API is used to query and update resources owned by a resource manager. Typically the provider of the resource manager defines this interface. For example, the API for a relational database would be an SQL API. TX API is used to signal the transaction manager the beginning, the commitment or the abortion of a transaction. XA API is used to coordinate transaction updates across resource managers (two-phase commit protocol). XA+ API defines the communication between the communications resource managers and the transaction manager. This interface, however, was never ratified, so not all the vendors use it. On the whole, the XA+ interface is relatively unimportant as, generally, it is used internally within the product. XATMI, TxRPC and CPI-C are transaction communication programming interfaces. There is no general standard. XATMI is based on BEAs Tuxedo's Application to Transaction Monitor Interface (ATMI); TxRPC is based on the Distributed Processing Environment (DCE) RPC interface and CPI-C is based on IBMs peerto-peer conversational interface. The role of these components and interfaces within a 3-tier architecture is visualized with the following picture. The client (presentation layer) communicates with the Application Program (AP). The access to the data-layer is done via the Resource Manager (RM) component. If several distributed TP Monitors are involved within a transaction, the Communication Resource Managers (CRM) are responsible for the necessary communication involved. 1999 EURESCOM Participants in Project P817-PF page 5 (120) Volume 3: Annex 2 - Data manipulation and management issues RPC, Queue, ... Deliverable 1 Application Program Client CRM TM RM Database TP Monitor X TCP/IP, SNA, OSI TP Monitor Y CRM TM RM Database Application Program PresentationLayer Application-Layer Data-Layer Figure 4. TP Monitor within a 3-tier architecture Actual implemenations of TP Monitors consists of serveral other components but these differ from product to product. Therefore the OpenGroup DTP Model could only be used to understand the main function of a TP Monitor: distributed transaction management. Other components include modules for client/server communication such as queues (which all TP Monitors have now included), administration tools, directory services and many more. We refer here to the commercial product chapter of this part. The key interface is XA, because it is the interface between the resource manager from one vendor and the DTPM from the middleware vendors. XA is not a precise standard, nor does it comprise source code which can be licensed. It is a specification against which vendors are expected to write their own implementations. There are no conformance tests for the X/Open XA specification, so it is not possible for any vendor to state that it is 'XA-compliant'; all that vendors can claim is that they have used the specification and produced an XA implementation which conforms to it. The situation is complicated even more by the fact, that the commitee which devised the XA Model and the specifications has now disbanded. The DBMSs that definitely support the XA standard and also work with all DTPMs that support the standard are Oracle, Informix, SQL Server and DB2/6000. In the following chapter we will describe special features of TP Monitors in more detail. 3.3 Transaction management TP Monitors are operation systems for business transactions. The unit of management, execution and recovery is the transaction. The job of the TP Monitor is to ensure the ACID properties even in a distributed resource environment while maintaining a high transaction throughput. The ACID properties are achieved through co-operation between the transaction manager and resource managers. All synchronisation, commit and rollback actions are co-ordinated by the transaction manager via the XA interface and the 2-phase-commit protocol. page 6 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues 3.4 Process management 3.4.1 Server classes TP Monitors main job is managing processes. They keep pools of pre-started application processes or threads (called server classes). Each process or thread in the server class is able to run the application. The TP Monitor balances the work between them. Each application can have one or more server classes. These server processes are pre-warmed. They are already loaded in memory, have a context and are ready to start instantly. If they finish their work for one client request they stay in memory and wait for the next request. 3.4.2 Reduced server resources Keeping and sharing these pre-warmed processes dramatically reduces the number of concurrent processes and therefore makes it possible to support huge number of clients. Database 1000 Clients 1000 connections + 1000 Processes + 500 MB of RAM + 10,000 open files Figure 5. Process Management without TP Monitor This kind of process management could be described as a pooling and funnelling. It provides scalability for huge database applications because it addresses the problem that databases establish and maintain a separate database connection for each client. It is because of this feature that all leading TPC-C benchmarks are obtained by using TP Monitors ([12]). Database TP Monitor 1000 Clients 100 Server Classes 50 50 shared connections + 50 Processes + 25 MB of RAM + 500 open files Figure 6. Process Management with TP Monitor - pooling and funneling 1999 EURESCOM Participants in Project P817-PF page 7 (120) Volume 3: Annex 2 - Data manipulation and management issues 3.4.3 Deliverable 1 Dynamic load balancing If the number of incoming client requests exceeds the number of processes in a server class, the TP Monitor may dynamically start new processes or even new server classes. The server classes can also be distributed across multiple CPUs in SMP or MPP environments. This is called load balancing. It could be done via manual adminstration or automatically by the TP Monitor. In the latter case it is called dynamic load balancing. This load balancing could be done either for appication layer or data layer processes. For data layer processes the database server bottleneck could be released by having several (replicated) databases over which the TP Monitor could distribute the workload. 3.5 Robustness TP systems mask failures in a number of ways. At the most basic level, they use the ACID transaction mechanism to define the scope of failure. If a service fails, the TP Monitor backs out and restarts the transaction that was in progress. If a node fails, it could migrate server classes at that node to other nodes. When the failed node restarts, the TP system's transaction log governs restart and recovery of the node's resource managers. In that way the whole application layer running as server classes on potentially distributed application servers is highly available. Each failure (local process/server class or total machine) could be masked by the TP Monitor by restarting or migrating the server class. Also the data layer is robust to failure, because a resource manager under TP Monitor control masks the real database server. If a database server crashes, the TP Monitor could restart the database server or migrate the server classes of the resource manager to a fallback database server. In either cases (failure of application or data layer) the failures will be fixed by the TP Monitor without disturbing the client. the TP Monitor is acting as a self-healing system, it not just handles faults, it automatically corrects them. This could be done because the client is only connected to one TP Monitor. The TP Monitor handles all further connections to different application, database, file services etc. The TP Monitor handles failures of servers and redirects the requests if necessary. That implies that the TP Monitor itself should be located on a fault-tolerant platform. Still it is possible to run several TP monitor server processes on different server machines that could take over the work of each other in case of failure, so that even this communication links has a fallback. Different to a 2-tier approach a client could crash and leave an open transaction with locks on the database, because not the client but the TP Monitor controls the connections to the database. Therefore the TP Monitor could rollback connections for a crashed client. TP systems can also use database replicas in a fallback scheme - leaving the data replication to the underlying database system. If a primary database site fails, the TP Monitor sends the transactions to the fallback replica of the database. This hides server failures from clients - giving the illusion of instant fail-over. Moreover TP Monitors deliver a wide range of synchronous and asynchronous communication links for application building including RPCs, message queues page 8 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues (MOMs), ORB/DCOM-invocation, conversational peer-to-peer and event-based publish-and-subscribe communication. Therefore based on the infrastructure and the nature of the services, the best communication links could be chosen. In short the following services are delivered: Failover Server Automatic retry to re-establish connection on failure Automatic restart of process on client, server or middleware Automatic redirection of requests to new server instance on server failure. Appropriate and reliable communication links. Transaction deadlocks are dissolved. 3.6 Scalability 3.6.1 Shared process resources TP Monitors are the best at database funneling, because they are able to use only a handful of database connections while supporting thousands of clients (see section on Process Management). Therefore by reducing the connection overhead on the database server they make the database side much more scalable. In a 3-tier TP Monitor architecture for database access there are typically at least a factor of 10 fewer database connections necessary than in a straightforward 2-tier implementation. Database Resources Without TP Monitor With TP Monitor Number of clients Figure 7. Scalability of the database layer 3.6.2 Flexible hardware requirements Scalability is not only enhanced on the database side. With dynamic load balancing the load could be distributed over several machines. By doing this the whole architecture becomes very flexible on the hardware side. To increase the total processing capabilities of the 3-tier architecture one could either upgrade server machines or increase the number of servers. The decision could be made based on costs and robustness of the hardware and on company policies. 3.7 Performance Performance could be sped up by different approaches. First of all it is based on the effective handling of processes in one machine. TP Monitors deliver an architecture 1999 EURESCOM Participants in Project P817-PF page 9 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 for multi-threading/multi-tasking on the middleware and the application layer. That includes: Automatic creation of new threads/tasks based on loads Automatic deletion of threads/tasks when load reduces Application parameters dynamically altered at runtime. TP Monitors are speeding up performance by keeping the pool of processes in memory together with their pre-allocated resources. In this pre-warmed environment each client request could be instantaneously processed without the normal starting phase. Another way to enhance performance is to use more processors/machines to share the workload. TP Monitor support load balancing for: 3.8 multiple processors in one machine (SMP or MPP) multiple machines (nodes) multiple middleware, application and resource services (which may be started on demand as stated above). Security The TP Monitor provides a convenient way to define users and roles and to specify the security attributes of each service in an access control list (ACL). It authenticates clients and checks their authority on each request, rejecting those that violate the security policy. Doing this it delivers a fine granulate security on the service/application level which adds a lot of value to security on the database or communication line levcl. Aspects of security typically include: Role. Based on roles, users have security restrictions to use the services. Workstation. It is defined which physical workstation is allowed to request what service. Time. A service might be limited to a special period of time. For example, in a payment systems, clerks might be allowed to make payments from in-house workstations during business hours. Furthermore a TP Monitor supports general communication security features as 3.9 Authentication Authorization Encryption. Transaction profiles It is possible to assign profiles to transactions/server classes. Attributes of profiles include: Priority. Transaction could have different priorities which are used by the TP Monitor to do load-balancing. page 10 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 3.10 Volume 3: Annex 2 - Data manipulation and management issues Security. Defines who is allowed to use the service. Administration As described in the above sections processes are clustered into pools in service classes. Typically, short-running or high-priority services are packaged together, and batch or low-priority work is packaged in separate low-priority server classes. After packaging the services, an administrator could assign security attributes to them. Change is constant, and TP Monitors manage it on the fly. They can, for example, automatically install a service by creating a server class for it (dynamic loadbalancing). Even more interesting, they can upgrade an existing service in place by installing the new version, creating new service classes that use it, and gradually killing off old server classes as they complete their tasks (on-the-fly software release upgrades). Of course, the new version must use the same request-reply interface as the old one. This load-balancing feature could also be used for planned outages in case of maintenance for 24x7 applications to shift all load to a back-up machine. The registration and start-up/shut-down of resources is unbundled from the application, because the application uses services of the TP Monitor which are mapped to available resources. Therefore resources could be added and removed on the fly. There is no direct connection between a resource and an application (i.e. via an IP-number or DNS-name of a Database-Server). Overall TP Monitors help to configure and manage client/server interactions. They help system administrators to install, configure and tune the whole system, including application services, servers and large populations of clients. Administration features include: Remote installation of middleware and applications Remote configuration Performance monitoring of applications, databases, network, middleware Remote start up/shut down of application, server, communication link and middleware Third party tool support Central administration Fault diagnosis with alerts/alarms, logs and analysis programs. Even if it should be possible to administer processes and load-balancing manually, the preferred option should always be an automatic, self-administrating and self-healing system. 3.11 Costs TP Monitors help to reduce overall costs in large, complex application systems servers. They do this in several ways: Less expensive hardware. By doing optimized load-balancing together with better performance, TP Monitors help to use resources more efficiently. 1999 EURESCOM Participants in Project P817-PF page 11 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Moreover by funneling client request, the number of concurrent processes running on the resources (databases) could be drastically reduced (normally by the factor of 10). Therefore the TP Monitor architectures have lower hardware requirements. Reduced Downtimes. Because of the robust application architecture downtimes of applications could be reduced. This reduces lost profits because of downtimes. Reduced license costs. The funneling effect reduces the number of concurrent open connections to the database server, therefore reducing expensive license costs. Development time savings. By delivering an application architecture and forcing the developers to build the system over a 3-tier architecture system development and maintenance time is reduced (according to Standish Group by up to 50%). According to Standish group this may result in total system cost savings of greater than 30% over a data-centric (2-tier) approach. 3.12 3-tier architecture framework TP Monitors provide a framework to develop, build, run and administer client/server applications. Increasingly, visual tool vendors are integrating TP Monitors and making them transparent to the developer. TP Monitors deliver shared state handling (transaction context) to exchange information between the services, freeing developers from this task. They introduce an event-driven component based programming style on the server side. Services are created and only function calls or objects are exported not the data itself. This allows to keep adding functions and let the TP Monitor distribute them over multiple servers. They provide a clear 3-tier architecture framework. It is almost impossible to violate this paradigma by "lazy" programmers. The application becomes strictly modularised with decoupled components. This leads to a state of the art architecture which fits best into current object and component paradigmas. Maintenance and re-use are best supported by such architectures. 3.13 When not to use a TP Monitor Despite the fact that a TP Monitor has a lot of advantages you do not need it for all kind of applications and there are also some other drawbacks: Few users. Even if you have a VLDB with complex data you do not need a TP Monitor if you have just a few concurrent users at any time. TP Monitor helps nothing in managing data but it helps a lot in managing processes. Raised Complexity. If you include a new component like a TP Monitor in the architecture it raises the complexity to be mastered (at least in the beginning and regarding the knowledge of the people involved). So you need to have the necessary knowledge in your development and administration team. But in fact with big systems the complexity is not raised but lowered, because the whole application structure becomes better modularized and decoupled (see section on 3-tier architecture framework). page 12 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 4 Volume 3: Annex 2 - Data manipulation and management issues Vendor dependence. Because the architecture of all TP Monitor systems is different it is not so easy to switch from one TP Monitor to another TP Monitor. Therefore for some part you are locked with a one vendor solution. Commercial TP Monitors The following comparison of the different available TP Monitors is heavily based on a study done by Ovum Publications ([11]) Ovum Publications, www.ovum.com, "Distributed TP Monitors", February 1997 and recent information from the product companies. In general all of the products follow the OpenGroup standard DTP architecture described in Figure 3. They differ in their support of the XA-Interface between the Transaction manager and the Resource manager which is of the greatest importance for the for the usage of a TP Monitor. Also some of them integrate the Transaction Manager and the Communication Resource Manager into one component (BEAs Tuxedo). But this has no importance for the usage of the TP Monitor because anyhow the interface between those two components is only used internally and should have no impact on the applications built on the TP Monitor. Also this XA+ interface between those components was never officially standardized. So the differentiation between the products should be mostly done by supported resources supported communication protocols platform support company history, structure and future Internet support Object / Component support Price Easy usage Future developments market share your expertise in similar/complemtary tools and programming languages 4.1 BEA Systems Inc.'s Tuxedo 4.1.1 Summary Key Points Transaction control available via XA compliant resource managers, such as Oracle, Informix, and others. Interoperates with MQSeries via third party or own gateways. Can also interoperate with other TP environments via the XAP OSI-TP standard and SNA (CICS) and R/3. 1999 EURESCOM Participants in Project P817-PF page 13 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Runs on OS/2, MS-DOS, Windows 3, Windows 95, Windows NT, Apple Macintosh, AS/400 and a wide range of UNIX flavours from the major system providers. Supports Bull GCOS8, ICL VME, MVS IMS, Unisys A series, and MVS/CICS via third party or own gateways. [ Note: I am not aware of GCOS8 or VME functionality in the latest versions of the product, although I may not know of all the 3rd party versions.] Directly supports TCP/IP, via sockets or TLI. Indirectly supports SNA LU6.2. Strengths Excellent directory services, with a labor-saving architecture and good administrative support tools, all suited to large-scale deployment Vast array of platforms (Hardware, Netware, Middleware) supported, with links to some environments which have no other strategic middleware support, such as GCOS and VME All technology is now available from one supplier, with a correspondingly clear strategy for development, support and evolution Weaknesses 4.1.2 BEA still has some way to go to integrate all the technology and people it has acquired - especially after buying TOP END from NCR. Guaranteed delivery services on the communication services side are not well developed Load balancing services should be more automated History AT&T started the development of Tuxedo in 1979 as part of an application called LMOS (Line Maintenance and Operation System). The product evolved internally within Bell Labs until 1989, when AT&T decided to license the technology to OEMs (value-added resellers). At 1992 AT&T had spun off the development of Unix, languages and Tuxedo into a new group named Unix Systems Laboratories (USL). In 1993, Novell bought USL and started to develop plans which involved the integration of Tuxedo with Novell's Directory System and AppWare application development tools. These plans never worked out. In September 1994, Novell released version 5 of Tuxedo. Enhancements to the product included support for DCE, extra platform support, a runtime trace feature, dynamic data-dependent routing and the 'domain' feature - used by systems administrators to configure Tuxedo servers into autonomous groups. However, in February 1996, BEA Systems assumed all development, sales and support responsibilities for Tuxedo'. BEA was a start-up company specifically set up to acquire and develop middleware technology in the transaction processing area. Novell retained the right to develop the technology on NetWare platforms. BEA acquired the rights to develop the technology on all other platforms. Despite the somewhat confusing language of the announcement, BEA has effective control of Tuxedo, the technology and its future development. It has obtained an exclusive 'licence' to the technology in perpetuity. The entire Tuxedo development, page 14 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues support and sales team - in effect the entire Tuxedo business unit - transferred to BEA which now has about 100 to 150 developers working on Tuxedo, including many of the developers from AT&T and Bell Labs. Release 6.1 was released in June 1996 and added the event broker, an administration API and ACLs. 1997 BEA Systems made a revenue of $ 61.6 Mio. May 1998, BEA Systems announced to buy the competing TP Monitor TOP END from NCR. 4.1.3 Architecture Figure 8. Tuxedo architecture The Tuxedo architecture includes the following components: Core System provides the critical distributed application services: naming, message routing, load balancing, configuration management, transactional management, and security. The Workstation component off-loads processing to desktop systems. This allows applications to have remote clients, without requiring that the entire BEA TUXEDO infrastructure reside on every machine. Queue Services component provides a messaging framework for building distributed business workflow applications. Domains allow the configuration of servers into administratively autonomous groups called domains. DCE Integration is a set of utilities and libraries that allows integration between The Open Group’s DCE. BEA CICx an emulator of the CICS transaction processing product which runs on Unix. BEA Connect are connectivity gateways to other TP environments (via SNA LU6.2 and OSI-TP protocol) BEA Builder covers tools that assist in the development and testing of Tuxedobased applications. BEA Manager is the administration component BEA Jolt for Web integration 1999 EURESCOM Participants in Project P817-PF page 15 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Figure 9. Tuxedo 3-tier architecture Special features include: 4.1.4 Event Brokering System which implements an event system based on the publish-and-subscribe programming paradigm. This allows for the notification of events on a subscription basis. Security is offered for both 40-bit and 128-bit Link Level Encryption add-on products to provide security for data on the network. It also supports servicelevel Access Control Lists (ACLs) for events, queues, and services. Cobol Support. A COBOL version of ATMI is provided. Service Directory. The Bulletin Board, located on every server node participating in an application, serves as the naming service for application objects, providing location transparency in the distributed environment. It also serves as the runtime repository of application statistics. Internationalization. In compliance with The Open Group’s XPG standards, users can easily translate applications into the languages of their choice. Languages can also be mixed and matched within a single application. Web Integration BEA Jolt enables Java programs to make Tuxedo service requests from Java-enabled Web browsers across the Internet (or intranets). The aim of Jolt is to get round the restrictions of normal Internet communication. Jolt consists of a collection of Java classes. It also replaces HTTP with its own enhanced Jolt Transaction Protocol. page 16 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Figure 10. Jolt architecture 4.1.5 4.1.6 When to use You are developing object-based applications. Tuxedo works with non-object based applications, but it is especially suited to object based ones. In fact, you cannot implement object-based applications involving transactions without under-pinning them with a distributed TP Monitor like Tuxedo. (ORBs without TP underpinning are not secure.) You have a large number of proprietary and other platforms which you need to integrate. You use Oracle, DB2/6000, Microsoft SQL Server, Gresham ISAMXA, Informix DBMSs or MQSeries, and you need to build transaction processing systems that update all these DBMSs/resource managers concurrently. You want to integrate Internet/intranet based applications with in-house applications for commercial transactions. Future plans There are plans to enhance Tuxedo in the following key areas: Java, internet integration – see newest release of Jolt 1.1: HTML client support via BEA Jolt Web Application Services and JavaBeans support for BEA Jolt client development via JoltBeans Exploiting the Object Technology by creating an object interface to ATMI for Java (BEA Jolt), COM, CORBA and C++ - the CORBA, COM and C++ interfaces are available using M3, Desktop Broker and BEA Builder for TUXEDO Active Expert EJB Builder, a graphical tool for building Enterprise JavaBeans (EJBs) applications. Exploiting the Object Technology by creating an object interface to ATMI for Java (BEA Jolt), COM, CORBA and C++ The Iceberg project (release date June 1998) includes an updated version of BEA Tuxedo; a revised version of BEA ObjectBroker, formerly called Digital's CORBA ORB; and an integrated pairing of the two. This will integrate ORBS into Tuxedo. 1999 EURESCOM Participants in Project P817-PF page 17 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 additional security features like with link level encryption, end-to-end encryption, digital signatures and built-in support for off-the-shelf security systems such as RSA - TUXEDO 6.4 provides most of these features. More support is also planned for multi-threading and more automated load balancing. tighter integration with CICS the BEA Manager will be supported on Windows NT and a browser-based administration tool will be released. Figure 11. Tuxedo future plans 4.1.7 Pricing Tuxedo costs about $ 5000 per development seat. The charges for runtimes are about $ 550 for concurrent use of a Tuxedo runtime and $ 125 for non-concurrent use per user per Tuxedo runtime. Jolt is sold on a per-server basis and its cost is related to the number of users that can access any server. The minimum likely charge is about $ 3500. 4.2 IBM's TXSeries (Transarc's Encina) 4.2.1 Summary Key points Based on DCE, X/Open, Corba II and JavaBeans standards Runs on AIX, HP-UX, SunOS, Solaris, Digital Unix, Windows 3, Windows NT. Third party versions from Hitachi (HI-UX), Stratus (FTX) and Bull (DPX). Twophase commit access to MVS CICS through DPL and access to IMS through Encina client on MVS Supports TCP/IP and LU6.2 via integrated Peer-to-Peer gateway page 18 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Strengths Adds considerable value to DCE Extensive, well developed product set Excellent service offering with well defined, helpful consultancy and technical support Encina++ provides distributed object support Weaknesses 4.2.2 TXSeries supports only a small subset of the platforms DCE supports Third-party tool support is poor and the TXSeries interface is not easy to understand - the choices can be bewildering to a novice user Limited automatic failover features (no automatic redirection of requests to new server instances or new nodes). History Transarc has its roots in pioneering research into distributed databases, distributed file systems and support for transaction-based processing, which was undertaken at Carnegie Mellon university in the early 1980s. Shortly after Transarc was founded in 1989, Hewlett-Packard, IBM, Transarc, Digital and Siemens met under the auspices of the OSF to create the architecture that was to become DCE. Transarc played a major role in providing the vision behind DCE. Transarc's AFS became the DFS component of DCE and was released as the first commercial version in 1994. Encina in its first product version was released in 1992. Transarc's close links with IBM resulted in an agreement with it that Encina should form the foundation for CICS on other platforms besides MVS. A joint team was formed to build CICS over Encina services, initially on AIX. About 60% of the code bases of Encina and Encina for CICS is common, but there are, in effect, two products for two markets (this is further explored in the CICS part). IBM recently bought Transarc and bundled the two products Encina 2.5 and CICS 4.0 into a new product called IBM TXSeries 4.2. Also included in the product package; MQSeries, Domino Go Web Server and DCE servers and Gateways. 4.2.3 Architecture TXSeries is a distributed transaction processing monitor, based on the XA standard and including support for both transactions and nested transactions. It supports twophase commit across: heterogeneous DBMSs, file systems and message queuing systems (such as IBM MQSeries) supporting the XA standard the queues (RQS) and record oriented file system (SFS) provided by TXSeries. any LU6.2-based mainframe application(in the case of CICS this is full 2-phase 2-way transactional support through DPL (Distributed Program Link) which is a higher level call interface than LU6.2). 