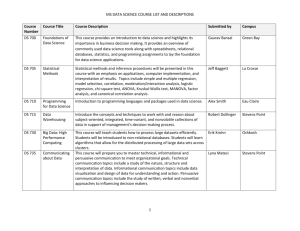
EdTech PIE2014 - Adaptivity and Personalization in Informatics
advertisement

EdTech PIE2014 Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) March 21-22, 2014 Matrix Hotel, Edmonton, AB, Canada EdTech Forum: Practices, Ideas and Experiences (EdTEch PIE) March 21-22, 2014 Matrix Hotel 10640 - 100 Avenue NW, Edmonton AB T5J 3N8, Canada Friday March 21, 2014 7:30 - 8:30 Registration and Breakfast 8:30 – 8:45 Welcome by Donna Romyn, Associate Vice President Research (Acting) 8:45 – 9:30 Educational technology showcase Maiga Chang (Athabasca University) Sanjiv Shrivastava (LMSERA) Hazra Imran (Athabasca University) Nam Hoang (Alacrity Solution) 9:30 – 9:45 Life of a Postdoc – some reflections by Hazra Imran 9:45 –10:30 Panel: Educational technology research directions Connor Gottfried (Leara eLearning Inc.) Nancy Parker (Athabasca University) Sanjiv Shrivastava (LMSERA) Evelyn Ellerman (Athabasca University) 10:30 – 11:00 Tea/Coffee Break (setting up innovation posters/tables) 11:00 – 11:45 Tutorial: Location-Based Mobile Learning (Qing Tan) 11:45 – 12:30 Educational technology showcase Linda Chmiliar (Athabasca University) Kevin Colton (Yellowjacket Software) Dietmar Kennepohl (Athabasca University) 12:30-13:30 Networking lunch (visit to innovation posters/tables) 13:30-14:30 Small group discussions Big data learning analytics Games and simulations in learning Commercialization of academic research 14:30 – 15:00 Tea/Coffee Break (visit to innovation posters/tables) 15:00 – 15:45 Panel: Academia-industry collaborations Ahmad Jawad (Intellimedia) Linda Chmiliar (Athabasca University) Nathan Friess (Lyryx Learning Inc) Stella Lee (Cadillac Fairview Corporation) 15:45 onwards Academia – industry networking (Moderator: Kinshuk) (Moderator: DietmarKennepohl) (Moderator: Evelyn Ellerman) [Facilitator: Vive Kumar] [Facilitators: Maiga Chang and Martha Burkle] [Facilitator: Hadi Shaheen] (Moderator: Linda Chmiliar) Saturday March 22, 2014 7:30 – 8:30 Registration and Breakfast 8:30 – 9:30 Presentations (Moderator: Maiga Chang) Using Healthcare Analytics to Determine a Diagnosis for Adult ADHD patients (Diane Mitchnick) Course in The Cloud: A Conceptual Framework (Guangde Xiao) Learning Analytics: Creative Data Strategies that Enhance Learning (Lorna Brown) Reading on Paper, Computer, and Tablet PC: Effects on Reading Comprehension and Effectiveness (Wei Cheng) 9:30 – 10:30 Tutorial: Intelligent Agent Technologies in Education (Oscar Lin) 10:30 – 10:45 Tea/Coffee Break (visit to innovation posters/tables) 10:45 – 11:45 Tutorial: Big data learning analytics (Vive Kumar) 11:45-12:45 Presentations (Moderator: Vive Kumar) Using Semi-Supervised Learning to Identify Students Experiencing Academic Difficulty in a Digital Education Environment (Steven Harris) Using Data Mining for Discovering User Roles in online synchronous learning (Peng Chen) Annotation Behavior Clustering (Miao-Han Chang) Relevant Factors to Identify At-Risk-Learners (Darin Hobbs) 12:45-13:30 13:30 – 14:30 Networking lunch (visit to innovation posters/tables) Presentations (Moderator: Sabine Graf) Platform Independent Game-based Educational Reward System (Cheng-Li Chen) Using Intelligent Mechanism to Enhance Adaptive Learning Systems (Charles Jason Bernard) Adaptive Learning based on a Collaborative Student Model (Jeffrey Kurcz) M-Learning projects in Alberta Schools (Dermod Madden) 14:30 – 14:45 Tea/Coffee Break (visit to innovation posters/tables) 14:45 – 15:30 Presentations (Moderator: Oscar Lin) Promoting Self-Regulatory Capacities of a Novice Programmer (Bertrand Sodjahin) Automatic Twitter Topic Summarization (Geoffrey Marshall) Agent Coordination and Reasoning Capabilities for Adaptive Assessment in Quiz Games (Steeve Laberge) 15:30 – 16:30 16:30 Tutorial: Enhanced Learning and Teaching Support through Adaptive and Intelligent Systems (Sabine Graf) General networking IGRW2014 Proceedings of 2nd International Graduate Research Workshop March 21-22, 2014 Matrix Hotel, Edmonton, AB, Canada Edited by Dr. Maiga Chang School of Computing Information and Systems Athabasca University Proceedings Using Healthcare Analytics to Determine a Diagnosis for Adult ADHD patients Diane Mitchnick ........................................................................................................................................... 1 Course in the cloud: a conceptual framework Guangde Xiao ............................................................................................................................................... 3 Learning Analytics: Creative Data Strategies that Enhance Learning Lorna Brown................................................................................................................................................. 5 Reading on Paper, Computer, and Tablet PC: Effects on Reading Comprehension and Effectiveness Wei Cheng .................................................................................................................................................... 7 Using Semi-Supervised Learning to Identify Students Experiencing Academic Difficulty in a Digital Education Environment Steven C. Harris ........................................................................................................................................... 9 Using Data Mining for Discovering User Roles in online synchronous learning Peng Chen .................................................................................................................................................. 11 Annotation Behavior Clustering Miao-Han Chang ........................................................................................................................................ 13 Relevant Factors to Identify At-Risk-Learners Darin Hobbs ............................................................................................................................................... 15 Platform Independent Game Based Educational Reward System Cheng-Li Chen............................................................................................................................................ 17 Using Intelligent Mechanisms to Enhance Learning Management Systems Charles Jason Bernard ............................................................................................................................... 19 Adaptive Learning based on a Collaborative Student Model Jeffrey M. Kurcz ......................................................................................................................................... 21 M-Learning projects in Alberta schools Dermod Madden ......................................................................................................................................... 23 Promoting Self-Regulatory Capacities of a Novice Programmer Cadoukpe Bertrand Sodjahin ..................................................................................................................... 25 Automatic Twitter Topic Summarization Geoffrey Marshall....................................................................................................................................... 27 Agent Coordination and Reasoning Capabilities for Adaptive Assessment in Quiz Games Steeve Laberge............................................................................................................................................ 29 i ii 2nd International Graduate Research Workshop (IGRW 2014) 1 Using Healthcare Analytics to Determine a Diagnosis for Adult ADHD patients Diane Mitchnick, Athabasca University dianemitchnick@hotmail.com mental illness. Abstract— Healthcare data mining is becoming increasingly essential to prediction modeling of diseases and illnesses. Contemporary data mining approaches have utilized simulation programs, diagnostic tools, and medical dictionaries with the assumption of availability of well-defined healthcare data. Healthcare analytics on the other hand, assumes that the quantity of continuously incoming data is big and further assumes the availability of structured, semi-structured, and unstructured data. This research explores big data analytics in the field of mental health, specifically in adult ADHD (Attention Deficit Hyperactivity Disorder). This workshop proposal presents the approach, challenges, and potential benefits of healthcare analytics in ADHD. We contend that an analytics based approach will be more beneficial in key areas of healthcare in addition to data mining based approaches. Index Terms—Healthcare Analytics, Education, Data Mining, ADHD I. INTRODUCTION T HE idea of using medical data for statistics is not a new one. Medical data has been a part of research studies for some time, especially in physical diseases and illnesses. In recent years, computers and the Internet have both become tools for recording and storing this data as well as filtering it. As advances in medical research such as simulations and test cases have been popularized, so has the idea of analyzing the data collected for this research through simulated and test processes [1]. Many tools currently do linear data mining, in the sense that they collect the data and filter through an algorithm to match an existing condition definition. This process can create issues since the data is not does not have a sufficient collection time length (data may have been collected a month ago and a patient’s symptoms may have changed since then; a factor that might alter the diagnosis), and the data is being drawn from one database, which may not capture all the information on the patient. Currently there is machine learning research being done to diagnose physical diseases such as brain tumors, prostate cancer and diabetes [2]. However, mental health diseases are a little harder to determine, as they revolve around behavioral symptoms instead of physical ones. Still, the same principle can be applied using patient data to classify attributes that define the The focus of this study will be one mental illness in particular. Attention-deficit hyperactivity disorder (ADHD) is a mental health disease that can have physical symptoms as well (fatigue, muscle tension/stress). Its primary symptoms are inattentiveness, hyperactivity and impulsiveness [3]. By using historical patient data that caters to these main characteristics, diffusion or causal models can be created to predict the mental status of the patient. The objective of this workshop is to discuss the role that healthcare analytics could potentially play in the assessment and diagnosis of mental health patients with ADHD symptoms or attributes. This discussion may include any or all of the following topics: • How traditional assessment of ADHD may be assisted by healthcare analytics. • Available tools for healthcare analytics, which metrics they record, and how each may be useful in the field. • Ideal tools, systems and interfaces for the systems that would make use of the analytics. Analytics and healthcare analytics in particular are defined in the discussion below, along with a brief coverage of the above topics. II. EXPECTED AUDIENCE The intended audience of this workshop includes computing professionals, instructors and students of medicine, nursing or psychology, and general educators. Computing professionals will lend insight into technical considerations and advise on the tools available for analytics. Those with a background in data mining or a similar discipline will find themselves comfortable with the discussion. Students and educators will advise on how analytics may help them, and provide suggestions from a more practical and perhaps non-technical standpoint. III. OUTCOMES By the end of the workshop, participants will have a better understanding and possible discussion of diagnostics that Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 2 leverage healthcare analytics, consider the sort of data that would be useful, and current state of the art in analytical methods. These ideas and suggestions should be recorded for use in future and current research endeavors. IV. DISCUSSION To guide the workshop proceedings, a number of definitions and points are made in the discussion below. A. Definitions Analytics is the science of analysis. Analysis is defined as the separation of an entity into its constituent parts, and the use of this separation to study the features and relations of that entity [3]. Analytics are usually quantitative in nature, but may be qualitative as well. Healthcare analytics, then, are the metrics that can be calculated from patient data. Simple healthcare analytics can be (and often are) collected manually, such as the keywords for a hand-written patient chart. The patient data is referred to as “big” data, which means it is so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications [5]. Simple analytics include diagnostic keyword matching and symptom keyword matching. More complex metrics include co-variance checks on elements, and causation modeling on external factors. A standard or controlled variable in the study will be the classifier that defines ADHD. This classifier will be the standard when using keyword (symptom) matching from the patient data. Using the classifier for the ADHD from the Diagnostic and Statistical Manual of Mental Disorders (DSM-IV), at least 6 inattentive-type symptoms must be displayed, at least 6 hyperactive-type symptoms must be displayed and all symptoms must have a combined type that limits their functioning in two areas (ex. home, school or work) over the last 6 months. The individual must have had these symptoms in their childhood (before age 7). B. Collection and Use of Healthcare Analytics The study will be a prospective observational diagnostic study, with patient data being collected from three high-traffic hospitals. The study will be done on 20 adults from each hospital (60 patients total as a sample size) between 18-24 years in age exhibiting primary ADHD symptoms. The symptoms will be assessed by a computerized diagnostic tool, stripping the data of keywords such as “hyperactive”, “brain cc” (volume size), “brain structural deviations” or “brain functioning” (development issues). The keywords will be grouped by occurrences with ANCOVA [6] tests being done on them to reduce variance on the relationship pattern and validate the relationship between the symptom and the classifier. If the correlation ratio is closest to the diagnosis terms, the closest the model diagnosis is to the actual classification. C. Analytic tools in Healthcare A research effort by Athabasca University is leading to the development of a tool that will combine these methods and models, and make use of healthcare analytics to provide a more complete picture of student learning. The proposed tool will analyze historic patient data using the methodologies mentioned above. The tool will make note of certain patterns in the analysis and use the patterns to define its own algorithms for matching. The resulting information will be compiled and available to the instructor, student or medical practitioner. In order to promote maximum utility, the tool will be developed as a web application, allowing many institutions to begin using it with minimal restructuring of curricula or programs. ACKNOWLEDGMENT The author would like to thank Athabasca University for the implementation of this workshop, and their continuing devotion to academic research. Further thanks go to Dr. Vive Kumar for overseeing analytics research, and to the iCORE research program for hosting the International Graduate Research Workshop. REFERENCES [1] Hasan, A. R., Kamruzzaman, S. M., Mazumder, M. E., & Siddiquee, A. B. (2004). Medical Diagnosis Using Neural Network. Retrieved February 5, 2013, from Arxiv: http://arxiv.org/ftp/arxiv/papers/1009/1009.4572.pdf [2] Mirzazadeh, F. (2010). Using SNP Data to Predict Radiation Toxicity for Prostate Cancer Patients. Retrieved March 20, 2013, from University of Alberta - Research Papers: http://papersdb.cs.ualberta.ca/~papersdb/uploaded_files/1039/paper_Mi rzazadeh-Farzaneh-MSc-Thesis.pdf [3] Quinn, D. P. (2012, July 7). Attention-Deficit/Hyperactivity Disorder: Causes of ADHD. Retrieved March 14, 2013, from WebMD: http://www.webmd.com/add-adhd/guide/adhd-causes [4] Dictionary.com, "analysis," in Dictionary.com Unabridged. Source location: Random House, Inc. http://dictionary.reference.com/browse/analysis [5] Kusnetsky, D. (2010, February 16). What is ‘Big Data’? Retrieved September 12, 2013, from ZDNET: http://www.zdnet.com/blog/virtualization/what-is-big-data/1708 [6] Wyseure, G. (2003, March 31). ANCOVA. Retrieved March 24, 2013, from KU LEUVEN: http://www.agr.kuleuven.ac.be/vakken/statisticsbyR/ANOVAbyRr/ANC OVAinR.htm Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 3 Course in the cloud: a conceptual framework Guangde Xiao, Beijing Normal University xiaoguangde@163.com Abstract— Although education based on technology has succeeded in implementation of many pedagogical requirements, there is still some questions for which we must consider better solutions. Current education is not scalable, it is not geared for today’s globalization, it