Quality Control
advertisement

QUALITY CONTROL
One of the common approaches to quality control is taking frequent samples during
production, inspecting them, plotting control charts to see if the production conforms to
predetermined upper and lower control limits. For example, the lower and upper limits for
diameter of a circular part may be 1.9 and 2.1 inches respectively and as long as all the parts
within these acceptable limits, the process is said to be in control.
the
the
the
are
Example:
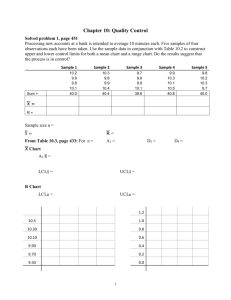
Suppose we take a subgroup every hour consisting of two measurements during a 10-hour
working day with the following results:
Subgroup
Number
Measurements
X1
X2
Subgroup
Averages
Subgroup
Ranges(R)
1
10
8
9
2
2
3
4
5
6
7
8
9
10
9
8
7
7
6
9
8
6
9
9
6
7
9
8
7
8
10
9
9
7
7
8
7
8
8
8
9
80
0
2
0
2
2
2
0
4
0
14
What are the 3-sigma control limits?
Solution:
3- control limits are given by:
X 3 x
Therefore, we first need to compute the mean of the sample means denoted by X with two bars
over it:
X 80 / 10 8
Then, we need to compute the standard deviation.
In this problem we are going to
s x
assume that the standard deviation
that is computed on the basis of the samples is
approximately equal to the true standard deviation
x
.
In real life, especially in more
sensitive quality control situations requiring precision it is essential to keep the sample size large
and exercise caution in terms of the assumptions. In reality, using
x
instead of
x
woud be
more suitable( sign on top of indicates that it is the approximate estimated value of ). Many
times, signs have not been used on the symbols that follow to keep the notation simpler).
We are going to use two different approaches in this problem. In the first approach, we
first estimate the approximate value of standard deviation as follows:
x
[(9 - 8 )2 + (9 - 8 )2 + (7 - 8 )2 + (7 - 8 )2 + (8 - 8 )2 + (7 - 8 )2 + (8 - 8 )2 + (8 - 8 )2 + (8 - 8 )2 (9 8) 2
10
x 0.775
Note: Since we don't know the true value of certain parameters and estimate them instead, some
degrees of freedom are lost; therefore, in computing x above it is wrong to divide it by 10.
However, n=10 was used in the denominator above in the estimation of x for simplicity
without getting into the complexity of degrees of freedom issue. In real life applications it is
necessary to reduce n by the degrees of freedom lost prior to using it in the denominator in the
estimation of x .
Now, we can substitute the estimated mean and standard deviation values that we computed
above into the control limits equation:
X 3
x
8 3(0.775) (5.68, 10.33)
Here, 5.68 is the lower control limit, 10.33 is the upper control limit.
As can be seen, the computations to obtain x are tedious(especially in large scale
problems). Therefore, it may be more practical to use the range concept to estimate 3 x . If the
standard deviation is not known, we can use 3x A2 R in cases where high degree of precision
is not required and where the objective is to find 3-sigma control limits( where the multiple in
front of the standard deviation is 3.) In this second approach to the computation of 3-sigma control
limits, we first compute
R = 14/10 = 1.4
Then, we can use the following equation to get the 3- limits:
X A2 R 8 188
. (14
. ) (5.37, 10.63)
Note that the results are very close to the previous lower and upper control limits. They
could have been much closer, if the example had not used unrealistic numbers like 6 inches for the
first item and 10 inches for the next item as in the case of subgroup 9. In reality, these numbers
would be quite similar like 8.06 and 8.10 for a standard product and number 6 may represent 0.06
inches above 8 and number 10 may represent 0.10 inches above 8, for example. In this problem,
simple and uncomplicated numbers were used to prevent distraction from the main procedure.
Other applications that involve lower and upper limits follow:
Example:
Given X = 2, = 0.15, n = 36 and assuming normal distribution, what percentage of sample
means would be expected to fall outside the limits of 1.925 and 2.075?
Solution:
x =
n
=
0.15
36
= 0.025
The upper limit is given by:
X z x 2 + z(0.025) = 2.075 z = (2.075 - 2) / 0.025 = 3
Probability of being below the upper limit = 0.9987
Prob. of being above the upper limit = 1-0.9987 = 0.0013
The lower limit is given by:
X z x 2 - z(0.025) = 1.925
-z = (1.925 - 2) / 0.025 = -3
Prob. of being below the lower limit = 0.0013
Note that the difference between the upper limit and the mean is 2.075 - 2 = 0.075 and the
difference between the mean and the lower limit is = 2 - 1.925 = 0.075; the differences are equal.
Therefore, this is a case with equal tails.