1999 EURESCOM Participants in Project P817-PF page 19 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 TXSeries provides synchronous and asynchronous support for client-server based applications. It supports synchronous processing using remote procedure calls and asynchronous processing using either its recoverable queuing service (RQS)or IBM MQSeries, which is included in the TXSeries server package TXSeries is layered over DCE. The developer can access DCE services and TXSeries has been built to take advantage of them. Services such as time, security, threads support and directory are all provided by DCE. Figure 12. TXSeries architecture The Encina Monitor The Encina Monitor is the core component of TXSeries and consists of run-time and development libraries. It provides programmers with tools and high level APIs with which to develop applications, as well as run-time services such as load balancing, scheduling and fault tolerance services. The Encina Monitor comes with a GUI-based management and administration tool, called Enconsole, which is used to manage all resources in the DCE network (Encina servers, clients and DCE resources such as cells) from a central point. The Monitor also acts as the central co-ordination agent for all the services. For example, it contains processing agents that receive and handle client requests, multithread services and multi-thread processes. Further modules are: Encina Toolkit is built from several modules including the logging service, recovery service, locking service, volume service and TRAN - the two-phase commit engine. Recoverable queuing service (RQS) provides a message queue for message storage. Encina structured file server (SFS) is Transarc's own record-oriented file handling system Peer-to-peer communication (PPC) executive is a programming interface that provides support for peer-to-peer communication between TXSeries-based applications and either applications on the IBM MVS mainframe or other Unix applications, using the CPI-C (common program interface communication) and CPI-RR (common program interface resource recovery) interface. Peer-to-peer communication (PPC) gateway provides a context bridge between TCP/IP and SNA networks allowing LU6.2 'sync level syncpoint (synclevel2)' communication. DE-Light is a light-weight implementation of TXSeries which consists of three components: - the c client component, which runs on Windows page 20 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues - the JavaBeans component which runs on any JDK 1.1-enabled browser - the gateway, which runs on Solaris, AIX and HP-UX. Figure 13. TXSeries interfaces 4.2.4 Web Integration For DE-Light exists a DE-Light Web client that enables any Web browser supporting Java to access TXSeries and DCE services. DE-Light Web client does not need DCE or TXSeries on the client. It is implemented as a set of Java classes, which are downloaded automatically from the Web server each time the browser accesses the Web page referencing the client. DE-Light Web also has minimal requirements for RAM and disk. Figure 14. TXSeries Web Integration 4.2.5 When to use You are already using or will be happy to use Your programmers are familiar with C, C++ or Corba OTS You use Oracle, DB2/6000, MS SQL Server, Sybase, CA-Ingres, Informix, ISAM-XA, MQSeries and/or any LU6.2-based mainframe transaction and you 1999 EURESCOM Participants in Project P817-PF page 21 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 need to build transaction processing systems that update or inter-operate with all these 4.2.6 DBMSs/resource managers concurrently. You need to build applications that enable users to perform transactions or access files over the Internet - all Transarc's Web products are well thought out and useful. Future plans Future development plans include: 4.2.7 Integration with Tivoli's TME, the systems management software from IBM's subsidiary Integration with Lotus Notes (available as sample code today) Enhancement of the DE-Light product (Full JavaBeans client support is currently available There are plans to provide an Enterprise JavaBeans environment later this year, which will be integrated with TXSeries in the future TXSeries currently provides Corba 2.0 OTS and OCCS services. These work with IONA’s ORB today and there are plans to support other ORBS - such as IBM’s Component Broker in the near future. Available since 4Q97, IBM provides direct TXSeries links to IMS, which will enable IMS transactions to become part of a transaction controlled using twophase commit and specified using TxRPC Transarc will provide tools for automatic generation of COM objects from the TXSeries IDL in our next release. Today, integration with tools like Power Builder, Delphi, etc is achieved through calls to DLL libraries. Support for broadcast and multi-cast communication. Pricing Product Price TXSeries Server $ 3,600 TXSeries Registered User $ TXSeries Unlimited Use (mid-tier) $ 16,500 4.3 IBM's CICS 4.3.1 Summary 80 Key Points Supports NetBIOS (CICS clients only), TCP/IP (except the ESA, AS/400 and VSE platforms) and SNA (all platforms) page 22 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues CICS servers run on AIX, HP-UX, Solaris, Digital Unix, Sinix, OS/2, Windows NT, ESA, MVS, VSE and OS/400 CICS clients run on AIX, OS/2, DOS, Apple Macintosh, Windows 3, Windows 95 and Windows NT Strengths Development environment (API, tools, languages supported) and communication options for programmer well developed Context bridging and message routing support provided to bridge SNA and TCP/IP environments Worldwide IBM support, training and consultancy available Weaknesses 4.3.2 Directory services are weak and likely to need high administrator input to set up and maintain Central cross-platform administration of the environment is weak Underlying security services are not provided in a uniform way across all the environments and lack encryption facilities History Over the years IBM has produced three transaction monitors - CICS (Customer Information Control System), IMS (Information Management System) and TPF (Transaction Processing Facility), but CICS has become the dominant one. During the 1960s IBM set up a team of six people at IBM Des Plaines to develop a common software architecture on the System 360 operation system what became CICS. The product was initially announced as Public Utility Customer Information Control System (PUCICS) in 1968. It was re-announced the following year at the time of full availability as CICS. In 1970, the CICS team moved to Palo Alto, California. In 1974, CICS product development was moved to IBM's Hursley Laboratory in the UK. During the late 1970s and early 1980s, support for distributed processing was added to CICS. The main functions added were: transaction routing, function shipping and distributed transaction processing. Support for the co-ordination of other resource managers as part of a CICS transaction was introduced in the late 1970s. The first version on Unix to be released was CICS/6000, based on Encina from Transarc and DCE. Only parts of the Encina product and DCE were used: IBM estimates that between 40% and 50% of the resulting code base is new code, the remainder being Encina and DCE. The Windows NT version of CICS was originally based on the OS/2 code base, but is currently being transferred to the Encina code base. The CICS development is now placed at IBM's Global Network Division. 4.3.3 Architecture CICS comprises a CICS core, application servers and listener services. The listener services handle the communications links on the network, apply any security 1999 EURESCOM Participants in Project P817-PF page 23 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 and collect buffers received from the network software, breaking the buffers down into their components. Each instance of CICS has a schedule queue: a shared memory queue, invisible to the programs but used within CICS to handle the scheduling of requests. As requests are received by the listeners, they place the requests on the schedule queue. CICS does not have a 'transmission queue' on the sending end to store requests. One CICS instance on a machine (there can be more than one CICS instance on mainframes) can handle the messages or requests destined for all the programs, CICS files, or CICS transient data queues which are using that CICS instance. Thus, the scheduling queue will contain the request and message from multiple programs and destined for multiple programs, files or queues. The CICS instance can also contain one or more application servers. These components handle the dequeuing of messages and requests from the scheduling queue and the transfer of these messages to the appropriate program, file or queue. An application server is not 'allocated' to a specific application program, file system or transient queue. Each application server simply takes whatever happens to be the next message on the schedule queue and then processes it. In essence, the scheduling queue is organised in first-in-first-out order. CICS supports prioritisation of messages on the ESA machine, but this is only used to despatch messages, not to process them when a message is received. Once the application server has taken the message off the queue, it will load the program where necessary and then wait until the program has completed its activity, the action has been completed by the file system or the message has been placed on the transient queue. Once the program has finished processing, the application server will clean up any data in memory and then go back to see if there are any messages on the schedule queue for it to process. Once there are more messages/requests on the schedule queue than a specified limit (normally ten), new application servers are spawned automatically. When there are fewer messages than the limit, application servers are automatically taken out of service. Further components include: directory service CICS file system (a record-based file-handling system) temporary storage (memory-based or disk-based queue) transient data (sequential files outside the file control functional area, which can be shared between transactions/tasks) memory-based semaphore (CICS-controlled area of memory, which acts like a semaphore - not under transaction control) shared temporary storage. page 24 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Figure 15. CICS architecture Special features include: 4.3.4 New Java functionality. CICS transaction capability from any Java-enabled browser. Integration with Lotus Domino and the Internet. Web integration IBM has two products to integrate CICS with the Web. CICS Internet Gateway A recently released component enables CICS applications to be accessed via the Web. The user uses a normal Web browser to access the Web server; the CICS Internet Gateway is then used to interface between CICS client applications and the Web server. The CICS client can be AIX or OS/2. CICS/Java Gateway The CICS/Java Gateway enables Java applets to be automatically downloaded from a Web server via a Web page. As shown in Figure 4, the CICS ECI Applet then connects directly to a CICS/Java Gateway, while the CICS ECI Applet works on the client machine within the Java Virtual machine. CICS/Java Gateway uses the secure sockets connection to transmit data and ECI calls. The CICS/Java Gateway can run on OS/2, Windows NT and AIX. 1999 EURESCOM Participants in Project P817-PF page 25 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Figure 16. CICS Web Integration 4.3.5 4.3.6 When to use You are already a big user of CICS and intend to be, in the future, a user of predominantly IBM machines and operating systems. Note that if you intend to use non-IBM operating systems you must be prepared to use DCE. You are attracted by IBM's service and support network. You are prepared to dedicate staff to performing all the administrative tasks needed to ensure CICS is set up correctly and performs well across the company. You do not need an enterprise-wide, self-administering solution supporting a large range of different vendors' machines. Future plans CICS Systems Manager IBM wants to harmonise all the different versions of the CICS Systems Manager so that there is one unified interface, preferably GUI-based. All administration should be done from a central remote console. CICS Java-based applet Due early in 1997, the CICS External Call Interface is used to enable a Java applet to access CICS servers through Web browsers. Read-only access is provided to systems over TCP/IP and SNA networks. By late 1997, a Java interface should be available on CICS servers, enabling developers to write client-server, CICS-based Java applications. Support for data format translation IBM is thinking of providing support for self-describing message data and for messages which are more than 32Kb long. This will enable more flexible support for messages and will allow the format of those messages to be translated. IBM is considering the use of a type of data definition language to describe the message content. It could thus borrow both the ideas and technology available in distributed databases and use them to do the conversion. page 26 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Support for dynamic load balancing CICS only supports load balancing on the ESA and AIX platforms. IBM would like to extend this facility to all the platforms and add to the support so that tasks could be automatically created. Better security support IBM is planning support for encryption and for more unified security methods such as Secure Sockets. It is also investigating the use of DCE's GSSAPI. 4.3.7 Pricing IBM packages its products into what are termed 'transaction servers'. These servers are part of a range of server components, including database server and communications server. Therefore no separate prices could be state. 4.4 Microsoft Transaction Server MTS 4.4.1 Summary Key Points MTS is Windows NT-only. MTS extends the application server capabilities of NT and uses features of NT for security and robustness . Synchronous communication support via DCOM, DCE RPC and asynchronous store and forward features of MSMQ. Support of SQL Server 6.5 and 7, and ORACLE 7.3 via ODBC-interfaces. Strengths Adding transactions and shared data to COM-Objects. Easy integration of DCOM on the client side. Simple COM-API (only three methods: GetObjectContext, SetComplete and SetAbort). Easy administration. The GUI-drag and drop management console is tightly integrated into the Microsoft Management Console (MMC). It is cheap. There is no additional software cost because it is bundled with the NT Server 5.0. Weaknesses 4.4.2 Limited support of the standard XA resource interface. Poor transaction recovery. Poor cross-platform support for diverse networks and existing systems. History A few years ago, Microsoft hired some of the best and brightest minds in transaction processing, including Jim Gray, who literally wrote the book on it, and set them to 1999 EURESCOM Participants in Project P817-PF page 27 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 work on a next-generation TP monitor. The result was Microsoft Transaction Server (MTS). Version 1.0 was released in January 1997. MTS is an ActiveX-based component coordinator. It managed a pool of ODBC connections and COM-Object connections that clients could draw from. MTS focuses on transactions for COM objects and supports developers with an easy manageable tool, thereby lowering the barrier for developers to use a transaction monitor. It was targeted toward Visual Basic applications running as ActiveX components under IIS (Internet Information Server). In December 1997 Microsoft released a Windows NT Option pack which includes MTS 2.0. It enhances support to the Message Queue Server (MSMQ), transactional Active Server Pages (ASP) for IIS and support for ORACLE 7.3. MTS 2.0 was integrated fully into NT Server 5.0. It is positioned against JavaBeans and CORBA by "naturally" enhancing the DCOM model with transactions. 4.4.3 Architecture MTS consists of the following components: MTS Explorer is the management console to create and manage packages, configure component properties such as security and transaction behavior, and monitor/manage operating servers. MTS Explorer can run as a snap-in to the Microsoft Management Console (MMC). Resource dispensers create and manage a reusable pool of resource connections automatically. Automatic Object Instance Management extends the COM object model with just-in-time activation where components only consume server resources while they are actually executing. Shared Property Manager is a special-purpose resource dispenser that enables multiple components to access the same data concurrently. Distributed Transaction Coordinator (DTC) is responsible for the transaction management (2-phase-commit, etc.). Microsoft Message Queue Server (MSMQ) provides a transaction sensible message queue. SNA Server 4.0 Integration via COM-based interfaces to mainframe applications. page 28 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Figure 17. MTS architecture The client side of MTS is totally integrated into Windows 95. Therefore no special MTS client is necessary. 4.4.4 Web Integration MTS 2.0 is tightly integrated with IIS 4.0. This allows to mark Active Server Pages (ASPs) as transactional, using the same transaction settings that system administrators assign in the MTS Explorer. IIS can run in its entirety within an MTS-managed process, or individual ASP applications can run in separate processes. 4.4.5 4.4.6 When to use You are building an multi-tier (especially internet) application based on Microsoft Backend Server Suites. Your system architecture is built upon the DCOM architecture. Your developers have good Visual Basic, VisualJ++ and NT knowledge. You are building a complex business application which stays in the Microsoft world only. Future plans Not known. 4.4.7 Pricing MTS 2.0 is included as a feature of the Microsoft Windows NT Server. There is no additional charge. 1999 EURESCOM Participants in Project P817-PF page 29 (120) Volume 3: Annex 2 - Data manipulation and management issues 4.5 NCR TOP END 4.5.1 Summary Deliverable 1 Key Points Oracle, Informix, Sybase, Teradata, CA-Ingres, Gresham's ISAM-XA, MS SQL Server, DB2/6000 and MQSeries are supported via XA Supports many flavours of Unix including AIX, HP-UX, Sun Solaris and NCR SvR4. IBM support for MVS, AS/400 and TPF is provided via gateways or remote server. Client-only support is provided for OS/2, MS-DOS and Windows. Remote server support is also provided for Windows 95 and OS/2 Supports TCP/IP and OSI TLI. Support is provided for LU6.2 via gateway Strengths Excellent directory services, with a labor saving architecture and good administrative support tools, all suited to large scale, enterprise-wide deployment Highly developed automatic load balancing and restart/recovery facilities, again providing a labor saving administrative environment and likely to guarantee high availability and performance NCR has found a way to circumvent the current limited support for XA by using its own 'veneers' Weaknesses 4.5.2 Some key platforms are not supported (for example, Digital's OpenVMS), or are only supported via remote clients and/or remote servers Limited support for guaranteed delivery History In the early 1970s when NCR first started to ship mainframe computers, its staff in countries such as the UK and Switzerland decided that the machines needed to be supported by a mainframe class TP Monitor that worked across the range of machines and therefore NCR developed a TP Monitor called TranPro, which it provided for all its proprietary systems. TranPro evolved to become MultiTran, a TP Monitor that could support the NCR 9800 and clustered environments with added functionality such as failover. When the NCR 3000 range was launched in 1990 and NCR decided to move away from its proprietary operating systems to Unix, it realised that MultiTran would need to be adapted and re-developed to support not only the Unix operating system, but large networks of distributed computers. MultiTran was consequently re-developed to support distributed environments and parallel architectures and the resulting product was renamed Top End. It was released in late 1991. At that time developments were affected by AT&T's ownership of the competing Tuxedo product. Despite the rivalry between Tuxedo and Top End, development and enhancement of Top End continued. Once AT&T sold USL to Novell in 1993, however, a notable increase in the pace of Top End development took place. page 30 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Top End on Windows NT (release 2.03.01) was available at the beginning of 1996. 1996 AT&T's allowed NCR to be an independent public company. May 1998, BEA Systems, owner of the competing product Tuxedo, announced that it would buy TOP END from NCR. 4.5.3 Architecture Top End consists of the following components: Top End Base Server software runs on every server node in the network where there are Top End clients connected or where there are Top End applications. Top End Base Server software is also required on any node that is being used to connect to IBM hosts, or to drive the SNA open gateway. Security services are an optional component that can be added to the Base Server software Top End Client software is needed on any client machine running an application that issues Top End transaction requests. It also includes software that can handle PC and 3270 terminal screen support Top End connections provide connectivity to mainframe and other server platforms. Node Manager is a collection of processes that run on each server and provide the core middleware services such as message routing and queuing, transaction management, security checking, runtime administrative services, as well as exception logging, alert and failure recovery. Network Interfaces provide communication services between node managers. Remote Client Services extends client application services and APIs to remote networked workstations. Remote Server Services extend server application services and APIs to remote networked workstations and various server platforms. Network Agents extend all application services to the Remote Client Services and the Remote Server Services platforms. Login Clients use a library of terminal support routines and TOP END screen formats to facilitate communications between a character-mode terminal (client) and a TOP END application program (service). Tools for developing and configuring applications, and managing the enterprise. Administration tools are used to perform component start-up and shutdown, manage auditing and recovery, activate communication links, monitor application alerts, and other distributed services. 1999 EURESCOM Participants in Project P817-PF page 31 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Figure 18. TOP END architecture Special features include: 4.5.4 Automatic Recovery from application failures, transaction failures, network failures, and node failures. Components are monitored by the system monitor. When an component fails, the system monitor notifies the node manager and restarts the failed process. Data-warehousing. NCR is a leading provider of large-scale Data-warehousing solutions with its Teradata database software. TOP END's transaction monitor brings OLTP transaction scalability to this Data-warehouse. Web Integration Java remote client is aimed at organisations wanting to support commercial transactions on the Internet using the Web. The Internet and its protocols are normally unable to recognise the state of a transaction, which makes the multi-step, often complex interactions that take place within a transaction largely impossible to support. Java remote client solves this problem by combining the distributed transaction processing capabilities of Top End with software that can sustain transaction interactions over the Web using browsers. Although Web browsers and servers can be used directly with Top End, NCR believes that the combination of the Java remote client with the Web browser is a more robust and high performance solution for transaction processing and other applications. Java remote client is written in the Java language and is supplied as a Java applet. The Enterprise ActiveX controls (TEC) are currently available. page 32 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Figure 19. TOP END web-integration 4.5.5 4.5.6 When to use You need a strategic, high performance, high availability middleware product that combines support for synchronous and asynchronous processing with message queuing, to enable you to support your entire enterprise. You use TCP/IP, Unix (AIX, HP-UX, Solaris, Dynix, Sinix, IRIX, NCR SvR4, U6000 SvR4, Olivetti SvR4, SCO UnixWare, Digital Unix, Pyramid DC/OSx), Windows (NT, 95 or 3), OS/2, MVS, AS/400 or TPF. You need distributed transaction processing support for Oracle, Informix, Sybase, Teradata, CA-Ingres, Gresham's ISAM-XA, Microsoft SQL Server or DB2/6000. Your programmers use C, Cobol or C++, Oracle Developer/2000, NatStar, Natural, PowerBuilder, Informix 4GL, SuperNova, Visual Basic, Visual C++ (or any other ActiveX compliant tool), Java and Web browsers. Future plans Enhancements include: Remote clients - support will be provided for message compression and encryption from remote clients. Top End development environment - support will be provided for Enterprise ActiveX controls Security - enhancements will be added within the Windows NT environment to match those in the Unix environment Interactive systems definition - this type of support will be added for XR, MSR, YCOTS and BYNET. More 'data warehouse enablers' Support for very large systems, with the focus on scalability and availability. 1999 EURESCOM Participants in Project P817-PF page 33 (120) Volume 3: Annex 2 - Data manipulation and management issues 4.5.7 Deliverable 1 Support of an enterprise component model for ”plug-and-play” application development with CORBA and Java Beans. A key development here is the TOP END Enterprise Java Beans Server (EJB). Pricing NCR has a tiered pricing model. Machines are split into groups based on their theoretical relative processing power. All machines within a category (whatever make and operating system) are then priced the same. Pricing ranges from $ 2,700 to $ 150,000. 4.6 Itautec's Grip 4.6.1 Summary Key Points Grip can control transactions which access local Btrieve 5 & 6 (Windows NT and NetWare), Oracle (Windows NT and NetWare), SQL Server (Windows NT), Faircom (Windows NT), and Sybase version 10 (NetWare and Windows NT) databases. Grip clients run on Windows 3.11 and MS-DOS version 3, NetWare, Windows 95 and Windows NT (Servers or Workstations). Grip Servers can run under Windows NT, NetWare 3 & 4, NetWare SFT III or SCO Unix. Access is available to IBM hosts (MVS or AS/400) via SNA LU6.2 and a gateway Grip supports IPX/SPX, TCP/IP, X.25 and SNA LU6.2 Strengths Simple, easy-to-use API and development environment Easy-to-understand architecture and configuration Provides a design geared towards fast transaction throughput Weaknesses 4.6.2 No dynamic directory facilities Support restricted to a small number of key platforms No support of the standard XA resource interface. Limited support services outside South America and Portugal History Grip was designed by Itautec Informatica, Brazil's largest IT company, to handle the 10 million transactions per day processed by the country's second-largest private bank, Itau. The development of Grip was driven largely by the nature of Brazilian politics, coupled with the state of Brazil's economy in the 1980s. At that time Brazil had protectionist policies, with self-imposed restrictions which largely prevented the use of external technology. Its economy, however, was in severe trouble, with inflation page 34 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues exceeding 30% per month. Tremendous pressures were placed on Brazil's banking systems to support the need to put cash immediately into electronic form, in order to help to protect it from inflation (via interest rates) and move it around the banking system quickly and reliably. Work started on Grip in 1982. Grip technology was sold during the late 1980s and early 1990s as part of a package of banking and other commercial solutions developed by Itautec. In 1993, Itautec decided to decouple what became Grip from these packaged solutions. 4.6.3 Architecture Grip has two main components: a Grip Server component and a Grip Client component. Grip Server Most of the modules on the server can be multi-threaded. Grip Start-up module and tables provides a configuration file which contains tables and parameters used on start-up. Application manager manages the application execution, including handling routines, statistics information and database transaction control. Functions Time scheduler controls and activates all the time scheduled transactions. Message manager (two managers: Grora and Groea) manage all the incoming and outgoing messages. Server queue which are invisible to the programmer and only used internally. Communications modules allow messages to be sent across a network, while hiding the underlying network protocols. Figure 20. Grip Server architecture Grip Client 1999 EURESCOM Participants in Project P817-PF page 35 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 The client is intended to be a complete environment for both running and creating client applications on Windows. The Grip Client components include a GUI screen generator, Microsoft VBXs, OCXs and Microsoft foundation. The communication modules on the client provide a programming interface which can be used to open and close sessions and to send and receive messages. Figure 21. Grip client architecture 4.6.4 Web Integration No support for the Internet. 4.6.5 4.6.6 When to use You need a DTPM which is capable of supporting a cost-effective, stand-alone or locally distributed application, which may exchange data with a central mainframe. You want to develop these applications on Windows NT or NetWare servers. Your hardware and network configurations are relatively stable. The DBMSs you intend to use are Oracle, Sybase, SQL Server, Btrieve or Faircom. Future plans The plans that Itautec has for Grip cover three areas: Integration of Grip for Windows NT with the Windows NT event viewer, performance monitor, NT login process and security system. This enhancement is 'imminent' Integration of Grip on NetWare with Novell's NDS (NetWare Directory Services). Integration of Windows NT with Exchange so that messages can be received by and sent to users. page 36 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 4.6.7 Volume 3: Annex 2 - Data manipulation and management issues Pricing Prices range from $ 4,000 to $ 31,000. A typical customer can expect to spend an additional 10-25% on interfaces, for example, to Sybase, TCP/IP and NetWare (NetWare for SAA), depending on the configuration of the system. 5 Analysis and recommendations 5.1 Analysis The Standish Group recommends the use of TP Monitors for any client/server application that has more than 100 clients, processes more than five TPC-C type transactions per minute, uses three or more physical servers and/or uses two or more databases. TP Monitor are forcing the building of robust 3-tier applications. The internet is making 3-tier client/server applications ubiquitous and therefore creates a huge demand of this kind of middleware technology. As component-based middleware becomes dominant, support of transactional objects becomes a must for robust applications. This will clearly govern the future development of TP Monitors. These next-generation monitors which span transaction control over components and objects are so-called Object Transaction Monitors (OTMs). 5.2 Recommendations The most mature products are Tuxedo, Encina, TOP END and CICS. Grip and MTS lack some features and standards support. If you are looking for enterprise-wide capacity, consider Top End and Tuxedo. If your project is medium sized, consider Encina as well. If you look for a product to support a vast number of different platforms then Tuxedo may be the product to choose. If DCE is already used as underlying middleware then Encina should be considered. MTS and Grip are low-cost solutions. If cost is not an issue then consider Tuxedo, TOP END and Encina. Internet integration is best for MTS, Encina, Tuxedo and TOP END. Regarding support of objects or components MTS is clearly leading the field with a tight integration of transaction concepts into the COM component model. Tuxedo and Encina will support the competing CORBA object model from the OMG. There seems to be a consolidation on the market for TP Monitors. On the one hand Microsoft has discovered the TP Monitor market and will certainly gain a big portion of the NT server market. On the other side the former TP Monitor competitors are merging which leaves only IBM (CICS and Encina) and BEA Sytems (Tuxedo and TOP END) as the old ones. The future will heavily depend on the market decision about object and component models such as DCOM, CORBA and JavaBeans and the easy access to integrated development tools. 1999 EURESCOM Participants in Project P817-PF page 37 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 References [1] Bea Systems, www.beasys.com; www.beasys.com/action/tpc.htm [2] Edwards, Jeri; DeVoe, Deborah, "3-tier client/server at work", John Wiley & Sons, Inc., 1997 [3] Frey, Anthony, "Four DTP Monitors Build Enterprise App Services", Network Computing Online, techweb.cmp.com/nc/820/820r1.html [4] Gray, Jim, "Where is Transaction Processing Headed?", OTM Spectrum Reports, May 1993 [5] Gray, Jim; Andreas Reuter, "Transaction Techniques", Morgan Kaufmann, 1993 [6] IBM, www.ibm.com [7] Itautec Philco SA - Software Products Division, www.itautec.com.br [8] Microsoft, Transaction Server -- Transactional Component Services, December 1997, www.microsoft.com/com/mts/revguide.htm [9] NCR Corporation, www.ncr.com Processing Concepts and [10] Open Group, www.opengroup.org [11] Ovum Publications, www.ovum.com, "Distributed TP Monitors", February 1997 [12] Transaction Processing Performance Council, www.tpc.com [13] Transarc Corporation, www.transarc.com page 38 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Part 2 Retrieval and Manipulation 1 Introduction 1.1 General architecture of distributed Databases A distributed database is a collection of databases distributed over different nodes in a communication network. Each node may represent different branches of an organisation with partly anutonomous processes. Each site participates at least at one global application, which may be responsible for the exchange of data between the different branches or for synchronising the different participating database systems (Figure 1). Branch 2 DBMS Branch 1 DBMS Communication Network Branch 3 DBMS Figure 1: DBMS distributed in a communication network To apply distributed databases in organisations with decentralised branches of responsibility may naturally match most of the required functionality of a decentralised information management system. The organisational and economic motivation are probably the most important reason for developing distributed databases [2]. The integration of pre-existing databases in a decentralised communication environment is probably less costly, than the creation of a completely new centralised database. Another reason for developing distributed databases is the easy extensibility of the whole system. 1.1.1 Components of a distributed DBMS A distributed database management system supports the creation and maintenance of distributed databases. Additionally to centralised DBMS distributed DBMS contain additional components which extend their capabilities by supporting communication and cooperation between several instances of DBMS’s which are installed on 1999 EURESCOM Participants in Project P817-PF page 39 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 different sites of a computer network (Figure 2 ). The software components which are typically necessary for building a distributed database are according [2]: DB: Database Management Component DC: Data Communication Component DD: Data Dictionary DDB: Distributed Database Component Local Database 1 DB DC DDB DD Site 1 Site 2 Local Database 2 DB DC DDB DD Figure 2 Components of a distributed DBMS The components DB, DC and DD are representing the database management system of a conventional non distributed database. But the data dictionary (DD) has to be extended to represent information about the distribution of data in the network. The distributed database component (DDB) provides one of the most important features, the remote database access for application programs. Some of the features supported by the above types of components are: Remote database access Some degree of distribution transparency; there is a strong trade-off between distribution transparency and performance Support for database administration and control: this feature includes tools for monitoring, gathering information about database utilisation etc. Some support of concurrency control and recovery of distributed transaction One important aspect in a distributed DBMS-Environment is the degree of heterogeneity of the involved DBMS. Heterogeneity can be considered at different levels in a distributed database: hardware, operating system and the type of local DBMS. As DB software vendors are offering their products for different hardware/operation systems, heterogeneity problems of these types have usually not to be considered, these levels heterogeneity are managed by the communication software. The development of distributed DBMS without pre-existing local DBMS, the design may be performed top-down. In this case it is possible to implement a harmonised page 40 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues data model for all involved sites, this type of development implements a homogeneous distributed DBMS: In case of pre-existing local databases, one type of heterogeneity has to be considered in building a distributed DBMS: the required translation between the different data models used in the different local databases. This translation realises a global view of the data in a heterogeneous distributed DBMS. 1.1.2 Distributed versus Centralised databases Distributed databases are not simply distributed implementations of centralised databases [2]. The main features expected by Centralised DB have to be implemented offering different features in the case of distributed DBMS: Centralised Control The idea of Centralised Control which is one of the most important features in centralised DB has to be replaced by a hierarchical control structure based on a global database administrator, who is responsible for the whole database and local database administrators who have the responsibility for the local databases. The so called site autonomy may be realised in different degrees of autonomy: from complete site autonomy without any database administrator to almost completely centralised control. Data independence Data independence guarantees to the application programmer that the actual organisation is transparent to the applications. Programs are unaffected by changes in the physical organisation of the data. In a distributed DB environment data independence has the same importance, but an additional aspect has to be considered: distribution transparency. Distribution transparency means that programs can be written as if the databases were not distributed. Moving data from one site to another does not affect the DB applications. The distribution transparency is realised by additional levels of DB schemata. Reduction of redundancy opposite to the decision rules in traditional databases, data redundancy in distributed databases are a desirable feature: the accessibility to data may be increased if the data is replicated at the sites where the applications are needing them. Additionally the availability of the system is increased; in case of site failures application may work on replicated data of other sites. But similar to the traditional environment the identification of the optimal degree of redundancy requires several evaluation techniques. As a general statement, replication of data items improves the ratio of retrieval accesses, but the consistent update of replicated data reduces the ratio of update accesses. 