does not take proper advantage of today’s technology; the current educational paradigm is focused on creating mass production, and does not concern individual students. Facing with the transformation of the society, learning needs is also changed. To support this, we need to consider that: learner community is expanding; learning contents need better structure; learning process needs to provide various optimal learning solutions. Taking advantage of the potential of current technological advancements, we can develop a new kind of online course which can support better experience of online learning, more learning analytics and global collaboration and sharing of resources. The proposed conceptual framework including three components: knowledge nodes, learners’ network, learning process. According this framework, online course can meet the emerging learning needs of online learning. Index Terms—Conceptual framework, Course in the cloud, Online course V. INTRODUCTION I n the development process, although education based on technology has succeeded in implementation of many pedagogical requirements, the current education is not scalable for the reason of lack of pedagogical feasibility. Because a pedagogical strategy that is successful in one particular classroom setting with one particular group of students frequently will not succeed in a different classroom with other students[1]. Globalization has influenced the educational philosophy and classroom practices all over the world[2]. Especially, Contemporary higher education has been impacted deeply by globalization[2][3][4]. Globalization provides learners the opportunity to access high-quality education without the restrictions imposed by physical or socio-economic circumstances. But the current education is not geared for today’s globalization. The best learning resources just belong to few schools in an area rather than focus on a perspective of global sharing. In contrast to experiences in other sectors, the current education does not take proper advantage of today’s technology. The transform in education enhanced by technology should be a whole systematical change rather than part application for special objective with some elements of education. Another problem is that the current educational paradigm is focused on creating mass production, and does not concern individual students. Deeply ingrained in the structure of schooling is a mass-production notion of uniform learning. This belief stipulates that everyone should learn the same things at the same time [5]. No matter educators, parents, or students have long dreamed of the possibility of personalized education and more engaging. With the emergence of new technologies, better solutions on education will be possible. This paper is to propose a new type of online course aimed to promote more flexibilities and better quality learning content, and illustrate its conceptual framework and the potential benefits to individual learner based on globalize perspective. VI. EMERGING CHALLENGES: CHANGES IN LEARNING NEEDS From the starting in the 1970s, in all the key dimensions of social organization and social practice, network technology gradually had a pervasive impact on society. Many researchers put forward the term information society even knowledge society. Knowledge society is stimulated and driven by creativity and ingenuity. While most of today’s schools and the paradigm of education were designed to prepare young people for the industrial age rather than a knowledge society [9]. Faced with this challenge posed by the enormous changes of society, from the educational perspective, we must consider the following questions: • What kind of citizens we need? Now, we need individual people with creativity and advanced intellectual skills, we need individual thinkers. • What are the characteristics of today’s learners? Today’s kids are digital natives, multi-takers, visual expression, connected learning, experiencing learning; • What kind of learning we need? We need to take advantage of opportunistic learning; we need to integrate formal and informal learning; To support this, we need to consider that: • Learner community is expanding. We need solutions that can get expertise from any part of the world and provide that to students globally. • Learning contents need better structure Current online courses are typically a list of topics, The structure need to be better to suit individual learners, the context of learning, and the current need of globalized market. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) • 4 It is impossible to create high quality of content in local level; and OER movement provide the solution, we need to take advantage of that. Learning process needs to provide various optimal learning solutions To analyze learners, their interactions goals, objectives, through learning analytics, and provide various solutions for effective learning. Knowledge nodes Learning objectives concepts and inherent relationship Learning and assessment objects (local and Course in the Cloud Leanrers’ Leanrers’network VII. POTENTIAL OF CURRENT TECHNOLOGICAL ADVANCEMENTS: A CASE IN THE CLOUD Explain the case in the cloud, which is based on the following three dimensions) [find benefits from literature for each dimensions and components] (1) Online learning (concept, experience, feedback), (2) Learning analytics (supporting personalized learning, analyzing patterns for effective supporting as micro, meso and macro level), (3) Cloud computing (global collaboration and sharing of resources between contents, subject matter experts, pedagogics, and students) • Conception of cloud computing • Features of cloud computing • Cloud Computing as Service (in very short abstract) • SaaS • PaaS • IaaS • Three technical pillars for building online courses in the cloud • Technical obstacle-free learning environment • Service - oriented course model • Powerful backend computing capabilities Learner model; Teacher model Connections among learners In this part, we will illustrate the vision of what kind of educational system do you foresee in the future. Then we will give a definition of course in the cloud and the interpretation of the framework of course in the cloud. • Definition Knowledge nodes • Learning process • Learners’ network • Interdependencies among the components Teaching models Platforms Delivery strategies Student-student interaction Student-teacher interaction Learning process Learning strategy;Assessment strategy Pedagogy; Suggested learning paths Feedback Learning behaviors Fig. 1. The conceptual framework of course in the cloud. • Benefits of the framework; • Any limitations, may have some other dimensions the framework may not cover; some interdependencies were not explored; • Future of courses in the cloud; • Emerging research directions; REFERENCES [1] [2] [3] VIII. PROPOSED SOLUTION: FRAMEWORK OF COURSE ON THE CLOUD external ) [4] [5] [6] J. Clarke, C. Dede, and D. J. Ketelhut, “A design-based research strategy to promote scalability for educational innovations,” Educ. …, 2006. B. Anyikwa, M. Amadi, and P. Ememe, “Globalization and the Context of Future Higher Education in Nigeria,” Humanit. Soc. Sci. J., 2012. J. Shin and G. Harman, “New challenges for higher education: Global and Asia-Pacific perspectives,” Asia Pacific Educ. Rev., 2009. S. Bakhtiari and H. Shajar, “Globalization and Education: Challenges and opportunities,” Int. Bus. Econ. …, 2011. A. Collins and R. Halverson, Rethinking education in the age of technology: The digital revolution and schooling in America. New York: Teachers College Press, 2009. A. Bailey, T. Henry, L. McBride, and J. Putcket, “Unleashing the potential of technology in education,” Bost. Consult. Gr., 2011. IX. A SCENARIO OF COURSE IN THE CLOUD Through an example, we will illustrate what are the different possibilities that will happen by using the framework? X. CONCLUSION In this section, we will draw conclusion from the following aspects: Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 5 Learning Analytics: Creative Data Strategies that Enhance Learning Lorna Brown, Athabasca University lbrown@computer.org Abstract—Learning Analytics tools and dashboards have great potential for improving education. Resilience and self-awareness are qualities that lead to student persistence. However existing tools focus mainly on educators and designers and overlook student needs. These topics are discussed and investigation into a persistent Learning Analytics dashboard for students is proposed. Index Terms— higher education, learning analytics, persistence, self-regulated learning I. INTRODUCTION L EARNING Analytics (LA) is defined as “the measurement, collection, analysis and reporting of data about learners and their contexts, for purposes of understanding and optimizing learning and the environments in which it occurs” [1]. Most educational analytic processes use collected data to improve next semester's course. In contrast LA seeks to use data to personalize and improve learning in real time [2]. Current research in Learning Analytics indicates it has great potential for improving teaching and learning. Proponents believe that for the field to grow and thrive it is necessary for openness and collaboration between technical, pedagogical and social domains [3]. Higher Education (HE) programs can benefit from LA tools that combine data collection and analysis with educational goals such as collaboration, awareness and reflection [4]. However the majority of existing analytic dashboards and tools are directed towards teachers and/or designers. Only a few dashboards and tools are oriented towards students, and these are on a course by course basis. To date I have not found any that encompass the learner's journey throughout their HE program. In this extended abstract I will briefly review existing LA tools and dashboards, discuss student resilience and self-regulation, and outline my intention for an expanded paper. II. EXISTING TOOLS AND DASHBOARDS A. For Instructors and Designers eLAT processes large databases from various LMS to support teacher reflection and improvement of online learning [5]. LASSIE provides useful statistics about the Landing, Athabasca University's social networking site that promotes formal and informal learning [6]. MooDog (Moodle Watchdog) tracks learner activity from Moodle logs and provides information to instructors and researchers [7]. SNAPP is a social network analysis tool that provides instructors with visualization and analysis of student interactions in discussion forums [8]. LOCO-Analyst is a feedback tool for teachers to improve content and instructional design [9]. GISMO extracts tracking data from Moodle and generates visualizations for course instructors [10]. CourseVis obtains tracking data from WebCT and generates visualizations for instructors [11]. EDMVis is a domain-independent visualization tool for student data logs [12]. Course Signals uses a predictive student success algorithm and data from Blackboard Vista to predict student risk status [13]. B. For Learners and Instructors StepUp! is a tool that enables students to reflect on their own activity as well as the activity of other students [14]. CAMera was designed to collect usage metadata, monitors and reports on user actions, and fosters learning process reflection and self-regulated learning [15]. SAM. The Student Activity Meter assists learners with self-reflection and teachers with awareness [16]. E2Coach uses survey results and student data from a variety of sources to create a personalized web page of information and advice to students [17]. C. Other Tools The Professional Development Center (PDC) of Farmers Insurance (University of Farmers, Claims’) is an application for personalized employee training. Each employee has a dashboard that they and their supervisors and mentors can access, and learning is tracked throughout employment [18]. SMILI is a framework to discuss and compare adaptive educational systems [19]. III. RESILIENCE, SELF-REGULATION, AND PERSISTENCE The ability to make adjustments is essential to student success. Researchers at the Canada Millennium Scholarship Foundation describe student resilience as “the capacity to overcome obstacles, adapt to change, recover from trauma or to survive and thrive despite adversity” [20]. They discovered that many students who discontinue their post-secondary studies will later Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 6 re-enroll, often in another program. Resilience is an essential quality of those students who persist and graduate. Therefore an appropriate tool that follows students throughout their HE experience could enable them to self-regulate, to see roadblocks to avoid, and to create patterns of success. Common questions students ask include: “how am I supposed to complete this task?” and “what are other students doing?” Time management visualizations, recommendation engines, strategies and advice from other students … LA dashboards can help students answer these questions. "For learners and teachers alike, it can be extremely useful to have a visual overview of their activities and how they relate to those of their peers or other actors in the learning experience." [21] From a student point of view much information relating to their HE program is dispersed. For example the course requirements and student summary is often distributed among many emails, several electronic documents, the course Learning Management System, the Registrar's site, some written correspondence, or perhaps not documented at all. The information is scattered about the institution and the student’s world. Consider the benefits of a dashboard application such as Farmer's PDC [18] that could be a central point for planning, correspondence, self-regulation and other educational needs throughout student's time at the HE institution. interactions, and when interactions are sparse, indicating problems. Ideally, the LA dashboard will also act as a mirror that enables learners to become more reflective and less dependent [22]. REFERENCES [1] [2] [3] [4] [5] [6] [7] [8] IV. A PERSISTENT DASHBOARD In an expanded paper I will propose a design for a HE dashboard that is student oriented, enables student input, recommendations, self-discovery, and self-regulation. It will accompany the student throughout their HE journey at the institution, even if they change course direction or change program. This concept of persistence differentiates it from other dashboards and tools. Students will see their core courses required, those in progress, and those completed. They will be able to view possible course routes or program routes such as essay, project or thesis. Students will be able to search for extra learning opportunities both inside and outside the institution: presentations, workshops and MOOCs. There will be communication sections to track personal and general correspondence: email, announcements, important program messages from student advisors, etc. Students will be able to consent to participate in extra tracking/analytics and then see the benefits of their participation. Topics I intend to discuss include: what data can be collected, privacy concerns, how the data can be analyzed, what can be learned, and what can be done with this data. There are several possible advantages of this dashboard; students will have a central site for their information. The institution will have a better interface to track data such as interactions. For example how much communication via email is occurring between student and advisor? How many phone calls between the student and the instructor? The dashboard could answer questions such as which courses generate more [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] Society for Learning Analytics Research. About, 2014. Available: http://www.solaresearch.org/mission/about/ T. Elias. 2011. Learning Analytics: Definitions, Processes and Potential. [Online]. Available: http://learninganalytics.net/LearningAnalyticsDefinitionsProcessesPoten tial.pdf G. Siemens and D. Gasevic, "Guest Editorial-Learning and Knowledge Analytics," Educational Technology & Society, vol. 15, no. 3, pp. 1-2, 2012. K. Verbert, S. Govaerts, E. Duval, J. Santos, F. Assche, G. Parra, and J. Klerkx, "Learning dashboards: an overview and future research opportunities," Personal and Ubiquitous Computing, pp: 1-16, 2013. A. L. Dyckhoff, D. Zielke, M. A. Chatti, and U. Schroeder, "eLAT: An Exploratory Learning Analytics Tool for Reflection and Iterative Improvement of Technology Enhanced Learning," EDM, pp. 355-356, 2011. N. Rahman and J. Dron, “Challenges and Opportunities for Learning Analytics when Formal Teaching Meets Social Spaces,” in Proceedings of the 2Nd International Conference on Learning Analytics and Knowledge, New York, 2012, pp. 54-58. H. Zhang and K. Almeroth, "Moodog: Tracking Student Activity in Online Course Management Systems," Journal of Interactive Learning Research, vol. 21, no. 3, pp. 407-429, July 2010. A. Bakharia and S. Dawson, “SNAPP: a bird's-eye view of temporal participant interaction,” in Proceedings of the 1st International Conference on Learning Analytics and Knowledge, New York, 2011, pp. 168-173. J. Jovanović, D. Gasević, C. Brooks, V. Devedzić, and M. Hatala, "LOCO-analyst: A tool for raising teachers’ awareness in online learning environments," Creating New Learning Experiences on a Global Scale, Springer, 2007, pp 112-126. R. Mazza and L. Botturi, "Monitoring an Online Course With the GISMO Tool: A Case Study," Journal of Interactive Learning Research, vol. 18, no. 2, pp. 251-265, April, 2007. R. Mazza and V. Dimitrova, “CourseVis: A Graphical Student Monitoring Tool for Supporting Instructors in Web-based Distance Courses,” Int. J. Hum.