THE PROJECT IN FURTHER DETAIL
advertisement

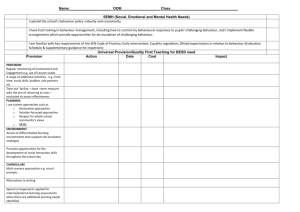
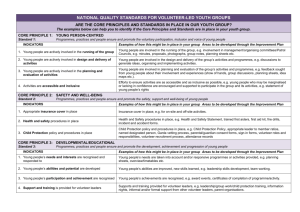
THE PROJECT IN FURTHER DETAIL As explained, the cross-national dataset of the ISRD-2 project is a unique starting point for the research we are planning to do. The standard ISRD-2 student paper and pencil questionnaire which was used in the study, was translated into the language (or languages) of the participating countries. The project followed the established, validated self-report survey method to collect data on attitudes, offending and victimisation. The questions reflected the assumptions concerning the relevance of psychological predisposition (Grasmick's self control scale), socio-demographic variables (gender, minority status, economic background), importance of family situation, school experiences, neighbourhood and school context. National level statistical indicators were also collected. The data have been collected in 2006. The sampling procedure for the ISRD-2 study was standardized to ensure robust and valid estimates of prevalence and frequencies of juvenile delinquency across participating countries. All participating countries followed the sampling protocol as closely as the specific circumstances and limitations in their country allowed. The ISRD-2 study applied a stratified random probability sample, ensuring each unit of the population had an equal chance of being selected. Stratified sampling involves the process of dividing the overall population into independent strata, which are non-overlapping subgroups of the survey population. Stratification controls the distribution of the sample size in the strata. It is a technique that is widely used in survey methodology to ensure equal probability of selection. Stratification is particularly important in a national survey. There are three main variables that were used to stratify the samples: (1) geographical area or region; (2) school type, and (3) school grade. Participants could use some extra criteria to select cities for the city samples, for example: proportion of ethnic minorities in schools or socio-economic factors. A minimum sample size for each country was set at 2100. School classrooms are the primary sampling units in this study, to be precise (all) school classes serving grades 7, 8 and 9 (the equivalent of age groups 12-13, 13-14 and 14-15) in compulsory secondary schools in all major school sectors. All the countries received a standardised personalised data entry file, a codebook and coding rules. Two cleaning stages are made using both Epidata and SPSS. They were conducted to ensure a uniform data cleaning process for all data sets. The dataset consists of 74.000 cases spread over 30 countries. Subproject 1: Science based research (building block 2) The proposed project will start with a further elaboration of the theoretical and conceptual framework and methodology. The first step in this further elaboration will be the organisation of an opening seminar bringing together the members of the national research teams and the Expert Advisory Board (EAB) (see 2.1). The theoretical and conceptual framework and methodology will be used to specify our research questions and all the steps in the research design, namely the link between concept, theory, research questions, methods, fieldwork and analysis. The seminar will be the starting point of further elaboration on understanding and operationalization of key concepts for the study. Furthermore, theoretical relations between alcohol vulnerability and multilevel governance (environmental strategies for the prevention of alcohol abuse on adolescents) will be detailed. Questions which will be answered here are: • What are the alcohol use patterns and related problem behaviours? • What can be said about the risk factors and protective factors? • What are the results of the first analyses of cross-national similarities and differences? With use of SPPS and Stata we elaborate on the prevalence and incidence of anti-social behaviour among young people aged 12-15 years in 26 countries in relation to anti-social behaviour and to determine differences for use by specific covariates. The dataset contains information about 15 offences, the use of alcohol (soft drinks and liquor), marijuana, and hard drugs (Speed, LSD, Heroin, Cocaine and amphetamine). Sub-project 2: Multilevel analyses of data (building block 3) The next objective of this research project is to compare the prevalence and incidence of alcohol use among youth of 12-15 years in 26 countries and the association with risk factors (and protective factors if possible). This part of the research will focus on two levels: the individual level (young people with covariates and risk factors) and the national level (city/nations; drug policy and other selected structural indicators). Specific research questions here are: • What are the differences in the prevalence and incidence of alcohol use among young aged 12-15 year (the first, second and third grade in secondary schools) in the 26 countries? • Is there cross-national variability in specific dimensions or patterns such as the initiation of alcohol use of this age group? • What can be said about the prevalence and incidence of other drugs use and anti social behaviour among these students? • Is there a difference in the relationships between risk factors (and protective factors) such as norms, attitudes and perceptions on the one side and alcohol use in participating countries on the other side? • Do adolescents in the countries show different combinations of alcohol use, other drug use and risk factors? • Are there specific use patterns according to gender, ethnicity, social economic status and other demographic variables and do these differences vary from one country to the other? • Are observed gender or ethnic differences in