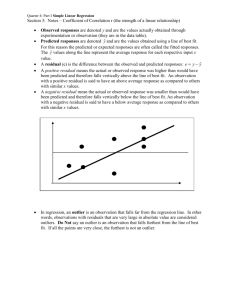
Lecture 8
advertisement

Lecture 8
Analysis of bivariate data: introduction to Correlation,
Covariance and REGRESSION ANALYSIS
Aims and Learning Objectives
By the end of this session students should be able to:
Calculate and interpret the covariance coefficient, the correlation
coefficient and the coefficient of determination
Construct and interpret simple regression models
Understand the nature of outliers and influential variables and how
they can be detected
Preliminaries
So far we have always analysed variables when taken one at time. In Weeks
5 and 7 we saw how univariate data could be statistically described and
displayed in histograms or boxplots. Statistical analysis only rarely focuses on
a single variable. More often than not we are interested in relationships
among several variables.
So, what if you have two variables – ‘bivariate’ data? Suppose you have, for
example, GDP and Exports, or GDP and Democracy (just like in your project).
In this case, we have to introduce more sophisticated (not too much!)
statistical tools.
1. Analyzing Bivariate Data by graphical inspection
By simply displaying your variables, you can draw some preliminary
conclusions about the existing relationship between the variables. The display
you use depends on the type of the data – in particular, whether it is “nominal”
(sometimes called “categorical”) or “non-nominal” – that is to say, real
measurable data for which you can meaningfully calculate means and
dispersion measures.
- Cross-tabulations are used when you have two Nominal (or Categorical)
level variables, i.e. data with no intrinsic ordering structure, taking discrete
and finite values.
You want to see how scores on one relate to scores on the other, that is, how
they are associated. For instance, the following demo cross-analyses choice
of degree course by gender.
Demo 1 - Cross-tabulations (click here for Excel output results)
- Scatterplots, or Scattergrams, or XY Charts are used when we have ordinal
continuous variables (non-nominal) – real data with means and variances –
which we want to cross-analyse.
Demo 2 - shows how student marks in Year 2 relate to student marks
in Year 3. To what extent can we predict student performance from one year
to the next? Click here for Excel output results).
The problem is that the interpretation of the scatterplot (and cross-tabs) is
extremely subjective; as such, it’s questionable. What we need is more formal
techniques.
2. Covariance coefficient and the Correlation coefficient
We want to measure whether two or more variables are associated with each
other, i.e., to determine if two or more variables are linearly related.
The covariance and correlation coefficients are descriptive measures of the
relationship between two variables.
Definitions:
- Covariance coefficient is a measure of linear association between two
variables
Given two variables we want to investigate (X, Y), the covariance coefficient is
formally expressed as: s xy
( xi
x )( y i y )
n 1
Properties:
i)
direction of association
ii)
its value depends on the unit of measurement
- Correlation coefficient is a measure of how strongly the two variables
are linearly related
Given X and Y, the correlation coefficient can be calculated as: r
s xy
sx s y
where is the covariance coefficient, which is divided by the standard deviation
of X, s x
( xi
x) 2
n 1
and Y, that is s y
( yi
y) 2
n 1
Requirements for using r:
1. A linear relationship exists between the two variables
2. The data is measured at the continuous level of measurement
3. Random sampling occurs
4. Both the x and y variables are normally distributed in the
population.
a) Usually a sample size of 30 or more satisfies this
requirement
Properties of r:
i)
Unit-free measure
ii)
It ranges from -1 to +1
iii)
Value of -1 perfect negative linear correlation
iv)
Value of +1 perfect positive linear correlation
v)
Values close to zero represent weak relationships
To summarize:
•
•
If the two variables move together: a positive correlation exists
And if the two variables move in opposite directions: a negative
correlation exists.
•
Correlations among variables are rarely perfect; most are only
correlated to some degree. From this we get a correlation coefficient
scale….
-1
-0.60
Perfect
Negative
Relationship
-0.30
Strong
Moderate
Negative
Negative
Relationship Relationship
-0.10
0
+0.10
Weak
No
Relationship
Weak
Positive
Relationship
Negative
Relation
ship
+0.30
+0.60
Moderate
Strong
Positive
Positive
Relationship Relationship
+1
Perfect
Positive
Relationship
To calculate the covariance and correlation coefficients in Excel, click on
tools, then data analysis. Scroll down until you find covariance and
correlation.
- Demonstrations for Covariance and Correlation coefficients
Demo 9.1 - Calculating covariance and correlation coefficients
( for Excel output results click here)
3. Regression Analysis
Let’s look again at our education standards from the 70s and 80s scatterplot.