-Comput. Stud., vol. 65, no. 2, pp. 125-139, Feb. 2007. M. Johnson, M. Eagle, L. Joseph, and T. Barnes, "The EDM Vis Tool," in Proceedings of the 3rd Conference on Educational Data Mining, 2011, pp. 349-350. K. E. Arnold and M. D. Pistilli, “Course Signals at Purdue: Using Learning Analytics to Increase Student Success,” in Proceedings of the 2Nd International Conference on Learning Analytics and Knowledge, 2012, pp. 267-270. J. L. Santos, K. Verbert, S. Govaerts, and E. Duval, “Addressing Learner Issues with StepUp!: An Evaluation,” in Proceedings of the Third International Conference on Learning Analytics and Knowledge, 2013, pp. 14-22. H-C. Schmitz, M. Scheffel, M. Friedrich, M. Jahn, K. Niemann, and M. Wolpers, “CAMera for PLE,” in Learning in the Synergy of Multiple Disciplines, Lecture Notes in Computer Science, vol. 5794, Springer Berlin Heidelberg, 2009, pp. 507-520. S. Govaerts, K. Verbert, E. Duval, and A. Pardo, “The Student Activity Meter for Awareness and Self-reflection,” in CHI '12 Extended Abstracts on Human Factors in Computing Systems, 2012, pp. 869-884. T. McKay, K. Miller, and J. Tritz, “What to Do with Actionable Intelligence: E2Coach As an Intervention Engine,” in Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, 2012, pp. 88-91. E. Masie, Big Learning Data. Alexandria, VA: ASTD Press, 2013, pp. 85-95. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 7 Reading on Paper, Computer, and Tablet PC: Effects on Reading Comprehension and Effectiveness Wei Cheng, Beijing Normal University chengweirzh@163.com Abstract—With the widespread use of the Table PC (Such as Apple iPad) in school and at home, there is an ongoing transition of reading from print to screen. This study examines the reading comprehension and reading effectiveness of linear text passages with three media platforms (Paper, Computer and Tablet PC) and reading strategies (Underline and Look-back). 90 university students will take part in this research. Index Terms—Screen Reading, Digital Reading, Reading Comprehension, Reading Effectiveness, iPad I. INTRODUCTION R EADING, and more importantly, comprehension, is a fundamental skill necessary for the successful completion of almost any type of class as well as in the job marketplace. With the widespread use of the digital devices (computers, tablet computers, and handheld devices) in our daily life, nowadays, we are immersed in a wide variety of screens [1]. Currently, most reading is either of the printed text from ink or toner on paper, such as in a book, magazine, newspaper, leaflet, or notebook, or of electronic displays, such as computer displays, television, mobile phones or e-readers. Therefore, there is an ongoing transition of reading from paperbound to screen-based. It is obvious that the reading devices emerge in an endless stream. So many studies have been addressing the impact and effects of reading on different media platform. Some studies focused on the effects of the paper and video display terminals (VDT) [2][3][4], the others explored the differences between paper reading and the computer reading[5][6][7][8][9]. Then, e-Reader was introduced as a new member of the reading devices[10][11][12]. Some studies revealed that the reading comprehension on an electronic display (such as computer screen, PDA screen) was poorer than the reading comprehension on paper[4] [9].Noyes & Garland[6], however, found there was no significant difference on reading comprehension between VDT and paper-based text. With the widespread use of the tablet computer (such as Apple iPad, Microsoft Surface and etc.) from 2010[15], the interactivity (multi-touch) and flexibility (easy to get the content) of the tablet computers will change the paradigm of reading and learning. Many teachers use the tablet computer to support the teaching, and the students use them to facilitate the learning in the classroom and outside. Obviously, comparing the computer, the reading operation style of the Tablet PC is similar to the paper: the same page direction and etc. However, many of the texts that university students read for academic purposes are digitized linear text. Hence, in our study, we focused on compare the linear text reading in different media platform and different reading strategies. There were different methods to measure the reading performance. Most of the studies compared the accuracy of the reading comprehension questions [3][4]; some of the studies examined the performance of the summarization [4][7][8].. Hence, the aim of the research is to explore the impact and effects of the media platforms and reading strategies on reading performance. The research question consists of two key issues, as follows: (1) Is there any difference on reading comprehension and reading effectiveness among the tablet, computer, and paper? (2) Is there any difference on reading comprehension and reading effectiveness among the different reading strategies? II. RESEARCH METHODS A. Research Design The present research used a two-factor design, with media platforms (Paper-P, Computer-C, and Tablets PC-T) and reading strategies (Underline-U, Look-back-L, None-N) as between-subjects factors. The dependent variables were reading comprehension (the score of the multiple-choice comprehension questions, the score of the summarization), reading effectiveness (reading satisfaction, mental load, mental effort, and self-efficacy). B. Participants 90 participants will be recruited by online advertisement for this research and were paid for a 60-min session. They are sophomore students (20-23 years old). They are randomly assigned to 9 groups. All the participants are Chinese native speakers and have passed the China’s College Entrance Examination (CCEE). C. Materials and Instruments 1) Reading Materials There are 44 passages of Language Arts Exam of CCEE in 2013. Four experts selected four expository passages from the 44 passages. Passage 1 was for practical test, and the other three were for the formal test. Passage 2 is about the customary Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 8 society with 1050 Chinese characters; Passage 3 is about the born of Lao Tzu and his books with 1099 Chinese characters; Passage 4 is about the viruses with 1085 Chinese characters. The four experts confirmed that these three passages had the same readability and difficulty. 2) Reading Instruments The three passages were presented via three media platform. They have the same page layout, including font size, typeface, font color, and line spacing (B5 size, 12 points, Song font, and 1.3 times line spacing). For the paper condition, the passages were printed on B5 paper (176 × 250mm). For the computer condition, the same passages were presented as PDF-files with Adobe Reader XI for Windows, at 100% scale. The computer display was 12.5’’ LCD monitors operating at 60Hz, at a resolution of 1366*768 pixels. For the Tablets PC condition, all passages were presented as ePub-files, using iBooks 2.0 for iPad 3. D. Reading Comprehension 1) Reading Comprehension Test Reading comprehension test will be assessed using multiple-choice comprehension questions. After reading each passage, there will be 5 multiple-choice comprehension questions. Four possible answers follow each question. The dependent variable of reading comprehension is represented by the participants’ raw scores on this task, with a possible range of 0-15. 2) Summarization The four experts made the scoring rubric on summarization. The full score is 10 for each summarization. After all the participants have finished the task, two of the experts will give the scores for all the participants. E. Reading Effectiveness The reading effectiveness will be measured by the self-report scale, which includes 4 parts and 21 items: reading satisfaction, mental workload, mental effort and self-efficacy. They are all 5-point Likert scales: Strongly agree, Agree, Neutral, Disagree, Strong disagree. 1) Reading Satisfaction I am satisfied with the reading. I like reading in this way. It will help me to understand what I have read. I think, it is the best way for reading. I think, it is the best way for reading comprehension. I think I can get a good score. 2) Mental Load It is difficult for me to read these passages. I understand the passage with a lot of effort. During the reading, I feel very tired. During the reading, I feel frustrated. I have not enough time to finish the reading. 3) Mental Effort During the reading, I’m under a lot of pressure. It will need great effort to read. I find it difficult to understand the passages. 4) Self-Efficacy I believe I understand the passages I have read. I can remember the main content of the passages. I believe I can get good scores on the multiple-choice. I believe I can get good scores on the summarization. I am good at reading. I feel confident about reading. F. Procedure The research are composed of the following sessions. The participant are told the experiment object and procedure, and asked the experience and frequency of the use of computer and Tablet PC. Then read Passage One and finished the task for practice. At last, there were three passages to read with the Latin Square Design. While reading the passages, the participants in Group N and L cannot write any note, or make any notations, but the participants in Group M can underline the key texts. During the pilot study, we found that all the participants can finish reading each passage in 4 minutes, so all the participants will have 4 minutes to reading each passage. After reading each passage, there were 5 multiple-choice questions to complete, and then wrote the summarization of 80-120 Chinese characters. For the participants in Group L, they can look back the texts during the task. All the multiple choices test and summarization will be presented and finished on paper. REFERENCES [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] “Screen reading,” Wikipedia, the free encyclopedia. 06-May-2013. D. K. Mayes, V. K. Sims, and J. M. Koonce, “Comprehension and workload differences for VDT and paper-based reading,” International Journal of Industrial Ergonomics, vol. 28, no. 6, pp. 367–378, Dec. 2001. J. M. Noyes and K. J. Garland, “VDT versus paper-based text: reply to Mayes, Sims and Koonce,” International Journal of Industrial Ergonomics, vol. 31, no. 6, pp. 411–423, Jun. 2003. E. Wästlund, H. Reinikka, T. Norlander, and T. Archer, “Effects of VDT and paper presentation on consumption and production of information: Psychological and physiological factors,” Computers in Human Behavior, vol. 21, no. 2, pp. 377–394, Mar. 2005. C. Spencer, “Research on Learners’ Preferences for Reading from a Printed Text or from a Computer Screen,” Journal of Distance Education, vol. 21, no. 1, pp. 33–50, Jan. 2006. J. M. Noyes and K. J. Garland, “Computer- vs. paper-based tasks: Are they equivalent?,” Ergonomics, vol. 51, no. 9, pp. 1352–1375, 2008. G. Yu, “Effects of Presentation Mode and Computer Familiarity on Summarization of Extended Texts,” Language Assessment Quarterly, vol. 7, no. 2, pp. 119–136, 2010. R. Ackerman and T. Lauterman, “Taking reading comprehension exams on screen or on paper? A metacognitive analysis of learning texts under time pressure,” Computers in Human Behavior, vol. 28, no. 5, pp. 1816–1828, Sep. 2012. A. Mangen, B. R. Walgermo, and K. Brønnick, “Reading linear texts on paper versus computer screen: Effects on reading comprehension,” International Journal of Educational Research, vol. 58, pp. 61–68, 2013. T. Tees, “Ereaders in academic libraries: a literature review,” Australian Library Journal, pp. 180–186, Jan. 2010. D. Zambarbieri and E. Carniglia, “Eye movement analysis of reading from computer displays, eReaders and printed books,” Ophthalmic and Physiological Optics, vol. 32, no. 5, pp. 390–396, 2012. S. J. Margolin, C. Driscoll, M. J. Toland, and J. L. Kegler, “E-readers, Computer Screens, or Paper: Does Reading Comprehension Change Across Media Platforms?,” Applied Cognitive Psychology, vol. 27, no. 4, pp. 512–519, 2013. L. Johnson, S. Adams Becker, and M. Cummins, “The NMC Horizon Report: 2012 Higher Education Edition,” The New Media Consortium, Austin, Texas, USA, 2012. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 9 Using Semi-Supervised Learning to Identify Students Experiencing Academic Difficulty in a Digital Education Environment Steven C. Harris, Athabasca University steve@employinginnovation.com Abstract—Text-based natural language classifiers have been used extensively for opinion and sentiment analysis of social media communities, online reviews, and a wide array of related data mining applications. Correctly identifying author emotion in a stream of text presents a number of challenges including accurate language parsing, differing perspectives between author and reader, and the general difficulty in accurately classifying natural language semantics. This research documents the testing of a number of machine learning algorithms types, in an effort to identify the best option for the development and testing of a similar classifier specifically designed to identify students who have become frustrated or confused in a digital learning environment, based on the language used in class discussion forums or messaging systems. Ultimately we see this work being especially useful to academic institutions – especially offering some form of digital or course or massive open online courses (MOOCs) – where instructors and administrators may be unable to read every individual forum or discussion item, but require an automated system to alert them of students who have run into difficulty so that they may propose corrective actions. Index Terms—natural language processing, online courses, educational data mining, sentiment analysis I. INTRODUCTION S ENTIMENT analysis, or opinion mining is the application of a set of probabilistic models in an attempt to classify the opinions or attitudes of the content creator though the language and text used in source materials. It is a fast growing area of research, somewhat similar in nature to email spam analysis, though requiring more refined machine learning techniques and sophisticated algorithms that can identify special language characteristics, such as sarcasm or humor, which may not be necessary to recognizing spam. A wide variety of approaches have been taken in an attempt to develop and train classifiers that can handle the specific and unique characteristics of the source data. And because virtually every data set is relatively unique, classifiers tend to work best on the texts and subject matter they are trained and developed for, and fare very poorly when attempting to classify even closely related or similar domains. The most common approach focuses on simple, supervised learning agents, which are trained on a percentage of expected content types, prior to their use in a production environment. Other approaches, such as the semi-supervised approach proposed by Suzuki et al. have also proven promising even with fairly small datasets (Liu, 2010). The online education environment, such as those based in Moodle or Blackboard, and larger MOOC environments with built-in student discussion forums and heavy dependence on written communication, creates an interesting opportunity to apply the principles of sentiment analysis to the digital classroom. In this research we are working with sample data taken from the actual discussion forums and messages of a Moodle-based introductory Computer Science course, and using classifier models in order to evaluate the success rate of each one: a naïve Bayesian classifier, and decision tree classifier, and an SVM classifier. The purpose of this research is to create a a natural language text-based sentiment analysis agent which can benefit from ongoing semi-supervised learning from conversations in the discussion or forum interfaces, identify and alerting administrators to significant, abrupt changes in user sentiment, or related conversational speech patterns that might indicate an increased level of student frustration or a lack of academic understanding of course material. II. EXPERIMENTAL SETUP Automated sentiment analysis involves defining an opinion as a quintuple (ei, aij, ooijkl, hk, tl), where ei is the topic or event, aij is a feature or aspect of the topic or event, ooijkl is the sentiment classification, hk is the opinion holder, and tl is the time identifier (Liu, 2011). In other words, an opinion oojkl is given by opinion holder hk about feature ajk of product ei at time ti (Liu, 2011). And all five must be identified and