1.2 General architecture of federated Databases In [3] different definitions for distributing data and applications on database systems are identified (see Figure 3). 1999 EURESCOM Participants in Project P817-PF page 41 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 A centralised DBS consists of a single centralised database management system (DBMS), which manages a single database on the same computer system. A distributed DBS consists of a single distributed database management system (DBMS) managing multiple databases. The databases may differ in hardware and software, may be located on a single or multiple computer system and connected by a communication infrastructure. A multidatabase system (MDBS) supports operation on multiple DBS, where each component DBS is managed by a ”component database management system (DBMS)”. The degree of autonomy of the component DBS within a MDBS identifies two classes of MDBS: the nonfederated database system and the federated database system. In the nonfederated database system, the component DBMS are not autonomous. For instance a nonfederated DBS does not distinguish local and nonlocal users. The component DBS in a federated database system participate at the federation as autonomous components managing their own data, but allowing controlled sharing of their data between the component DBS. FDBMS Component DBS 1 Component DBMS 1 a centralised DBMS Component DBS 1 Component DBS n Component DBS 2 Component DBMS 2 a distributed DBMS Component DBS 2-1 others Component DBS 2-2 Figure 3: Components of a DBS according [3] The cooperation between the component DBS allow different degrees of integration, a FDBS represents a compromise between no integration (users must explicitly interface with multiple autonomous databases) and total integration (users may access data through a single global interface, but cannot directly access a DBMS as a local user). 1.2.1 Constructing Federated Databases In general there are different interests in distributed databases. Some of these are (1-3): (1) The opportunity to implement new architectures, which are distributed according to their conceptual nature. This is often the case for client / server systems. (2) The opportunity to make distributed implementations of conceptual non distributed systems to achieve efficiency. For instance it might be desirable to implement advanced query searching in a conceptually large entity (table) by distributing the table among many computers, and let each computer do the query search on parts of the entity. (3) There may be situations, where data are available on page 42 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues a distributed system by nature. But where it is more desirable to consider these data as non distributed. For instance this might be the case, when two companies (or two divisions in one company) wish to join forces and hence data. In such a case the companies may choose to design a federated database to be able to share data. A federated database is also called a multidatabase. The term ”federated” is used in the research world - the term ”multidatabase” is used in commercial products. A federated database arise by considering a set of databases as one (federated) database. The databases might very well exist on different computers in a distributed system. As an example we can think of a fictitious commercial telephone company comprised of two more or less independent divisions. Let us assume, that one division is responsible for providing the customer with mobile telephone services, and the other division is responsible for providing the necessary network for static desk telephones communication. It is then very likely, that each of these divisions has its own system to handle customer orders and billing (billing system). That is, at the end of the month each customer receives two bills: One bill covering the customers expenses for using the mobile telephone (printed by the first divisions billing system) and another bill covering the expenses for using the static telephone (printed by the second divisions billing system). But it might be more desirable both from the company and the customers point of view, that the customer only receives one bill each month both covering the mobile and static telephone expenses. If the company decides to implement this, the company might choose to implement a whole new billing system integrated in the two divisions. However this solution might be very difficult. One reason is, that customer billing directly or indirectly must be based on customer bill reporting (CDR) from the networks implementing the telephone services. Most likely the networks implementing the mobile and static telephone services have different topologies and internal communication protocols. (The mobile network might be an extension of the static network.) So the CDR formats are different from one network to the other. Assuming that each division uses a database (for instance comprised of a set of tables / entities) to keep track of CDR collections, the two databases (one for each division) will likewise represent heterogeneous information. For instance this means, that the entities (tables) uses by the two databases have different entity formats (record structures). The implementer of the new billing system therefore have two choices (1-2): (1) Restructure the telephone service networks to unify the CDRs and merge them into one database instead of the existing two databases. (2) Base the new billing system on the existing databases. Restructuring (1) the networks is probably impossible and undesirable. A new billing system must therefore more or less be based on the existing databases (2). In practical terms: The job for the new billing system is to make the information in the existent databases look uniform on the customer bill. The billing system might do this by implementing a new view of the databases as a federated database. In the rest of this section we will deal with some of the aspects of implementing federated database systems. To some extent we will also discuss how to express queries in such systems and how to implement query searching. A federated database will probably be implemented using concepts and techniques known in the world of distributed systems. So in the following we assume, that the federated databases under discourse will be implemented on a some kind of distributed database system. We assume we are equipped with techniques to access the databases on the different computers in the system. We further assume, that we have query techniques available conforming to the power of SQL of some variant. We use the word ”entity” to 1999 EURESCOM Participants in Project P817-PF page 43 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 identify the basic elements in a database. So we more or less expect, that we are in the relational world of databases. 1.2.2 Implementing federated database systems To some extent the concept of federated database in a distributed system conforms to the concept view for instance defined in SQL and provided by many DBMS’s. Logically a view is a function from a set of entities to an entity. Likewise a federated database is logically a function from a set of databases to a database. On the other hand a DBMS itself is not expected to support functional mapping directly suitable for federated purposes. But since a database is a set of entities (in the relational case), the use of views might be an important tool to implement a federated database. As an example we continue the discussion of the above two databases defined by the divisions in the telephone company above. For simplification we now further assume, that each database is comprised of just one entity (table with no relation / record ordering and no multiple instances of the same relation), and these entities are instances of the same schema (contains the same attributes). In all we deal with two entities A and B. The entities A and B keep customer accounts for the two company divisions respectively. (Let us say A for the division dealing with the mobile phones and vice versa.) For each customer in each division a relation (record) in the entity specifies the name of the customer and the amount of money to be specified on the next monthly bill. (This amount increases as the customer uses the telephone.) It might look like this: Entity A Entity B Name Account Name Account Peterson 100 Peterson 100 Hanson 50 Hanson 50 Larson 200 Larson 200 From the federated perspective we are really just interested in the customers and the accounts. When we print the bills, it is not important whether the customers are using a mobile phone or a static phone as long as they pay. So the federated database should just be comprised of one logic table made as some sort of concatenation of the accounts represented by A and B. We could consider using the view U defined as the union of A and B as the first step for this purpose. Apart from some problems with Hansons account (to be discussed below) U represents all accounts in A and B. Using for instance SQL it is easy to express, that we want the sum of all accounts, presented as the entity (view) F0. Except for the problem with Hanson, F0 will do as our federated database. page 44 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues FO: Federated database - first attempt! U: Union of A and B Name Account Name Peterson 100 Peterson 175 Hanson 50 Hanson 50 Larson 200 Larson 200 Jonson 200 Jonson 200 Peterson Account 75 But since we are in the (strict) relational world, U has lost too much information. The reason is, that Hanson has used the same amount on the mobile and static telephone, and Hanson therefore is represented by identical relations (records) in A and B. Since a relation is represented with exactly one or zero instances in the (strict) relational model, only one of Hansons accounts is registered in U. So in U we have lost the necessary information about one of Hansons accounts. We assume, that it will be possible to solve the problems with Hansons account on any DBMS. But the point here is, that the facilities provided by a particular DBMS not necessarily are suitable for the needs of constructing a federated database. It could be argued that the problems above are due to bad database design. But the problem with federated databases as such is, that the databases forming the basis for the federated database not are designed for the purpose. Therefore different attempts are made to meet the special problems met, when designing federated databases. An example is the Tuple-Source (TS) model described in [11]. The TS model can be thought of as an extension of the traditional relational model. We will not try to explain this model in detail. But in the following we will try to give some idea of how this model can solve the problem above. Above we used the union operator to define the view U. The TS-model provides us with an alternative ”union” view operator, let us call it TS-union (this operator is not explicitly named as such in [11]). The TS-union operator makes it possible to concatenate entities, which are instances of the same schema (like entities A and B) without loss of information as in the case of U. Using the TS-union on A and B yields the entity showed below (W). W: TS-union on A and B Name Account DB Peterson 100 DB_A Hanson 50 DB_A Larson 200 DB_A Hanson 50 DB_B Jonson 200 DB_B Peterson 75 DB_B 1999 EURESCOM Participants in Project P817-PF page 45 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 The TS-union makes sure, that each instances of the same relation appearing in both A and B is replicated as two distinct relations in W. This is assured by providing W with an extra attribute, identifying the originating database - either A (DB-A) or B (DB-B). From W it is now easy to generate the sum of the accounts belonging to each client (identified by the Name attribute) using TS-SQL (the query language provided with the TS-model - a variant of SQL). The sum of all the accounts is presented as the entity below (F) - which make up our federated database. F: The federated database - as we want it - summing Hanson accounts correctly! Name Account Peterson 175 Hanson 100 Larson 200 Jonson 200 When designing a federated database, we sometimes need to consider a set of databases (the basis) as one as above. For the same federated database, we might at other times need to consider the basis it is made of - a set of distinct databases. TS-SQL contains SQL extended instructions, which make it convenient to deal with both cases. Regarding the TS-model it should finally be noted, that the extensions do not violate the fundamental important properties of the traditional model. This for instance means that a system implementing the TS-model can make use of query optimization techniques used in traditional relational systems. 1.2.3 Data Warehouse Used To Implement Federated System Above we ended up defining our federated database as an entity (view) called F. To define F we used an intermediate entity (view) called W defined from two other entities A and B. We did say define - not generate. The fact the F and W are defined with A and B as basis, do not necessary mean that each relation in F and W are represented physically by the DBMS. It might be feasible just to keep a symbolic logical definition in the DBMS - also in the case where the entities grow to represent any higher number of relations. For instance the size of W might just be on the order of 50 bytes / octets, independent of the number of entities in W. To see why, let us look at a yet another view. Let us define the view H as comprised of ”All accounts regarding Peterson in the union of A and B”. Again this might seem, as we first need the union of A and B (in a physical though small representation) as a first step to generate a representation of H. But possibly the DBMS (which is relational) will choose internaly to rephrase the definition of H (which will have a formal representation in the DBMS), using properties of the relational algebra. Probably the DBMS can find out that H equally is defined as ”the union of Peterson accounts in A and Peterson accounts in B”. Since there is a small number of Peterson accounts in both A and B the latter expression of H might be much more efficient to calculate, than brute force calculation the first definition of H. Although it may seem, that a federated database can be implemented mostly using properties of relational algebra on the databases making up the basis, it might anyway be necessary to generate physic representations of the federated database (like F above) or physic representations of views used to define the federated database (like W above). Let us for instance say, that we actually need frequent access to the data page 46 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues warehouse F above, defining the amount of money each customer owes the telephone company. We might want to give the customers online access to their own account in F, so they can keep track of their growing bill. But for instance it might be, that it is not possible to get access to A and B in the day times. A reason for this could be, that the local DBMS’s collecting CDR information in A and B just are too busy doing that in the day time. So since A and B are not available in the daytimes, we have to generate a physic representation of F in the night time, where the local DMBS’s managing A and B can find spare time to send a copy of A and B over the network to the local DBMS administrating F. In this case the federated database F is implemented as a data warehouse. We now say, that F is a data warehouse because we made explicit, that F is having a physical representation independent of the physical representations of the data sources A and B. [11] Gives further references to attempts made to help the design of federated databases. 1.2.4 Query Processing in Federated Databases Query processing on a federated database meets the problems of distributed database systems in general. Above we described the TS-model. This model is implemented on a distributed DBMS also described in [11]. Regarding query processing we almost literally quote from [11]: The distributed query processor consists of a query mediator and a number of query agents, one for each local database. The query mediator is responsible for decomposing global queries given by multidatabase applications into multiple subqueries to be evaluated by the query agents. It also assembles the subquery results returned by the query agents and further processes the assembled results in order to compute the final query result. Query agents transform subqueries into local queries that can be directly processed by the local database systems. The local query results are properly formatted before they are forwarded to the query mediator. By dividing the query processing tasks between query mediator and query agents, concurrent processing of subqueries on local databases is possible, reducing the query response time. This architectural design further enables the query mediator to focus on global query processing and optimization, while the query agents handle the transformation of subqueries decomposed by query mediator into local queries. Note that the query decomposition performed by query mediator assumes all local database schemas are compatible with the global schema. It is a job for the query agents to convert the subqueries into local queries on heterogeneous local schemas. The heterogeneous query interfaces of local database systems are also hidden from the query mediator by the query agents. 1.2.5 Conclusion: Federated Databases A federated database is conceptually just a mapping of a set of databases. When the word federated is used, it indicates that the federated database is a mapping of a set of databases not originally designed for a mutual purpose. This gives rise to special problems. Above we have tried to indicate some of these. Though we have not discussed the situations, where it is desirable to perform changes (conceptually) directly in the federated database. 1999 EURESCOM Participants in Project P817-PF page 47 (120) Volume 3: Annex 2 - Data manipulation and management issues 2 Organisation of distributed data 2.1 Schema integration in Federated Databases Deliverable 1 Following the definitions in [3] a Five Level Schema is identified to support the general requirements of a FDBMS: distribution, heterogeneity and autonomy (Figure 4). Externel Schema Externel Schema Federated Schema Federated Schema Export Schema Externel Schema Export Schema Export Schema Component Schema Component Schema Local Schema Local Schema Component DBS Component DBS Figure 4 Five-level schema architecture of a FDBMS [3] The Local Schema is the conceptual schema of a component database. The Local Schema is expressed in the native data model of the component DBMS, different Local Schemas may be expressed in different data models. The Component Schema builds a single representation of the divergent local schemas. Semantic that are missing in a local schema can be added in its component schema. The Component Schema homogenises the local schema in a canonical data model. The Export Schema filters the data available to the federation, it represents a subset of the component schema. The purpose of defining Export Schemas is to facilitate control and management of association autonomy. Using filtering processor may limit the set of operations that can be submitted to a corresponding Component Schema. The Federated Schema is an integration of multiple Export Schemas. It also includes information about data distribution, represented by the integrated Export Schemas. There may be multiple Federated Schemas in an FDBMS, one for each class of federation users. A class of federation users is a group of users and/or applications performing a related set of activities (e.g. corporate environment: managers and employees). The External Schema defines a schema for a user and/or application or a class of user/applications. As a Federated Schema may be large, complex, and difficult to manage, the External Schema can be used to specify a subset of information relevant page 48 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues to the users of the External Schema (customisation). Additionally integrity constraints may be specified in the External Schema and access control provided for the component databases. Based on this schema model and an introduced reference architecture, different design methodology of distributed/federated databases are discussed in [3]. 2.2 Data Placement in Distributed Databases The design of a distributed database is an optimisation problem requiring solutions to several interrelated problems e.g.: Data fragmentation Data allocation and replication Partitioning and local optimisation A optimal solution will reduce delay by communication costs and additionally enable parallel managing of the distributed data. The main keywords in this field are: Data Declustering, Data Partitioning. A general description of data placement and the applied technology may be found in [8]. Global Schema Site independent schema Fragmentation Schema Allocation Schema Local Schema Local Schema DBMS site 1 DBMS site 2 DB (other sites ) DB Figure 5: reference architecture for distributed databases 1999 EURESCOM Participants in Project P817-PF page 49 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Figure 5 shows a reference architecture for distributed databases according [2]. There are several levels of schemas introduced which reflect the different views to the distributed DB environment. At the top level is the global schema which defines all the data as if the database were not distributed. Each global relation may be split into several (nonoverlapping) fragments (Fragmentation schema). Fragmentation may be done one to many: i.e. several fragments may correspond to one global relation, but only one global relation corresponds to one fragment. The allocation schema defines at which site a fragment is located. The local mapping schema maps the physical images of the global relations to the objects of the local DBMS. This concepts describes the following features in general [2]: Fragmentation Transparecy provides, that user of application programmer are working on global relations Location Transparency is a lower degree of transparency: applications are working on fragements and not on global relations Local Mapping Transparency Independence from local DBMS: this feature, guarantees that the local representation of data is hidden to the global applications The different levels of transparency offer various options for optimising the design of distributed DBMS. 2.2.1 Data Fragmentation Data fragmentation is done in several ways: vertical, horizontal and mixed. Horizontal fragmentation consists of partitioning tuples of global relations into subsets. This type of partitioning is useful in distributed databases, where each subset can contain data which have common geographical properties. Vertical partitioning takes attributes of a relation and groups them together into non overlapping fragments. The fragments are then allocated in a distributed database system to increase the performance of the system. The objective of vertical partitioning is to minimise the cost of accessing data items during transaction processing. [6] and [9]gives an survey about techniques in vertical partitioning, but see too the remarks in[8]. 2.2.2 Criteria for the distribution of fragments Two aspects are the key influencing the distribution of data in a distributed DBS, efficiency of access high availability The efficiency of access is influenced by transmission time of requests and the response time of the involved nodes. The distribution of data near the places they are needed reduces the overall transmission time, the smart distribution of workload reduces the response time. High availability is realised in redundant distribution of data among several nodes. The failure of one or more nodes will keep the system running. In case of failures the page 50 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues redundant distribution of data may improve the performance of the whole system even if some nodes are failing (graceful degradation). 3 Parallel processing of retrieval 3.1 Query Processing The steps to be executed for query processing are in general: parsing a request in an internal form, validating the query against meta-data informations (schemas or catalogs), expanding the query using different internal views and finally building an optimised execution plan to retrieve the requested data objects. In a distributed system the query execution plans have to be optimised in a way that query operations may be executed in parallel, avoiding costly shipping of dataSeveral forms of parallelism may be implemented: Inter-query-parallelism allows the execution of multiple queries concurrently on a database management system. Another form of parallelism is based of the fragmentation of queries (sets of database queries, e.g. selection, join, intersection, collecting) and on parallel execution of these fragment pipelining the results between the processes [8]. Inter-query-parallelism may be used in two forms, either to execute producer and consumers of intermediate results in pipelines (vertical inter-operator parallelism) or to execute independent subtrees in a complex query execution plan concurrently (horizontal inter-operator parallelism[7]). A detailed description of technologies applied for query evaluation may be found in [7]. 3.2 Query optimisation The main parts involved in query processing in a database are the query execution engine and the query optimiser. The query execution engine implements a set of physical operators which takes as input one or more data streams and produces an output data stream. Examples for physical operators are ”sort”, ”sequential scan”, ”index scan”, ”nested loop join”, and ”sort merge join”. The query optimiser is responsible for generating the input for the execution engine. It takes a parsed representation of a SQL query as input and is responsible for generating an efficient execution plan for the given SQL query from the space of possible execution plans. The query optimiser has to resolve a difficult search problem in a possibly vast search space. To solve this problem it is necessary to provide: A space of plans (search space) A cost estimation techique so that a cost may be assigned to each plan in the search space An enumeration algorithm that can search through the execution space A desirable optimiser is one where (1) the search space includes plans that have low cost, (2) the costing technique is accurate (2) the enumeration algorithm is efficient. Each of these tasks is nontrivial. 1999 EURESCOM Participants in Project P817-PF page 51 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 In [5] an overview is given of the state of the art in query optimisation. 4 Parallel processing of transactions 4.1 Characteristics of transaction management The transaction processing management in a distributed environment is responsible to keep the consistency of data in a distributed system, to guarantee the efficiently execution of competing transactions and to be able to handle error conditions. The main properties of a transaction are the ACID-Properties [1]: 4.2 Atomicity within a transaction, every or none of the needed operations will be done. The interruption of a transaction will initiate a recovery condition which reestablishes the former state conditions. Consistency A transaction is a correct transformation of the state. The action taken as a group do not violate any of the integrity constraints associated with the state. Isolation Even though transactions execute concurrently, it appears to each transaction T, that others executed either before T or after T, but not both Durability Once a transaction completes successfully, it changes to the state survive failures. Distributed Transaction The Two-Phase commit protocol is used primarily to coordinate work of independent resource managers within a transaction (from [1]). It deals with integrity checks that have been deferred until the transaction is complete (phase 1) and with work that has been deferred until the transaction has finally committed (phase 2). In a distributed system each node in a cluster has it own transaction manager. In case that transactions are accessing objects on different nodes, the transactions are known to several transaction managers. The two-phase commit protocol is used to make the commit of such distributed transactions atomic and durable, and to allow each transaction manager the option to unilaterally aborting any transactions that are not yet prepared to commit. The protocol is fairly simple. The transaction manager that began the transaction is called the root transaction manager. As work flows from one node to another, the transaction managers in the transaction form a tree with the root transaction manager at the root of the tree. Any member of the transaction can abort the transaction, but only the root can perform the commit. It represents the commit coordinator. The coordinator polls the participants at phase 1; if any vote no or fail to respond within the timeout period, the coordinator rejects the commit and broadcasts the abort decision. Otherwise, the coordinator writes the commit record and broadcasts the commit decision to all the other transaction managers. page 52 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues 5 Commercial products 5.1 Tandem NonStop Clusters software combines a standards-based, version of SCO UnixWare 2.1.2 with Tandem’s unique single system image (SSI) clustering software technology. SSI simplifies system administration tasks with a consistent, intuitive view of the cluster. This helps migrating current UNIX system applications to a clustered environment. It also allows transparent online maintenance such as hot plugin of disks, facilitates the addition of more nodes to the cluster, and provides automatic failover and recovery. [12] 5.1.1 Designed for scalability With NonStop Clusters software, servers within the cluster are highly scalable and can be scaled as needed without incurring significant downtime. Through the use of NonStop Clusters software, each node can contain a different number of processors of different speeds, memory capacities, and internal disk storage capacities. Other features, such as shared devices and memory, enhance scalability. Depending upon the applications structure, there is nearly one-to-one performance scaling. In addition, NonStop Clusters software supports industry-standard middleware to facilitate cluster growth. 5.1.2 High degree of manageability The SSI approach to cluster management is designed to avoid the need for special cluster considerations. With the SSI, you manage a single resource, not a collection of systems. 5.1.3 Automatic process migration and load balancing NonStop Clusters software lets you migrate applications, operating system objects, and processes between cluster nodes. Migrating into default or predefined operating areas balances the load between nodes. Migration can be automatic, and the load can be balanced with other tasks or through a failover to specific node groups. Any node can be selected for failover. Automatic process migration and load balancing are available during normal operation or after application restart or failover. This promotes efficient cluster operation without the need for a dedicated standby node. 5.1.4 High level of application and system availability NonStop Clusters software promotes a high level of availability throughout the enterprise. It runs on industry-standard servers, the reliable Integrity XC series, which consists of packaged Compaq ProLiant servers. The clustering operation provides a replicated operating system, which continues membership services as if hardware were replicated. Availability is also enhanced by the Tandem ServerNet® faulttolerant system area network (SAN) technology. NonStop Clusters software runs on the Integrity XC seriesfrom Compaq. CPU performance on the Integrity XC series is tied to Intel processor architecture evolution and enhancements and extensions to Compaq’s ProLiant server line. 1999 EURESCOM Participants in Project P817-PF page 53 (120) Volume 3: Annex 2 - Data manipulation and management issues 5.2 Oracle 5.2.1 Oracle8 Deliverable 1 Oracle8 is a data server from Oracle. Oracle8 is based on a object-relational model. In this model it is possible to create a table with a column whose datatype is another table. That is, tables can be nested within other tables as values in a column. The Oracle server stores nested table data "out of line" from the rows of the parent table, using a store table which is associated with the nested table column. The parent row contains a unique set identifier value associated with a nested table instance [14]. Oracle products run on Microsoft Windows 3.x/95/NT, Novell NetWare, Solaris, HPUX and Digital UNIX platforms. Many operational and management issues must be considered in designing a very large database under Oracle8 or migrating from an Oracle7 (the major predecessor of Oracle8) database. If the database is not designed properly, the customer will not be able to take full advantage of Oracle8’s new features. This section discusses issues related to designing a VLDB under Oracle8 or migrating from an Oracle7 database [17]. 