We believe this plot expresses a direct relationship between the standards.
Education 80s
Education80s
160
140
120
100
80
60
40
20
0
0.000 20.000 40.000 60.000 80.000 100.00
0
Education 70s
Education
Regression is a way to estimate (or predict ) a parameter value (e.g. the
mean value) of a dependent variable, given the value of one or more
independent variables.
Y = dependent variable while
x1, x2, x3…xi = independent variables.
Thus, we are estimating the value of Y given the values of x1, x2, x3…xi .
Dependent and independent variables are identified on the basis of a
scientific theory underlying the phenomenon.
How do we find out if there is such a relationship? How do we express it in
formal terms?
In statistics, it is assume that relationships among variables (X and Y) can be
modelled in a linear fashion:
Why? Because: a) it’s simple and tractable; b) many relationship in real world
are found to be linear; c) there is no evidence of a non-linear link.
andare called parameters of the model. They must be estimated in a way
to get the best possible fit to the data at hand.
The problem is to fit a line to the points in the previous scatterplot expressed
as Yˆi X i and ŷ i is the predicted Y (called Yhat).
Estimation is not an exact prediction. Rather, the estimate of y is:
–
the value of y, on average, that will occur given a value of x.
Thus, yhat is really the mean value of y given x
How can this estimation be done? Use the method of least squares
(commonly known as Ordinary Least Squares or OLS for short):
The least squares regression line is the line that minimises the sum of
square deviations of the data points.
3.1 An illustration of OLS technique
When fitting a line, call ei the (inevitable) deviation of the fitted values of Y
from the ‘real’ observed values of Y.
This vertical deviation of the ith observation of Y from the line can be
expressed as:
Error (or Deviation) = Observed Y - Predicted Y; also expressed as
ei Yi Yˆi
and, after substituting for the predicted Y,
becomes ei Yi X i . This can be observed in graphical terms:
Y
Y
Y
.
e {
.
Y2
e {..
Yi X i ei
.} e
.
Y
}e
.
Y1
X2
X
X3
The relationship among Y, ei and the fitted regression
line.
X4
X
The OLS technique is about estimating the parameters andof the
equation Yi X i
in such a way that
the sum of squared errors is minimised: min
n
n
i 1
i 1
ei2 (Yi X i ) 2
the solutions to this problem are:
ˆ
(X i
X (Yi Y )
i
(X i X )
i
2
Co var iance( X , Y )
Variance( X )
and
ˆ Yi X i
Once you have understood the theoretical principles behind the regression
analysis, you have to know how to implement this simple methodology.
You want to estimated the ˆ and ˆ parameters of your linear model ,
Yˆi X i ,MS Excel will do this for you, by clicking on Tools and the
data analysis
. Here is the Excel output.
Regression Statistics
Multiple R
R Square
Adjusted R Square
Standard Error
Observations
0.662044415 Correlation coefficient
0.438302807
Coefficient of
determination
0.432571203
2.006488797
100
ANOVA
df
Regression
Residual
Total
Intercept (α)
X Variable (β)
1
98
99
Coefficients
20.98686482
0.49420145
SS
MS
F
Significance F
307.872964 307.872964 76.47122975
6.3759E-14
394.5477348 4.02599729
702.4206988
Standard Error
t Stat
0.258361693 81.2305594
0.056513861
8.744783
P-value
1.02848E-91
6.3759E-14
Your regression model is now ready to be used for analysis..
a) Parameters:
Intercept= α = average value of Y when X is zero
Slope of straight line = coefficient ß = average change in Y associated
with a unit change in X
Suppose the above output relates to the relationship between GDP and
Exports. According to the results in the above figure, we can conclude that
your linear model can predict the Gross Domestic Product following the
quantitative model:
GDPi = 20.98 + 0.49*Exportsi
theoretical model )
( which corresponds to the above
Lower 95% Upp
20.47415447 21.
0.382051535 0.6
Interpretation: For every change of 1 unit in the Exports, GDP will change by
0.49 units (e.g.billions of £) on average. The constant term is seen as the
average value of GDP when the economy in not exporting any commodities.
How well do the estimated coefficients conform to a priori expectations? This
implies answering the following questions: Was a relationship found in the
sample data? If yes, does its sign and magnitude correspond to our
expectations?
This judgment must be made in the light of economic theory and of the nature
of the economy you are studying. In any case, you must:
Check the coefficient sign against our expectations (hypothesis)
Check coefficient magnitude against expectations (if any)
b) Statistical significance of the parameters of the model:
In statistics, you can analyze data based on a whole population, but more
often you deal with sample data drawn from a given population. In this case,
you need a decision rule that tells you if the values of the parameters of your
sample-based linear regression model are likely to be close to the ‘true
values’ of the parameters, i.e., to the intercept and to the slope coefficient of a
regression based on the whole population data.