parsed together in a pre-processing step prior to classification. In fact, part of the difficulty in developing and experimenting with sentiment analysis learning agents is that, given the collection of opinion quintuples and a set of documents D, in order to begin the process of sentiment analysis one must first go about extracting all of the opinion quintuples for every Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 10 opinion in the document set, even before any analysis can occur. This mean parsing out opinions or sentiments, and then applying semantic rules to ensure that the feature, aspect, opinion, opinion holder and time all directly relate to one another. This process is complex, and when considering the training of a sentiment analysis agent, may introduce additional errors of incorrectly related quintuples, as a result of misunderstood contexts or external references. At the very least a considerable amount of supervised learning must occur even before any sentiment analysis can happen. As well, once the pre-processing is complete there is the problem with perspective, or the actual classification of ooijkl as being positive, negative or neutral. Most corporate sentiment analysis agents are taught to recognize negative sentiment from the point of view of the company itself, so the term “Purple Cola is horrible, it’s Pink Cola for me!” would be seen as negative from the point of view of the makers of Purple Cola, and positive from the point of view of Pink Cola – and possibly a relatively neutral statement of fact – or perhaps a joke - from the point of view of the author. Similarly, we want our classifier to recognize that the author is linking the horrible with Purple Cola, and not Pink Cola. Pre-processing for this initial round of research is performed using the Stanford Natural Language Processing Tool Kit (SNLPTK), which identifies parts of speech in the corpus and organizes them in a consistent manner for all three classifier models. The decision to utilize a naïve Bayesian classifier, a support vector machine, and a decision tree model as the basis for the tree classifiers naïve Bayesian has been shown to work quite well on short sections of text in small data sets with a large number of independent factors, while decision tree and SVM have shown promising results with texts of varying lengths and moderately sized data sets (Ting, Ip, & Tsang, 2011). Finally, The University of Waikato’s WEKA project is utilized to develop and train each classifier using the pre-processed data, and then WEKA Experimenter compares and assists with the visualization of the results of each of the three models, in or to determine the most accurate results. has any causal effect on overall grades. REFERENCES [1] Liu, B. “Sentiment Analysis and Subjectivity”. Handbook of Natural Language Processing, 2nd Edition. Ed. N. Indurkhya and F. Damerau. CRC Press: 2010. [Online] http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.216.5533 &rep=rep1&type=pdf. [Retrieved Nov 10, 2012] [2] Liu, B. Web Data Mining, 2nd ed. Springer: New York, 2011, pp 459 - 467. [3] Suzuki, Y., Takamura, H, Okumura, M., and Gelbukh, A. “Application of Semi-supervised Learning to Evaluative Expression Classification.” Computational Linguistics and Intelligent Text Processing. Springer: 2006. [Online] http://dx.doi.org/10.1007/11671299_52 [Retrieved Nov 10, 2012] [4] Ting, S., Ip, W., and Tsang, A. “Is Bayes a Good Classifier for Document Classification?” International Journal of Software Engineering and its Applications. 5:3, Jul 2011. [Online] http://www.sersc.org/journals/IJSEIA/vol5_no3_2011/4.pdf [Retrieved 25Nov 2012]. [5] Pak, A., Paroubek, P.. “Twitter as a Corpus for Sentiment Analysis and Opinion Mining.” Proceedings of the Seventh International Conference on Language Resources and Evaluation, 2010. European Language Resources Association. [Online] http://deepthoughtinc.com/wp-content/uploads/2011/01/Twitter-asa-Corpus-for-Sentiment-Analysis-and-Opinion-Mining.pdf [Retrieved 25 Nov, 2012]. [6] Go, A., Bhayani, R., and Huang, L. “Twitter Sentiment Classification using Distant Supervision.” Processing. Stanford: 2009, pp 1-6. [Online] http://deepthoughtinc.com/wp-content/uploads/2011/01/Twitter-Sen timent-Classi%EF%AC%81cation-using-Distant-Supervision.pdf [Retrieved 25 Nov, 2012]. [7] Li, G.,Hoi, S., Chang, K., and Jain, R. “Micro-blogging Sentiment Detection by Collaborative Online Learning.” 2010 IEEE International Conference on Data Mining. IEEE: 2010, pp 893 – 898. [Online] http://0-ieeexplore.ieee.org.aupac.lib.athabascau.ca/stamp/stamp.jsp ?tp=&arnumber=5694057 [25 Nov, 2012]. III. CONCLUSION Initial test results of the student frustration and confusion classification agent have been very satisfactory. The system is able to provide an initial categorization of a variety of corpuses in the test data, and provide both the classification and visual results to the user. Much more extensive learning will be required before a comprehensive system can be put in place to identify and flag student problems to instructors in an online environment, but this project certainly promises to provide some interesting opportunities for future testing. For instance, there may be interesting patterns to investigate, such as whether or not a student’s sentiment in a discussion forum has an effect on grades, or whether specific forms of learning content produces better sentiment – and whether that Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 11 Using Data Mining for Discovering User Roles in online synchronous learning Peng Chen, Beijing Normal University elma0827@126.com Abstract—The purpose of this research is to show how data mining explores user roles in online asynchronous learning. At present, there are many researchers who focus on analyzing learner roles based on asynchronous learning. And most of them subjectively presume the diversity of learners’ roles in advance and then verify it based on the statistics of interaction data. We adopts the data mining technology to explore learner’ roles in online asynchronous learning. may limit the kinds of learner’s roles, ignore the interaction content between the learner and learning resource[7]. Data mining is a data-driven technology that are usually used to extract the potential and useful information and knowledge from a large, incomplete, noise, blurring, and random data[8] . Taken the interaction transcripts as data source, this research adopts the data mining technology to explore the learners’ roles in online synchronous learning. Index Terms—online synchronous discussion, data mining, user roles I. INTRODUCTION Computer-mediated asynchronous communication has been successfully utilized in learning and instruction using various learning management systems such as WebCT, Blackboard and Moodle[1]. Now, many institutions use online synchronous components to facilitate asynchronous learning, so that learners can undertake educational activities in the tutors’ setting time and interact with students and tutors more sufficiently and deeply. From a socio-cultural constructivist perspective of learning [2] dialogic interactions between students and tutors are crucial for supporting negotiation of meaning that leads to knowledge construction. Different from the traditional face-to-face class participation, users are encouraged to initiatively interaction with other group members for jointly studying in synchronous cyber systems or environments. With the practice of online learning in academic and social contexts, many researchers found that learners behave diversely with different level and quality of learning activities. So, the investigation of learners’ roles and the association between role and performance draw a lot of attention from researchers, such as many user roles researches in Computer Supported Collaborative Learning which are defined from different perspectives[3][4][5][6]. Meanwhile there are some learning analysis in synchronous learning, which almost focuses on learner’s experience and learning process. However, we found that most of the user roles research adopts the method of social network analysis (SNA), focusing on the relational data between individual measurements, which II. RESEARCH QUESTION (1) What are the students’ perceptions and behavioral intentions in a synchronous learning environment? Are synchronous learning environment beneficial to students? 2 What is the percentage/frequency of synchronous discussion in terms of Cognitive presence, social presence, teaching presence? 3 What is the user role in online synchronous discussions? () () III. RESEARCH DESIGN A. Research framework of learn role analysis The success of data mining requires people have profound comprehend of problem fields, and understands data and the data mining’s process, which help them find out reasonable explanation for results. Because the application demand and data base are different, the process steps of data mining may be different. Usually, the basic data mining process including identify target, data preparation, data mining, and explain the result. And the data preparation includes data selection, data preprocessing and data conversion[9]. Based on the classical process of Data Mining, we propose a user role analysis framework, which consists of 5 steps. Data Selection: In this step, data sample should be selected from discourse database of synchronous discussion. Data Preprocessing: the source discussion data collected in above step mainly are articulated by members in natural language, so it is necessary to extract speeches’ features manually or semi-automatically which can be used for computing and mining by machine. To get the features, a simple and practiced method is to classify every speech into different category based on certain theoretical framework. Data Conversion: after data preprocessing, it is important to establish an analysis model and convert the processed data Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 12 into the format which can get role analysis results by data mining algorithm. Data Mining: in this step, a specific mining algorism would be chose according to our mining objective, such as clustering algorithm, which mine members’ speech patterns from everyone’s speech number in each speech category. Result Analysis: the mined pattern in above step can not represent the roles directly. It is necessary to filter the meaningful and effective patterns, explaining and describing the mining result, and making a conclusion for the roles of team members and their characteristics. B. Data sources& collection The participants in this study included 50 students who choose the course General psychology in Beijing Normal University. The major data source in this study was the online synchronous discussion transcripts. Teacher gives discussion topics, and was required to participate in online synchronous discussions 1 h every week. The synchronous discussion was held at fixed time. Every week, one discussion topic was assigned by the teacher based on course readings and materials. The synchronous discussion activities entailed teachers to discuss the topic of the week’s readings. Another source of data was the questionnaire and interview about their perceptions and learning experience in the synchronous cyber classroom. has differences form asynchronous discussions? REFERENCES [1]Daniel Chia-En Teng et al., ‘Exploring Students’ Learning Experience in an International Online Research Seminar in the Synchronous Cyber Classroom’, Computers & Education, 58 (2012), 918–930 [2]Vygotsky, L. (1962). Thought and language. Cambridge, MA: MIT Press. [3]Dansereau, D.F, Learning and Study Strategies: Issues in Assessment, Instruction and Evaluation, New York: Academic Press. [4]McCalla, G. The central importance of student modelling to intelligent tutoring, Technical report, ARIES Laboratory, Department of Computational Science, University of Saskatchewan, Saskatoon, Saskatchewan S7N 0W0 Canada, 1988.90. [5]Blaye, A. Light, P.H, Joiner, R. and Sheldon, S. Joint planning and problem solving on a computer-based task, British Journal of Developmental Psychology, 1991, 471--483. [6]Blandford, A.E. Teaching through collaborative problem solving, Journal of Artificial Intelligence in Education, 1994, 5(1):51--84. [7]Jian Liao, Yanyan Li ,Peng Chen,Ronghuai Huang. Using data mining as a strategy for discovering user roles in CSCL. IEEE International Conference on Advanced Learning Technologies, 2008. 960 - 964 [8] Jiawei, H., Kamber M. Data Mining; Concepts and Techniques[C], Mongan Kaufmann publishers,2000. 225-270. [9]Lan H. Witten, Eibe Frank, Data Mining: Practical Machine Learning Tools and Techniques, Academic Press, ISBN 0120884070, 2005 C. Data processing & analyzing As the discussion transcripts are natural language, we firstly extract abstract elements from these speeches which can represent speech characteristic. Based on some act theory, we should classify group members’ discussion texts into some categories effectively. Then, we need to code with tools. Before mining, we also should build a specific analysis model. Data mining comprises many kinds of methods, such as classification, clustering, correlation analysis and so on. D. Key Problems () () () () 1 How to design discussion topic that suitable for online synchronous learning? 2 How to collect the online synchronous discussion data effectively and how to guarantee the validity of the data? 3 What category of interaction and user roles analysis is best for us? 4 Which code tool for this study is best according data characters? And how to ensure the accuracy of the code? IV. RESEARCH DESIGN (1) Students’ perceptions and behavioral intentions in a synchronous learning environment. (2) The interactive situation of learners and teacher in the online synchronous discussion. (3) User roles in the online synchronous discussion, if it Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 13 Annotation Behavior Clustering Miao-Han Chang, Athabasca University chang.miaohan@gmail.com Abstract - When students read a book, they usually make annotations on the text which they think important. Students have their preference in making annotations. Some prefer to underline important words; some prefer to use different colors on the important words; and some others may circle the important words in different colors. This research focuses on clustering students according to the similarity of their annotations. The clustering results then can be used to provide students feedback such like words they didn't annotate but probably is also important to them and sidebar notes made by other students who are in the same cluster. Index Terms—Annotation, Chromosome, Patterns, Clustering I. INTRODUCTION S tudents have different annotation preference while reading. They may use different annotation type (e.g., underling, highlighting, or double-line). For example, when Jack, John, and Berry are reading a text – "Every year in the U.S. factories release over 3 million tons of toxic chemicals into the land, air and water" – in the "Pollution" article [5], their annotations might be different. Jack only underlines the word "air"; John double-line the whole sentence; and, Berry highlights "air", "water", and "land". Students might miss to annotate some important keywords when reading an article. When they review the annotated article for preparing exams or homework, they may also skip the un-annotated words. To avoid of missing any important thing, students always borrow friends' books and take their friends' annotations as reference. If an annotation system can provide students annotation recommendation, they might catch up the missing annotations easier. This research aims to design an annotation tool which is capable of recommending students the annotations made from other students who have similar annotation behavior. II. RELATED WORKS When users read an article on their computers and mobile devices, they may always want to annotate important information directly on the devices. For helping users read and annotate articles on their computers, Su and colleagues [2][3] have developed a web-based annotation platform – Personal Annotation Management System (PAMS) – where users can highlight, underline, attach notes and voice recording to the text in an article. The annotation systems can record user's annotation and analyze user’s annotation data to identify users into different groups. Ying and colleagues' research [1][4] has used bit-string chromosome to represent and to store users' annotations. Every word's annotation in the text is represented by a bit-0 (no highlight) and 1 (has been highlighted). In addition, the research has used four different approaches, which are Standard, Quantitative Cosine, and Diffusion, for clustering those chromosome-like data. Comparing the efficiency of the four approaches, Diffusion approach is the fastest one with only 20.53 milliseconds (Standard approach: 29.95 milliseconds, Quantitative approach: 27.43 milliseconds, Cosine approach: 178.7 milliseconds). Though Cosine approach's run time is the slowest, it has highest accuracy rate with 0.7488 precision (Standard: 0.7146, Quantitative: 0.7027, Diffusion: 0.7047). Although the four approaches has high efficiency and accuracy in clustering students' annotations, the approaches can only deal with single annotation type. This research aims to propose a new chromosome-like coding method for representing and clustering students' various annotations on a text, e.g., highlight words in different colors, underline words in different colors, and other different kind annotation types. The goals of this research are: 1) Having a web-based annotation tool for researchers, teachers, and students. 