5.2.1.1 Partitioning Strategies – Divide And Conquer One of the core features of Oracle8 is the ability to physically partition a table and its associated indexes. By partitioning tables and indexes into smaller components while maintaining the table as a single database entity, the management and maintenance of data in the table becomes more flexible. The data management now can be accomplished at the finer-grained, partition level, while queries still can be performed at the table level. For example, applications do not need to be modified to run against the newly partitioned tables. The divide-and-conquer principle allows data to be manipulated at the partition level, reducing the amount of data per operation. In most cases, this standard also allows partition-level operations to be performed in parallel with the same operations on other partitions of the same table, speeding up the entire operation. 5.2.1.2 Benefits From Table Partitioning The greatest benefits from Oracle8 partitioning is the ability to maintain and administer very large databases. The following dimensions of scalability can be found in Oracle8 compared to Oracle7: 5.2.1.3 Higher Availability Greater Manageability Enhanced Performance Higher Availability Using intelligent partitioning strategies, Oracle8 can help meet the increasing availability demands of VLDBs. Oracle8 reduces the amount and duration of scheduled downtime by providing the ability to perform downtime operations when the database is still open and in use. Refer to the paper, Optimal Use of Oracle8 page 54 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Partitions, for further information about this topic. The key to higher availability is partition autonomy, the ability to design partitions to be independent entities within the table. For example, any operation performed on partition X should not impact operations on a partition Y in the same table. 5.2.1.4 Greater Manageability Managing a database consists of moving data in and out, backing up, restoring and rearranging data due to fragmentation or performance bottlenecks. As data volumes increase, the job of data management becomes more difficult. Oracle8 supports table growth while placing data management at a finer-grain, partition level. In Oracle7, the unit of data management was the table, while in Oracle8 it is the partition. As the table grows in Oracle8, the partition need not also grow; instead the number of partitions increases. All of the data management functions in Oracle7 still exist in Oracle8. But with the ability to act against a partition, a new medium for parallel processing within a table now is available. Similar rules apply to designing a database for high availability. The key is data-segment size and to a lesser degree, autonomy. 5.2.1.5 Enhanced Performance The strategy for enhanced performance is divide-and-conquer through parallelism. This paradigm inherently results in performance improvements because most operations performed at the table level in Oracle7, now can be achieved at the partition level in Oracle8. However, if a database is not designed correctly under Oracle8, the level of achievable parallelism and resulting performance gains will be limited. The table partitioning strategy used in Oracle7 may not necessarily be adequate to make optimal use of the Oracle8 features and functionality. 5.2.2 A Family of Products with Oracle8 Oracle offers a set of products and tools to aid in the development and management of complex computer systems and applications. This section focuses on how specific products are integrated with and take advantage of the new features of Oracle8 [13]. The Oracle products described in this section are built around NCA (Network Computing Architecture). NCA provides a cross-platform, standards-based environment for developing and deploying network-centric applications. NCA aids integration of Web servers, database servers, and application servers. To address these challenges, all Oracle products are embracing NCA, from the core Oracle8 database to Oracle's comprehensive development tools and packaged enterprise applications. A key strength of Oracle’s product offering is the breadth of tools available for working with the Oracle database. Database application development requires tools to build, design, and manage the applications. In addition, Oracle is working with many third-party partners to ensure that their products fully leverage and exploit the new capabilities provided with Oracle8. Oracle offers a set of tools targeted to build and deploy both applications for a potentially large network of computers and applications for a single computer. The tools are designed to let developers focus on solving business problems instead of programming application infrastructure. 1999 EURESCOM Participants in Project P817-PF page 55 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 The suite of products make it possible to: Provide a management system for all servers in the enterprise. Application development using component creation and assembly tools. Mining of data from data warehouses with OLAP (Online Analytical Processing) and decision support tools. Deploy Web applications. The rest of this section is a more detailed description of the capabilities of some of the products and tools All of these products are integrated with the Oracle8 system. The focus is on how these specific products take advantage of the new features of Oracle8 [16]. 5.2.2.1 SQL*Plus SQL*Plus, the primary ad-hoc access tool to the Oracle8 server, provides an environment for querying, defining, and controlling data. SQL*Plus delivers a full implementation of Oracle SQL and PL/SQL (see below), along with a set of extensions. SQL*Plus provides a flexible interface to Oracle8, enabling developers to manipulate Oracle SQL commands and PL/SQL blocks. With SQL*Plus it is possible to create ad hoc queries, retrieve and format data, and manage the database. For maximum administrative flexibility, you can work directly with Oracle8 to perform a variety of database maintenance tasks. You can view or manipulate database objects, even copy data between databases. The new Oracle8 features can be implemented through SQL*Plus 8.0.3. Use of New Oracle8 features, such as creating and maintaining partitioned objects, using parallel Data Manipulation Language (DML) commands, creating index organized tables and reverse key indexes, deferred constraint checking and enhanced character set support for National Language Support can be implemented with SQL*Plus. SQL*Plus also supports the new password management capability of Oracle8. In addition, SQL*Plus 8.0.3 fully supports the object capability of Oracle8, as well as its very large database support features. New object types can be defined, including collection types and REF (reference) attributes. SQL*Plus supports the SQL syntax for creating object tables using the newly defined object types, as well as all the new DML syntax to access the object tables. Object type methods are written in PL/SQL from the SQL*Plus tool, along with object views and instead of triggers. All the storage handling syntax is supported from SQL*Plus, in addition to handling all aspects of LOB (Large Object) manipulation and storage management. PL/SQL is Oracle’s procedural extension to SQL. PL/SQL’s extension to industrystandard SQL, is a block-structured programming language that offers application developers the ability to combine procedural logic with SQL to satisfy complex database application requirements. PL/SQL provides application developers benefits including seamless SQL access, tight integration with the Oracle RDBMS and tools, portability, security, and internationalization [15]. page 56 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 5.2.2.2 Volume 3: Annex 2 - Data manipulation and management issues Oracle8 Enterprise Manager Oracle8 Enterprise Manager (OEM) is Oracle's framework for managing the Oracle environment. Enterprise Manager consists of a centralized console, common services (such as job scheduling and event management), and intelligent agents running on managed nodes. Various applications run on this framework performing comprehensive systems management capabilities. Oracle8 Enterprise Manager 1.4 supports the new scalability features of Oracle8 such as partitioning, queuing, password management, and server managed backup and recovery. Bundled with the Console are a set of database administration tools that help automate and simplify the common tasks in the life of a database administrator (DBA). All the tools provide a graphical user interface, with drag-and-drop functionality and wizards. OEM helps the availability of the data in a recovery situation by enabling the DBA to complete recovery sooner. OEM’s Backup Manager provides a graphical interface to various backup options, such as the new Oracle8 utility, Recovery Manager (RMAN). The Oracle8 Recovery Manager supports secure management of backups by using either a recovery catalog or a control file. The DBA initiates restore and recovery operations very quickly, using a point-and-click interface, allowing the recovery operation to complete that much sooner. Backups can be scheduled to run at off-hours of the day using OEM’s job scheduling capability. In addition, Oracle8 Backup Manager also has support for Oracle7 type database backups. OEM provides graphical user interface (GUI) support for all the password management capabilities of Oracle8. Additionally, OEM supports GUI creation of global users and global roles, greatly simplifying the security administrator’s user management tasks. 5.2.2.3 Designer/2000: Model Once For Multiple Targets Designer/2000 is a business and application modeling tool with the ability to generate complete applications from those models. Business analysts and developers use a visual modeling interface to represent and define business objects, functionality, business rules and requirements in a declarative way. These rules can then be implemented on one or more tier: on the client, application server or database server. Designer/2000 enables the definition of systems independently of their implementation so that applications can be generated in multiple environments and configurations from a single model. Developers can reuse these definitions by dragging and dropping them into new models. From these models, Designer/2000 generates and reverse engineers Oracle database objects, Developer/2000 client/server and Web applications, Oracle Web Application Server applications, Visual Basic applications, Oracle Power Objects applications, and C++ mappings for database objects. Designer/2000 2.0 also provides modeling, generation, and design recovery for all the scalability features of Oracle8, such as partitioned tables, new LOBs (Line-OfBusiness), index organized tables and deferred constraint checking, as well as object features including user defined types, type tables, referenced and embedded types, and 1999 EURESCOM Participants in Project P817-PF page 57 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 object views of relational data. These concepts are represented using an extension of the ULL (United Modeling Language), the emerging open standard for object modeling. The design is then implemented within the Oracle8 Server through automated SQL DDL generation. Existing Oracle8 Server designs can be reverse engineered into the Designer/2000 Release 2.0 repository, including the automated construction of diagrams based on recovered objects and definitions. Additionally, in the definition of client-side applications Designer/2000 uses a concept called a 'module component'. A module component defines what data is accessed (tables and columns), how it appears in a form, and what specialized behavior it has (in addition to that inherited from the tables it includes, e.g. validation rules). A module component can then be included in many forms (or reports, etc.). Any change made in the original component definition will be inherited in every module definition that includes the component. 5.2.2.4 Object Database Designer Object Database Designer is the natural companion for anyone designing and building Oracle8 systems. The product addresses key areas of functionality designed to aid in all aspects of ORDBMS design, creation, and access: type modeling forms the core of an object oriented development, and is used in all stages of analysis and design. Object Database Designer, like Designer/2000, implements type modeling by UML; thereby meeting the needs of both the major developer roles: database designers and application developers. The type model is transformed into an Oracle8 database schema, giving the database designer an excellent head start on the design, and mapping abstract type models onto the world of ORDBMS. The designer can then refine this schema design to exploit Oracle8 implementation options. Then the visual design is automatically translated into the appropriate SQL DDL to implement it. This approach takes the effort out of manually building a database, and guarantees bug-free SQL. Because it is equally important to be able to visualize existing database structures, Object Database Designer supports reverse engineering and full round-trip engineering of model and schema. This database design and generation capability is identical to the corresponding capability in Designer/2000 thus providing DBAs with a single tool-set. However Object Database Designer is specifically designed for developers of Object Oriented 3GL applications of Oracle8. C++ is currently the most widely used object-oriented programming language, as such it is extremely important to provide a mechanism for C++ programs to seamlessly access Oracle8. Using the type model as its base, the C++ generator automatically generates C++ classes that provide transparent database persistency for those objects. This delivers major productivity benefits to C++ programmers, allowing them to concentrate on application functionality rather than database access. C++ Generator also creates a run-time mapping to allow those applications to interact with their persistent store: the Oracle database. This allows the database schema to migrate without unnecessarily affecting the applications. Additionally, by exploiting the power and performance of the Oracle8 client-side cache, the generated code provides a high performance database access. Not only is the interface simplified for the developer, it is also performance tuned. On the client side, Object Database Designer generates a library of class definitions, each of which may have a persistency mapping onto Oracle8 types. The class page 58 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues structure generated is based on the abstract type model, which is UML compliant and hence is capable of modeling and generating multiple inheritance class structures. However, the transformer to Oracle8 schema design only resolves single inheritance trees, which it implements using a number of options (super-type references sub-type, sub-type references super-type, super-type and sub-type union, and single type with type differentiator attribute). The type modeling and generation in Object Database Designer is a streamlined packaging of the equivalent Designer/2000 capability. Object Database Designer is focused specifically at the Oracle8 database designer and C++ Programmer. 5.2.2.5 Developer/2000: Building Enterprise Database Applications Developer/2000 is a high-productivity client/server and Web development tool for building scalable database applications. A typical Developer/2000 application might include integrated forms, reports, and charts, all developed using an intuitive GUI interface and a common programming language, PL/SQL. Developer/2000 applications can be constructed and deployed in two-tier or multi-tier architectures, in a client/server or Web environment. One of the strengths of Developer/2000 lies in its database integration and its inherent ability to support highly complex transactions and large numbers of users. Oracle has carried these strengths through to the Developer/2000 Server, an application server tier that supports the deployment of robust database applications in a network computing environment. The Developer/2000 Server enables any new or previouslycreated Developer/2000 application to be deployed on the Web using Java, and to publish information using industry standard formats, including HTML, PDF, and GIF. Oracle8 Developer/2000 Release 2.0 is fully certified for application development against Oracle8. This release will also enhance the large scale OLTP nature of applications developed with Developer/2000 by support of such functions as Transparent Application Fail-over, password management, and connection pooling. Along with an enhanced user interface to support these newer more complex data structures, Developer/2000 will allow developers to extend the scalability of their applications, and in conjunction with Sedona, provide greater access to the object world. 5.2.2.6 Sedona: Component-Based Development Sedona is a development environment for building component-based applications. It includes a component framework, a repository, and a suite of visual tools that work in concert to simplify and expedite the specification, construction, and evolution of component-based applications. Oracle and SQL*PLUS are registered trademarks and Enabling the Information Age, Oracle8, Network Computing Architecture, PL/SQL, Oracle7, Developer/2000, Designer/2000, Oracle Enterprise Manager, and Oracle Web Application Server are trademarks of Oracle Corporation. 1999 EURESCOM Participants in Project P817-PF page 59 (120) Volume 3: Annex 2 - Data manipulation and management issues 5.3 Informix 5.3.1 Informix Dynamic Server Deliverable 1 Informix Dynamic Server is a database server. A database server is a software package that manages access to one or more databases for one or more client applications. Specifically, Informix Dynamic Server is a multithreaded relational database server that manages data that is stored in rows and columns. It employs a single processor or symmetric multiprocessor (SMP) systems and dynamic scaleable architecture (DSA) to deliver database scalability, manageability and performance. This section deals with Informix Dynamic Server, Version 7.3. This version is provided in a number of configurations. Not all features discussed are provided by all versions. Informix Dynamic Server works on different hardware equipment, of which some is UNIX or Microsoft Windows NT based [18]. 5.3.2 Basic Database Server Architecture The basic Informix database server architecture (DSA) consists of the following three main components: Shared memory Disk Virtual processor These components are described briefly in this section. 5.3.2.1 The Shared-Memory Component Shared memory is an operating-system feature that lets the database server threads and processes share data by sharing access to pools of memory. The database server uses shared memory for the following purposes: To reduce memory use and disk I/O To perform high-speed communication between processes Shared memory lets the database server reduce overall memory uses because the participating processes - in this case, virtual processors - do not need to maintain individual copies of the data that is in shared memory. Shared memory reduces disk I/O because buffers, which are managed as a common pool, are flushed on a database server-wide basis instead of on a per-process basis. Furthermore, a virtual processor can often avoid reading data from disk because the data is already in shared memory as a result of an earlier read operation. The reduction in disk I/O reduces execution time. Shared memory provides the fastest method of interprocess communication because processes read and write messages at the speed of memory transfers. 5.3.2.2 The Disk Component A disk is a collection of one or more units of disk space assigned to the database server. All the data in the databases and all the system information that is necessary to maintain the database server resides within the disk component. page 60 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 5.3.2.3 Volume 3: Annex 2 - Data manipulation and management issues The Virtual Processor Component The central component of Informix DSA is the virtual processor, which is a database server process that the operating system schedules for execution on the CPU. Database server processes are called virtual processors because they function similarly to a CPU in a computer. Just as a CPU runs multiple operating-system processes to service multiple users, a virtual processor runs multiple threads to service multiple client applications. A thread is a task for a virtual processor in the same way that the virtual processor is a task for the CPU. How the database server processes a thread depends on the operating system. Virtual processors are multithreaded processes because they run multiple concurrent threads. 5.3.2.4 Architectural Elements of Informix Dynamic Server 5.3.2.4.1 Scalability Informix Dynamic Server lets you scale resources in relation to the demands that applications place on the database server. Dynamic scalable architecture provides the following performance advantages for both single-processor and multiprocessor platforms: A small number of database server processes can service a large number of client application processes. provides more control over setting priorities and scheduling database tasks than the operating system does. DSA Informix Dynamic Server employs single-processor or symmetric multiprocessor computer systems. In an SMP computer system, multiple central processing units (CPUs) or processors all run a single copy of the operating system, sharing memory and communicating with each other as necessary. 5.3.2.4.2 Raw (Unbuffered) Disk Management Informix Dynamic Server can use both file-system disk space and raw disk space in UNIX and Windows NT environments. When the database server uses raw disk space, it performs its own disk management using raw devices. By storing tables on one or more raw devices instead of in a standard operating-system file system, the database server can manage the physical organization of data and minimize disk I/O. Doing so results in three performance advantages: No restrictions due to operating-system limits on the number of tables that can be accessed concurrently. Optimization of table access by guaranteeing that rows are stored contiguously. Elimination of operating-system I/O overhead by performing direct data transfer between disk and shared memory. If these issues are not a primary concern, you can also configure the database server to use regular operating-system files to store data. In this case, Informix Dynamic Server manages the file contents, but the operating system manages the I/O. 1999 EURESCOM Participants in Project P817-PF page 61 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 5.3.2.4.3 Fragmentation Informix Dynamic Server supports table and index fragmentation over multiple disks. Fragmentation lets you group rows within a table according to a distribution scheme and improve performance on very large databases. The database server stores the rows in separate database spaces (dbspaces) that you specify in a fragmentation strategy. A dbspace is a logical collection of one or more database server chunks. Chunks represent specific regions of disk space. 5.3.2.4.4 Fault Tolerance and High Availability Informix Dynamic Server uses the following logging and recovery mechanisms to protect data integrity and consistency in the event of an operating-system or media failure: Dbspace and logical-log backups of transaction records Fast recovery Mirroring High-availability data replication Point-in-time recovery 5.3.2.4.5 Dbspace and Logical-Log Backups of Transaction Records Informix Dynamic Server lets you back up the data that it manages and also store changes to the database server and data since the backup was performed. The changes are stored in logical-log files. You can create backup tapes and logical-log backup tapes while users are accessing the database server. You can also use on-line archiving to create incremental backups. Incremental backups let you back up only data that has changed since the last backup, which reduces the amount of time that a backup would otherwise require. After a media failure, if critical data was not damaged (and Informix Dynamic Server remains on-line), you can restore only the data that was on the failed media, leaving other data available during the restore. 5.3.2.4.6 Database Server Security Informix Dynamic Server provides the following security features: Database-level security Table-level security Role creation Informix Dynamic Server, Workgroup and Developer Editions, do not support role creation and the CREATE ROLE statement. The databases and tables that the database server manages enforce access based on a set of database and table privileges. 5.3.3 Informix Dynamic Server Features 5.3.3.1 Relational Database Management An Informix RDBMS consists of a database server, a database, and one or more client applications. This chapter discusses the first two components. Informix Dynamic page 62 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Server works with relational databases. A relational database lets you store data so that the data is perceived as a series of rows and columns. This series of rows and columns is called a table, and a group of tables is called a database. (An edition of the database server that is not discussed in this manual works with object relational databases.) SQL statements direct all operations on a database. The client application interacts with you, prepares and formats data, and uses SQL statements to send data requests to the database server. The database server interprets and executes SQL statements to manage the database and return data to the client application. You can use SQL statements to retrieve, insert, update, and delete data from a database. To retrieve data from a database, you perform a query. A query is a SELECT statement that specifies the rows and columns to be retrieved from the database. An Informix RDBMS permits high-speed, short-running queries and transactions on the following types of data: 5.3.3.2 Integer Floating-point number Character string, fixed or variable length Date and time, time interval Numeric and decimal Complex data stored in objects High-Performance Loader The High-Performance Loader (HPL) is an Informix Dynamic Server feature that lets you efficiently load and unload very large quantities of data to or from an Informix database. Use the HPL to exchange data with tapes, data files, and programs and convert data from these sources into a format compatible with an Informix database. The HPL also lets you manipulate and filter the data as you perform load and unload operations. 5.3.3.3 Informix Storage Manager The Informix Storage Manager (ISM) lets you connect an Informix database server to storage devices for backup and restore operations. ISM also manages backup media. ISM has two main components: the ISM server for data backup and recovery, and the ISM administrator program for management and configuration of the ISM server, storage media, and devices. 5.3.3.4 Database Support Informix Dynamic Server supports the following types of databases: ANSI compliant Distributed Distributed on multiple vendor servers Dimensional (data warehouse) 1999 EURESCOM Participants in Project P817-PF page 63 (120) Volume 3: Annex 2 - Data manipulation and management issues 5.3.3.5 Deliverable 1 ANSI-Compliant Databases Informix Dynamic Server supports ANSI-compliant databases. An ANSI-compliant database enforces ANSI requirements, such as implicit transactions and required ownership, that are not enforced in databases that are not ANSI compliant. You must decide whether you want any of the databases to be ANSI compliant before you connect to a database server. ANSI-compliant databases and databases that are not ANSI-compliant differ in a number of areas. 5.3.3.6 Dimensional Databases Informix Dynamic Server supports the concept of data warehousing. This typically involves a dimensional database that contains large stores of historical data. A dimensional database is optimized for data retrieval and analysis. The data is stored as a series of snapshots, in which each record represents data at a specific point in time. A data warehouse integrates and transforms the data that it retrieves before it is loaded into the warehouse. A primary advantage of a data warehouse is that it provides easy access to, and analysis of, vast stores of information. A data-warehousing environment can store data in one of the following forms: 5.3.3.7 Data warehouse Data mart Operational data store Repository Transaction Logging The database server supports buffered logging and lets you switch between buffered and unbuffered logging with the SET LOG statement. Buffered logging holds transactions in memory until the buffer is full, regardless of when the transaction is committed or rolled back. You can also choose to log or not to log data. 5.3.4 Supported Interfaces and Client Products 5.3.4.1 Interfaces 5.3.4.1.1 Informix Enterprise Command Center Informix Enterprise Command Center (IECC) runs on Windows 95 or Windows NT. IECC provides a graphical interface that allows the administrator to configure, connect to, control, and monitor the status of the database server. IECC simplifies the process of database server administration and automates common administrative functions. 5.3.4.1.2 Optical Subsystem The optical storage subsystem supports the storage of TEXT and BYTE data on optical platters known as WORM optical media. It includes a specific set of SQL statements that support the storage and retrieval of data to and from the optical storage subsystem. page 64 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues 5.3.4.1.3 Informix SNMP Subagent Simple Network Management Protocol (SNMP) is a published, open standard for network management. The Informix SNMP subagent lets hardware and software components on networks provide information to network administrators. The administrators use the information to manage and monitor applications, database servers, and systems on networks. 5.3.4.2 Client SDK Products The Informix Client SDK provides several application-programming inter-faces that you can use to develop applications for Informix database servers. These APIs let developers write applications in the language with which they are familiar, such as ESQL, C, C++, and Java. INFORMIX-Connect contains the runtime libraries of the APIs in the Client SDK. 5.3.4.2.1 INFORMIX-ESQL/C INFORMIX-ESQL/C lets programmers embed SQL statements directly into a Cprogram. ESQL/C contains: ESQL/C libraries of C functions, which provide access to the database server ESQL/C header files, which provide definitions for the data structures, constants, and macros useful to the ESQL/C program ESQL, a command that manages the source-code processing to convert a C file that contains SQL statements into an object file 5.3.4.2.2 INFORMIX-GLS The INFORMIX-GLS application-programming interface lets ESQL/C programmers develop internationalized applications with a C-language interface. It accesses GLS locales to obtain culture-specific information. Use INFORMIX-GLS to write or change programs to handle different languages, cultural conventions, and code sets. 5.3.4.2.3 INFORMIX-CLI INFORMIX-CLI is the Informix implementation of the Microsoft Open Database Connectivity (ODBC) standard. INFORMIX-CLI is a Call Level Interface that supports SQL statements with a library of C functions. An application calls these functions to implement ODBC functionality. Use the INFORMIX-CLI application programming interface (API) to access an Informix database and interact with an Informix database server. 5.3.4.3 Online analytical processing MetaCube is a variety of tools for online analytical processing [19]. MetaCube Explorer is a graphical data access tool that enables quick retrieval and analysis of critical business data stored in a large data warehouse. Explorer works with the MetaCube analysis engine to query data warehouses stored in an Informix database. Explorer’s graphical interface displays multiple views of the information retrieved by any query. As a business analyst, you can: [20] retrieve results of complex queries. 1999 EURESCOM Participants in Project P817-PF page 65 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 pivot rows and columns to present data by different categories or groupings; sort report rows and columns alphabetically, numerically, and chronologically. drill down for more detailed information or up for a more summarised report. incorporate calculations into reports that provide comparisons and rankings of business data, thereby facilitating analysis of business data. customize reports to present user-defined views of data. MetaCube for Excel is an add-in for Excel spreadsheet software that enables quick retrieval and analysis of business data stored in a MetaCube data warehouse. MetaCube for Excel works with the MetaCube analysis engine to query a multidimensional data warehouse that resides in an Informix database. Using MetaCube for Excel, you can: [21] Retrieve results of complex queries. Automatically sort, subtotal, and total data retrieved from the data warehouse. Apply powerful analysis calculations to returned data. 5.4 IBM 5.4.1 DB2 Universal Database IBM delivered its first phase of object-relational capabilities with Version 2 of DB2 Common Server in July, 1995. In addition, IBM released several packaged Relational Extenders for text, images, audio, and video. The DB2 Universal Database combines Version 2 of DB2 Common Server, including object-relational features, with the parallel processing capabilities and scalability of DB2 Parallel Edition on symmetric multiprocessing (SMP), massively parallel processing (MPP), and cluster platforms. (See Figure 3.) DB2 Universal Database, for example, will execute queries and UDFs in parallel. After that, IBM will add major enhancements to DB2 Universal Database's object-relational capabilities, including support for abstract data types, row types, reference types, collections, user-defined index structures, and navigational access across objects [22]. The DB2 product family spans AS/400* systems, RISC System/6000* hardware, IBM mainframes, non-IBM machines from Hewlett-Packard* and Sun Microsystems*, and operating systems such as OS/2, Windows (95 & NT)*, AIX, HP-UX*, SINIX*, SCO OpenServer*, and Sun Solaris [24]. 5.4.1.1 Extensibility 5.4.1.1.1 User-defined Types (UDTs) DB2 Common Server v2 supports user-defined data types in the form of distinct types. UDTs are strongly typed and provide encapsulation. The DB2 Relational Extenders (see below) provide predefined abstract data types for text, image, audio, and video. DB2 Universal Database will introduce an OLE object for storing and manipulating OLE objects in the DBMS. An organisation will be able to store personal productivity files centrally, query the contents with predefined UDFs ("find all of the spreadsheets with 'profit' and 'loss' in them"), manage the files as regular relational data (e.g., for backup purposes), and apply integrated content-searching page 66 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues capabilities. In the future, DB2 will add user-defined abstract data types with support for multiple inheritance. 