Statistical significance is very important for the theory behind your empirical
model. X may not, in fact, affect Y – repeated findings of insignificance in
different samples suggest a need to re-evaluate theory. To establish this, a
more substantial technical background in statistics is required. Nevertheless,
we can avoid a technical discussion and still learn how to gain insights about
how to judge the statistical significance.
The estimated model parameters are insignificant if they exert no impact on
our Y. They do so if they are zero.
Excel output provides us with a numerical value for the significance of the
estimated model parameters against the pre-determined hypothesis that the
slope or the intercept they is zero. Two ways of evaluating this numerical
value:
•
•
Compare this “test” statistic to a “critical value”
Calculate the P-value (probability value) and compare this to the
significance level chosen
Our software packages calculate the probability value, P-value. It is defined
as the lowest probability value at which x i are not zero. Suppose we repeat
our regression using each time different samples drawn randomly from our
population. The P-value is telling us what is the probability that our model
parameters will become zero, thus exerting no impact on Y.
Conventionally, a P-value smaller or equal to 5% probability is considered a
strong level of significance. A P-value lying between 5% and 10% stands for
weak significance. In all the other cases, the explanatory variables are
insignificant.
The t-statistic is a more formal test for significance, in this case it consists of
the ratio between the coefficient and the standard error, to produce a test
statistic which can then be compared to a critical value at a specific level of
significance (usually 5%). In general at the 5% level of significance the critical
value is about 2. (The exact value depends on the number of observations
and parameters in the model). If the test statistic exceeds the critical value
(ignoring the sign, this is an absolute value), we say the coefficient is
significantly different to zero, if it is less then the critical value we say it equals
zero and is therefore not significant.
c) Goodness of fit:
We want to answer the question: how well our model explains variations in the
dependent variable Y ?
First we have to see how the variation in Y is constructed. Basically, we want
to find out if our linear model explains the variation of Y better its simple
arithmetic mean Y-bar.
Total Sum of Squares (TSS): ∑i(Y-Y)2
total deviation of the observed Yi from the sample mean, Y
it’s the
Residual Sum of Squares (RSS): ∑ie2
unexplained deviation of Yi from Y
it’s the
Explained Sum of Squares (ESS): ∑i( Yˆ -Y)2
it’s the
portion of the total deviation explained by the regression model
A graphical illustration is in this slide
The Coefficient of Determination, r2 , is an appropriate measure of how good
is the fit of our simple statistical model.
r2 = ESS/TSS = 1-(RSS/TSS)
It’s the proportion of the total variation in the dependent variable Y that is
explained by the variation in the independent variable X.
The coefficient of determination is also defined as the square of the coefficient
of correlation, and ranges from 0 to 1:
Interpretation:
r2 is close to 1 : a very good fit (most of the variance in Y is explained
by X)
r2 is near 0 : X doesn't explain Y any better than its sample mean
3.2 Limitations of regression analysis
•
Outliers - points that lie far from the fitted line
•
Influential Observations- an observation is influential if removing it
would markedly change the position of the regression line
•
Omitted Variables - a variable that has an important effect on the
dependent variable but is not included in the simple regression model
Regression Analysis and Correlation Analysis Compared:
Correlation analysis: association between two variables
Regression analysis: dependence of one variable on other
Neither correlation nor regression analysis are robust to outliers. An outlier is
an observation that is far removed from the body of the data; it could be a
legitimate observation, but it could also be an error. Your results are going to
be crucially affected.
When dealing with univariate data, we can use the following criteria for
detecting the presence of outliers:
When using bivariate data, for example least squares estimation, we can
examine the scatter plot. Alternatively, we look at the least squares residuals
e. By calculating the presence of outliers in the series of residuals from the
regression, you will find out if your regression results were spoiled by outliers.
Final remarks
We have learnt elegant techniques, incredibly easy to implement with
modern software packages.
Nevertheless, a warning must be given. Always keep in mind that neither
correlation nor regression analyses necessarily imply causation.
Example: “Ice Cream Sales and Bicycle Sales are both highly correlated.”
Do Ice Cream Sales cause Bicycle sales to increase…?
not?)
(Why
Causality must be justified or inferred from the (economic or political)
theory that underlies the phenomenon that is investigated empirically.
Demonstrations for Regression Analysis
Demo 9.2 - Estimating a bivariate regression model (Excel). Click here for
output results
Demo 9.3 - Estimating a multiple regression model (Excel). Click here for
results.
Class Exercise 8 can be found here