2) Storing and representing a student's annotations on a text. 3) Spending less time than the four approaches in clustering student annotations. 4) Having more accurate clustering results. 5) Finding the characteristics of clustering results. III. PROBLEM STATEMENT An article may have thousands of words or longer. When a teacher collects students' annotations of an article, he/she has difficulty identifying which two students have similar annotation behavior. To help teachers cluster students according to their annotations and to recommend students annotations taking from others, this research investigates four problems: 1) What kind of data structure can be used to represent students' annotations? 2) How to reduce the complexity of the data structure which represents a student's annotations on the article with thousands of words? 3) How to weight a student's annotations so any two students’ annotations can be compared. 4) How to measure the similarity between two students' annotations? Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 14 IV. SYSTEM PROGRESS A. Major Functions Currently, I’ve implemented four sub-functions, which are: 1.1) Annotate articles assigned by teachers. 1.3) View the reading activity list. 2.2) Create reading activities. 2.4) Review and edit cluster results. B. Sytem Demonstration - Teachers' View When teachers start using the system, they can see a function list in part A of Fig. 1. After teachers click the "Create reading activity" link, the system ask teachers to provide the required information of the reading activity (part B). Teachers have to choose the course which this reading activity will be used, decide the start and end date of the reading activity, and put the reading material in the system. After clicking the "CREATE" button, students in the designated course have a new reading activity. C. Sytem Demonstration - Students' View When students log in the system, they can see a list of all the reading activities they need do. After selecting a reading activity, students can read the article in the reading panel as Fig. 3 shows. Students can take different annotations on the article, such as highlight, underline, bold face, italics, and increase the font size. Studnets can not only use single annotation type on one word (part B) but also apply mixed annotations on the same word (part C). Fig. 5. A reading panel which students can do their reading activitiey. V. POTENTIAL CONCLUSION Fig. 1. Teachers' interface of creating a new reading activity. After students completed the reading activity, teachers can review students’ cluster results created by four approaches proposed by [1][4]. Teachers can choose which clustering method they would like to use by clicking one of the clustering approach buttons in part A of Fig. 2, and the system will display the cluster result in part B. Fig. 2 shows the system has clustered students into two groups. The proposed annotation recommendation system has several potential benefits for students: (1) a platform for annotating learning materials online; (2) suggestions of notes and annotations that other students have taken; (3) having better academic performance. Also, the research project can help teachers to identify student’s learning problems via their annotations and get clear idea of which parts of the text (or the learning unit) that most of students don't understand or have misconceptions. REFERENCES [1] [2] [3] [4] [5] M. Chang, R. Kuo, K. Ying, A. F. Chiarella, J. Heh, and Kinshuk, “Clustering Annotations of a Digital Text with Bio-inspired Approaches,” Hybrid Technology, (JHT2013), vol. 1, no. 1, pp. 1-10, 2013. A. Y. S. Su, S. J. H. Yang, W. Hwang, and J, Zhang, “A Web 2.0-based collaborative annotation system for enhancing knowledge sharing in collaborative learning environments,” Computers & Education, vol. 55, no. 2, pp. 752-766, Sep, 2010. S. J. H. Yang , J. Zhang , A. Y. S Su, and J. J.P. Tsai, “A collaborative multimedia annotation tool for enhancing knowledge sharing in CSCL,” Interactive Learning Environments, vol. 19, no. 1, pp. 45-62, Jan, 2011. K. Ying, M. Chang, A. F. Chiarella, Kinshuk, and J. Heh, “Clustering Students based on Their Annotations of a Digital Text,” In the Proceedings of 4th IEEE International Conference on Technology for Education, (T4E 2012), Andhra Pradesh, India, July 18-20, 2012, pp. 20-25. “Pollution” (n.d.), Pollusion. Retrieved March 2, 2014 from http://www.greenstudentu.com/encyclopedia/pollution Fig. 2. Teachers can vew and revise the clustering results generated by the system from students' annotation records.. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 15 Determining Relevant Factors in the Identification of At-Risk Students Darin Hobbs, Athabasca University darinh@shaw.ca Abstract –Many colleges and universities are utilizing data stored within a Learning Management System (LMS) to develop predictive models and tools to identify students at-risk. Students will display similar behaviors and patterns in effort, participation and engagement before dropping or failing a course, or failing a quiz or other performance assessment. The predictive models and tools will recognize these patterns of behavior and can provide positive interventions. These tools aggregate the raw data to construct factors for student risk identification. Factor analysis and association rules determine which factors are most relevant and accurate in identifying students at-risk of not succeeding at school. Index Terms — classification algorithms, clustering algorithms, factor analysis, educational data mining (EDM), learning analytics, predictive model I. INTRODUCTION I n a traditional classroom setting, instructors and students are physically present, and interactions between student and instructor, student-to-learning material, and student-to-student occur frequently. Instructors can observe learner activities, behaviors and interactions within the classroom and make decisions based on their observations. In an online environment, instructors and students are physically separated across geographic distances and time zones. For instructors, the ability to physically observe a student’s interactions is no longer available. In an online classroom environment that utilizes a Learning Management System (LMS), all student interactions and behaviors are captured in databases and server logs. Course content, communications and interactions are delivered through asynchronous channels. Whereas the instructor in a physical classroom can provide assistance to students based on their observations, the instructor in a virtual classroom must take a much different approach, relying on the data stored within an LMS to act as their eyes and ears in a virtual classroom. The objective of many virtual classrooms and institutions is to design a tool that can observe the actions and behaviors of students electronically and identify those who are at-risk based on the analysis of data captured within the LMS. The tool would use data mining techniques on the data to create factors that will identify learners at-risk. By using logistic regression analysis, the relevancy of these factors can be determined through measures of accurately predicting which students are likely to need additional support and assistance. The research into the identification of at-risk learners is significant as many factors have been used to disseminate the raw data found in the multiple systems used at educational institutions. These factors must be analyzed and tested to reveal their importance in contributing to the process of identifying at-risk learners [7, 5, 6]. The identification of at-risk learners is important for both the student [9] and the instructor [11]. The instructor will utilize these factors to identify students at-risk and intervene with corrective action when and where necessary. The student will become more aware of their academic performance. With the identification of at-risk students, the learner and the instructor can discuss work, activities, and behaviors to improve student performance. The research that is currently underway will attempt to answer the following questions: 1. What factors are consistently used in current predictive and forecasting systems? 2. Based on the data, which factors are consistently accurate at identifying at-risk learners and which are not? 3. Based on the data, which factors are more relevant to others and why? 4. Based on the data, what combination of factors, if any, will constitute a standardized framework to identify at-risk learners? II. LITERATURE REVIEW A majority of existing literature discusses the research of factors that are used to predict student success and/or identify at-risk learners. Analysis and testing of relevant factors significantly correlated to final course grades or student retention levels are discussed and debated. The methods used to determine the relevancy of the factors also vary from study to study. Based on previous research conducted, student data has been classified in the following factor groups: • Demographics – (gender, age, employment status) [2, 7, 4, 14, 16, 19] • Academic history – (high school GPAs, previous course final mark) [4, 14, 16, 19] • Online effort and engagement – (session logins, login time, web pages and other URLs accessed) [2, 7, 12, 5, 16] • Social interactions and active participation – (discussions forum posts viewed, created and replied) [2, 7, 12] • Course content understanding – (course assignment, quizzes, and exam marks during the course) [2, 5, 16] Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 16 • Learning environment – (course programme, course learning style) [16, 19] • Locus of control – (learner attitudes, motivation, and self-efficacy) [7, 4, 14, 16] Many schools have developed data mining tools for their systems that implement the factors and variables into success prediction or risk identification models. These tools include AAT [9], Course Signals [2], DeLeS [8], GISMO [13], LOCO-Analyst [1], and Moodog [21] to name a few. By identifying student data under the listed factors, in addition to implementing an ensemble tool that utilizes those factors in identifying students who are in danger of dropping out or failing a course, the relevancy of factors that are successful in identifying at-risk learners will be researched. high risk once the course commences, and provide timely interventions to students when necessary. As the usage of LMS’ continues to increase within virtual and physical schools, so too will the amount of student behavioral data captured in these systems. New patterns and factors will be discovered that will be more accurate and efficient at identifying students’ at-risk than those that currently exist. REFERENCES [1] [2] [3] III. RESEARCH METHODOLOGY The research methodology consists of extracting student background and behavioral data from Athabasca University’s (AU) SIS and LMS, Moodle. Student background data will be analyzed to form groups based on final learning outcomes. Student behavioral data will be analyzed sequentially to discover patterns that indicate a student is in danger of not succeeding in a course. Variables within the data will be aggregated to determine their relevancy in identifying students at-risk. These factors in identifying students at-risk will be analyzed to determine their relevancy. An existing tool will be extended to implement data mining algorithms utilizing the discovered relevant factors. IV. LIMITATIONS One of the biggest limitations to developing a predictive tool is that student learning does not only occur online within the context of the LMS. Student learning and the effort performed on tasks and assignments offline and outside of the LMS are not captured, and therefore cannot be measured. Students who are entering their first year of study will also pose a challenge in identification due to the lack of historical data that will exist. Finally, the learning environment may contribute to the success or failure of a student. It is possible that a student could excel in one type of course, but struggle in another. Students may also prefer to read the material as opposed to viewing a video lecture. V. POTENTIAL CONCLUSION There are many influencers on a student’s life that affect their performance and commitment to successfully completing a course. The reasons why a student is unable to achieve academic success will be unknown to the faculty at a college or university. However, students will display behaviors that will indicate if they are considering dropping a course or in danger of failing. Institutions are creating tools to assist instructors and course administrators in identify these students who are potentially at-risk. The value of these tools will allow instructors and course administrators to identify students at-risk prior to a course commencing, monitor those students who become classified as [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] Ali, L., Hatala, M., Gašević, D., and Jovanović, J., “A qualitative evaluation of evolution of a learning analytics tool,” Computers & Education, 58(1), 470-489. Arnold, K. E. and. Pistilli, M. D., “Course Signals at Purdue: Using learning analytics to increase student success.” In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge. ACM, 2012. Barber, R. and Sharkey, M., “Course correction: using analytics to predict course success,” In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, ACM 2012. Burton, L. J., & Dowling, D. (2010, December). “In search of factors that influence academic success: A comparison between on-campus and distance students.” In Proceedings of the 21st Annual Conference for the Australasian Association for Engineering Education (AaeE 2010) (pp. 582-589). Australasian Association for Engineering Education. Chen, C. M., & Chen, M. C., “Mobile formative assessment tool based on data mining techniques for supporting web-based learning,” Computers & Education, 52(1), 256-273. Essa, A., and Ayad, H., “Improving student success using predictive models and data visualisations,” Research in Learning Technology, 20. Fancsali, S. E., “Variable construction for predictive and causal modeling of online education data,” In Proceedings of the 1st International Conference on Learning Analytics and Knowledge, ACM.,” Graf,S., Kinshuk, and Liu, T.C. “Supporting Teachers in Identifying Students' Learning Styles in Learning Management Systems: An Automatic Student Modelling Approach”, Educational Technology & Society, vol. 12(4), pp. 3-14. Graf, S., Ives, C., Rahman, N., and Ferri, A., “AAT: a tool for accessing and analysing students' behaviour data in learning systems,” In Proceedings of the 1st International Conference on Learning Analytics and Knowledge, ACM KNIME - http://www.knime.org/ [Accessed on 03/07/2014] Lockyer, L., and Dawson, S., “Learning designs and learning analytics,” In Proceedings of the 1st International Conference on Learning Analytics and Knowledge (pp. 153-156). ACM. Macfadyen, L. P., and Dawson, S., “Mining LMS data to develop an “early warning system” for educators: A proof of concept,” Computers & Education, 54(2), 588-599. Mazza, R., & Milani, C. (2005, July). “Exploring usage analysis in learning systems: Gaining insights from visualisations.” In Proceedings of the 12th International Conference on Artificial Intelligence in Education (AIED) (pp. 65-76). McKenzie, K. and Schweitzer , R.,“Who Succeeds at University? Factors predicting academic performance in first year Australian university students,” Higher Education Research & Development, Jul. 2010. Moodle - https://moodle.org [Accessed on 03/07/2014] Morris, L., Wu, S-S., and Finnegan , F., “Predicting Retention in Online General Education Courses,’ American Journal of Distance Education. Jun. 2010. PSPP - https://www.gnu.org/software/pspp/ [Accessed on 03/07/2014] R - http://www.r-project.org/ [Accessed on 03/07/2014] Simpson, O., “Predicting student success in open and distance learning,” Open Learning, 21(2), 125-138. Weka - http://www.cs.waikato.ac.nz/ml/weka/ [Accessed on 03/07/2014] Zhang, H., Almeroth, K., Knight, A., Bulger, M., and Mayer, R., “Moodog: Tracking students' online learning activities,” In World Conference on Educational Multimedia, Hypermedia and Telecommunications, Vol. 2007, No. 1, pp. 4415-4422 Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 17 Platform Independent Game Based Educational Reward System Cheng-Li Chen, Athabasca University u0024810@gmail.com Abstract—Reward is a common way to increase students' learning motivation in traditional classroom learning. The