5.4.1.1.2 User-defined Functions (UDFs) DB2 v2 supports scalar UDFs for defining methods such as comparison operators, mathematical expressions, aggregate functions, and casting functions. DB2 Universal Database will add table functions (UDFs that return tables), a very significant enhancement, and parallel execution of UDFs. Functions are resolved based on multiple attributes and can be delivered in binary form (source code is not required), making it attractive for third parties to develop DB2 UDFs. In addition, DB2 supports the notion of a "sourced" function, allowing one to reuse the code of an existing function. UDFs can run in an "unfenced" mode in the same address space as the DB2 server for fast performance, or in a "fenced" mode in a separate address space for security. UDFs can be written in C, Visual Basic, Java, or any language that follows the C calling convention. The ability to write UDFs in SQL is coming. Support for the JDBC API is also available. This provides a set of object methods for Java applications to access relational data. 5.4.1.1.3 New Index Structures Several new index structures for text, images, audio, and video are now available through the DB2 Relational Extenders. Future releases of DB2 will add navigational access via object pointers, indexes on expressions (for example, index on salary + commission), indexes on the attribute of a UDT (e.g., index on language(document) where document is a UDT and language is an attribute of document), and support for user-defined index structures. 5.4.1.1.4 Extensible Optimiser The optimiser plays a critical role in achieving good performance, and IBM has made a significant investment here. DB2's optimiser is now rule-based and has sophisticated query transformation, or query rewrite, capabilities. This is a key foundation for DB2's object-relational extensibility. IBM plans to document the rules interface for the optimiser so that customers and third parties can also extend the scope of the DB2 optimiser. The user can give the DB2 optimiser helpful information about the cost of a UDF, including the number of I/Os per invocation, CPU cost, and whether the function involves any external actions. 5.4.1.2 LOBs And File Links Version 2 of DB2 added LOB (large object) support with three predefined LOB subtypes: BLOBs (binary), CLOBs (character), and DBCLOBs (double-byte character). There can be any number of LOB columns per table. DB2 provides significant flexibility in storing and retrieving LOB data to provide both good performance and data recoverability. For example, the option to preallocate storage for LOBs trades off storage requirements and performance. Locators within LOBs allow DB2 to optimize delivery of the data via piecemeal retrieval of LOB data. In the area of recovery, the option to log or not log LOB data trades off recovery and performance; the ability to recover LOB data without writing changes to the log files optimises both. Reading LOB data into application memory rather than into shared memory avoids excessive manipulation of shared memory. And direct file support 1999 EURESCOM Participants in Project P817-PF page 67 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 means DB2 can write LOBs directly to disk on the client for manipulation by the application. Integration with external file systems via the robust file-links technology described above is in development. External filesystems will be supported for data/index storage and delivery of data, and DB2 will guarantee the integrity of data stored in external files. 5.4.1.3 Integrated Searchable Content All of the object-relational extensions to DB2 are fully supported by SQL, enabling the user to access any and all data in the database in a single SQL statement. Extended functions for searching the content of complex data can be used anywhere a built-in SQL function can be used. This is an important goal for IBM. The company is committed to the SQL3 standard here. 5.4.1.4 Business Rules DB2 v2 already supports SQL3-style triggers, declarative integrity constraints, and stored procedures. DB2 offers significant flexibility in its stored procedures. Stored procedures are written in a 3GL (C, Cobol, Fortran), a 4GL, or Java. This approach provides both portability and programming power, unlike proprietary stored procedure languages. IBM also plans to implement the SQL3 procedural language extensions so that procedures can be written in SQL as well. 5.4.1.5 Predefined Extensibility: DB2 Relational Extenders The DB2 Relational Extenders build on the object-relational infrastructure of DB2. Each extender is a package of predefined UDTs, UDFs, triggers, constraints, and stored procedures that satisfies a specific application domain. With the extenders, the user can store text documents, images, videos, and audio clips in DB2 tables by adding columns of the new data types provided by the extenders. The actual data can be stored inside the table or outside in external files. These new data types also have attributes that describe aspects of their internal structures, such as "language" and "format" for text data. Each extender provides the appropriate functions for creating, updating, deleting, and searching through data stored in its data types. The user can now include these new data types and functions in SQL statements for integrated content searching across all types of data. Here are some highlights of the current extender offerings. All of the extenders will be bundled with DB2 Universal Database. 5.4.1.5.1 DB2 Text Extender The Text Extender supports full-text indexing and linguistic and synonym search functions on text data in 17 languages. Search functions include word and phrase, proximity, wild card, and others plus the ability to rank each retrieved document based on how well it matches the search criteria. Text Extender works with multiple document formats and can be applied to pre-existing character data in the database. 5.4.1.5.2 DB2 Image Extender The Image Extender offers similar capabilities for images stored in multiple formats. Searches can be based on average color, color distribution, and texture within an image. The user can also find images similar to an existing image. Future page 68 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues enhancements include image-within-image support and more sophisticated indexing techniques. 5.4.1.5.3 DB2 Audio Extender The Audio Extender supports a variety of audio file formats, such as WAVE and MIDI, and offers import/export facilities and the ability to playback audio clips on an audio browser. Attributes include number of channels, transfer time, and sampling rate. 5.4.1.5.4 DB2 Video Extender The Video Extender maintains attributes such as frame rate, compression ratio, and number of video tracks for each video clip stored in the database. This extender supports several video file formats-MPEG1, AVI, QuickTime, etc.-and a variety of file-based video servers. In addition to playing video clips, the Video Extender can identify and maintain data about scene changes within a video, enabling the user to find specific shots (all of the frames associated with a particular scene) and a representative frame within the shot. 5.4.1.5.5 Other Extenders IBM also offers an extender for fingerprints with extenders for time series and spatial data in development. The company is also working with third-party vendors to help them incorporate their software products as DB2 extenders. An extender developers kit with wizards for generating and registering user-defined types and functions is coming to make the development effort easier. This is an important component of IBM's strategy. 5.4.2 IBM's Object-Relational Vision and Strategy IBM has made significant contributions to our understanding and use of database management systems and technology over the past three decades. IBM developed both the relational model and SQL, its now-industry-standard query language, in the 1970s. IBM has also long recognized the need for an extensible database server. The company began research in this area over ten years ago with its Starburst project, a third-generation database research project that followed the System R (aprototype relational database) and R* (distributed relational database) projects. Designed to provide an extensible infrastructure for the DBMS, Starburst technology is now a major underpinning for object-relational capabilities in IBM's DB2 family of RDBMS products. IBM has four primary efforts underway in its drive to deliver a state-of-the-art objectrelational data management 5.4.2.1 DB2 Object-Relational Extensions Extending the DB2 server itself is obviously a focal point. To do this, IBM is incorporating Starburst technology into DB2 in phases. Version 2 of DB2 Common Server added the first round of object-relational features, including UDTs, UDFs, large object support, triggers, and enhanced integrity constraints. IBM also replaced the entire query compiler and optimiser with an extensible one. 1999 EURESCOM Participants in Project P817-PF page 69 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 With these building blocks in place, IBM can extend DB2 to "push down" complex business logic as much as possible into the database server. The company has already introduced the DB2 Relational Extenders for text, image, audio, video, and others. Future versions will continue to expand DB2's object-relational capabilities. IBM plans to include object extensions and Relational Extenders in DB2 for OS/390 and DB2 for OS/400 in the future as well. 5.4.2.2 Robust File Links For External File Access We have already discussed file links and support of data stored in external file systems. A major challenge is ensuring the integrity of external data and controlling access to the data even though they are physically stored outside the database. To do this, IBM is developing what it calls "robust file links." These file links will enable SQL to provide a single point of access to data stored in both the DBMS and external files. (See Figure 2.) The goal is to add integrated search capability to existing applications that already use a file API for storage of data, and to give SQL-based applications transparent access to external data. A future release of DB2 will include this file-link capability. A file link is actually a UDT (a file-link type) with a handle that points to an external flat file. The developer uses the UDT when creating any new column that represents data in an external file. In the example in Figure 2, photographs of employees are stored externally and referenced in the "picture" column of the employee table. The picture column is a file-link UDT that points to an external image file. External indexes could also be represented as file-link UDTs. DB2 provides two software components to support file-link types in a particular file system. One is a DB2 file-system API that the DBMS uses to control the external files in a file server. For example, when a new file is "inserted" into the database, the DBMS checks to see if the file exists (that is, the external file has already been created) and then tells the file system, "note that I own this file." The second software component, DB2 File-Link Filter, is a thin layer on the file system that intercepts certain file-system calls to these DBMS-managed external files to ensure that the request meets DBMS security and integrity requirements. When a user submits a query to retrieve the employee picture, the DBMS checks to see if the user has permission to access the image. If yes, the DBMS returns to the application the file name with an authorization token embedded in it. The application then uses the file API to retrieve the image. No changes are required to the existing file API provided by the operating system to support file links. The DBMS also uses the DB2 filesystem API to include external files when backing up the database. File links will provide tight integration of file-system data with the object-relational DBMS, allowing the DBMS to guarantee the integrity of data whether they are stored inside or outside the database. 5.4.2.3 Client Object Support Client Object Support is designed to fulfil many important roles in IBM's objectrelational vision. This component, currently under development, is an extended database front end that enhances object support for the client application. Client Object Support can run anywhere but will most likely reside close to the application for performance reasons. The overall goal is to enable the execution of database page 70 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues extensions wherever appropriate: on the client, on an application server, or in the DBMS. Client Object Support will: Provide a logical view of all data accessible through DB2, through file links, or through DataJoiner (see below) and guarantee transaction consistency. Manage the client cache, automatically moving objects between the database and the client cache as appropriate to satisfy query requests. Client Object Support will have enough optimization intelligence to decide where to run queries and UDFs (both can be executed locally or on the server) depending on the contents of the client cache, and to navigate through objects via pointers. Extend the existing database API to include a native API to the programming language in which the application is written. Thus, a C or C++ application, for example, will be able to navigate pointers among objects on the client side (Client Object Support will automatically create these pointers) and directly invoke UDFs. This also provides a way to map objects in the application program to objects in the database server so relational data can be materialized as native C/C++ objects, Java objects, etc. Client Object Support is the mechanism by which IBM will provide tight integration with object-oriented programming languages. The extensible architecture of Client Object Support will also enable IBM to implement different APIs on top of it. An example would be an API based on object-request-broker (ORB) technology that supports the ORB Interface Definition Language (IDL) and Java objects. 5.4.2.4 DataJoiner For Heterogeneous Access DataJoiner is IBM's solution for heterogeneous data access. It provides transparent read/write access to all IBM RDBMS products plus VSAM, IMS, Oracle, Sybase, Informix, Microsoft SQL Server, and database managers with an ODBC- or X/Opencompliant call-level interface, with others coming. DataJoiner is not just a simple gateway between DB2 and other database managers. It includes the full functionality of the DB2 server, a global optimiser that has considerable knowledge about the various data managers supported, and the ability to handle SQL compensation requirements. Because DataJoiner is built on the DB2 server, it can take advantage of all of DB2's object-relational extensions, including the ability to simulate these capabilities, where possible, in non-DB2 data managers. The next release of DataJoiner will incorporate Version 2 of DB2 Common Server, and thus begin to deliver a SQL3-based, objectrelational API for access to all of its supported data managers. 5.4.3 IBM’s Business Intelligence Software Strategy 5.4.3.1 Business Intelligence Structure The IBM business intelligence structure is an evolution of IBM’s earlier Information Warehouse architecture. The structure consists of the following components: [23] 1999 EURESCOM Participants in Project P817-PF page 71 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 5.4.3.1.1 Business Intelligence Applications These applications are complete business intelligence solution packages tailored for a specific industry and/or application area. These packages use products from other components of the business intelligence structure. 5.4.3.1.2 Decision Support Tools These tools range from basic query and reporting tools to advanced online analytical processing (OLAP) and information mining tools. All these tools support GUI-driven client interfaces. Many can also be used from a Web interface. At present most of these tools are designed to handle structured information managed by a database product, but IBM’s direction here is to add capabilities for handling both complex and unstructured information stored in database and file systems, and also on Web servers. 5.4.3.1.3 Access Enablers These consist of application interfaces and middleware that allow client tools to access and process business information managed by database and file systems. Database middleware servers enable clients to transparently access multiple back-end IBM and non-IBM database servers — this is known as a federated database. Web server middleware allows Web clients to connect to this federated database. 5.4.3.1.4 Data Management These products are used to manage the business information of interest to end users. Included in this product set is IBM’s DB2 relational database family. Business information can also be accessed and maintained by third-party relational database products through the use of IBM’s database middleware products. Web server middleware permits information managed by Web servers to participate in the business intelligence environment. IBM sees up to three levels of information store being used to manage business information. This three-level architecture is based on existing data warehousing concepts, but as has already been mentioned, other types of information, for example, multimedia data, will be supported by these information stores in the future. At the top level of the architecture is the global warehouse, which integrates enterprise-wide business information. In the middle tier are departmental warehouses that contain business information for a specific business unit, set of users, or department. These departmental warehouses may be created directly from operational systems, or from the global warehouse. (Note that these departmental warehouses are often called data marts.) At the bottom of the architecture are other information stores, which contain information that has been tailored to meet the requirements of individual users or a specific application. An example of using this latter type of information store would be where financial data is extracted from a departmental information store and loaded in a separate store for modeling by a financial analyst. 5.4.3.1.5 Data Warehouse Modeling and Construction Tools These tools are used to capture data from operational and external source systems, clean and transform it, and load it into a global or departmental warehouse. IBM products use the database middleware of the Access Enabler component to access and maintain warehouse data in non-IBM databases. page 72 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues 5.4.3.1.6 Metadata Management This component manages the metadata associated with the complete business intelligence system, including the technical metadata used by developers and administrators, and the business metadata for supporting business users. 5.4.3.1.7 Administration This component covers all aspects of business intelligence administration, including security and authorization, backup and recovery, monitoring and tuning, operations and scheduling, and auditing and accounting. 5.4.3.2 Business Intelligence Partner Initiative IBM’s business intelligence structure is designed to be able to integrate and incorporate not only IBM’s business intelligence products, but also those from thirdparty vendors. To encourage support for its business intelligence structure, IBM has created a Business Intelligence Partner Initiative. The objective of this program is to have not only joint marketing relationships with other vendors, but also joint development initiatives that enable other vendors’ products to be integrated with IBM’s products. Proof that IBM is serious about tight integration between its products and those from other vendors can be seen in its current relationships with Arbor Software, Evolutionary Technology International, and Vality Technology. The next part of this paper on IBM’s business intelligence product set reviews the level of integration that has been achieved to date with products from these vendors. 5.5 Sybase 5.5.1 Technology Overview: Sybase Computing Platform The Sybase Computing Platform is directly aimed at the new competitive-advantageapplication development/deployment needs of enterprise IS. The Sybase Computing Platform includes a broad array of products and features for Internet/middleware architecture support, decision support, mass-deployment, and legacy-leveraging IS needs, bundled into a well-integrated, field-proven architecture. The Adaptive Server DBMS product family, the core engine of the Sybase Computing Platform, supports the full spectrum of new-application data needs: mass-deployment, enterprise-scale OLTP, and terabyte-scale data warehousing. The most notable point about the Sybase Computing Platform for the developer is its combination of simplicity and power. Developers can create applications that run without change on all major platforms and architectures, scaling up from the laptop to the enterprise server or Web server. These applications can take advantage of the scalability of Adaptive Server and PowerDynamo, the flexibility and programmer productivity of Powersoft's Java tools, and the legacy interoperability of Sybase's Enterprise CONNECT middleware [25]. 5.5.1.1 Adaptive Server DBMSs need the following crucial characteristics to effectively support IS's new application-development needs: Scalability down to the desktop and up to the enterprise; 1999 EURESCOM Participants in Project P817-PF page 73 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Flexibility to handle the new Internet and distributed-object architectures and to merge them with client-server and host-based solutions; Programmer productivity support by supplying powerful object interfaces that allow "write once, deploy many." Notable new or improved Adaptive Server features to meet these needs include: A common database architecture from the laptop and desktop to the enterprise improving flexibility and programmer productivity; Ability to handle mixed and varying workloads - improving scalability and flexibility; Ability to leverage legacy data via Sybase middleware - improving flexibility; Scalable-Internet-architecture support - improving scalability/flexibility; and New low- and high-end scalability features. 5.5.1.1.1 Common Database Architecture Adaptive Server adds a common language capability and a "component layer" that allows developers to write to a common API or class library acrossAdaptive Server Enterprise, Adaptive Server IQ, and Adaptive Server Anywhere. This library is based on Transact SQL, will soon include Java support, and will later support a superset of each DBMS's APIs. Thus, developers using this interface can today write applications for Adaptive Server Anywhere's Transact SQL that will run without change on the other two DBMSs, and will shortly be able to "write once, deploy many" for all Adaptive Server DBMSs. 5.5.1.1.2 Mixed and Varying Workloads Adaptive Server Enterprise provides notable mixed-workload flexibility and scalability, e.g., via the Logical Process Manager's effective allocation of CPU resources and the Logical Memory Manager's tunable block I/O. Tunable block I/O allows Adaptive Server Enterprise to adapt more effectively to changes in data-access patterns, improving performance for changing workloads. This is especially useful for scaling packaged applications that mix OLTP and decision support, and as flexible "insurance" where the future mix of OLTP and decision support is hard to predict. 5.5.1.1.3 Leverage Legacy Data Combined with Replication Server or other data-movement tools, Enterprise CONNECT allows users to merge legacy and divisional databases periodically or on a time-delayed basis into a common mission-critical-data pool. Administrators may translate the data into end-user-friendly information or duplicate and group it for faster querying. Thus, Enterprise CONNECT combined with Replication Server and Adaptive Server IQ forms the core of an enterprise-scalable data warehouse. Enterprise CONNECT includes an array of gateways, open clients, and open servers that match of exceed other suppliers' offerings in breadth and functionality. These include high-performance, globalized versions of Open Client and Open Server integrated with directory and security services such as Novell's NDS, as well as DirectCONNECT for MVS that integrates Open ClientCONNECT and Open ServerCONNECT. Sybase supports X/Open's TP-monitor standard via Sybase's XA Library that includes support for CICS/6000, Encina, Tuxedo, and Top End. page 74 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Replication Server - which allows developers to replicate data across multiple suppliers' distributed databases - is now fully supported in all three DBMS products. Users can use Replication Server to synchronize Sybase databases with heterogeneous distributed databases within non-SQL-Server and multisupplier environments. The OmniSQL Gateway "data catalogs" provide data-dictionary information across multiple databases. Users may now apply distributed queries across not only Adaptive Server's databases but also previous versions of SQL Server. Overall, Sybase's legacy-data support is exceptionally broad, allowing simple, flexible backend access to a particularly wide range of user data. Moreover, it is field-proven; products such as Open Client and Open Server have been highly popular and fieldtested for more than half a decade. 5.5.1.1.4 Internet-Architecture Support Adaptive Server is "Web-enabled," allowing users to write once to its common API and thereby deploy automatically across a wide range of target Internet environments. Enterprise CONNECT allows Internet access to more than 21 backend database servers, including partnerships with "firewall" suppliers for database security. 5.5.1.1.5 Low- and High-end Scalability Adaptive Server builds on SQL Server 11's benchmark-proven record of high scalability in database size and numbers of end users. Adaptive Server Enterprise now includes features such as bi-directional index scans for faster query processing, parallel querying, and parallel utilities such as online backup. Adaptive Server effectively supports database applications at the workgroup and client level through its synergism with Adaptive Server Anywhere. 5.5.1.1.6 Adaptive Server Anywhere Users should also note Adaptive Server Anywhere's exceptional downward scalability. Adaptive Server Anywhere's relatively small engine size ("footprint") allows it to fit within most of today's desktops and many of today's laptops. It takes up approximately 1 to 2 megabytes in main memory and 5.3 megabytes on disk. Thus, for exceptionally high performance for small-to-medium-scale databases, Adaptive Server Anywhere code and the entire database or a large database cache could run entirely in main memory. Adaptive Server Anywhere also requires only 2K bytes per communications connection, a key consideration in many sites where free space in low main memory is scarce. At the same time, Adaptive Server Anywhere provides the RDBMS features essential to high performance and scalability in desktop and workgroup environments: the ability to run in main memory; multi-user support and multithreading; 32-bit support; stored procedures and triggers; transaction support; native ODBC Level 2 support for faster ODBC access to the server; and cursor support to minimize time spent on result set download from the server. Further, Adaptive Server Anywhere completely supports Java database development by storing Java objects and JavaBeans, by accommodating stored procedures and triggers written in Java, and by offering high-performance Java database connectivity. Finally, Adaptive Server Anywhere sets a new standard in low-end performance by integrating Symmetric Multi-Processor support and including enhanced caching and optimizing capabilities. 1999 EURESCOM Participants in Project P817-PF page 75 (120) Volume 3: Annex 2 - Data manipulation and management issues 5.5.2 Sybase's Overall Application Customer-Centric Development Development/Upgrade Deliverable 1 Solution: Adaptive Server is a key component of Sybase's overall application development/deployment solution that also includes Sybase middleware such as PowerDynamo and Powersoft development tools such as PowerBuilder Enterprise, PowerSite, and PowerJ. PowerBuilder builds on the highly-popular PowerBuilder client-server application development environment to provide enterprise features such as dataaccess and Web-enablement support. The PowerSite Visual Programming Environment (VPE) provides support for developers creating new data-driven, Webbased enterprise-scale applications; it includes advanced Web-development features such as team programming support, automated Web application deployment, and application management across the Internet. PowerJ supports development of Java applications for both Web server and client applets, including Enterprise JavaBeans support. PowerDesigner provides team-programming application design and data modeling support, with specific features for data warehousing and the Internet. The Jaguar CTS transaction server and PowerDynamo application server provide load balancing for Web-based applications (in effect acting as an Internet TP monitor for scalability and access to multiple suppliers' backend databases), and PowerDynamo offers automated application deployment via replication. jConnect for JDBC allows developers to access multiple suppliers' backend databases via a common SQL-based API. Sybase aims the Sybase Computing Platform at "customer-centric development": that is, allowing IS to create new applications that use new technology to deliver competitive advantage by providing services to "customer" end users inside and outside the enterprise - for example, data mining for lines of business or Web electronic commerce for outside customers. The Sybase Computing Platform and Powersoft tools together provide exceptional features to aid incorporation of new technologies into competitive-advantage application development and deployment: Solution scalability in both application and database complexity - e.g., via Adaptive Server's "both-ways" scalability and the focus of all products on enterprise-scale application development via data-driven and team programming; Solution flexibility to cover a broad range of IS needs - e.g., via Adaptive Server's ability to cover OLTP, decision support, and mass-deployment needs, and by the emphasis of the development tools and middleware on openarchitecture standards such as the Internet, Java and JDBC; Programmer productivity features enabling a "write once, deploy many" approach, including such features as Adaptive Server's common API, the development tools' VPEs and team-programming features, and PowerSite's automated deployment features; and Specific support for new technologies such as the Internet, objects, and data warehousing - including not only support across the product line for Java objects and the Internet architecture, but also specialty datastores for multimedia and geospatial data from Sybase partners as well as Replication Server, distributed querying, and Adaptive Server IQ's fast-query capabilities. page 76 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 5.5.3 Volume 3: Annex 2 - Data manipulation and management issues Java for Logic in the Database A full-featured programming language for the DBMS Application logic (in the form of Java classes) will run in Adaptive Server in a secure fashion. A Java virtual machine (VM) and an internal JDBC interface are being built into Adaptive Server to make this happen. In this way, Sybase is bringing a fullfeatured yet secure programming language into the server, overcoming the programming limitations of SQL-based stored procedures. Object data type Java objects can be stored as values in a relational table. This provides the support for rich data types that other object-relational databases have aimed for, but by using Java it does so in an open, non-proprietary fashion. A consistent programming model For the first time, application components can be moved between clients or middle-tier servers and the DBMS. Developers have a single consistent programming model for all tiers. A natural implementation Sybase is committed to a natural implementation: Java objects and syntax work as you expect them to work; server schema function in an expected manner, even when interacting with Java objects. The Sybase Java initiative will open new doors for enterprise application development [26]. 5.5.3.1 A Commitment to Openness and Standards The Java relational architecture removes barriers to application development productivity, but proprietary implementations of new technologies can create other barriers. To further promote the open development environment Sybase believes IT organizations need, Sybase is working with JavaSoft, the ANSI SQL standards committee, and the JSQL consortium to develop standards for running Java in the DBMS. -Sybase aims to succeed by being the best company for IT to work with, not by providing proprietary solutions to IT problems. 5.5.3.2 Java for Logic in the Database Today's data servers use SQL to perform two tasks; data access and server-based logic. While SQL continues to be an excellent language for data manipulation and definition, the stored procedure extensions to SQL that allow server-based logic show some clear weaknesses. SQL stored procedures are limited by the lack of development tools, the inability to move stored procedures outside the server, and the lack of many features found in modern application programming languages such as external libraries, encapsulation and other aspects of object orientation, and the ability to create components. 1999 EURESCOM Participants in Project P817-PF page 77 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 5.5.3.2.1 Installing classes into the server Java logic is written in the form of classes. To use Java in the server, Adaptive Server will provide the ability to install a Java class into the server. The class is compiled into bytecode (ready for execution by the VM) outside the server. Once installed, it can be run and debugged from inside the server. -Java provides a natural solution to the limitations of stored procedures for encoding logic in a server. SQL continues to be the natural language for data access and modification. 