prevalence of alcohol due to differences in levels of risk factors (and protective factors)? Latent Class Analyses (LCA) will be used in this study for classification of groups of young people with different patterns of substance use. The primary objective of LCA is to find the smallest number of classes of individuals and countries with similar patterns of alcohol and drug use and anti-social behaviour that can explain the relationships among a set of observed variables. The input of the classes will be based on social theories (e.g. threshold theory or the social inequality theory). Classes are found till the model fits well (Vermunt, 2004; Muthen and Muthen, 2007). The programme Mplus will be used here. The project is based on a large volume of individual and national level data, allowing the study of multi-level contextual influences on alcohol and drug use in relation to anti social behaviour. Multilevel analyses (MLWin) will be used here to give more information on this study’s objective: identifying differences on various levels: the individual level (age, gender, ethnicity, social class), risk factors in family, school and neighbourhood, and the national level (policy variables and social economical variables) (Luke, 2004; Rasbash et al., 2005; Bickel, 2007; Rabe-Hesketh and Skrondal, 2008). To answer these questions the dataset will be analyzed and studied. Subproject 3: Analysis of multilevel policy development (governance) (building block 4) We will cluster the countries based on variables measuring the policy of the countries toward the alcohol and drug use of adolescents and the social economical status of the countries. Therefore, in the ISRD-2 study we have collected national and local structural indicators. These structural indicators provide a context for the findings, and will be used in comparative analyses. The main goal of the Local Indicators Data Collection Form was to collect statistical data that are internationally comparable, readily available, and have a clear policy- or theoretical relevance. The data collection consisted of a series of tables designed to elicit responses in the form of data, primarily statistical data, on the main local indicators for the period closest to the administration of the ISRD-2 survey. A core list of indicators that have been collected for the ISRD-2 contains information about: Population by Age and Sex, Population Diversity, Household Composition, Unemployment, Income Inequality and Poverty, Housing and Residential Mobility, Education, Officially Recorded Crime and Delinquency, Social Control by Law Enforcement. At the national level, a number of additional indicators are also available (e.g. crime and victimization data, World Values Survey data) In the participating countries, we will carry out also a multi-level policy analysis of the policies, programmes and interventions used for prevention of alcohol and other substance abuse: • Which national policies do the national governments pursue with regard to alcohol use among youth? • Which programmes and interventions are set out on the different risk factors (in families, schools and communities)? • Which programmes and interventions are set out on the individual behaviour of young people? To answer these multilevel policy questions, documents will be studied and interviews will be held with key stakeholders in each country. The gathered information will be used to generate a cross-national overview regarding the ways in which multi-level governance is applied in the field of alcohol use by young people. At the end of the project, the information will be updated per country, using telephone interviews and a review of policy documents. Sub-project 4: Possible effective strategies (Building block 5) What works is rarely a factor in implementing prevention policies, programmes and interventions. In the final part of this study scientific evidence on what works best for the prevention of alcohol use of youth will be made available to policy makers and practitioners in the different countries. In the final part of this project we study effective and promising policies, programmes and interventions for the different countries. The basis for this will be an inventory of programmes and interventions that have been evaluated and of which the effectiveness has been proved. • • • Which national policies do the national governments have to pursue with regard to alcohol use among youth? Which programmes and interventions should be set out on the different risk factors (in families, schools and communities)? Which programmes and interventions should be set out on the individual behaviour of young people? The project will produce a web based guideline where all the effective and promising programmes are available. This web based guideline will have the function of an interactive web page (wiki based). The visitors of this web-site will have the opportunity to add effective and promising programmes or information. The idea is that the quality of the information will improve because everyone is encouraged to improve the information and keep it up to date. Wiki web-site is a way to virtually share knowledge and working together to make this knowledge available to everyone. In the Netherlands the Verwey-Jonker Institute has developed such a wiki based guideline for people with mental health problems (Oudenampsen & Rijkschroeff, 2008). During the project, dissemination of knowledge is important. In the final part of the project especially the further implementation and dissemination of effective and promising programmes for prevention of alcohol abuse will be encouraged. • What can the different countries do at national level to broaden the use of effective and promising policies, programmes and interventions? • What can the EU and the different countries together do regarding this objective?