traditional rewards, such as stamps and stickers, are usually symbolic and valueless to students and may not get students motivated. This project proposes a game based educational reward system where students can receive in-game rewards while studying online within the learning management system – Moodle. When students complete learning activities (e.g., exercise or quiz), the reward system will give items which they can use in the game according to their performance. When students have better performance in terms of doing learning activities, they will receive more powerful in-game items from the system. With these powerful in-game items' help, students can have more fun in the game-play or even show-off the items that they have to other players. For this reason, students may put more efforts on doing their homework and may be actively participated in the discussions in the class for getting better rewards. The project will design an experiment to evaluate the effectiveness of the reward system by figuring out the relationships between students' learning performance before and after they receive rewards. Index Terms—Educational reward, academic achievement, motivation, learning activities, game I. INTRODUCTION T raditionally, teachers give students rewards according to performance that students have shown in different learning activities. John, a science teacher, wants to encourage students to learn. He may give pencils as rewards to the top three students whose answers of the mid-term exam receive highest marks. He expects to see that students will have better performance for the next learning activities (e.g., final exam) if they receive rewards from this one. In the context of distance education and online learning, for instance, all students at Athabasca University are learning online in different time zones across Canada and worldwide, giving students real items as rewards is impractical and unrealistic. In order to make teachers still capable of rewarding students just like how they did in traditional learning settings, an educational reward system works with learning management systems needs to be designed and developed. This project plans to design a reward system within online learning environment. Teachers can use similar way to give students rewards as usual. With the reward system's help, students' learning motivation and academic achievement may be improved. Besides, teachers can use the rewards to engage students to participate in online learning activities. II. RELATED WORKS Winefield and Barnett argued that rewards positively affect students' learning performance [5]. However, Marinak pointed out that if rewards are not attractive to students, students' learning motivation will not be affected [3]. Another researcher, McNinch, considered that cash can be used as reward to encourage students learning [4]. Although this method is attractive for students, it is still criticized by others as giving cash to students that looks like a kind of suborning [2]. According to the above studies, we can find out that only when students think the rewards they received are valuable or meaningful, the reward mechanism can be effective in terms of engaging students in learning. To make rewards more attractive for students, Chen used cards in the Trading Card Game (TCG) he developed as educational rewards [1]. Teachers can give students higher-level cards if students did exercises well. Once students receive higher-level cards, they have higher chance to win in the game-play. On the other hand, when students are not doing exercise well, they probably will not receive cards as rewards or only receive lower-level cards for what they have done. The research also conducted an experiment to find out whether or not the use of the trading cards as educational rewards affects students' motivations and academic achievements. There were 172 fifth-grade students, 80 boys and 92 girls, participated in the experiment and were separated into two groups. The 68 control group students only used a vocabulary system for practicing their English vocabularies, and the 104 experiment group students used the vocabulary system and received cards as rewards automatically every time after they practiced vocabularies with the system. The research result showed that students who played the TCG more, they practice in the vocabulary system more often. The result suggested that students were study harder in order to receive higher-level cards. However, the research only has one learning activity which is vocabulary learning. Moreover, Chen's study only investigated elementary school students' attitudes toward the TCG. It is very important to know whether or not the same effect can be found at secondary and post-secondary level. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 18 This project plans to design a platform independent game-based educational reward system. The system allows students to play a trading card game on any devices include tablets and smartphones. The system also has educational reward management and distribution module which can be easily integrated into an existing learning management system such as Moodle to support teachers rewarding their students based on students' performances on different learning activities. In addition, this study will conduct a pilot and recruit high school and/or university level students to verify the following two hypotheses: 1. Students will actively participate in online learning activities when the game-based educational reward system is applied. 2. Students' performance of the follow-up learning activities will be improved after they received rewards. III. RESEARCH OBJECTIVES This research has following three objectives: Objective #1- According to the pre-defined criteria that the teacher setup to automatically deliver cards as rewards to students. Teachers usually have different criteria of rewarding students for different learning activities. The educational reward management and distribution module needs to allow teachers to set reward criteria for individual learning activity. Objective #2- To have a secure communication channel between the learning management system and the game while student's privacy and anonymity is maintained. Learning management system like Moodle and the platform independent game developed by this project are two systems. Student's private data like student ID should never be known by the game and student's identity should remain unknown from other players in the game. As the rewards that students received need to be sent to the game from the learning management system, it is important to have a secure data transmission mechanism so students can receive the rewards they deserved to have while keeping students to receive unauthorized rewards. Objective#3- Students' performance in doing learning activities will improve. To prove the proposed game and the educational reward management and distribution module is useful, it is important to design a pilot to verify this project's two hypotheses. V. POTENTIAL CONCLUSION The proposed educational reward system has following potential contributions: a. for students (1) to get students motivated in learning; (2) to put more efforts in doing learning activities; b. for teachers (1) to encourage students participating in online learning activities; and, c. for academic administrators (1) to easily integrate the game-based educational reward system into the existing learning management system while the privacy and the anonymity of students is maintained. REFERENCES [1] IV. RESEARCH PLANS AND METHODOLOGIES This project designs an experiment with five stages: Stage 1: At this stage, a course is designed for particular secondary or post-secondary students. The course has learning activities include assignments and discussions for twelve weeks. Three assignments and six course-related discussion topics are designed. Every three weeks an assignment is proposed and students have to submit their works within one week. The students are also asked to discuss a course-related topic with classmates biweekly. Stage 2: First of all, two classes will be chosen from a high school (or a university); one class is the control group, and the other is the experiment group. Before the course starts, all students will be asked to complete a questionnaire regarding their demographic information and computer game attitude. Stage 3: In the first four weeks of the course, both of control and experiment group students are self-paced learning on Moodle. They are going to do assignment and to discuss the proposed topics with their classmates online asynchronously without receiving rewards for their efforts. Stage 4: At this stage, the teacher will introduce the trading card game and the rewarding criteria to the experiment group students. Students can play the game with computer or each other at any time they want. The experiment group students can then receive the cards as rewards when their works of learning activities meet the criteria the teacher set at Stage 1. Stage 5: Experiment group students are asked to complete technology acceptance and usability questionnaires at this stage, so their perceptions toward the game can be collected and the relationships among their computer game attitudes, perceptions toward the games, rewarding and game-play histories can be analyzed and discovered after the pilot. The teacher is also interviewed to get his/her perceptions and comments on the game-based educational reward mechanism. [2] [3] [4] [5] P. Chen, “Designing a Trading Card Game as Educational Reward System to Improve Students’ English Vocabulary Learning,” M.S. thesis, Dept. Information Eng., Chung Yuan Christian Univ., Taoyuan County, Taiwan, 2010. A. Kohn, Punished by rewards: The trouble with gold stars, incentive plans, A’s, Praise, and other bridges. Boston: Houghton Mufflin, 1999. B.A. Marinak, “Insights about Third-Grade Children’s Motivation to Read,” College Reading Association Yearbook, Issue 28, 54–65, 2007. G.W. McNinch, “Earning by Learning: Changing Attitudes and Habits in Reading,” Reading Horizons, 37(2), 186-194, 1996. A.H. Winefield, J.A., Barnett & M. Tiggemann, “Learned helplessness and IQ differences,” Personality and Individual Differences, 5(5), 493-500, 1984. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 19 Using Intelligent Mechanisms to Enhance Learning Management Systems Charles Jason Bernard, Athabasca University littlejonnyninja@hotmail.com Index Terms— Computational Intelligence, Education, Evolutionary Computation, Learning Systems, Neural Networks, Learning Styles, Working Memory Capacity. T echnology enhanced learning (TEL) is a growing industry fueled both by an increase in online learning [1] and a commitment from education providers in the use of learning management systems (LMS) [18]. Surveys of students has shown that overall they have a positive view of LMSs and find that they improve learning and save them time [15][16][17][18]. Adaptive learning systems (ALS) are another form of TEL that personalizes each student’s learning environment by providing them with optimal content and supports teachers by providing them insight into their students [45]. In order to provide these benefits ALSs must know the characteristics of the students. Two such characteristics, and the focus of this research, are learning style (LS) and working memory capacity (WMC). A LS is the approach a student takes to learning [4][14]. There are many LS models although this research will use the Felder / Silverman model [8] which consists of four dimensions: (1) Active / Reflective (A/R), (2) Sensing / Intuitive (S/I), (3) Visual / Verbal (V/V), (4) Sequential / Global (S/G). WMC is the portion of memory used to store information for short periods of time during the processing of other tasks [2]. Most people are able to retain 5 to 9 items in working memory, and it is believed to be a strictly biological limit [13][20]. Personalizing the educational environment, largely by providing optimal material in an optimal format, has been shown to improve immediate learning by increasing the amount learnt, reducing the time required to learn and improving student satisfaction [10][11][44][45]. It has also been shown that making appropriate interventions to account for a student’s WMC “can lead to effective management and support to bolster learning” [19]. The difficulty in finding the right function by human expert knowledge is that it is difficult to extract expert knowledge and translate into a logical or algorithmic form especially when the subject matter is complex, such as in this case where we are dealing with human behavior and the mind. The artificial intelligence / computational (AI / CI) approach is ideal for working on such problems because they are less constrained than a human expert since they seek or learn the best solution from the pool of all possible solutions with less bias or human limitations (such as speed). The primary drawback to the AI / CI approach is that it does not necessarily reveal why an answer is the best solution within the context of the field (e.g. educational psychology). Fortunately, for the purposes of personalizing the educational environment provided by an ALS, only the best solution is needed to accomplish the goals of increasing student learning, reducing the time to learn and increasing student satisfaction with the learning process. There exist methods for accurately identifying both LS and WMC. LS may be identified through the use of a questionnaire, such as the Index of Learning Styles Questionnaire [9]. WMC may be identified by having the participant perform two simultaneous mental tasks one of which is memorizing a word while the other task is one of (1) reading a phrase [6], (2) counting [3] or (3) solving a mathematical problem [7]. The problems with using these methods with an ALS are: (1) they are subject to the mood and perceptions of the student and (2) must be performed directly with the student and so may be intrusive. An algorithmic approach addresses these problems by identifying the characteristics based on the student’s behaviours. Therefore, it is able to run continuously and do so without being intrusive. In addition, it is not subject to the student’s perceptions of the importance of identification or to the mood of the student at a single point in time (i.e. when the test is given). This research will design, implement and evaluate intelligent mechanisms from the fields of AI / CI which will allow for a more accurate identification of LS and WMC than existing algorithmic approaches. It is hoped that the improvements provided by the AI / CI algorithms will allow for a better personalization of the educational environment in an ALS and so lead to an improvement in the learning for students. This research will done in three phases for both LS and WMC. The first phase will be to identify and assess AI / CI algorithms for their potential to solve the problems of identifying LS and WMC. Phase 2 will consist of designing and developing 3-4 of the algorithms from Phase 1 into prototypes. Different algorithms may be selected for identification of LS vs identification of WMC. In Phase 3, the algorithms will be evaluated using real student behavior logs from a LMS. All Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 20 three phases will then be repeated using hybrid AI / CI algorithms. The assessment of the algorithms in Phase 1 will be from the perspective of two approaches to solving both problems. The first approach is to find optimal weights to apply to a function which will convert behaviours into the corresponding characteristic (LS or WMC). This is a modification of the rule-based approaches developed by Graf et al [12] for LS identification and Chang et al [5] for WMC identification. The second approach will be to use an artificial neural network (ANN) to learn to identify these characteristics from behavior inputs. Although ANNs have been used before, the approach used here differs in two key regards. First, it is using more and different behaviours than previous attempts and second, feedback will be used in a novel approach to attempt to model the possible interactions between behaviours. It is expected that the resulting prototypes will improve identification of LS accuracy above the current best approach of ~73-78% [12]. No algorithmic approach for WMC exists for comparison purposes at this time, but it is expected that WMC identification will also be in excess of 80% accuracy. The prototypes will also be evaluated for the number of behaviours required to perform successful identification to within certain thresholds (70%, 80% and 90%) since the more behaviours required means that optimal personalization takes longer to occur. These approaches will be evaluated on what percentage of students are identified within the 70%, 80% and 90% thresholds. The reason for this is that that proper personalization improves learning it might be more desirable that more students are identified with reasonable accuracy than some with extremely high accuracy and others with low accuracy. For example, consider the scenario where 80% of the students are identified with 95% accuracy and the remaining 20% at 10% accuracy. In this scenario those 20% may suffer due to improper personalization vs a scenario where all students are identified at 80% accuracy. Lastly, the algorithms will be evaluated for computational complexity, largely to ensure that it does not become intractable with a large number of students or a large number of behaviours. [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] It is expected that both students and teachers will benefit from this research. Teachers will gain insight into their students and so can intervene to help them. Students will benefit from having a personalized learning environment. [20] A. Baddeley. “Working memory,”. Science, vol. 255, no. 5044, pp. 556-559. 