5.5.3.2.2 Accessing SQL from Java with JDBC To implement Java logic in the database, there is a need for a Java interface to SQL. Just as SQL data manipulation and definition statements can be accessed from stored procedures, so too must they be accessible from Java methods. On the client side, JDBC provides an application programming interface (API) for including SQL in Java methods. JDBC is a Java Enterprise API for executing SQL statements and was introduced in the Java SDK 1.1.0. To meet the goal of removing barriers to application development and deployment, JDBC must also provide the interface for accessing SQL from Java methods inside the database. An internal JDBC interface for Adaptive Server is therefore a key part of the Sybase Java initiative. 5.5.3.2.3 Facilitating JDBC Development Like ODBC, JDBC is a low-level database interface. Just as many RAD tools have built their own more usable interfaces on top of ODBC, so too is there a need for interfaces on top of JDBC if developers are to be productive. As the Sybase implementation installs compiled Java classes (bytecode) into the DBMS, any of the higher-level tools and methods that generate Java and JDBC code are automatically supported. For example: JSQL JSQL is an alternative method of including SQL calls in Java code, managed by a consortium that includes IBM, Oracle, Sybase, and Tandem. JSQL provides an embedded SQL capability for JDBC. JSQL code is simpler to write in some cases than JDBC, and for database administrators has the advantage of being closer to the way in which SQL-based stored procedures are written. JSQL code is preprocessed into JDBC calls before compilation. Adaptive Server users will be able to write in JSQL if they wish, and install the preprocessed code into the server. RAD Tools RAD tools for Java, such as Sybase's PowerJ, provide Java classes built on top of JDBC to provide a more useable interface for developers. Such classes can be installed into the server for use. page 78 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues JavaBeans JavaBeans are components: collections of Java classes with a well-defined interface. JavaBeans can be installed into the server in the same way as any other set of classes. The Sybase Adaptive Component Architecture recognizes that component-based application development has become the major way to build enterprise database applications and the principal method of accelerating software delivery by reusing code. 5.6 Microsoft Microsoft SQL Server Enterprise Edition 6.5 is a high-performance database management system designed specifically for the largest, highly available Microsoft Windows NT operating system applications. It extends the capabilities of SQL Server by providing higher levels of scalability, performance, built-in high-availability, and a comprehensive platform for deploying distributed, mission-critical database applications [27]. 5.6.1 Overview As businesses streamline processes and decentralize decision-making, they increasingly depend on technology to bring users and information together. To that end, enterprise-class organizations are turning to distributed computing as the bridge between data and informed business decisions. Performance and reliability become an even greater factor as today's transactional processing systems grow in size and number of users. Microsoft SQL Server, Enterprise Edition 6.5 was engineered with this environment in mind. Microsoft SQL Server, Enterprise Edition extends the tradition of excellence in Microsoft SQL Server, providing a higher level of scalability and availability. Optimized for the Windows NT Enterprise Edition operating system, Microsoft SQL Server, Enterprise Edition is designed to meet the needs of enterprise OLTP, data warehouse and Internet applications. In addition to the features provided in the standard version of Microsoft SQL Server, the Enterprise Edition of SQL Server supports high-end symmetric multiprocessing (SMP) servers with additional memory, providing customers with better performance and scalability. To meet the availability and 7-day by 24-hour requirements of mission-critical applications, Microsoft SQL Server, Enterprise Edition also supports high-availability 2-node clusters. Many of these performance and reliability gains are achieved through the close integration with the Enterprise Edition of Windows NT Server. And, as part of the Microsoft BackOffice, Enterprise Edition family, Microsoft SQL Server, Enterprise Edition 6.5works with the other Microsoft BackOffice server products for superior, integrated client/server and Web-based applications. 5.6.1.1 Product Highlights 5.6.1.1.1 Support for larger SMP servers Microsoft SQL Server is architected to deliver excellent scalability on SMP servers from a variety of system vendors. The standard version is optimized for use on up to 1999 EURESCOM Participants in Project P817-PF page 79 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 four-processor SMP servers. Enterprise Edition is designed and licensed for use on a new class of more-than-four-processor SMP servers for superior scalability. 5.6.1.1.2 Cluster-ready for high availability Microsoft SQL Server, Enterprise Edition also delivers built-in support for Microsoft Cluster Server, formerly known by the code name "Wolfpack." In a high-availability cluster configuration, Microsoft SQL Server delivers 100 percent protection against hardware faults for mission-critical applications. To simplify the management of a high-availability cluster, Microsoft SQL Server, Enterprise Edition provides easy-touse graphical tools for setting up and configuring the two-node cluster. 5.6.1.1.3 Support for additional memory Complete support for Windows NT Server 4GB RAM tuning (4GT), allows Microsoft SQL Server to take advantage of additional memory. Making use of 4GT allows Microsoft SQL Server to address up to 3 GB of real memory, providing increased performance for applications such as data warehousing. This feature is available for Microsoft SQL Server, Enterprise Edition only on 32-bit Intel architecture servers. Very large memory (VLM) support for Digital's 64-bit Alpha Servers will be delivered in a future release of Microsoft SQL Server, Enterprise Edition. 5.6.1.1.4 Natural language interface Enables the retrieval of information from SQL Server, Enterprise Edition using English, rather than a formal query language, such as SQL. An application using Microsoft English Query accepts English commands, statements, and questions as input and determines their meaning. It then writes and executes a database query in SQL Server and formats the answer. 5.6.1.1.5 A platform for building reliable, distributed applications In addition, Microsoft SQL Server, Enterprise Edition, in conjunction with Windows NT Server, Enterprise Edition, is a complete platform for reliable, large-scale, distributed database applications, utilizing the Microsoft Transaction Server and Microsoft Message Queue Server software. Microsoft Transaction Server is component-based middleware for building scalable, manageable distributed transaction applications quickly. Microsoft Transaction Server provides simple building blocks that can reliably and efficiently execute complex transactions across widespread distributed networks, including integrated support for Web-based applications. Microsoft Message Queue Server is store-and-forward middleware that ensures delivery of messages between applications running on multiple machines across a network. Microsoft Message Queue Server is an ideal environment for building large-scale distributed applications that encompass mobile systems or communicate across occasionally unreliable networks. 5.6.1.2 General Info 5.6.1.2.1 Specifications System using an Intel Pentium or Digital Alpha processor Microsoft Windows NT Server 4.0 Enterprise Edition. 64 MB of memory page 80 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues 80 MB of available hard disk space (95 MB with books online) CD-ROM drive 5.6.1.2.2 Networking Options The following networks are supported using native protocols: Microsoft Windows NT Server Microsoft LAN Manager Novell NetWare TCP/IP-based networks IBM LAN Server Banyan VINES Digital PATHWORKS Apple AppleTalk 5.6.1.2.3 Clients supported: 5.6.2 Microsoft Windows operating system version 3.1 Microsoft Windows 95 Microsoft Windows for Workgroups Microsoft Windows NT Workstation Microsoft MS-DOS® operating system Microsoft Cluster Server In late 1995, Microsoft announced that they would work with their hardware and software vendors to deliver clustering for the Microsoft Windows NT Server network operating system, the Microsoft BackOffice integrated family of server software, and leading application software packages. Clustering technology enables customers to connect a group of servers to improve application availability, data availability, fault tolerance, system manageability, and system performance. Unlike other clustering solutions, the Microsoft approach does not require proprietary systems or proprietary server interconnection hardware. Microsoft outlined this strategy because customers indicated a need to understand how clustering will fit into their long-term, information technology strategy. Microsoft Cluster Server (MSCS), formerly known by its code name, ”Wolfpack” will be included as a built-in feature of Microsoft Windows NT Server, Enterprise Edition. Over fifty hardware and software vendors participated in the MSCS design reviews throughout the first half of 1996, and many of these are now working on MSCS-based products and services. Microsoft is also working closely with a small group of Early Adopter system vendors in the development and test of its clustering software: Compaq Computer Corp., Digital Equipment Corp., Hewlett-Packard, IBM, NCR, and Tandem Computers. Together, Microsoft and these vendors will create a standard set of products and services that will make the benefits of clustered computers easier to utilize and more cost effective for a broad variety of customers. [28] 1999 EURESCOM Participants in Project P817-PF page 81 (120) Volume 3: Annex 2 - Data manipulation and management issues 5.6.2.1 Deliverable 1 A Phased Approach MSCS software will include an open Application Programming Interface (API) that will allow applications to take advantage of Windows NT Server, Enterprise Edition, in a clustered environment. As will other application vendors, Microsoft plans to use this API to add cluster-enabled enhancements to future versions of its server applications, the BackOffice family of products. Clustering will be delivered in phases. Phase 1: Support for two-node failover clusters. Applications on a primary server will automatically fail over to the secondary server when instructed to do so by the administrator or if a hardware failure occurs on the primary server. Phase 2: Support for shared-nothing clusters up to 16 nodes and for parallel applications that can use these large clusters to support huge workloads. The progress in MSCS will be mirrored by progress in applications that use these features to provide application-level availability and scalability. Microsoft SQL Server gives a good example of how applications built on top of MSCS provides these benefits to the customer. 5.6.2.2 SQL Server Use of Microsoft Cluster Server Microsoft SQL Server is an excellent example of a Windows NT Server-based application that will take advantage of MSCS to provide enhanced scalability and availability. Microsoft will deliver SQL Server clustering products in two phases: Phase 1: Symmetric Virtual Server: Enables a two-node cluster to support multiple SQL Servers. When one node fails or is taken offline, all the SQL Servers migrate to the surviving node. Phase 2: Massive Parallelism: Enables more than two servers to be connected for higher performance. 5.6.2.2.1 Phase 1: Symmetric Virtual Server Solution SQL Server will have the capability to run several SQL Server services on an MSCS Cluster. In a two-node cluster, each node will be able to support half the database and half the load. On failure, the surviving node will host both servers. During normal operation, each node will serve half the clients and will be managing the database on half the disks, as shown in Figure 2. SQL Server will also include wizards and graphical tools to automate cluster setup and management. This phase will be supported with the Phase 1 release of MSCS. 5.6.2.2.2 Availability SQL Server 6.5, Enterprise Edition is scheduled for release in the third quarter of 1998. It will provide for Microsoft Cluster Service and it will utilize a 3 GB memory space for its execution, offering users even higher performance. 5.6.2.2.3 Phase 2: Massive Parallelism Phase 2 will enable future versions of SQL Server to use massive parallelism on large clusters. When the overall load exceeds the capabilities of a cluster, additional systems may be added to scale up or speed up the system. This incremental growth page 82 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues enables customers to add processing power as needed. This parallelism is almost automatic for client-server applications like online-transaction processing, file services, mail services, and Internet services. In those applications the data can be spread among many nodes of the cluster, and the workload consists of many independent small jobs that can be executed in parallel. By adding more servers and disks, the storage and workload can be distributed among more servers. Similarly, for batch workloads like data mining and decision support queries, parallel database technology can break a single huge query in to many small independent queries that can be executed in parallel. Sphinx will support pipeline parallelism, while future versions will support partition parallelism. Formerly, IS professionals needed to make up-front commitments to expensive, highend servers that provided space for additional CPUs, drives, and memory. With the Phase 2 implementation of SQL Server on MSCS, they will be able to purchase new servers as needed and just add them to the cluster to grow the system's capacity and throughput. 5.7 NCR Teradata 5.7.1 Data Warehousing with NCR Teradata Beginning with the first shipment of Teradata RDBMS, NCR have over 16 years of experience in building and supporting data warehouses worldwide. Today, NCR Scalable Data Warehousing (SDW) deliver solutions in the data warehouse marketplace, from entry-level data marts to very large production warehouses with hundreds of Terabytes. Data warehousing from NCR is a complete solution that combines Teradata parallel databasetechnology, scalable hardware, experienced data warehousing consultants, and industry tools and applications available on the market today [29], [30]. 5.7.1.1 The Database – A Critical Component of Data Warehousing Most databases were designed for OLTP environments with quick access and updates to small objects or single records. But what happens when you want to use your OLTP database to scan large amounts of data in order to answer complex questions? Can you afford the constant database tuning required to accommodate change and growth in your data warehouse? And will your database support the scalability requirements imposed by most data warehouse environments? Data warehousing is a dynamic and iterative process, the requirements of which are constantly changing as the demands on your business change. 5.7.1.2 NCR claims to be The Leader in Data Warehousing NCR has more than 16 years of experience in the design, implementation, and management of large-scale data warehouses. NCR claims itself as the data warehousing leader and dominator of industry benchmarks for decision support in all data volumes. NCRs WorldMark servers have been hailed [31] as the most open and scalable computing platforms on the market today. NCR claims to have the most comprehensive data warehousing programs to help your current and future initiatives, as well as alliances with other software and services vendors in the industry. 1999 EURESCOM Participants in Project P817-PF page 83 (120) Volume 3: Annex 2 - Data manipulation and management issues 5.7.1.3 Deliverable 1 NCR Teradata RDBMS - The Data Warehouse Engine The NCR Teradata Relational Database Management System (RDBMS) is a scalable, high performance decision support solution. This data warehouse engine is an answer for customers who develop scalable, mission-critical decision support applications. Designed for decision support and parallel implementation from its conception, NCR Teradata is not constrained by the limitations that plague traditional relational database engines. Teradata easily and efficiently handles complex data requirements and simplifies management of the data warehouse environment by automatically distributing data and balancing workloads. 5.7.2 Teradata Architecture NCR Teradata’s architectural design was developed to support mission-critical, faulttolerant decision support applications. Here is how NCR database technology has evolved. 5.7.2.1 The Beginning – AMPs The original Teradata design employed a thin-node (one processor per logical processing unit) shared nothing architecture that was implemented on Intel-based systems. Each Access Module Processor (AMP), a physically distinct unit of parallelism, consisted of a single Intel x386 or x486 CPU. Each AMP had exclusive access to an equal, random portion of the database. 5.7.2.2 The Next Phase – VPROCs As hardware technology advanced and the demand for non-proprietary systems increased, Teradata entered its next phase of evolution in which the original architecture was "virtually" implemented in a single Symmetric Multi-Processing (SMP) system. The multitasking capabilities of UNIX, the enhanced power of next generation processors like the Pentium, and the advent of disk array subsystems (RAID), allowed for the implementation of virtual AMPs, also known as virtual processors (VPROCs). In this implementation, the logical concept of an AMP is separated even further from the underlying hardware. Each VPROC is a collection of tasks or threads running under UNIX or Windows NT. This allows the system administrator to configure NCR Teradata to use more AMPs than the underlying system has processors. In turn, each VPROC has semi-exclusive access to one or more physical devices in the attached RAID subsystem. There are actually two types of VPROCs in Teradata: the AMP and the Parsing Engine (PE). The PE performs session control and dispatching tasks, as well as SQL parsing functions. The PE receives SQL commands from the user or client application and breaks the command into sub-queries, which are then passed on to the AMPs. There need not be a one-to-one relationship between the number of PEs and the number of AMPs. In fact, one or two PEs may be sufficient to serve all other AMPs on a single SMP node. The AMP executes SQL commands and performs concurrency control, journaling, cache management, and data recovery. page 84 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 5.7.2.3 Volume 3: Annex 2 - Data manipulation and management issues Today – MPP Today's version of Teradata takes the architecture even further, providing openness and scalability by adding additional operating system support and interconnect capabilities. Now running on UNIX or Windows NT (with modifications - see note on NT below), each SMP system can be connected via Teradata's high-speed interconnect, the BYNET, to form "FAT Nodes" in a loosely coupled Massively Parallel Processing (MPP) architecture that is managed as a single system. This provides the foundation for Teradata's linear scalability, which can start with a fourprocessor SMP environment and scale to thousands of physical processors and tensof-thousands of VPROCs. A perfect fit for entry-level data marts or massive enterprise warehouses. Note on NT: Teradata on NT only allows up to 50 GB userdata. An update of Teradata on NT is planed for the fall 1998. This update will allow up to 300 GB userdata. According to plans Teradata 3.0 will be released in the second half of 1999. From this point forward feature and functionality enhancements will be released on the NT and UNIX platforms simultaneously [32]. 5.7.2.3.1 BYNET – Scalable Interconnect The BYNET is a redundant, fault-tolerant, intelligent, high-speed circuit switching interconnect for Teradata. The BYNET allows the database to coordinate and synchronize the activities of a large number of SMP nodes without increasing network traffic or degrading performance as the system grows. The BYNET provides a nodeto-node data transfer bandwidth of 10 MB per second and can linearly scale, supporting up to 1024 nodes on a single system. 5.7.2.3.2 Scalable Hardware Platform Teradata's scalability is further enhanced through its tight integration with the NCR WorldMark platform. The WorldMark family of Intel-based servers provides seamless and transparent scalability. Adding more computational power is as simple as adding more hardware to the current system. The operating system will automatically recognize and adapt to the additional system resources, and NCR Teradata will redistribute existing data to take advantage of the new hardware. Existing applications continue to run without modification. 5.7.3 Application Programming Interfaces Teradata provides a number of standardized interfaces to facilitate easy development of client/server applications. Included are the Teradata ODBC Driver, the Teradata Call-Level Interface (CLI), and the TS/API which permits applications that normally access IBM DB2 to run against Teradata. Also included are a number of third-party interfaces like the Oracle Transparent Gateway for Teradata, Sybase Open Server and Open Client. 5.7.4 Language Preprocessors NCR Teradata provides a number of preprocessors to facilitate application development in languages such as COBOL, C/C++ and PL/1. With the libraries in these preprocessors, developers can create or enhance client or host-based applications that access the Teradata RDBMS. 1999 EURESCOM Participants in Project P817-PF page 85 (120) Volume 3: Annex 2 - Data manipulation and management issues 5.7.5 Deliverable 1 Data Utilities Teradata includes both client-resident and host-based utilities that allow users and administrators to interact with or control the Teradata engine. Among them are the Basic Teradata Query facility (BTEQ) for command-line and batch-driven querying and reporting; BulkLoad, FastLoad and MultiLoad for data loading and updating; and FastExport for extracting data from Teradata. 5.7.6 Database Administration Tools The Teradata RDBMS has a rich collection of tools and facilities to control the operation, administration, and maintenance of the database. These include ASF/2 for backup, archive, and recovery, the Database Window (DBW) for status and performance statistics, and the Administrative Workstation (AWS) for a single point of administrative control over the entire WorldMark-based Teradata system. All of these tools and many others can be accessed individually or through a common user interface known as Teradata Manager. Teradata Manager runs on Windows NT or OS/2. 5.7.7 Internet Access to Teradata The Internet can widely expand your company's exposure to global markets. NCR understands this emerging opportunity and consequently offers two common methods for accessing information stored in the NCR Teradata RDBMS from the World Wide Web: Java and CGI. 5.7.7.1 Java The Teradata Gateway for Java provides application developers with a simple, easy to use API to access Teradata from the Internet or Intranet. Any client capable of running a Java applet or application, including web browsers like Netscape Navigator or Microsoft Internet Explorer, can now access the Teradata RDBMS directly. 5.7.7.2 CGI Access The Common Gateway Interface (CGI) describes a standard for interfacing database applications with web servers. NCR's CGI solution for Teradata allows SQL statements to be embedded within an HTML page and provides a mechanism to return result sets in the same HTML format. It validates parameters received through the HTTP query string and allows all data manipulation language (DML) constructs, including SELECTS, INSERTS, UPDATES, and DELETES. 5.7.8 NCR's Commitment to Open Standards NCR is a dedicated member of many committees that define industry standards, including the ANSI SQL Committee, the Microsoft Data Warehouse Alliance, the OLAP Council and the Metadata Coalition. Fifteen years ago, with its original parallel and scalable design, Teradata's developers began the process necessary to make the database available on many different platforms. page 86 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 5.7.9 Volume 3: Annex 2 - Data manipulation and management issues Teradata at work As your business expands in volume and complexity, NCR’s data warehousing solution protect your investment in both hardware and software. NCR data warehouses scale proportionately to support your users and your increasingly complex data. In fact, NCR offers a seamless pathway to scale a pilot data warehouse to a multi-terabyte configuration without changing hardware, databases or applications. NCR Teradata RDBMS with its shared nothing architecture, combined with a new class of scalable, modular and high availability WorldMark servers, give you a secure, guaranteed solution to help you move confidently into the 21st century. 5.7.9.1 Retail Retailers use NCR Teradata to compile and analyze months and years of data gathered from checkout scanners in thousands of retail stores worldwide to manage purchasing, pricing, stocking, inventory management and to make store configuration decisions. 5.7.9.2 Financial The financial industry uses NCR Teradata for relationship banking and householding where all customer account information is merged for cross segment marketing. Data is sourced from diverse geographical areas, different lines of business (checking, savings, auto, home, credit cards, ATMs) and from various online systems. 5.7.9.3 Telecommunications The telecommunications industry uses NCR Teradata to store data on millions of customers, circuits, monthly bills, volumes, services used, equipment sold, network configurations and more. Revenues, profits and costs are used for target marketing, revenue accounting, government reporting compliance, inventory, purchasing and network management. 5.7.9.4 Consumer Goods Manufacturing Manufacturers use NCR Teradata to determine the most efficient means for supplying their retail customers with goods. They can determine how much product will sell at a price point and manufacture goods for "just in time" delivery. 6 Analysis and recommendations In general there are different interests in distributed databases. Some of these are (1-3): (1) The opportunity to implement new architectures, which are distributed according to their conceptual nature. (2) The opportunity to make distributed implementations of conceptual non distributed systems to achieve efficiency. (3) Situations where data are available in a distributed system by nature. But where it is more desirable to consider these data as non distributed. In the latter case we might implement a federated database to access data. The design of a distributed database is an optimisation problem requiring solutions to several interrelated problems e.g. data fragmentation, data allocation, data replication, partitioning and local optimisation. Special care is needed to implement query processing and optimisation. 1999 EURESCOM Participants in Project P817-PF page 87 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Retrieval and manipulation of data in different database architectures has various options for finding optimal solutions for database applications. In recent years many architectural options have been discussed in the field of distributed and federated databases and various algorithms have been implemented to optimise the handling of data and to optimise methodologies to implement database applications. Retrieval and manipulation in the different architectures applies nevertheless similar theoretical principals for optimising the interaction between applications and database systems. Efficient query and request execution is an important criterion when retrieving large amounts of data. This part also described a number of commercial database products competing in the VLDB segment. Most of these run on various hardware platforms. The DBMSs are generally supported by a range of tools for e.g. data replication and data retrieval. References [1] Gray, Jim, Andreas Reuter, ”Transaction Techniques”, Morgan Kaufmann, 1993 Processing Concepts and [2] Ceri, S: ”Distributed Databases”, McGraw-Hill, 1984 [3] A. P. Sheth; J. A. Larson, ”Federated Database Systems for Managing Distributed, Heterogeneous, and Autonomous Databases”, ACM Computer Surveys, 22(3): 183-236, September 1990. [5] S. Chaudhuri, ”An Overview of Query Optimization in Relational Systems”, Proceedings the ACM PODS, 1998, http://www.research.microsoft.com/users/surajitc [6] J. K. Smith, ”Survey Paper On Vertical Partitioning”, November 3, 1997, http://www.ics.hawaii.edu/~jkdmith/survey69l.html [7] Goetz Graefe, ”Query Evaluation Techniques for Large Databases”, ACM Computing Surveys, pp. 73-170, June 1993, available online: http://wilma.cs.brown.edu/courses/cs227/papers/bl/Graefe-Survey.ps [8] EURESCOM P817, Deliverable 1, Volume 2, Annex 1 - Architectural and Performance issues, September 1998 [9] Chakravarthy, S., Muthuraj, J., Varadarajan, R., and Navathe, S., ”An Objective Function for Vertically Partitioning Relations in Distributed Databases and its Analysis”, University of Florida Technical Report UF-CISTR-92-045, 1992 [11] Ee-Peng Lim, Roger H. L. Chiang, Yinyan Cao, "Tuple Source Relational Model: A Source-Aware Data Model for Multidatabases" Note: Will be published in: Data & Knowledge Engineering. Amstedam: Elsevier, 1985-. ISSN: 0169-023X. Requests for further details can be sent by email to fnorm@tdk.dk. [12] Compaq World NonStop <http://www.tandem.com> [13] Oracle Technology Network <http://technet.oracle.com/> [14] The Object-Relational DBMS <http://technet.oracle.com/doc/server.804/a58227/ch5.htm#10325> [15] PL/SQL New Features with Oracle8 and Future Directions <http://ntsolutions.oracle.com/products/o8/html/plsqlwp1.htm> page 88 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues [16] A Family of Products with Oracle8 <http://www.oracle.com/st/o8collateral/html/xo8twps2.html> [17] <http://www.oracle.com/st/o8collateral/html/xo8vtwp3.html> [18] Getting Started with Informix Dynamic Server <http://www.informix.com/answers/english/pdf_docs/73ids/4351.pdf> [19] Introduction to new fetures <http://www.informix.com/answers/english/pdf_docs/metacube/5025.pdf> [20] Explorer User’s Guide, MetaCube ROLAP Option <http://www.informix.com/answers/english/pdf_docs/metacube/4188.pdf> [21] MetaCube for Excel, User’s Guide, MetaCube ROLAP Option <http://www.informix.com/answers/english/pdf_docs/metacube/4193.pdf> [22] Creating An Extensible, Object-Relational Data Management Environment, IBM's DB2 Universal Database <http://www.software.ibm.com/data/pubs/papers/dbai/db2unidb.htm> [23] The IBM Business Intelligence Software Solution <http://www.software.ibm.com/data/pubs/papers/bisolution/index.html> [24] The DB2 Product Family <http://www.software.ibm.com/data/db2/> [25] Sybase Adaptive Server And Sybase Computing Platform: A Broad, Powerful Foundation For New-Technology Deployment <http://www.sybase.com/adaptiveserver/whitepapers/computing_wps.html> [26] Sybase Adaptive Server: Java in the Database <http://www.sybase.com/adaptiveserver/whitepapers/java_wps.html> [27] Microsoft SQL Server, Enterprise Edition <http://www.microsoft.com/sql/guide/enterprise.asp?A=2&B=2> [28] Clustering support for Microsoft SQL Server <http://www.microsoft.com/sql/guide/sqlclust.asp?A=2&B=4> [29] <http://www3.ncr.com/teradata/teraover.pdf> [30] <http://www.teradata.com> [31] <http://www3.ncr.com/data_warehouse/awards.html> [32] <http://www3.ncr.com/teradata/nt/tntmore.html> 1999 EURESCOM Participants in Project P817-PF page 89 (120) Volume 3: Annex 2 - Data manipulation and management issues page 90 (120) Deliverable 1 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Part 3 Backup and Recovery 1 Introduction The purpose of this chapter is to discuss the control strategies available to the database administrator in order to deal with failures and security threats. Any deviation of a system from the expected behaviour is considered a failure. Failures in a system can be attributed to deficiencies in the components that make it up, both hardware and software, or in the design. Backups are important because no system is free from failures, not even fault-tolerant systems. It is necessary to restore and recover the data quickly to resume operations. The key to success in this situation is a well-defined backup and recovery strategy. The definition of the rules for controlling data manipulation is part of the administration of the database, so security aspects must also be taken into account. This part ends with two appendixes with backup and recovery demonstrations of terabyte databases. The figures mentioined, give an idea of the time needed and system overhead generated when backing up and recovering a very large database. 2 Security aspects Data security is an important function of a database system that protects data against unauthorised access. Data security includes two aspects: data protection and authorisation control. Data protection is required to prevent unauthorised users from understanding the physical content of data. This function is typically provided by data encryption. Authorisation control must guarantee that only authorised users perform operations they are allowed to perform on the database. Authorisations must be refined so that different users have different rights on the same objects. When discussing security, it is important to note the various threats to data. Some threats are accidental, but they can lead to the disclosure, deletion, or destruction of the data in the databases. These threats include software, hardware, and human errors. However, attempts to deliberately bypass or violate the security facilities are by far the biggest security threats. Such attempts include the following: Unauthorised stealing, copying, changing, corrupting, or browsing through stored data. Electronic bugging of communication lines, terminal buffers, or storage media. Sabotaging, which can include erasing and altering the data, deliberately inputting erroneous data, or maliciously destroying the equipment or the storage media. Personnel aspects, such as position misuse, false identification, blackmail, bribery, or transferred authorisation (where users can obtain other passwords). DBAs avoiding or suppressing the security facilities. 