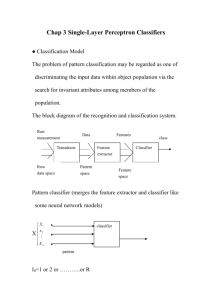
Pattern Classification
advertisement

0 Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors and the publisher Pattern Classification, Chapter 2 (Part 2) Chapter 2 (Part 2): Bayesian Decision Theory (Sections 2.3-2.5) • Minimum-Error-Rate Classification • Classifiers, Discriminant Functions and Decision Surfaces • The Normal Density 2 Minimum-Error-Rate Classification • Actions are decisions on classes If action αi is taken and the true state of nature is ωj then: the decision is correct if i = j and in error if i ≠ j • Seek a decision rule that minimizes the probability of error which is the error rate Pattern Classification, Chapter 2 (Part 2) 3 • Introduction of the zero-one loss function: ⎧0 i = j λ ( α i ,ω j ) = ⎨ ⎩1 i ≠ j i , j = 1 ,..., c Therefore, the conditional risk is: j =c R(α i | x) = ∑ λ (α i | ω j ) P(ω j | x) j =1 = ∑ P(ω j | x) = 1 − P(ωi | x) j ≠i “The risk corresponding to this loss function is the average probability error” Pattern Classification, Chapter 2 (Part 2) 4 • Minimize the risk requires maximize P(ωi | x) (since R(αi | x) = 1 – P(ωi | x)) • For Minimum error rate • Decide ωi if P (ωi | x) > P(ωj | x) ∀j ≠ i • Equivalently ωi ∈ arg minj P (ωi | x) Pattern Classification, Chapter 2 (Part 2) 5 • Regions of decision and zero-one loss function, therefore: P( x | ω1 ) λ12 − λ 22 P ( ω 2 ) Let . = θ λ then decide ω 1 if : > θλ λ 21 − λ11 P ( ω 1 ) P( x | ω 2 ) • If λ is the zero-one loss function which means: ⎛ 0 1⎞ ⎟⎟ λ = ⎜⎜ ⎝1 0⎠ P( ω 2 ) then θ λ = = θa P( ω1 ) ⎛0 2 ⎞ 2 P( ω 2 ) ⎟⎟ then θ λ = = θb if λ = ⎜⎜ P( ω1 ) ⎝1 0⎠ Pattern Classification, Chapter 2 (Part 2) 6 Pattern Classification, Chapter 2 (Part 2) Classifiers, Discriminant Functions and Decision Surfaces 7 • The multi-category case • Set of discriminant functions gi(x), i = 1,…, c • The classifier assigns a feature vector x to class ωi if: gi(x) > gj(x) ∀j ≠ i Pattern Classification, Chapter 2 (Part 2) 8 Pattern Classification, Chapter 2 (Part 2) 9 • Feature space divided into c decision regions if gi(x) > gj(x) ∀j ≠ i then x is in Ri (Ri means assign x to ωi) • The two-category case • A classifier is a “dichotomizer” that has two discriminant functions g1 and g2 Let g(x) ≡ g1(x) – g2(x) Decide ω1 if g(x) > 0 ; Otherwise decide ω2 Pattern Classification, Chapter 2 (Part 2) 10 • Bayes Classifier gi(x) = - R(αi | x) (max. discriminant corresponds to min. risk!) • For the minimum error rate, we take gi(x) = P(ωi | x) (max. discrimination corresponds to max.posterior!) gi(x) ≡ P(x | ωi) P(ωi) gi(x) = ln P(x | ωi) + ln P(ωi) (ln: natural logarithm!) Pattern Classification, Chapter 2 (Part 2) 11 Pattern Classification, Chapter 2 (Part 2) 12 • The computation of g(x) g( x ) = P ( ω 1 | x ) − P ( ω 2 | x ) P( ω1 ) P( x | ω1 ) = ln + ln P( ω 2 ) P( x | ω 2 ) Pattern Classification, Chapter 2 (Part 2) 13 Error Probabilities • Two-category case P (error ) = P ( x ∈ R2 , ω1 ) + P ( x ∈ R1 , ω 2 ) = P ( x ∈ R2 ω1 ) P (ω1 ) + P ( x ∈ R1 ω 2 ) P (ω 2 ) = ∫ p ( x ω ) P (ω )dx + ∫ p ( x ω 1 R2 1 2 ) P (ω 2 ) dx R1 Pattern Classification, Chapter 2 (Part 2) Minimax Solution 14 • Total Risk R R ( P (ω1 )) = Rmm + P (ω1 ) S Pattern Classification, Chapter 2 (Part 2)