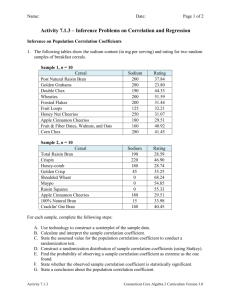
1. Indicate which would be the independent variable and which
advertisement

1. Indicate which would be the independent variable and which would be the dependent variable in each of the following: Independent variable, Dependent variable a. Score on the first test, Final grade b. Gas mileage, Car speed c. High school grade point average, Freshman College grade point average d. Crop yield, Rainfall 2. A math test was given with the following results: 80, 69, 92, 75, 88, 37, 98, 92, 90, 81, 32, 50, 59, 66, 67, 66 Find the range, standard deviation, and variance for the scores. Arranging the data in the ascending order of magnitude, we have 32, 37, 50, 59, 66, 66, 67, 69, 75, 80, 81, 88, 90, 92, 92, 98 N = 16 Let us assume the mean as 70. Thus A = 70 Deviations of each score from A are D = -38, -33, -20, -11, -4, -4, -3, -1, 5, 10, 11, 18, 20, 22, 22, 28 D^2 values are 1444, 1089, 400, 121, 16, 16, 9, 1, 25, 100, 121, 324, 400, 484, 484, 784 D^2 = 5818 D = 22 (a) Range = Highest score – Lowest score = 98 – 32 = 66 True mean = A + (D/N) = 70 + (22/16) = 70 + 1.375 = 71.375 (b) = [(D^2 /(N – 1)) – (D /(N – 1))^2] = [(5818/15) – (22/15)^2] = 19.64 (c) Variance = ^2 = 385.72 3. For a particular sample of 50 scores on a psychology exam, the following results were obtained. Mean = 78 Midrange = 72 Third quartile = 94 Mode = 84 Median = 80 Standard deviation = 11 Range = 52 First quartile = 68 a. What score was earned by more students than any other score? Why? b. How many students scored between 68 and 94 on the exam? c. What was the highest score earned on the exam? d. What was the lowest score earned on the exam? (a) The score was 84. This is because mode of the data is 84. (b) x1 = 68, x2 = 94 z = (x – )/ z1 = (68 – 78)/11 = -10/11 = -0.91 and z2 = (94 – 78)/11 = 16/11 = 1.45 Number of students who scored between 68 and 94 = Area under the Standard Normal Curve between -0.91 and 1.45 * Number of students who took the exam = 0.7454 * 50 = 37.27 37 students (c and d) By data, H – L = 52 and H + L = 2(72) = 144 Solving, we get H = 98 and L = 46. 4. a. What does it mean to say that x = 152 has a standard score of +1.5? b. What does it mean to say that a particular value of x has a z-score of -2.1? c. In general, what is the standard score a measure of? 6. An animal trainer obtained the following data (Table A) in a study of reaction times of dogs (in seconds) to a specific stimulus. He then selected another group of dogs that were much older than the first group and measure their reaction times to the same stimulus. The data is shown in Table B. Table A Table B Classes Frequency Classes Frequency 2.3-2.9 10 2.3-2.9 1 3.0-3.6 12 3.0-3.6 3 3.7-4.3 6 3.7-4.3 4 4.4-5.0 8 4.4-5.0 16 5.1-5.7 4 5.1-5.7 14 5.8-6.4 2 5.8-6.4 4 Find the variance and standard deviation for the two distributions above. Compare the variation of the data sets. Decide if one data set is more variable than the other. 7. Answer the following: a. What is the relationship between the sign of the correlation coefficient and the sign of the slope of the regression line? b. As the value of the correlation coefficient increases from 0 to 1, or decreases from 0 to -1, how do the points of the scatter plot fit the regression line? 8. Describe in your own words what is meant by “line of best fit.” 9. In your own words, state the primary purpose of: a. Linear correlation analysis b. Regression analysis (4) (a) It means the score 152 is 1.5 standard deviations higher than the mean score of that distribution. (b) It means the score x is 2.1 standard deviations lesser than the mean score of that distribution. (c) A standard score, in general, is a measure of how far (higher or lower) a score is from the mean of the distribution. (6) Table A: C.I. Mid score (x) fx Freq d= d^2 fd^2 x– (f) 2.3 – 2.9 2.6 10 26 -1.23 1.5129 15.129 3 – 3.6 3.3 12 39.6 -0.53 0.2809 3.3708 3.7 – 4.3 4 6 24 0.17 0.0289 0.1734 4.4 - 5 4.7 8 37.6 0.87 0.7569 6.0552 5.1 – 5.7 5.4 4 21.6 1.57 2.4649 9.8596 5.8 – 6.4 6.1 2 12.2 2.27 5.1529 10.3058 ∑ fd^2 = ∑ f = 42 ∑ fx =161 44.8938 = Variance = ∑ fx/∑ f = 161 /42 = (∑ fd^2 /∑ f) 3.83 = (44.8938 / 42) = 1.0689. Table B: C.I. Mid score (x) fx Freq d= d^2 fd^2 x– (f) 2.3 – 2.9 2.6 1 2.6 -2.25 5.0625 5.0625 3 – 3.6 3.3 3 9.9 -1.55 2.4025 7.2075 3.7 – 4.3 4 4 16 -0.85 0.7225 2.89 4.4 - 5 4.7 16 75.2 -0.15 0.0225 0.36 5.1 – 5.7 5.4 14 75.6 0.55 0.3025 4.235 5.8 – 6.4 6.1 4 24.4 1.25 1.5625 6.25 ∑ fd^2 = ∑ fx = 203.7 ∑ f = 42 = ∑ fx/∑ f = 203.7/42 = 4.85 26.005 Variance = (∑ fd^2 / ∑ f) = (26.005 / 42) = 0.6192 for Table 1: 1.0689 = 1.034 and for Table 2: 0.7869 The data set in Table 1 is more variable than that in Table 2. (7) (a) The sign of the correlation coefficient is the same as that of the regression lines. (b) The points on the graph approach the regression line. They come and fall closer and closer to the regression line. (8) The line of best fit is the straight line that best represents the data on a scatter plot. (This line may pass through some of the points, none of the points, or all of the points.) (9) (a) The purpose of the linear correlation analysis is to ascertain the degree of relationship between X and Y. We cannot assign cause and effect relationship between X and Y. In correlation analysis, we calculate the correlation coefficient which is a measure of the degree of covariablity between X and Y. (b) Regression analysis is done to study the nature of relationship between X and Y so that we may be able to predict the value of one on the basis of the other. In regression analysis we take X as the independent variable and Y as the dependent variable. This makes the study of cause and effect relation between X and Y possible.