1999 EURESCOM Participants in Project P817-PF page 91 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Shared programs performing functions not described in their specifications by taking advantage of the rights of their environment. Masquerading, such as when a program poses as the operating system or the application, to obtain user passwords. Each organisation should have a data security policy, which is a set of high-level guidelines determined by user requirements, environmental aspects, internal regulations, and governmental laws. In a database environment, security focuses on the allowed access, the control of the access, and the granularity of the control. The allowed access to data is somewhere on the scale between need-to-know (only the data necessary to perform a task is supplied) and maximal sharing. Data access control can be described by a scale ranging from an open system to a closed system. Control granularity determines which types of objects access rights are specified -- for example, individual data items, collections of data items (such as rows in tables), data object contents (such as all the rows in a table or a view), the functions executed, the context in which something is done, or the previous access history. The approaches, techniques, and facilities one use for security control must cover external (or physical) security control as well as internal (computer system) security control. The external security controls include access control, personnel screening, proper data administration, clean desk policies, waste policies, and many, many more. The main focus lies here on the internal controls that ensure the security of the stored and operational data. These include the following: Access controls: Ensure that only authorised accesses to objects are made -doing so specifies and enforces who may access the database and who may use protected objects in which way. Authorisation is often specified in terms of an access matrix, consisting of subjects (the active entities of the system), objects (the protected entities of the model), and access rights, where an entry for a [subject, object] pair documents the allowable operations that the subject can perform on the object. Two variations on access matrices are authorisation lists and capabilities. Authorisation lists or access-control lists (per object) specify which subjects are allowed to access the object and in what fashion. Capabilities are [objects, rights] pairs allocated to users; they specify the name or address of an object and the manner in which those users may access it. Ownership and sharing: Users may dispense and revoke access privileges for objects they own or control. Threat monitoring: An audit trail is recorded to examine information concerning installation, operations, applications, and fraud of the database contents. A usage log is kept of all the executed transactions, of all the attempted security violations, and of all the outputs provided. The security mechanisms you use to protect your databases should have the following properties: Completeness: Defence is maintained against all possible security-threatening attacks. Confidence: The system actually does protect the database as it is supposed to. Flexibility: A wide variety of security policies can be implemented. page 92 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Ease of use: The database administrator (DBA) has an easy interface to the security mechanisms. Resistance to tampering: The security measures themselves are secure. Low overhead: The performance costs can be predicted and are low enough for efficiency. Low operational costs: The mechanisms utilise the available resources efficiently. In most DBMSs, authorisation rules enforce security. Authorisation rules are controls incorporated in the database and enforced by the DBMS. They restrict data access and also the actions that people may take when they access the data. 3 Backup and Recovery Strategies This chapter put the main emphasis on backup and recovery strategies of VLDBs. Recovery can be necessary to receive data of an archive with special day stamp, or to reset an application or to keep an application in case of data loss running with lowest loss of service time. One of the innumerable tasks of the DBA is to ensure that all of the databases of the enterprise are always "available." Availability in this context means that the users must be able to access the data stored in the databases, and that the contents of the databases must be up-to-date, consistent, and correct. It must never appear to a user that the system has lost the data or that the data has become inconsistent. Many factors threaten the availability of the databases. These include natural disasters (such as floods and earthquakes), hardware failures (for example, a power failure or disk crash), software failures (such as DBMS malfunctions -- read "bugs" -- and application program errors), and people failures (for example, operator errors, user misunderstandings, and keyboard trouble). To this list one can also add security aspects, such as malicious attempts to destroy or corrupt the contents of the database. Oracle classifies the most frequent failures as follows: Statement and process failure: Statement failure occurs when there is a logical failure in the handling of a statement in an Oracle program (for example, the statement is not a valid SQL construction). When statement failure occurs, the effects (if any) of the statement are automatically undone by Oracle and control is returned to the user. A process failure is a failure in a user process accessing Oracle, such as an abnormal disconnection or process termination. The failed user process cannot continue work, although Oracle and other user processes can. h minimal impact on the system or other users. Instance failure: Instance failure occurs when a problem arises that prevents an instance (system global area and background processes) from continuing work. Instance failure may result from a hardware problem such as a power outage, or a software problem such as an operating system crash. When an instance failure occurs, the data in the buffers of the system global area is not written to the datafiles. User or application error: User errors can require a database to be recovered to a point in time before the error occurred. For example, a user might accidentally delete data from a table that is still required (for example, payroll taxes). To 1999 EURESCOM Participants in Project P817-PF page 93 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 allow recovery from user errors and accommodate other unique recovery requirements, Oracle provides for exact point-in-time recovery. For example, if a user accidentally deletes data, the database can be recovered to the instant in time before the data was deleted. Media (disk) failure: An error can arise when trying to write or read a file that is required to operate the database. This is called disk failure because there is a physical problem reading or writing physical files on disk. A common example is a disk head crash, which causes the loss of all files on a disk drive. Different files may be affected by this type of disk failure, including the datafiles, the redo log files, and the control files. Also, because the database instance cannot continue to function properly, the data in the database buffers of the system global area cannot be permanently written to the datafiles. Data saved in VLDB´s are used from applications e.g. data mining, data warehousing to deduce estimated values from or to make decisions or for operational actions. Depending of the application loss of data can be without effects or is not acceptable. In the second case security concepts have to be developed to avoid loss and repair respectively. Errors which causes loss of data are distinguished in 6 categories: 1. User error: user deletes or changes data improper or erroneous. 2. Operation error: an operation causes a mistake and the DBMS reacts with an error message. 3. Process error: a failure of a user process is called process error. 4. Network error: an interruption of the network can cause network errors in client/server based databases. 5. Instance error: e.g. power failure or software failures can cause that the instance (SGA with processes in the background) does not work properly any more. 6. Media error: Physical hardware defects causes read or write failures. Errors 1 - 5 can be troubleshooted by algorithms of the DBMS. Therefore backup and recovery strategies are focused on treatment of media errors and archivation. In a large enterprise, the DBA must ensure the availability of several databases, such as the development databases, the databases used for unit and acceptance testing, the operational online production databases (some of which may be replicated or distributed all over the world), the data warehouse databases, the data marts, and all of the other departmental databases. All of these databases usually have different requirements for availability. The online production databases typically must be available, up-to-date, and consistent for 24 hours a day, seven days a week, with minimal downtime. The warehouse databases must be available and up-to-date during business hours and even for a while after hours. On the other hand, the test databases need to be available only for testing cycles, but during these periods the testing staff may have extensive requirements for the availability of their test databases. For example, the DBA may have to restore the test databases to a consistent state after each test. The developers often have even more ad hoc requirements for the availability of the development databases, specifically toward the end of a crucial deadline. The business hours of a multinational organization may also have an impact on availability. For example, a working day from 8 a.m. in central Europe to 6 p.m. in California implies that the database must be page 94 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues available for 20 hours a day. The DBA is left with little time to provide for availability, let alone perform other maintenance tasks. 3.1 Recovery Recovery is the corrective process to restore the database to a usable state from an erroneous state. The basic recovery process consists of the following steps: 1. Identify that the database is in an erroneous, damaged, or crashed state. 2. Suspend normal processing. 3. Determine the source and extent of the damage. 4. Take corrective action, that is: 5. Restore the system resources to a usable state. Rectify the damage done, or remove invalid data. Restart or continue the interrupted processes, including the re-execution of interrupted transactions. Resume normal processing. To cope with failures, additional components and algorithms are usually added to the system. Most techniques use recovery data (that is, redundant data), which makes recovery possible. When taking corrective action, the effects of some transactions must be removed, while other transactions must be re-executed; some transactions must even be undone and redone. The recovery data must make it possible to perform these steps. The following techniques can be used for recovery from an erroneous state: Dump and restart: The entire database must be backed up regularly to archival storage. In the event of a failure, a copy of the database in a previous correct state (such as from a checkpoint) is loaded back into the database. The system is then restarted so that new transactions can proceed. Old transactions can be re-executed if they are available. The following types of restart can be identified: A warm restart is the process of starting the system after a controlled system shutdown, in which all active transactions were terminated normally and successfully. An emergency restart is invoked by a restart command issued by the operator. It may include reloading the database contents from archive storage. A cold start is when the system is started from scratch, usually when a warm restart is not possible. This may also include reloading the database contents from archive storage. Usually used to recover from physical damage, a cold restart is also used when recovery data was lost. Undo-redo processing (also called roll-back and re-execute): By using an audit trail of transactions, all of the effects of recent, partially completed transactions can be undone up to a known correct state. Undoing is achieved by reversing the updating process. By working backwards through the log, all of the records of the transaction in question can be traced, until the begin transaction operations of all of the relevant 1999 EURESCOM Participants in Project P817-PF page 95 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 transactions have been reached. The undo operation must be "idempotent," meaning that failures during undo operations must still result in the correct single intended undo operation taking place. From the known correct state, all of the journaled transactions can then be re-executed to obtain the desired correct resultant database contents. The operations of the transactions that were already executed at a previous stage are obtained from the audit trail. The redo operation must also be idempotent, meaning that failures during redo operations must still result in the correct single intended redo operation taking place. This technique can be used when partially completed processes are aborted. Roll-forward processing (also called reload and re-execute): All or part of a previous correct state (for example, from a checkpoint) is reloaded; the DBA can then instruct the DBMS to re-execute the recently recorded transactions from the transaction audit trail to obtain a correct state. It is typically used when (part of) the physical media has been damaged. Restore and repeat: This is a variation of the previous method, where a previous correct state is restored. The difference is that the transactions are merely reposted from before and/or after images kept in the audit trail. The actual transactions are not re-executed: They are merely reapplied from the audit trail to the actual data table. In other words, the images of the updated rows (the effects of the transactions) are replaced in the data table from the audit trail, but the original transactions are not reexecuted as in the previous case. Some organizations use so-called "hot standby" techniques to increase the availability of their databases. In a typical hot standby scenario, the operations performed on the operational database are replicated to a standby database. If any problems are encountered on the operational database, the users are switched over and continue working on the standby database until the operational database is restored. However, database replication is an involved and extensive topic. In the world of mainframes backup and recovery are very well known and therefore there are some well established tools. In contrast to the mainframe world there are less professional tools for VLDB for Unix and NT based systems available. This chapter shows concepts and requirements of backup strategies and give an overview of available commercial tools. 3.2 Strategies 3.2.1 Requirements The selection of backup and recovery strategies are driven by quality and business guidelines. The quality of backup and recovery strategies are [3]: Consistency: The scripts or programs used to conduct all kinds of physical backups and full exports must be identical for all databases and servers, to keep the learning curve for new administrators low. Reliability: Backups from which one can not recover are useless. therefore backup should be automated and monitored to keep the possibility of errors low and to bring them to attention immediately. page 96 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Extensibility/scalability: Extensibility describes the ability to include new servers and/or databases into the backup schedule easily. Support of heterogeneous environments: Backup should be able to handle a variety of platforms, operating systems and tape libraries. Usability: To keep the resource cost of backup strategies low, they have to be easy to use and to learn. There are also some important guidelines: 3.2.2 Speed: The speed of backup depends on the speed of tape, network, and/or disk on which the backup is dependent and on the software performing the backup. Application load: Backups of large databases could place a noticeable load on the server where the database resides, therefore peak transaction periods should be avoided. Resources for periodically testing of backups and restores personnel and hardware resources have to be included in the backup plans. Business requirements determine availability requirements for an application and database. Business requirements also determine database size, which in conjunction with hardware/software configuration, determines restoration time. Restoration time: The hardware and software configuration determines the restoration time. Characteristics Backup strategies differ along the following characteristics: 4 Locality: backups can be located on the server where the database resides or can be executed on a remote server over a network. Storage media. Toolset: To automate the backup strategies system based tools can be written or commercial tools can be used. Database size: Very large database strategies tend to be problematic in terms of backup or recovery time. It takes hours with most types of disk or tape subsystems to backup and restore. Availability requirements: Some applications/systems have to be available 24 hours a day, 7 days a week others less. Applications which have very high availability requirements have no window for cold physical backups. Online/hot backups are more complicated. Life cycle: Depending o the importance of the data backup and recovery strategies can be differentiated by production, development or test environment. Overview of commercial products As a result, the DBA has an extensive set of requirements for the tools and facilities offered by the DBMS. These include facilities to back up an entire database offline, facilities to back up parts of the database selectively, features to take a snapshot of the 1999 EURESCOM Participants in Project P817-PF page 97 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 database at a particular moment, and obviously journaling facilities to roll back or roll forward the transactions applied to the database to a particular identified time. Some of these facilities must be used online -- that is, while the users are busy accessing the database. For each backup mechanism, there must be a corresponding restore mechanism -- these mechanisms should be efficient. The backup and restore facilities should be configurable -- e.g. to stream the backup data to and from multiple devices in parallel, to add compression and decompression (including using third-party compression tools, to delete old backups automatically off the disk, or to label the tapes according to ones own standards. One should also be able to take the backup of a database from one platform and restore it on another -- this step is necessary to cater for non-database-related problems, such as machine and operating system failures. For each facility, one should be able to monitor its progress and receive an acknowledgement that each task has been completed successfully. There exist two kinds of tools used to perform backups: the facilities offered by each DBMS and the generally applicable tools which can be used with more than one (ideally all) commercial DBMSs. 4.1 Tools 4.1.1 PC-oriented backup packages None of these tools come with tape support built in, so it is necessary to have some third party software to work with tapes. Here is a set of the most commonly used tools to perform backups oriented towards PC servers: 4.1.2 Arcada Software - Storage Exec. Avail Cheyenne Software - ArcServe Conner Storage Systems - Backup Exec Emerald Systems - Xpress Librarian Fortunet - NSure NLM/AllNet Hewlett Packard - Omniback II IBM - ADSM (Adstar Distributed Storage Manager) Legato - Networker Mountain Network Solutions - FileSafe NovaStor Palindrome - Network Archivist Palindrome - Backup Director Performance Technology - PowerSave Systems Enhancement - Total Network Recall UNIX packages Among the tools available in the Unix world, the following can be found: page 98 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 4.1.2.1 Volume 3: Annex 2 - Data manipulation and management issues APUnix - FarTool Cheyenne - ArcServe Dallastone - D-Tools Delta MycroSystems (PDC) - BudTool Epoch Systems - Enterprise Backup IBM - ADSM (ADSTAR Distributed Storage Manager) Hewlett Packard - Omniback II Legato - Networker Network Imaging Systems Open Vision - AXXion Netbackup Software Moguls - SM-arch Spectra Logic - Alexandria Workstation Solutions Example: IBM's ADSM In the next lines, the main features of IBM’s ADSM will be presented in order to illustrate with an example the functionality of these tools. Provides unattended, backups, long-term data archives and Hierarchical Storage Management (HSM) operations. Supports a wide range of hardware platforms. Administrator capabilities to manage the ADSM server from any ADSM client platform. Easy-to-use Web-browser and Graphical User Interfaces (GUIs) for daily administrative and user tasks. Extensive storage device support. Disaster recovery features allowing multiple file copies onsite or offsite. Optional compression to reduce network traffic, transmission time and server storage requirements. HSM capability to automatically move infrequently used data from workstations and file servers onto an ADSM storage management server, reducing expensive workstation and file server storage upgrades and providing fast access to data. Provides a Disaster Recovery Manager (DRM) feature to help plan, prepare and execute a disaster recover plan. Multitasking capability. Online and offline database backup and archive support. Security capabilities. 1999 EURESCOM Participants in Project P817-PF page 99 (120) Volume 3: Annex 2 - Data manipulation and management issues 4.2 Deliverable 1 Databases In this section the tools and facilities offered by IBM, Informix, Microsoft, Oracle, and Sybase for backup and recovery will be presented. 4.2.1 IBM DB2 IBM's DB2 release 2.1.1 provides two facilities to back up your databases, namely the BACKUP command and the Database Director. It provides three methods to recover your database: crash recovery, restore, and roll-forward. Backups can be performed either online or offline. Online backups are only supported if roll-forward recovery is enabled for the specific database. To execute the BACKUP command, you need SYSADM, SYSCTRL, or SYSMAINT authority. A database or a tablespace can be backed up to a fixed disk or tape. A tablespace backup and a tablespace restore cannot be run at the same time, even if they are working on different tablespaces. The backup command provides concurrency control for multiple processes making backup copies of different databases at the same time. The restore and roll-forward methods provide different types of recovery. The restoreonly recovery method makes use of an offline, full backup copy of the database; therefore, the restored database is only as current as the last backup. The roll-forward recovery method makes use of database changes retained in logs -- therefore it entails performing a restore database (or tablespaces) using the BACKUP command, then applying the changes in the logs since the last backup. You can only do this when rollforward recovery is enabled. With full database roll-forward recovery, you can specify a date and time in the processing history to which to recover. Crash recovery protects the database from being left in an inconsistent state. When transactions against the database are unexpectedly interrupted, you must perform a rollback of the incomplete and in-doubt transactions, as well as the completed transactions that are still in memory. To do this, you use the RESTART DATABASE command. If you have specified the AUTORESTART parameter, a RESTART DATABASE is performed automatically after each failure. If a media error occurs during recovery, the recovery will continue, and the erroneous tablespace is taken offline and placed in a roll-forward pending state. The offline tablespace will need additional fixing up -- restore and/or roll-forward recovery, depending on the mode of the database (whether it is recoverable or non-recoverable). Restore recovery, also known as version control, lets you restore a previous version of a database made using the BACKUP command. Consider the following two scenarios: A database restore will rebuild the entire database using a backup made earlier, thus restoring the database to the identical state when the backup was made. A tablespace restore is made from a backup image, which was created using the BACKUP command where only one or more tablespaces were specified to be backed up. Therefore this process only restores the selected tablespaces to the state they were in when the backup was taken; it leaves the unselected tablespaces in a different state. A tablespace restore can be done online (shared mode) or offline (exclusive mode). Roll-forward recovery may be the next task after a restore, depending on your database's state. There are two scenarios to consider: page 100 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 4.2.2 Volume 3: Annex 2 - Data manipulation and management issues Database roll-forward recovery is performed to restore the database by applying the database logs. The database logs record all of the changes made to the database. On completion of this recovery method, the database will return to its prefailure state. A backup image of the database and archives of the logs are needed to use this method. Tablespace roll-forward can be done in two ways: either by using the ROLLFORWARD command to apply the logs against the tablespaces in a rollforward pending state, or by performing a tablespace restore and roll-forward recovery, followed by a ROLLFORWARD operation to apply the logs. Informix Informix for Windows NT release 7.12 has a Storage Manager Setup tool and a Backup and Restore tool. These tools let you perform complete or incremental backups of your data, back up logical log files (continuous and manual), restore data from a backup device, and specify the backup device. Informix has a Backup and Restore wizard to help you with your backup and restore operations. This wizard is only available on the server machine. The Backup and Restore wizard provides three options: Backup, Logical Log Backup, and Restore. The Backup and Restore tool provides two types of backups: complete and incremental. A complete backup backs up all of the data for the selected database server. A complete backup -- also known as a level-0 backup -- is required before you can do an incremental backup. An incremental backup -- also known as a level-1 backup -- backs up all changes that have occurred since the last complete backup, thereby requiring less time because only part of the data from the selected database server is backed up. You also get a level-2 backup, performed using the command-line utilities, that is used to back up all of the changes that have occurred since the last incremental backup. The Backup and Restore tool provides two types of logical log backups: continuous backup of the logical logs and manual backup of the logical logs. A Logical Log Backup backs up all full and used logical log files for a database server. The logical log files are used to store records of the online activity that occurs between complete backups. The Informix Storage Manager (ISM) Setup tool lets you specify the storage device for storing the data used for complete, incremental, and logical log backups. The storage device can be a tape drive, a fixed hard drive, a removable hard drive, or none (for example, the null device). It is only available on the server machine. You can select one backup device for your general backups (complete or incremental) and a separate device for your logical log backups. You always have to move the backup file to another location or rename the file before starting your next backup. Before restoring your data, you must move the backup file to the directory specified in the ISM Setup and rename the backup file to the filename specified in ISM Setup. If you specify None as your logical log storage device, the application marks the logical log files as backed up as soon as they become full, effectively discarding logical log information. Specify None only if you do not need to recover transactions from the logical log. When doing a backup, the server must be online or in administration mode. Once the backup has started, changing the mode will terminate the backup process. When backing up to your hard drive, the backup file will be created automatically. 1999 EURESCOM Participants in Project P817-PF page 101 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 The Restore option of the Backup and Restore wizard restores the data and logical log files from a backup source. You cannot restore the data if you have not made a complete backup. The server must be in offline mode during the restore operation. You can back up your active logical log files before doing the restore, and you can also specify which log files must be used. A level-1 (incremental) backup can be restored, but you will be prompted to proceed with a level-2 backup at the completion of the level-1 restore. Once the restore is completed, the database server can be brought back online, and processing can continue as usual. If you click on Cancel during a restore procedure, the resulting data may be corrupted. 4.2.3 Microsoft SQL Server Microsoft SQL Server 6.5 provides more than one backup and recovery mechanism. For backups of the database, the user can either use the Bulk Copy Program (BCP) from the command line to create flat-file backups of individual tables or the built-in Transact-SQL DUMP and LOAD statements to back up or restore the entire database or specific tables within the database. Although the necessary Transact-SQL statements are available from within the SQL environment, the Microsoft SQL Enterprise Manager provides a much more userfriendly interface for making backups and recovering them later on. The Enterprise Manager will prompt the DBA for information such as database name, backup device to use, whether to initialize the device, and whether the backup must be scheduled for later or done immediately. Alternatively, you can use the Database Maintenance wizard to automate the whole maintenance process, including the backup procedures. These tasks are automatically scheduled by the wizard on a daily or weekly basis. Both the BCP utility and the dump statement can be run online, which means that users do not have to be interrupted while backups are being made. This facility is particularly valuable in 24 X 7 operations. A database can be restored up to the last committed transaction by also LOADing the transaction logs that were dumped since the previous database DUMP. Some of the LOAD options involve more management. For example, the database dump file and all subsequent transaction-log dump files must be kept until the last minute in case recovery is required. It is up to the particular site to determine a suitable backup and recovery policy, given the available options. To protect against hardware failures, Microsoft SQL Server 6.5 has the built-in capability to define a standby server for automatic failover. This option requires sophisticated hardware but is good to consider for 24 X 7 operations. Once configured, it does not require any additional tasks on an ongoing basis. In addition, separate backups of the database are still required in case of data loss or multiple media failure. 4.2.4 Oracle 7 Oracle 7 Release 7.3 uses full and partial database backups and a redo log for its database backup and recovery operations. The database backup is an operating system backup of the physical files that constitute the Oracle database. The redo log consists of two or more preallocated files, which are used to record all changes made to the database. You can also use the export and import utilities to create a backup of a database. Oracle offers a standby database scheme, with which it maintains a copy of page 102 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues a primary database on duplicate hardware, in a constant recoverable state, by applying the redo logs archived off the primary database. A full backup is an operating system backup of all of the data files, parameter files, and the control file that constitute the database. A full database backup can be taken by using the operating system's commands or by using the host command of the Server Manager. A full database backup can be taken online when the database is open, but only an offline database backup (taken when the database server is shut down) will necessarily be consistent. An inconsistent database backup must be recovered with the online and archived redo log files before the database will become available. The best approach is to take a full database backup after the database has been shut down with normal or immediate priority. A partial backup is any operating system backup of a part of the full backup, such as selected data files, the control file only, or the data files in a specified tablespace only. A partial backup is useful if the database is operated in ARCHIVELOG mode. A database operating in NOARCHIVE mode rarely has sufficient information to use a partial backup to restore the database to a consistent state. The archiving mode is usually set during database creation, but it can be reset at a later stage. You can recover a database damaged by a media failure in one of three ways after you have restored backups of the damaged data files. These steps can be performed using the Server Manager's Apply Recovery Archives dialog box, using the Server Manager's RECOVER command, or using the SQL ALTER DATABASE command: You can recover an entire database using the RECOVER DATABASE command. This command performs media recovery on all of the data files that require redo processing. You can recover specified tablespaces using the RECOVER TABLESPACE command. This command performs media recovery on all of the data files in the listed tablespaces. Oracle requires the database to be open and mounted in order to determine the file names of the tables contained in the tablespace. You can list the individual files to be recovered using the RECOVER DATAFILE command. The database can be open or closed, provided that Oracle can take the required media recovery locks. In certain situations, you can also recover a specific damaged data file, even if a backup file isn't available. This can only be done if all of the required log files are available and the control file contains the name of the damaged file. In addition, Oracle provides a variety of recovery options for different crash scenarios, including incomplete recovery, change-based, cancel-based, and time-based recovery, and recovery from user errors. 4.2.5 Oracle 8 Oracle 8 offers to the DBA three possibilities for performing backups: Recovery Manager. Operating System. Export. 