In reality, we could skip the computation of probability of being below the lower limit
because it would always be the same as the probability of being above the upper limit, i.e., 0.0013 in
case of equal tails; this computation has been included to provide the basic insight.
To summarize 0.0013 + 0.0013 = 0.0026 or 0.26% of the sample means would be expected
to be outside the control limits.
Example:
Specifications for a product requires that it should weigh between 11.4 and 11.8 pounds. If
the mean weight is 11.6 pounds with a standard deviation of 0.2 pounds, what percentage of the
products is expected to meet the specifications?
Solution:
= 11.6
= 0.2
P{11.4
11.8}
= P{[(11.4 - 11.6)/0.2]
= P(-
- 11.6)/0.2]}
1) -
-1) = 0.8413 - 0.1587
= 0.6826
Therefore, about 68% is expected to meet the specifications.
Example:
In a problem situation, th
sample measurements and computations shows that the mean is 3.9 and the standard deviation is
0.6.
Several more samples of size 36 are taken and each of these 36 products is measured and a sample
average (sample mean) is determined for each sample. What percent of the sample means would be
expected to fall outside the limits?
Solution:
This is a case of unequal tails; so each part should be treated separately and then combined.
imits are 4 ± 0.2 → (3.8, 4.2). The difference between the mean and the lower limit is: 3.9 - 3.8 =
0.1 and the difference between the upper limit and the mean is 4.2 - 3.9 = 0.3; as can be seen the
differences
are not equal.
x =
n
=
0.6
36
= 0.1
The upper limit is given by:
X + z
x
3.9 + z(0.1) = 4.2 z(0.1) = 0.3 z = 3
Probability of being below the upper limit = 0.9987
Prob. of being above the upper limit = 1-0.9987 = 0.0013
The lower limit is given by:
X - z
x
3.9 - z(0.1) = 3.8 - z(0.1) = - 0.1 -z = -1
Prob. of being below the lower limit = 0.1587
Therefore, 0.013 + 0.1587 = 0.16 or 16% would be expected to be outside the limits.
Control Charts for Attributes
The previous examples were related to control charts for variables such as the diameter of
circular part, the weight of a product, etc. that could be measured. On the other hand, the control
charts for attributes are used when the items are counted rather than measured such as counting the
items that are defective. In such a case we are dealing with an attribute such as defectives or
nondefectives rather than measurements of variable dimensions or weights.
The limits for the control charts for variables of our previous examples have had the form:
X z x
where X represented the average of sample means and
x
represented the standard deviation of
the sample means.
The limits for the control charts for attributes have a very similar form:
p z ̂ p
where p represents the average proportion of defective items and
p
represents estimated
standard deviation of p . The sign on indicates that it is not the true value of the standard
deviation but it is an estimated approximate value based on samples. Also, it is important to note
that it is the estimated standard deviation of p not p.
Basically, here we are talking about the average proportions or percentages rather than
average measurements such as length or weight. Here, p represents the average for proportions
whereas X represents the average for measurements; but the format is pretty much the same.
Example:
A company manufactures light bulbs in lots of 700. Inspectors take a sample of 50 from
each lot. Suppose inspectors analyzed 4 different lots by taking a sample of 50 from each lot and
found the following results:
Sample
1
2
3
4
Number of
defectives
13
16
12
11
52
Determine 95% control limits on the basis of the information above; assume that 95% control limits
imposed by management are desired and acceptable limits.
Solution:
p = 52/4(50) = 0.26
̂ = p(1 - p )/n = 0.26(1 - 0.26)/50 = 0.062
p
This is a two-tailed case because it involves both upper and lower control limits. The
standard normal table is based on one-tailed case. Assuming equal tails 95% or 0.95 has (1-0.95)/2
= 0.025 or 2.5% on each side. The conversion to one-tailed case will be 1 - 0.025 = 0.9750 or
97.5% so that we can use the one-tailed standard normal table. For 0.9750, the z = 1.96. Hence,
p z ̂ p 0.26 1.96(0.062) 0.26 0.12 (0.14,0.38)
Proportion of defectives (0.14, 0.38) can be converted to the number of defectives by multiplying by
the sample size of 50 with the result of (7,19). Hence as long as the number of defectives in each
sample is within the limits of 7 and 19, the process is said to be in control. In our example, the
number of defectives in 4 samples are 13, 16, 12, 11 and none of them is less than 7 or greater than
19, so that the process is said to be in control.
Sampling Plans
Inspecting the items that have already been produced is also a part of quality control. This
section discusses two common sampling plans.
Single Sampling
Only one sample is taken and the whole decision is based on this sample. For example,
suppose that N (lot size) = 8,000,
n (sample size) = 280, c (acceptance criterion) = 7. According to this plan, we take a sample of 280
out of 8,000. On the analysis of those 280 items, we accept the whole lot of 8,000 units if there are
7 or fewer defectives in a sample of 280 and reject the whole lot if there are more than 7 defectives.
