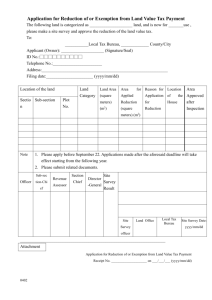
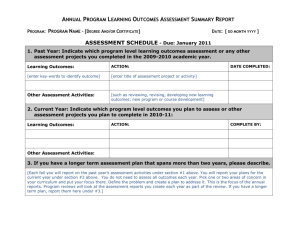
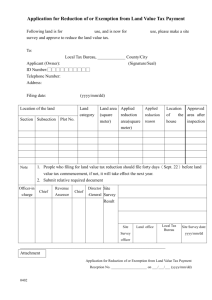
Tutorial 2 Unofficial Solution
advertisement

Question 0: If we make a processor twice faster, does it require twice the data transfer capacity? What’s the significance of the processor being twice as fast? - It can now compute twice as many instructions per second. What do we mean here by “data transfer capacity?” - This is the rate of transfer between the processor and memory. How does this affect data transfer capacity? - To keep the processor capacity full, we need to fetch twice as much instructions and data. Hence we need to move twice as much data between memory and CPU. Is this necessarily true? - No: If the increased CPU complexity also allows us to keep more instructions and data within the processor itself (e.g. in a cache), then we can double execution fetches without doubling fetches from memory. Question 1: if aaa then if xxx then yyy else zzzz else bbbb Compile aaaa We need to jump to the code for bbbb in the event that aaaa is false. Otherwise we just follow through with the code xxxx. Memory Code for aaaa …. jne label1 Stack Problem: Address of bbbb, and hence label1, is unknown. Push label1 onto the stack. Memory Code for aaaa …. jne label1 Stack label1 Compile xxxx. Insert a jump to zzzz if xxxx is false. Currently we don’t know what zzzzz’s address is, so we call it label2 and push this onto the stack: Memory Code for aaaa …. jne label1 Code for xxxx …. jne label2 Stack label2 label1 Compile yyyy: At this point we compile the code for yyyy. We insert a jump at the end of yyyy to skip over zzzz to exit. Unfortunately we don’t yet know the address for exit and need to push label3 onto the stack. But first… yyyy: Memory Code for aaaa …. jne label1 Code for xxxx …. jne label2 Code for yyyy …. j label3 Stack label2 label1 … at this point, we now know the address of zzzz, which is the address following yyyy. We pop label2 from the stack, and assign label2=yyyy. After doing this we push label3. Memory Code for aaaa …. jne label1 zzzz: Code for xxxx …. jne zzzz Code for yyyy …. j label3 Code for zzzz zzzz1: j exit yyyy: Stack label3 label2 label1 We can now pop label3 from the stack, and assign label3=zzz1: Memory Code for aaaa …. jne label1 zzzz: Code for xxxx …. jne zzzz Code for yyyy …. j zzzz1 Code for zzzz zzzz1: j label4 yyyy: Stack label3 label2 label1 At this point we can generate the code for bbbb. We also now know the address of bbbb, which is the address following zzzz1. So we pop label1 from the stack, assign label1=bbbb. Note also that at zzzz1, we intend to jump over bbbb, but we don’t know the address yet until bbbb is compiled. So we push label4 onto the stack. Memory Code for aaaa …. jne bbbb yyyy: zzzz: zzzz1: bbbb Code for xxxx …. jne zzzz Code for yyyy …. j zzzz1 Code for zzzz j label4 Code for bbbb …. exit: At this point, label4 is popped and is assigned label4=exit. Stack label4 label3 label2 label1 Memory Code for aaaa …. jne label1 yyyy: zzzz: zzzz1: bbbb exit: Code for xxxx …. jne zzzz Code for yyyy …. j zzzz1 Code for zzzz j exit Code for bbbb …. Stack label4 label3 label2 label1 Question 2 (((( ex+d)x + c) x + b)x + a Easiest to derive postfix notation first: ex*d+x*c+x*b+x*a+ Translate this into a program: load e load x mul load d add load x mul load c add load x mul load b add load x mul load a add All steps depend on previous step, hence no ILP (except the loads, in the event of a cache miss). e(x^2)(x^2) + d(x^2) + c(x^2) + bx + a load e load x load x mul store s load s mul load s mul load d load s mul add load c load s mul add load b load x mul add load a add // This assigns s = x^2 // This gets e * s = e * x^2 // Stack is now e*x^2. The previous step and this step get e*(x^2)*(x^2) // We now have d * (x^2) // Add to earlier e*(x^2)*(x^2) // This gets us c * (x^2) // And adds that the our earlier e*(x^2)*(x^2) + d * (x^2) // This gets us bx // Add to earlier result // Add a to earlier result to complete expression. Several places for ILP here: i) ii) Once s is computed, e(x^2)(x^2), d(x^2), c(x^2) can be computed independently and added later. bx+a can be computed independently of s, and therefore ahead of everyone else.