1999 EURESCOM Participants in Project P817-PF page 103 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Backup Method Version Available Requirements Recovery Manager Oracle8 Media Manager (if backing up to tape) Operating System All versions of Oracle O/S backup utility (for example UNIX dd) Export All versions of Oracle N/A Table 1. Requirements for different backup methods Summarizing here comes a table wich compares the features of the methods above described. Feature closed database backups open database backups Recovery Manager Supported. Requires instance to be mounted. Not use BEGIN/END BACKUP commands. incremental backups Supported. Backs up all modified blocks. corrupt block detection Supported. Identifies corrupt blocks and writes to V$BACKUP_CORRUP TION or V$COPY_CORRUPTI ON. Supported. Establishes the name and locations of all files to be backed up (whole database, tablespace, datafile or control file backup). Supported. Backups are cataloged to the recovery catalog and to the control file, or just to the control file. Supported. Interfaces with a Media Manager. automatically backs up data catalogs backup performed makes backups to tape backs up init.ora and password files Operating System independent language Not supported. An O/S independent scripting language. Operating System Export Supported. Not supported. Generates more redo when using BEGIN/END BACKUP commands Not supported. Not supported. Requires RBS to generate consistent backups. Supported, but not a true incremental, as it backs up a whole table even if only one block is modified. Supported. Identifies corrupt blocks in the export log. Not supported. Supported. Performes Files to be backed either full, user or table up must be backups. specified manually. Not supported. Not supported. Supported. Backup Supported. to tape is manual or managed by a Media Manager Supported. Not supported. O/S dependent. O/S independent scripting language. Table 2. Feature comparison of backup methods page 104 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 4.2.6 Volume 3: Annex 2 - Data manipulation and management issues Sybase SQL Server Sybase SQL Server 11 uses database dumps, transaction dumps, checkpoints, and a transaction log per database for database recovery. All backup and restore operations are performed by an Open Server program called Backup Server, which runs on the same physical machine as the Sybase SQL Server 11 process. A database dump is a complete copy of the database, including the data files and the transaction log. This function is performed using the DUMP DATABASE operation, which can place the backup on tape or on disk. You can make dynamic dumps, which let the users continue using the database while the dump is being made. A transaction dump is a routine backup of the transaction log. The DUMP TRANSACTION operation also truncates the inactive portion of the transaction log file. You can use multiple devices in the DUMP DATABASE and DUMP TRANSACTION operations to stripe the dumps across multiple devices. The transaction log is a write-ahead log, maintained in the system table called syslogs. You can use the DUMP TRANSACTION command to copy the information from the transaction log to a tape or disk. You can use the automatic checkpointing task or the CHECKPOINT command (issued manually) to synchronize a database with its transaction log. Doing so causes the database pages that are modified in memory to be flushed to the disk. Regular checkpoints can shorten the recovery time after a system crash. Each time Sybase SQL Server restarts, it automatically checks each database for transactions requiring recovery by comparing the transaction log with the actual data pages on the disk. If the log records are more recent than the data page, it reapplies the changes from the transaction log. An entire database can be restored from a database dump using the LOAD DATABASE command. Once you have restored the database to a usable state, you can use the LOAD TRANSACTION command to load all transaction log dumps, in the order in which they were created. This process reconstructs the database by reexecuting the transactions recorded in the transaction log. You can use the DUMP DATABASE and LOAD DATABASE operations to port a database from one Sybase installation to another, as long as they run on similar hardware and software platforms. 5 Analysis and recommendations Although each DBMS that has been treated, has a range of backup and recovery facilities, it is always important to ensure that the facilities are used properly and adequately. "Adequately" means that backups must be taken regularly. All of the treated DBMSs provided the facilities to repost or re-execute completed transactions from a log or journal file. However, reposting or re-executing a few weeks worth of transactions may take an unbearably long time. In many situations, users require quick access to their databases, even in the presence of media failures. Remember that the end users are not concerned with physical technicalities, such as restoring a database after a system crash. Even better than quick recovery is no recovery, which can be achieved in two ways. First, by performing adequate system monitoring and using proper procedures and good equipment, most system crashes can be avoided. It is better to provide users with 1999 EURESCOM Participants in Project P817-PF page 105 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 a system that is up and available 90 percent of the time than to have to do sporadic fixes when problems occur. Second, by using redundant databases such as hot standby or replicated databases, users can be relieved of the recovery delays: Users can be switched to the hot backup database while the master database is being recovered. A last but extremely important aspect of backup and recovery is testing. Test your backup and recovery procedures in a test environment before deploying them in the production environment. In addition, the backup and recovery procedures and facilities used in the production environment must also be tested regularly. A recovery scheme that worked perfectly well in a test environment is useless if it cannot be repeated in the production environment -- particularly in that crucial moment when the root disk fails during the month-end run! References [1] Oracle Consulting, Backup/Recovery Template, Berlin, 1996 [2] Theo Saleck, Datenbanken für sehr große Datenmengen: Nicht nur eine technische Herausforderung. "Datenbank Fokus", Februar 1998, Volume 2, pp 36-43. [3] Derek Ashmore, Backing up the Oracle Enterprise. "DBMS Online"., Update April 3, 1998 page 106 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Appendix A: Backup and Restore Investigation of Terabytescale Databases A Proof of Concept featuring Digital AlphaServers, Storage Tek Redwood Tape Drives, Oracle's Enterprise Backup Utility (EBU) and Spectra Logic's Alexandria Backup Librarian. October 30, 1996 A.1 Introduction Databases and database applications continue to grow exponentially. Document imaging, data warehousing and data mining, and massive On-Line Transaction Processing (OLTP) systems are constantly adding to the demand for increased database performance and size. Advances in server and I/O technology also contribute to the viability of Very Large Databases (VLDBs). In the past, however, Database administrators (DBAs) have not had the methods, tools and available hours to accomplish backups. They cannot bring down a database long enough to back it up. With earlier backup tools, some sites were unable to accomplish a "hot" (on-line) backup in 24 hours, during which users were forced to accept substantial performance degradation. A.2 Requirements For Terabyte-scale VLDBs to become truly viable, there must be tools and methods to back them up. While certain features and functionality will be advantageous to certain sites, a sine qua non list of DBA requirements would certainly include: A.3 Hot backup capability: 24 x 7 access to applications and world-wide access to OLTP preclude many sites from bringing the database off-line at all for routine maintenance or backup. Performance and the ability to scale: sites must be able to accomplish backups in short time intervals with the addition of more and faster tape drives -- the backup software or utilities must not be a bottleneck. Low CPU utilisation: during the backup, the system cannot devote a large portion of system resources to backup; CPU bandwidth must be available to the RDBMS applications and any other tasks (reports, etc.) that must be accomplished in the background. Support for a wide range of hardware platforms, operating systems and backup devices: applications are running on a variety of these platforms in different environments, the software should not limit choices. Accurate benchmarking With more mature tools on the market for VLDB backup, it has become difficult to prove which products can meet the requirements outlined above. There are many bottlenecks to consider and it is dangerous to extrapolate. Backup to a single tape drive at 1 MB/sec does not guarantee that you can back up to a thousand tape drives at 1000 MB/sec. 1999 EURESCOM Participants in Project P817-PF page 107 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 The only way to truly find the limits of backup performance is to do it empirically hook up all the hardware, load the software and run real life tests. While this is accurate, it is time consuming and expensive to achieve the numbers described in this paper. Spectra Logic was able to partner with Digital Equipment Corporation to bring this demonstration to fruition. Digital, with partners Storage Technology Corporation and Oracle, provided millions of dollars worth of hardware to test Oracle's EBU backup utility with Spectra Logic's Alexandria Backup Librarian. A.4 The benchmark environment At Digital's Palo Alto Database Technology Center, the following was available for the test: Digital AlphaServer 8400 (Turbo Laser) Server: eight 300MHz Alpha processors, 8 GB system memory, one TLIOP I/O channel, 30 KZPSA F/W SCSI Controllers, Digital UNIX 64-bit OS (v4.0a). Storage Technology Corporation (STK): 16 Redwood SD-3 Drives. NOTE: Although 16 tape drives were available for the testing, only 15 were used for the hot backups. This was considered a better match for the database structure and the number of disk drives available for source data. This allowed 14 drives to interleave data from four disks each and one to interleave from three. If the database were spread across 64 disks, (4 per tape drive) the benchmarks could have made use of all 16 tape drives. Oracle 7.2.2 database and Oracle EBU v2.0 184 GB of data on 59 SCSI disk drives 15 tablespaces: 14 tablespaces of 4 disk each 1 tablespace of 3 disks 59 Tables, one (3.1 GB).per disk 59 Indexes, one (0.7 GB) per disk 26,000,000 rows per table; 1,534,000,000 rows total. page 108 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Table Data Structure: L_ORDERKEY NUMBER(10) L_PARTKEY NUMBER(10) L_SUPPKEY NUMBER(10) L_LINENUMBER NUMBER(10) L_QUANTITY NUMBER(10) L_EXTENDEDPRICE NUMBER L_DISCOUNT NUMBER(10) L_TAX NUMBER(10) L_RETURNFLAG CHAR(1) L_LINESTATUS CHAR(1) L_SHIPDATE DATE L_COMMITDATE DATE L_RECEIPTDATE DATE L_SHIPINSTRUCT VARCHAR2(25) L_SHIPMODE VARCHAR2(10) L_COMMENT VARCHAR2(27) The 8400 Server can accept up to three TLIOPs (Turbo Laser Input Output Processors), each with four PCI busses allowing the system to scale beyond the numbers achieved. Enough hardware was available, however, to saturate the single channel and demonstrate impressive transfer capabilities. Three backup methods were chosen for comparison: a hot backup using Oracle's EBU, a cold backup of raw disk using Alexandria's Raw Partition Formatter (RPF), and a hot backup using Spectra Logic's Comprehensive Oracle Backup and Recovery Agent (COBRA). No compression was used in the benchmarks. The compressibility of data varies with the data itself, making it difficult to reproduce or compare different benchmarks. All of the numbers in this document were achieved with native transfer. A.5 Results A.5.1 Executive summary Spectra Logic's Alexandria achieved impressive throughput and CPU figures in all three tests. Sustained transfer rates were similar in each of the tests, implying that I/O limitations of the hardware were being approached. During the testing, close to 8090% of theoretical maximum was achieved; allowing for system overhead, arbitration and I/O waits, this is close to a realistic maximum. Both wall clock rates and sustained transfer were measured. The wall clock rate is computed from the elapsed time to complete the backup from start to finish. The 1999 EURESCOM Participants in Project P817-PF page 109 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 sustained transfer is the throughput when the system is running - the actual processor time not accounting for media selection, mounting or any backup overhead. The sustained transfer rate is, however, a valid predictor of how much additional time would be added or subtracted from the backup window if more or less data were backed up. Cold Backup: 542 GB/hour at 3% CPU Utilisation For the cold backup testing, the disks containing the Oracle data were written to tape using Alexandria's high performance RPF format. A total of 236 GB was written to 15 drives in 29 minutes: TOTALS: Max Xfer 542 GB/hour Wall clock 236 GB / 29 minutes (.483 hours) = 488 GB/hour CPU utilisation < 3% Hot Backup using Spectra Logic's COBRA: 525 GB/hour at 4% CPU Utilization Spectra Logic has been shipping a hot backup product for Oracle for over a year. The COBRA agent uses SQL commands to place individual tablespaces in backup mode and coordinates with Alexandria to back up their datafiles. This method also uses Alexandria's high performance RPF format. A total of 236 GB was written to 16 drives in 30 minutes: TOTALS: Max Xfer 525 GB/hour Wall Clock 236 GB / 30 minutes (.5 hours) = 472 GB/hour CPU utilisation < 4% Hot Backup Using Oracle's EBU: 505 GB/hour at 9.5% CPU Utilisation The Enterprise Backup Utility is provided by and supported by Oracle for on-line backup of Oracle databases. EBU is not a stand-alone product but rather an API which gives third-party developers a standard access method for database backup and retrieval. Coupled with Alexandria's media management and scheduling capabilities it provides a robust, high-performance backup method. For the EBU backup testing, a total of 184 GB was written to 15 drives in 29:17. TOTALS: Max Xfer 05.5 GB/hour Wall clock 184 GB / 29:17 (.49 hours) = 375 GB/hour CPU utilisation 9.5 % Hot Backup With Transaction Load: 477 GB/hour at 16% CPU Utilisation As the purpose of hot backup is to allow for database access during backup, one of the tests was to perform a full backup with a light transaction load (118 updates per second) on the system. page 110 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Performing a hot, EBU backup with this transaction load, a total of 184 GB was written to 15 drives in 38:03. TOTALS: Max Xfer 477.4 GB/hour Wall clock 184 GB / 38:03 (.63 hours) = 291 GB/hour CPU utilisation 16.3 % Hot Restore Using Oracle's EBU To preserve the integrity of the test system and to provide a means of verifying restores, it was decided not to write over the original datafiles. Rather, restores were directed toward other disks on the system. The maximum number of concurrent restores that were practical in this environment was 12 tapes at a time. To check the ability to scale, restore tests were run with one, two, four and 12 concurrent restores. A.5.2 TAPE DRIVES SUSTAINED THROUGHPUT CPU UTILIZATION 1 40.28 GB/hour %3 2 78.05 GB/hour %4 4 140.73 GB/Hour %6 12 382.75 GB/Hour % 30 Detailed results Spectra Logic's Alexandria achieved impressive throughput and CPU figures in all three tests. Sustained transfer rates were similar in each of the tests, implying that I/O limitations of the hardware were being approached. During the testing, close to 8090% of theoretical maximum was achieved; allowing for system overhead, arbitration and I/O waits, this is close to a realistic maximum. Cold Backup: 542 GB/hour For the cold backup testing, 16 stores were launched by Alexandria, each one to a single tape drive. Each store backed up multiple physical disks. A total of 236 GB was written to the 16 drives in 28.4 minutes at a CPU utilisation of less than 3%. Table 1 shows the statistics for each store operation in both wall clock rate (from the launch of the entire operation to the completion of the store) and processor rate (from the launch of the store process to its completion). The process rate does not account for media selection, software latency or any system time to start the store operation. 1999 EURESCOM Participants in Project P817-PF page 111 (120) Volume 3: Annex 2 - Data manipulation and management issues SIZE AND WALL CLOCK RATE PROCESS CLOCK RATE 10,477,371,392 bytes 1412 sec 7246.32 kb/s 1267 sec 8075.62 kb/s 13,969,129,472 bytes 1418 sec 9620.40 kb/s 1264 sec 10792.51 kb/s 13,969,129,472 bytes 1438 sec 9486.60 kb/s 1281 sec 10649.28 kb/s 13,969,129,472 bytes 1420 sec 9606.85 kb/s 1274 sec 10707.79 kb/s 13,969,129,472 bytes 1414 sec 9647.62 kb/s 1265 sec 10783.97 kb/s 13,969,129,472 bytes 1418 sec 9620.40 kb/s 1270 sec 10741.52 kb/s 13,969,129,472 bytes 1433 sec 9519.70 kb/s 1278 sec 10674.28 kb/s 13,969,129,472 bytes 1410 sec 9674.98 kb/s 1305 sec 10453.43 kb/s 13,969,129,472 bytes 1397 sec 9765.02 kb/s 1310 sec 10413.53 kb/s 13,969,129,472 bytes 1413 sec 9654.44 kb/s 1263 sec 10801.05 kb/s 13,969,129,472 bytes 1415 sec 9640.80 kb/s 1268 sec 10758.46 kb/s 13,969,129,472 bytes 1411 sec 9668.13 kb/s 1264 sec 10792.51 kb/s 13,969,129,472 bytes 1419 sec 9613.62 kb/s 1264 sec 10792.51 kb/s 13,969,129,472 bytes 1414 sec 9647.62 kb/s 1266 sec 10775.46 kb/s 13,969,129,472 bytes 1407 sec 9695.61 kb/s 1266 sec 10775.46 kb/s Total Deliverable 1 206,045,184,000 bytes 142108.10 kb/s 157987.37 kb/s CPU 2-3% Hot Backup Using Oracle's EBU: 505 GB/hour For the EBU backup testing, a total of 184 GB was written to 15 drives in 29:17 at a CPU utilisation of 9.5%. The following chart shows a chronological report of transfer rate as different store operations were launched. Note that the 505GB/hour maximum transfer rate was sustained for 18:07 -- more than half the store. It is irresistible to extrapolate these figures and ask "How much throughput could be achieved with more hardware?" The sign of stress in the system will be evidenced by the linearity of the system's ability to scale. For this reason, tests were run with one, two, four, eight and 15 tape drives. Up through 15 drives, numbers were almost completely linear. The other factor germane to scalability is CPU utilization. During the actual data transfer, CPU usage was between 9-10%. A short peak to 18% reflects Alexandria's overhead to select media and update its internal database. Hot Backup with Transaction Load: 477 GB/hour Using Oracle's EBU for a hot backup with a light transaction load on the database (118 transactions per second), a total of 184 GB was written to 15 drives in 38:03 at a CPU utilisation of 16.3%. page 112 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Hot Restore Using Oracle's EBU To preserve the integrity of the test system and to provide a means of verifying restores, it was decided not to write over the original datafiles. Rather, the restores were directed toward other disks on the system. The maximum number of concurrent restores that were practical in this environment was 12 at a time. Of all the tests, hot restores were the most demanding in CPU and system resource utilization. It is interesting, therefore to check the ability to scale when using one, two, four and 12 drives. Again, the data through 12 drives is almost completely linear. A.6 TAPE DRIVES SUSTAINED THROUGHPUT CPU UTILIZATION 1 40.28 GB/hour %3 2 78.05 GB/hour %4 4 140.73 GB/Hour %6 12 382.75 GB/Hour % 30 Interpreting the results The total throughput numbers for all the tests are impressive: a Terabyte database can be backed up in about two-three hours. Just as important, however, is the CPU utilisation. The reason for a hot backup is to allow access to the database during the backup. If a large portion of the CPU is devoted to backup tasks, the users will see severe performance degradation. By taking less than 10%, Alexandria/EBU is leaving most of the bandwidth available to other applications. Another consideration is the application's ability to scale. If 505GB/hour is required today, next year will the requirement be 1 TB/hour? If this benchmark configuration were a production system, the user could add one or two more TLIOP processors, additional tape drives and be confident of scaling well beyond 505 GB/hour. Again, extrapolating is dangerous but it is obvious that at less than 10%, there is ample headroom to support more hardware-without taking all the system resources. The linearity of the scaling throughout the demonstration also suggests that both the Alexandria application and the EBU utility are capable of even faster benchmarks. Quite likely the ultimate limitation here was the number of disk drives available for simultaneous read. To use substantively more than the 59 disks, however, would have necessitated an additional TLIOP I/O channel and perhaps more tape drives. All in all every component in this demonstration proved its ability to scale. A.7 Summary This demonstration was important-not only to Spectra Logic-but also to all the vendors involved. The Digital 8400 AlphaServers and 64-bit Digital UNIX showed amazing throughput. The TLIOP provides I/O which is not bound by backplane limitations and as the numbers attest, the I/O operates very near its theoretical maximum with 30 SCSI busses and over a hundred separate devices attached. Likewise, the StorageTek Redwood tape drives performed magnificently. In weeks of full throttle testing by multiple software vendors, the drives proved robust and fast. 1999 EURESCOM Participants in Project P817-PF page 113 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 Lastly, Oracle's EBU demonstrates the firm's commitment to supporting and managing VLDBs. EBU scaled well with minimal CPU utilization, proving that these vendors are ready to manage and support the databases of tomorrow. RDBMS usage will continue to grow in size and in applications. Developers and Information Service professionals can now rest assured that the huge databases can be managed and protected. page 114 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Appendix B: True Terabyte Database Backup Demonstration A Proof of Concept for backing up a one terabyte database in a one hour timeframe featuring Silicon Graphics(r) Origin2000 S2MP(tm) Server, IBM Magstar(tm) 3590 ACF Tape Libraries, Oracle's Enterprise Backup Utility (EBU(tm)) and Spectra Logic Corporation's Alexandria(tm) Backup and Archival Librarian. B.1 Executive Summary This whitepaper describes the results of a performance demonstration where Silicon Graphics and Spectra Logic partnered for the enterprise industry's first successful true Terabyte database backup demonstration. The demonstration was a proof of concept for backing up a 1-Terabyte Oracle7 database in approximately one hour using a Silicon Graphics® Origin2000 S2MP™ Server, IBM Magstar™ 3590 with ACF (Automatic Cartridge Facility), Oracle's Enterprise Backup Utility (EBU™) and Spectra Logic Corporation's Alexandria™ Backup and Archival Librarian software. The results of this demonstration are as follows: TEST Sustained Throughput Wall-Clock Throughput Total System Overhead (TB/Hour) (GB/Hour) Cold 1.5 1,237 6% overhead (94% of the system still available) Hot Backup 1.3 985 6% overhead (94% of the system still available) Hot Backup with load (4500tpm) 1.1 901 21% overhead (79% of the system still available) Fast growing multi-gigabyte and multi-terabyte enterprise sites looking for highperformance solutions should note the following demonstration results: All the tests were run on an actual 1.0265 Terabyte Oracle7 database. No extrapolation was used for the wall-clock throughput rates. The hot backup left 94% of the system still available for user processes. This removes the need to quiesce databases during the backup. The hot backup was successfully completed in approximately one wall-clock hour, including tape exchanges. Shrinking backup windows on 24x7 systems can now be addressed with a proven, real-time solution. The demonstration distinctly shows scalability. There was plenty of I/O left for growth in additional data processing, CPUs, memory, tape drives, and disk drives. All of the products used in the demonstration are commercially available today. For the true terabyte performance demonstration, Silicon Graphics and Spectra Logic performed three tests: a cold backup, a hot backup and a hot backup with transaction load. 1999 EURESCOM Participants in Project P817-PF page 115 (120) Volume 3: Annex 2 - Data manipulation and management issues B.1.1 B.2 Deliverable 1 Definitions Cold Backup. The database is offline during the backup and not available to end-users. Hot Backup. The database remains available to end-users during the backup. System. The system consists of the server (nodes, backplane, etc.), the disks, the Oracle database, the operating system, the backup software, the SCSI busses and the tape drives. Total System Overhead. Total system overhead includes CPU utilization generated by the operating system, the relational database management system (RDBMS) and the backup software, and is an average taken for the duration of the backup. Total System Throughput. Total system throughput is the total amount of data written to the tape drives during the duration of the backup divided by the system time required to complete the backup. Total system overhead and total system throughput are inseparable numbers that directly influence system scalability. Detailed Results This section includes descriptions and graphs explaining the performance results in detail. The database used was the same for all three tests - a 1.0265 Terabyte Database using Oracle7. The data used to derive the charts was captured using Silicon Graphics' System Activity Reporter, or SAR. B.2.1 Demonstration Environment The demonstration took place at Silicon Graphics headquarters in Mountain View, California using following hardware and software: The Server. Silicon Graphics Inc. Origin2000 S2MP Server running IRIX 6.4: 16 MIPS RISC R10000 64-bit CPUs on 8 boards on 2 Origin2000 modules. The modules were connected via a CrayLink(tm) Interconnect. 5 Gigabytes memory. Each node card has up to 700 MB/sec sustained memory bandwidth. 20 XIO slots were available for SCSI. Since each XIO slot can accommodate 4 SCSI channels, this means a total of 80 UltraSCSI channels could be used. The Database. Oracle 7.3.2.3 database and Oracle Enterprise Backup Utility (EBU) v2.1: Database size - 1.0265 TB. 138, 9 Gigabyte disks, housed in 3 rackmountable Origin Vaults. The 2 internal SCSI drive bays had a total of 10 single-ended disks enclosed in them (5 per bay) but these were not used for the test database. One of them was the system disk. Each rackmountable disk enclosure had one SCSI channel. 18 enclosures had the full 6 disk complement. 6 enclosures had 4 disks. 2 enclosures had 3 disks. page 116 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues Database data was striped and consisted of 193 data files in a TPC-C schema database for transactions. 80% of the database was populated. The Drives. IBM Magstar 3590 Tape Subsystem with ACF (Automatic Cartridge Facility): 38 drives were available for the cold backup. 35 drives were available for the hot backups Each 3590 used a separate SCSI channel. The Backup Software. Spectra Logic Corporation's Alexandria v3.7 and Alexandria's Oracle Backup Agent: Alexandria exhibits high-performance and scalability across multiple platforms and storage library systems. Miscellaneous. B.2.2 The demonstration configuration used a total of 64 SCSI channels including disks and tape drives. Since each XIO slot can accommodate 4 SCSI channels, this means that only 16 XIO slots out of 20 were used. This is important for hardware scalability because there were still 16 SCSI channels available for additional headroom and expansion, without adding another Origin module. Two backup methods were used: the hot backups used Oracle's EBU, and the cold backup was performed on raw disk using Alexandria's Raw Partition Formatter (RPF). No software compression was used, however hardware compression was enabled on the tape drives. Tape exchanges produced visible troughs on the throughput curve. This is related to the load/unload times staggering slightly for various reasons, such as the amount of data that was streamed to that particular drive. Certain CPU spikes may be related to file finds, UNIX kernal and EBU processes. Results Cold Backup at 1,237 GB/hour with 38 drives The cold backup was performed with 38 IBM Magstar 3590 drives and wall-clock measured at 1,237 GB/hour and 6% total system overhead. TOTALS Database Elapsed Time Sustained Xfer Wall clock Xfer Total System Overhead Cold Backup 1.0265 TB Oracle7 database 51 Minutes 1.5 TB/hour 1,237 GB/hour 6% (94% of the system was still available for other processes) Hot Backup without Transaction Load at 985 GB/hour with 35 drives 1999 EURESCOM Participants in Project P817-PF page 117 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 The hot backup without transaction load was performed with 35 IBM Magstar 3590 drives and was wall-clock measured at 985 GB/hour and 6% total system overhead. TOTALS Hot Backup 1.0265 TB Oracle7 database Database 64 minutes Elapsed Time 1.3 TB/hour Sustained Xfer 985 GB/hour Wall clock Xfer Total System Overhead 6% (94% of the system was still available for other processes) Hot Backup with Transaction Load at 901 GB/hour with 35 drives The hot backup with transaction load was performed with 35 IBM Magstar 3590 drives and was wall-clock measured at 901 GB/hour and 21% total system overhead. Scripts were used to generate a load of 75 transactions per second (4500 tpm). TOTALS Database Elapsed Time Sustained Xfer Wall clock Xfer Total System Overhead B.3 Hot Backup with Transaction Load 1.0265 TB Oracle7 database 70 minutes 1.1 TB/hour 901 GB/hour 21% @ 4500 updates per minute load (79% of the system was still available for other processes) Interpreting the Results Demonstrating the ability to back up a true terabyte database in approximately one hour is an important landmark for company's with VLDBs looking for a capable backup solution. Why is one hour so important? Taking a VLDB off-line directly cuts into a 24x7 company's bottom line. In a recent Information Week article, one of the largest banks in the country estimated the bank would lose close to $50 million for every 24 hours, or $2.08 million per hour, their system is down.1 Backup of terabyte databases requires certain features and functionality to take advantage of their sheer size: Hot (Online) backup capability: As applications increasingly demand 24x7 uptime, "hot" online database backup will take precedence over "cold" offline database backup. Availability: Database availability is key. The backup system should have minimal impact on availability, so that as the database grows the backup system will not interfere with its' availability to the end-users. Ability to Scale: the system must be designed so that it will not collapse under the weight of its own growth in 18 to 24 months. 10% growth of terabyte database will use considerably more resources than 10% growth of a 10 gigabyte database. Support for Heterogeneous Environments: today's terabyte UNIX sites consist of a wide variety of platforms, operating systems and tape libraries. The backup software should not limit your choices. page 118 (120) 1999 EURESCOM Participants in Project P817-PF Deliverable 1 Volume 3: Annex 2 - Data manipulation and management issues For this performance demonstration, a true terabyte database was used for all of the tests conducted. The only way to truly exercise the boundaries of backup performance is to do it empirically - hook up all the hardware, load the software and run real life tests. While this is accurate, it is time consuming and expensive to achieve the numbers described in this paper. But, the significance of these numbers need to be understood given the criteria listed above. One aspect of this demonstration that warrants looking at closely is scalability.2 A scaleable system is one which allows for an increase in the amount of data managed and the amount of user workload supported without losing any functionality. Figure 4 illustrates a growing database. It attempts to put in perspective the considerable amount of resources that a terabyte of data can consume. Figure 4: Growing towards a Terabyte Database The backups at Silicon Graphics demonstrated a level of throughput and overhead that had minimal impact against on-going, end-user operations. (See Figure 5) Because of the minimal overhead generated by Alexandria and EBU there was no need to increase the system availability by adding additional CPU nodes and memory. During the hot backup demonstration, 79% of the total system throughput was still available when a transaction load of 4500 tpm was applied during the backup. Figure 5: Hot Database Backup with Transaction Load. Minimal Backup Software Overhead Allows for Scalability B.4 Summary This demonstration has proven the viability of true terabyte backup solutions. The Origin2000 running Alexandria Backup and Archive Librarian is now confirmed in 1999 EURESCOM Participants in Project P817-PF page 119 (120) Volume 3: Annex 2 - Data manipulation and management issues Deliverable 1 its' ability to handle ten's-of-gigabytes to terabytes of Oracle database data. This also demonstrated a new backup paradigm, as shown in Figure 6. It is no longer necessary to divide terabyte sites into several multi-gigabyte groups. Now, terabyte sites can be backed up in several terabyte groups. Figure 6: The New Backup Paradigm The Origin2000 system can scale to considerably larger than the configuration used in the performance demonstration. Maximum configuration consists of 128 CPUs, 192 XIO boards and an I/O bandwidth of up to 82 GB/second. On the other hand, given the systems tremendous I/O capabilities a much smaller Origin2000 configuration (and considerably less expensive) would have adequately handled the demonstration parameters. The IBM Magstar 3590's performed superbly in terms of performance, capacity and reliability based on hours of sustained streaming. Magstar has leading-edge streaming and start/stop performance with uncompacted data transfer rate of 9MB/sec, and instantaneous data rate of up to 20MB/sec with compaction. The advanced Magstar tape drive is designed for up to a 100-fold increase in data integrity with improved error correction codes and servo tracking techniques. Magstar uses longitual serpentine recording technology, using IBM's industry leading magneto-resistive heads that read and write sixteen tracks at a time. The IBM Magstar 3590 Model B11 includes a removable 10 cartridge magazine, and provides random access to over 300GB (compacted) data. Each cartridge has a uncompacted capacity of 10GB, 50 times more than 3480 cartridges. Spectra Logic's Alexandria Backup and Archive Librarian proved that it is the industry's most scaleable solution. Furthermore, the low CPU-overhead shows Alexandria will continue to scale with your needs. Once again, Oracle's EBU demonstrated the firm's commitment to supporting and managing very large databases. EBU scaled exceptionally well with minimal CPU utilisation, proving that these vendors are ready to manage and support the databases of tomorrow. page 120 (120) 1999 EURESCOM Participants in Project P817-PF