Double Sampling
A sample is taken and analyzed. It is not conclusive, a second sample is taken. For
example, let
N = 8,000, n1 = 50, c1 = 1, r1 = 5
n2 = 140, c2 = 6, r2 = 7
According to the above plan, we take a sample of n1 = 50 and definitely accept the whole lot of
8,000 if there is 1 or fewer defectives or definitely reject it if there are 5 or more defectives. In these
cases, a second sample would not be taken.
A second sample of n2 = 140 would be taken only if there are between 1 and 5 defectives (i.e., 2, 3,
or 4 defectives) in the first sample. Then, if the cumulative number of defectives in both samples
are 6 or fewer, we accept the whole lot, if it is 7 or more defectives, we reject the whole lot. Below
are the possibilities for acceptance on the basis of cumulative number of defectives:
i)
2 defectives in the first sample plus 4 defectives or fewer in the second sample,
ii)
3 defectives in the first sample plus 3 defectives or fewer in the second sample,
iii)
4 defectives in the first sample plus 2 defectives or fewer (i.e., 0, 1, or 2 defectives) in the
second sample.
Average Outgoing Quality (AOQ)
This concept is illustrated by an example and AOQ curve and a more detailed explanation of
the concept follows the example with reference to the example and AOQ curve to provide a clearer
understanding.
Example:
A firm inspects the lots consisting of 1,000 items by taking a sample of 10 and accepts the
whole lot if there are 2 or fewer defectives. Past experience shows that the proportion of defectives
is 10%. Draw the AOQ curve.
Solution:
AOQ = p (pac) ((N-n)/N)
where
AOQ = average outgoing quality or proportion of defectives going out
p = proportion of defectives coming in
N = lot size
n = sample size
In our example, the proportion, ((N-n)/N) = ((1,000 - 10)/1,000) = .99 ≈ 1. Therefore, it is
eliminated in this example for simplicity; this proportion would be close to 1 when the lot size is
much bigger than the sample size. Now, AOQ = p (pac).
The following pac values are obtained from the binomial table with n = 10 and c(or x) = 2 for
various p values.
Proportion of
Defectives Coming In
(p)
Probability of
Acceptance
(pac)________
AOQ or
Proportion of
Defectives Going Out
[p (pac)]___________
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
0.50
0.55
0.60
1.0000
0.9885
0.9298
0.8202
0.6778
0.5256
0.3828
0.2616
0.1673
0.0996
0.0547
0.0274
0.0123
0.0000
0.0494
0.0930
0.1230
0.1356
0.1314
0.1148
0.0916
0.0669
0.0448
0.0274
0.0151
0.0074
The AOQ(proportion of defectives going out) values are simply obtained by multiplying
p(proportion of defectives coming in) values by pac(probability of acceptance) values. For example,
if an incoming lot has 10% defectives and the probability of accepting it is 92.98%, then,the
proportion of defectives going out would be expected to be 10%(92.98%) = 0.1(0.9298) = 0.0930
because only 92.98% of the lots with 10% defectives would be expected to pass the inspection.
The AOQ curve is obtained by using the numbers in the first column of the table
above(proportion of defectives coming in) as the horizontal axis values and the numbers in the third
column(AOQ or proportion of defectives going out) as the vertical axis values.
AOQ CURVE
As can be inferred from the curve, as there are more defectives in the incoming lots, there
will be more defectives in the outgoing lots. This situation is indicated by the initial upward slope
of the curve. After a certain point, as indicated by the downward slope of the curve, as the
proportion of defectives coming in increases, the proportion of defectives going out decreases. At
first, this seems contrary to our common sense; but when there are too many defectives, there is a
better chance of catching and rejecting them. Also, too many defectives would prompt tighter
inspection which would ease spotting and rejecting the bad items. When bad items are rejected,
more of the good ones
would be accepted and the proportion of defectives in outgoing lots would decrease as indicated by
the downward slope of the curve after a certain point.
Operating Characteristics (OC) Curve
Using the numbers from the p and pac column of the AOQ example we can easily construct
an OC curve.
OC CURVE
The operating characteristic (OC) curve shows the probability of accepting the lots with
various proportions of defectives. Obviously, the probability of accepting the lots with smaller
proportion of defectives is higher. For example, if the proportion defectives is 0.1, the probability
of acceptance is 0.9298 whereas if the proportion of defectives goes up to 0.3, probability of
accepting it drops to 0.3828 as can be seen from the graph.
The OC curve basically describes the ability of a sampling plan to discriminate between
high quality lots and low quality lots. A steeper OC curve would imply a more discriminating
sampling plan.