1992. R. Case et al. “Operational efficiency and the growth of short-term memory span,” J. Experimental Child Psychology, vol. 33, no. 3, pp. 386-404. 1982. S. Cassidy. “Learning styles: An overview of theories, models, and measures,” Educational Psychology, vol. 24, no. 4, pp. 419-444. 2004. T. Chang et al. “An Approach for Detecting Students’ Working Memory Capacity from their Behaviour in Learning Systems,” in IEEE 13th Int. Conf. Advanced Learning Technologies, 2013, pp. 82-86. M. Daneman and P.A. Carpenter. “Individual differences in working memory and reading,” J. Verbal Learning Verbal Behavior, vol. 19, no. 4, pp. 450-466. 1980. R.W. Engle. (1989) Working Memory Capacity: An Individual Differences Approach. South Carolina University Department of Psychology. [Online] Available: http://www.dtic.mil/dtic/tr/fulltext/u2/a207127.pdf R.M. Felder and L.K. Silverman. “Learning and teaching styles in engineering education,” Engineering Education, vol. 78, no 7, pp. 674-681. 1988. R.M. Felder et al. (1999) Index of Learning Styles. North Carolina State University. [Online] Available: http://www.engr.ncsu.edu/learningstyles/ilsweb.html N. Ford and S.Y. Chen. “Matching/mismatching revisited: an empirical study of learning and teaching styles,” British J. Educational Technology, vol. 32, no. 1, pp. 5-22. 2002. S. Graf et al. “Investigations about the effects and effectiveness of adaptivity for students with different learning styles,” in 9th Int. Conf. Advanced Learning Technologies, 2009, pp. 415-419. S. Graf et al. “Supporting Teachers in Identifying Students' Learning Styles in Learning Management Systems: An Automatic Student Modelling Approach,” Educational Technology & Society, vol. 12, no. 4, pp. 3-14. 2009. M.J. Kane and R.W. Engle. “The role of prefrontal cortex in working-memory capacity, executive attention, and general fluid intelligence: An individual-differences perspective,” Psychonomic bulletin & review, vol. 9, no. 4, pp. 637-671. 2002. D.A. Kolb. Experiential learning: Experience as the source of learning and development. New Jersey: Prentice Hall.1984. S. Lonn and S.D. Teasley. “Saving time or innovating practice: Investigating perceptions and uses of Learning Management Systems,” Computers & Education, vol. 53, no. 3, pp. 686-694. 2009. R, Loo. “Evaluating change and stability in learning style scores: a methodological concern,” Educational Psychology, vol. 17, no. 1-2, pp. 95-100. 1997. S.D. Smith and J.B. Caruso. (2010) The ECAR study of undergraduate students and information technology, 2010. Educause. [Online]. Available: http://www.educause.edu/library/resources/ecar-study-undergraduate-stu dents-and-information-technology-2010 S.D. Smith et al. (2009). The ECAR study of undergraduate students and information technology, 2009. Educause. [Online]. Available: http://www.educause.edu/library/resources/ecar-study-undergraduate-stu dents-and-information-technology-2009 J.L. Woehrle and J.P. Magliano. “Time flies faster if a person has a high working-memory capacity,” Acta psychologica, vol. 139, no. 2, pp. 314-319. 2012. E.K. Vogel and M.G. Machizawa. “Neural activity predicts individual differences in visual working memory capacity,” Nature, vol. 428, no. 6984, pp. 748-751. 2004. ACKNOWLEDGEMENT The author would like to thank the Alberta Innovates Technology Futures (AITF) for their research scholarship in support of this research. REFERENCES [1] I.E. Allen and J. Seaman. (2011). Going the Distance: Online Education in the United States, 2011. Sloan Consortium. [Online] Available: http://www.eric.ed.gov/PDFS/ED529948.pdf Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 21 Adaptive Learning based on a Collaborative Student Model Jeffrey M. Kurcz, Athabasca University jkurcz@gmail.com Abstract— Adaptive Learning is taking great strides forward with respect to distance learning and bridging the gap between traditional brick-and-mortar styles of education. While there has been done a lot of research on adaptive learning for supporting individual students, the next important step in this area is tailoring adaptive learning to groups or teams, as group learning is an important aspect of a student’s education. Collaborative learning is important to a student’s education because it teaches them to develop communication and interpersonal skills that will be used outside of the classroom. Often when students are working in groups they are faced with additional challenges of different learning styles, varying knowledge levels and equal participation. My research hopes to eliminate this challenges of collaborative learning by providing adaptive recommendations to teams/groups of students, allowing students to work effectively and efficiently in groups. Keywords— Adaptive Collaborative Learning, Collaborative Student Model, Group Work I. INTRODUCTION M uch research has been done around individual learning to personalize a course for students based on their characteristics such as learning styles and level of knowledge. The next step in this area is to look into how adaptive learning systems can extend beyond the individual aspects and incorporate groups and teams of students learning together. Sometimes problems arise when students are placed into groups, and by doing research into collaborative student models and adaptive collaborative learning my goal is to help eliminate these types of problems. Research will focus on how effective teams work together and how to make recommendations to existing teams so that they can improve and become an efficient group maximizing the quality of learning and output. Adaptive collaborative learning and collaborative student models present new challenges in the area of adaptive learning and my research hopes to build on existing research findings to create a working design and implementation. By conducting our research we hope to find information based on other’s work in which we can improve upon and develop an effective adaptive collaborative learning approach that can be implemented from a concept to a working system. An algorithm will be designed and implemented to fill a collaborative student model that will store a diverse set of variables about students’ behaviour as part of a group, and based on this information, make recommendations and suggestions to the students on how they can improve upon their participation. II. LITERATURE REVIEW Current research demonstrates some facts that group learning can be an effective tool for students if used properly. However, students will only perform well when they are highly involved in many of the groups’ activities. This includes all participation and interaction such as sharing thoughts and ideas and clearly articulating them to other members of the group. Just because students are in a group does not mean they will do better than if they were studying individually. When all students are involved and captivated the group can excel together and students will take away the greatest experience [1]. However, many times when students are placed in groups there can be students who do not necessarily participate as equally as some others and it would be important to determine how to provide recommendations to these students to integrate them in the group. Durán and Amandi also discuss that not all students have the same level of knowledge as well, and that sometimes the collaboration within the group and accordingly the group output can be affected by such different skill levels. [1] Also students who are more passive in a group will tend to learn less than those who are more active because the effort that they place within the group is less [1]. In distance education collaborative learning encourages active learning and all parties to participate through social interactions, which leads to improved learning [2]. Collaborative learning can be achieved by utilizing tools such as wikis, discussion forums and chat that are built into the Learning Management System. Activities in such tools can be monitored to help generate recommendations and feedback based on the students’ efforts [3]. Collaborative student models or group models are important to the collaborative process because when individuals are working together they will have different behaviour in the course based on their own characteristics such as learning style [4]. Research in this area has sparked interest Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 22 more recently because online learning systems, which offer the ability to cater to heterogeneous students, do not offer the same benefits as a live classroom such as personalized support, custom presentations and feedback [5], all of which are also important to a students learning experience. Essawi and Tilchin discuss that collaborative learning is best suited for students learning when combined with practical learning activities such as learning by doing and build upon other skills such as knowledge sharing and managing groups [6]. III. RESEARCH METHODOLOGY This research will start with conducting a literature review to get more familiar with previous works in which adaptive learning has been combined with collaborative student models. For example, research will be required on how to gather a user’s behaviour and interactions within a group, then store this information in a collaborative student model. Once this information has been stored it will need to be used to provide accurate recommendations to students on how they can improve their group experience whether it is by participating more or some other form of interaction. Once this collaborative student model has been designed, the concept of the adaptive collaborative learning approach will be implemented within a Learning Management System such as Moodle. This approach will determine what recommendations will be provided to students in particular situations. Once this approach has been implemented we will look at evaluating it, using one of two options. The first option is evaluating the approach using simulated data, which will be created based on specific scenarios and group behaviour and be used to determine whether the output is in line with what is expected. The second option is to evaluate the adaptive collaborative learning approach through a pilot study with real student behaviour. In this case, students will be separated into two randomly selected core groups; those students who will use the adaptive collaborative learning approach and those students who will not use the adaptive collaborative learning approach. After the course has been completed, students’ behaviour from log files will be analyzed as well as students’ behaviour and their grades from the two groups will be compared to determine whether the adaptive collaborative learning approach in fact made a difference to the students’ learning. IV. DISCUSSION Adaptive collaborative learning is an important area of research because it allows current knowledge to extend beyond the individual student learning done by many researchers which will in turn help the online education working towards improving the student online learning experience and bridging the gap from tradition classroom learning. This is important because it allows a personalized approach to a students’ learning within a group that can be customized to each student and group. This has an advantage over traditional learning as the collaborative student model will monitor student behaviours and provide recommendations to enhance the quality of performance in groups. As more people and devices are becoming connected each day it is changing the way we consume information, and the same is true for the way students are learning and collaborating with others. Such adaptive collaborative learning approach will be beneficial to all institutions that use collaborative online learning or learning in a group because it will help students increase their participation in group tasks and make sure all students benefit from group activities by enhancing their experience. The research will be a beginning point for the industry with respect to an implementation of adaptive collaborative learning and allow other researchers to build on top of my work, as it would be open source. The research would hopefully not only benefit students to help them learn more effectively and increase their grades, but to also help other researchers within the field of personalized and adaptive learning. V. CONCLUSION While research on adaptive collaborative learning is still in the beginning stages, this project aims at demonstrating promising rewards for collaborative student learning and adaptive learning, as it will greatly benefit students and other researchers in adaptive learning, distance education and collaborative learning. The project implementation will demonstrate how adaptive collaborative learning will increase a students’ learning ability by including all the members within a group and enhancing the online learning experience. REFERENCES [1] [2] [3] [4] [5] [6] Durán, E. B., & Amandi, A. A. (2011). Personalised collaborative skills for student models. Interactive Learning Environments, 19(2), 143-162. doi:10.1080/10494820802602667 Anaya, A. R., & Boticario, J. G. (2011). Content-free collaborative learning modeling using data mining. User Modeling & User-Adapted Interaction,21(1/2), 181-216. doi:10.1007/s11257-010-9095-z Béres, I., Magyar, T., & Turcsányi-Szabó, M. (2012). Towards a Personalised, Learning Style Based Collaborative Blended Learning Model with Individual Assessment. Informatics In Education, 11(1), 1-28. Brusilovsky, P. (1996). Methods and techniques of adaptive hypermedia. User Modeling and User-Adapted Interaction vol. 6(2-3), 87-129. Chrysafiadi, K., & Virvou, M. (2012). Student modeling approaches: A literature review for the last decade. Expert Systems with Applications, 40, 4715-4729. Essawi, M., & Tilchin, O. (2011). Online Project-based Collaborative Learning: Complex Evaluation of Students. International Journal Of Technology, Knowledge & Society, 7(3), 101-116. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 23 M-Learning projects in Alberta schools Dermod Madden, Athabasca University derm.madden@aspenview.org Aspen View Public School Division No. 78 is a small rural district in northern Alberta. During the last two years the division has committed to a number of mobile/blended learning projects throughout the district. The purpose of this presentation is to highlight these projects, and to present a rationale for mobile learning in a K-12 context. Aspen View believes that such projects will facilitate much needed change within the public education system in Alberta; from traditional pedagogies of exclusion to one which embraces inclusive practice for all students. The implication of such fundamental change has equal significance for teachers and pedagogy. Mobile learning within a blended learning environment can assist this process and in so doing affect significant change to teaching practice and student learning. Mobile technologies have the potential to enhance existing educational supports and services in Alberta, where access to education is a right. As a source of technology, mobile devices are useful only to the extent that they assist in facilitating the learning process. The presentation will also focus on the process of change and the resistance to change within the public education system In Alberta, stand-alone labs are being replaced with portable wireless labs. Students are attending school with personal portable mobile devices, with or without school permission. Ubiquitous social networking is a reality. Social networking practices are providing opportunities for educators to engage students in inclusive learning environments. Mobile learning environments, under the guidance of the right teacher, have the potential to foster the necessary degree of ‘distance’ required by students to ensure the six dimensions of freedom associated with twenty-first century learning; access, content, media, pace, space and time, (Paulson, 1993). The flexibility of such ubiquitous engagement has serious implications for K-12 education in Alberta. Blended learning in this context is a combination of traditional classroom processes and online or virtual learning processes. Online learning by design and necessity is learner and process focused and requires student to student interaction and student to teacher interaction, (Greener, 2008). The operative term that defines such a learning environment is flexibility. A flexible learning environment is one that can function within the traditional classroom setting, and incorporate an online or virtual component. Blended learning, defined as a combination of traditional classroom and online or virtual learning processes, can accommodate singular learning processes as well as interactive, interdisciplinary collaborative learning processes, both online and in the regular classroom setting. Two events of significance have shaped the future of public education in Alberta, and in so doing may also have implications for mobile learning. The first was the ‘Setting the Direction’ initiative, launched in 2008, which, after a process of consultation with more than 6000 Albertans in 40 consultations, revealed the need for a change of focus in public education which acknowledges diversity and celebrates differences, within the context of a ‘inclusive framework’. The framework stipulates that all students have specific learning needs, and that differences should be deemphasized and diversity acknowledged, as stipulated in Article 26 of the Universal Declaration of Human Rights (1948). Article 26 stipulates that every individual is entitled to an appropriate education regardless of gender, race, color, or religion, without distinction of sex, language, political opinion, national or social origin, property, birth or other status. The inclusion of all students in regular schools is reflective of the international movement to provide equal opportunities and access for all learners in the same schools whenever possible (Forlin, Earle, Loreman, & Sharma, 2011; Katz, 2012). The second event of consequence was the release in April 2010, of an Alberta, government appointed steering committee report entitled ‘Inspiring Education: A Dialogue with Albertans’. The findings were significant in that they not only set the direction for the future of education in Alberta, but they also highlighted the significance of the student within the educational process. To achieve the goals of twenty-first century learning in Alberta, the following seven principles were identified as significant in shaping the future of education in the province. • Education should be learner-centered: decision-makers should consider the needs of children and youth first and foremost when making decisions. • Responsibility and accountability for education should be shared: acknowledging that parents are the primary guides and decision-makers for children. All partners in education should share responsibility and accountability for education outcomes. • Education implies the entire community: community resources should be fully engaged to support learners, including expertise, facilities, services and learning opportunities. Community resources; whether local, provincial, national or global; should actively participate in the education of learners. • Education implies inclusive, equitable access for all: every learner should have fair and reasonable access to Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 24 educational opportunities regardless of ability, economic circumstance, location, or cultural background. Their needs and ways of life should be respected and valued within an inclusive learning environment. Some learners will require additional specialized supports to fully access these opportunities. • Pedagogy and instructional design should be flexible and responsive to students’ needs: children and youth should have meaningful learning opportunities appropriate to each learner’s developmental stage, including learning that is experiential, multidisciplinary, community-based, and self-paced. To ensure the learning opportunities are relevant, the education system must be nimble in responding to the changing needs of communities and the world. • Resources should be developed that are both sustainable and efficient: decision-makers should identify and adopt strategies and structures that optimize resources (financial and human) and minimize duplication. • Changes in practice should reflect a commitment to innovation to promote and strive for excellence: Creativity and innovation are central to achieving excellence in education. Learners, educators and governors must be creative, innovative and entrepreneurial to attain the highest possible standards (Alberta Education, 2010). In September 2014, Aspen View committed to a mobile-learning project for students in K-12. Teachers in all schools were asked to submit E learning proposals for all grades which supported the seven principles of Inspiring Education, and the following ten skills identified as important for twenty-first century learners: • Sense-making. The ability to determine the deeper meaning or significance of what is being expressed. • Social intelligence. The ability to connect to others in a deep and direct way, to sense and stimulate reactions. • Novel and adaptive thinking. Proficiency at thinking and coming up with solutions and responses beyond that which is rote or rule-based. • Cross-cultural competency. The ability to operate in different cultural settings. • Design mind-set. Ability to represent and develop tasks and work processes for desired outcomes. • Cognitive load management. The ability to discriminate and filter information for importance and to understand how to maximize cognitive functioning using a variety of tools and techniques. • Virtual collaboration. The ability to work productively, drive engagement and demonstrate presence as a member of a virtual team. In addition, teachers were asked to consider the following changes to practice within the context of the E learning proposals: • The implementation of a competency based-based system of education • A review of assessment practices and designs to align with a competency-based system • The development of a process of formative assessment and continuous evaluation to ensure the achievement of outcomes To this end, Aspen View has distributed 240 tablets across its system to support a variety of innovative learning projects. In so doing we have created a paradigm that embraces the creation of capacity from within, and a commitment to ‘best practices in public education. REFERENCES [1] [2] [3] [4] [5] Alberta Education. (2010). Inspiring Education. http://www.inspiringeducation.alberta.ca Forlin, C., Earle, C., Loreman, T., & Sharma, U. (2011). The sentiments, attitudes, and concerns about inclusive education revised (SACIE-R) scale for measuring pre-perceptions about inclusion. Exceptionality Education International, 21(3), 50-65. Greener, S. (2008). Self-aware and Self-directed: Student Conceptions of Blended Learning. Merlot Journal of Online Learning and Teaching. 4(2) 243-253. Katz, J. (2012). Reimaging inclusive education (Inclusion). Canadian Association of Principals, 22-26. Paulsen, M. F. (1993). The hexagon of cooperative freedom: A distance education theory attuned to computer conferencing. DEOSNEWS, 3(2), October 13, 2009. Retrieved from http://www.nettskolen.com/forskning/21/hexagon.html • Computational thinking. The ability to translate vast amounts of data into abstract concepts and to understand data-based reasoning. • New-media literacy. The ability to critically assess and develop content that uses new media forms and to leverage these media for persuasive communication. • Transdisciplinarity. Literacy in and ability to understand concepts across multiple disciplines. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 25 Promoting Self-Regulatory Capacities of a Novice Programmer Cadoukpe Bertrand Sodjahin, Athabasca University bercadson@yahoo.fr Abstract—This research proposes to develop a mixed-initiative interactive dashboard that engages learners in conversation about what they know and can do at successive instructional points of their coding requirements in a programming course. The goal of this dashboard is to build their self-regulatory competencies in aspects of coding, debugging, testing, and documenting software. Index Terms—SRL, self-regulation Learning, programming, coding, academic, algorithm, debugging, software I. INTRODUCTION A significant portion of learners graduating from academic institutions are unable to participate effectively in our knowledge society mostly because they lack study competencies [1] [2] [3]. Self-Regulated Learning is a seminal educational theory that explains this underperformance in terms of adaptation strategies, learning transformations, and diversity in study habits among learners [4] [5] [6]. This research suggests the development of a mixed-initiative interactive dashboard, the objectives of which is to construct their self-regulatory proficiency pertaining to code writing and debugging as well as the software testing and its documentation. II. LITERATURE AND PROBLEM STATEMENT Literature reports that high achieving learners exhibit discernible self-regulatory abilities such as goal setting, self-monitoring, seeking help, and self-efficacy, but with two caveats. First, the quality of how well learners apply these abilities within and across contexts could not be measured. To address this, this research will develop the dashboard to indicate the evolution of various self-regulatory traits exhibited by the student and engage students in conversations about whether students use these traits between problems in the same assignment or across multiple assignments. Second, relations between these abilities and learning outcomes (e.g., grades, application skills, and topic comprehension) could not be proven [7] [8] [9]. To address this, this research will develop algorithms to estimate the utility of self-regulatory traits in improving coding competency. III. RESEARCH HYPOTHESIS This research hypothesizes that these two challenges can be computationally addressed by advancing contemporary model-tracing techniques [10] using big data learning analytics. This research proposes a) to ontologically capture long-term learner interactions using a real-time, model-tracing software system [11] b) to extract long-term non-intrusive self-regulation measurements that indicate the quality of application of self-regulatory abilities[12] [Kumar 2007; [13] and 3) to infer causality between study habits of learners and their learning outcomes [14] . IV. METHODS AND RESEARCH QUESTION First of all, this research seeks to record learners' self-regulatory tendencies in task-specific online learning contexts, across multiple competencies, in a formal manner, over longer periods of academic life - for example, through the last 2 years of high school or the four years of an undergraduate degree. We seek to identify computational boundaries to record/process study habits that span the academic life of a learner and target the notion of lifelong learning. Can we compare online study habits of learners from participating institutions within the country and across continents? REFERENCES [1] [2] [3] [4] HRD, Canada. (2002). Department of Human Resources Development Canada, www.hrle.gov.nl.ca/hrle/publications/Doing%20What%20Works%20Ba ckground%20Report4.pdf and http://www11.sdc.gc.ca/sl-ca/doc/knowledge.pdf Bali, Valentia A. & R. Michael Alvarez. (2004). “The Race Gap in Student Achievement Scores: Longitudinal Evidence from a Racially Diverse School District,” The Policy Studies Journal, Vol 32, No. 3, pp. 393-415, 2004. Lock K. (2006). “What accounts for the ethnic gap in student test scores in New Zealand?, in Proceedings of the 47th National Conference of the New Zealand Economists, Available online at: http://www.nzae.org.nz/conferences/2006/JW-49-LOCK.pdf, 2006. Winne, P. H. (2001). “Self-regulated learning viewed from models of information processing”, In B. J. Zimmerman and D. H. Schunk (Eds.), Self-regulated learning and academic achievement: Theoretical perspectives, 2nd ed, pp. 153-189, Mahwah, NJ: Lawrence Erlbaum Associates. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] 26 Winne, P. H., & Hadwin, A. F. (2002).“Studying as self-regulated learning”, In D. J. Hacker, J. Dunlosky, & A. C. Graesser (Eds.), Metacognition in educational theory and practice, pp. 277-304, Mahwah, NJ: Lawrence Erlbaum Associates. Zimmerman, B. J. (2000). Self-Regulatory Cycles of Learning. In: Gerald A. Straka (Ed.): Conceptions of Self-Directed Learning. Münster: Waxmann, 221-234. Boekaerts, M., Maes, S., & Karoly, P. (2005). Self-regulation across domains of applied psychology: Is there an emerging consensus? Applied Psychology: An International Review, Vol 54, No 2, pp. 149-154. Gress, C. L. Z. & Winne, P. H. (2007). Measuring Cognitive & Metacognitive Monitoring of Study Skills with Trace Data. Paper to be presented at the Annual Convention of the American Educational Research Association, Chicago, IL, USA. Purdie N., Hattie J. (1999). “The relationship between study skills and learning outcomes: A meta-analysis”, Australian Journal of Education, vol. 43, no.1, pp. 72-86 Anderson, J. R., Albert, M. V., & Fincham, J.M. (2005). Tracing Problem Solving in Real Time: fMRI Analysis of the Subject-Paced Tower of Hanoi. Journal of Cognitive Neuroscience, 17 1261-1274. Shakya J. (2005). “Capturing and Disseminating Principles of Self-Regulated Learning in an Ontological Framework”, MSc dissertation, Simon Fraser University, Surrey, Canada. Kumar V. (2007). “Capturing and Disseminating Shareable Learning Experience”, In Proceedings of the Workshop on AI for Human Computing at 20th International Joint Conference on Artificial Intelligence (IJCAI-07), Hyderabad, India, pp. 107-114. Kumar V., Winne P.H., Hadwin A.F., Nesbit J.C., Jamieson-Noel D., Calvert T., & Samin B. (2005). Effects of self-regulated learning in programming, IEEE International Conference on Advanced Learning Technologies (ICALT 2005), Kaohsiung, Taiwan, 5-8 July, 383 – 387. Brokenshire, D. (2008). Discovering causal models of self-regulated learning. Master’s Thesis, Simon Fraser University, Canada. Aine S., Chakrabarti P., & Kumar, R. (2007). “AWA* - A Window Constrained Anytime Heuristic Search Algorithm”, Proceedings of the International Joint Conference on Artificial Intelligence, Hyderabad, India, pp. 2256-2261. Dodier R.H. (1999). “Unified prediction and diagnosis in engineering systems by means of distributed belief networks”, PhD dissertation, University of Colorado, Boulder, USA. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 27 Automatic Twitter Topic Summarization Geoffrey Marshall, Athabasca University geoffrey.marshall@gmail.com Abstract— The project aims to generate digests of tweets from live trending and ongoing topics. Summarization is accomplished using an non-parametric Bayesian model applied to Hidden Markov Models and a novel observation model designed to allow ranking based on selected predictive characteristics of individual tweets. Index Terms—twitter analysis, non-parametric Bayesian model, hierarchical Dirichlet process, infinite HMM, text summarization I. INTRODUCTION T HE purpose of this project was to investigate the possibility of using a temporal probabilistic data model known as a Hierarchical Dirichlet Process Hidden Markov Model (HDP-HMM) to process a stream of tweets pertaining to a single subject and cluster the tweets into groups or rankings based on the value of the individual tweets. Twitter is widely claimed to have a very high “signal-to-noise” ratio [1] and it is therefore potentially useful to be able to provide a summarized digest of high-value tweets based on automatically generated ranking values. II. BACKGROUND The HDP-HMM model is based on the Hidden Markov Model (HMM) — a popular statistical modelling tool widely used to evaluate sequential processes as a first-order Markov Chain [2]. The process is represented as a series of states that are “hidden” -- in other words not directly observable. A HMM attempts to provide statistical information regarding the state at each slice in a given sequence of states. In addition to the state sequence, an HMM consists of an alphabet of emission symbols, or observations. Along with the states and observations, HMMs require two transition matrices: the first specifying the probability of any state transitioning to any other state, and the second specifying the likelihood that any state emits or produces any particular observation. Given these elements and an initial starting state, various algorithms can be employed to efficiently reason based on the provided sequence. HMMs have been previously used for problems of sentence extraction. Sentences are converted into observation symbols by identifying predictive features such as number of unique query terms in a sentence, number of words in a sentence, position of the sentence within the paragraph or overall document, etc. [3]. One of the key limiting factors of the classical HMM stems from the fact that the state model is constrained to a predetermined number of possible states. This limits the usefulness of the model when working with data sets where the number of states is previously unknown or changes over time. The Infinite Hidden Markov Model (iHMM) was introduced as a possible answer to this problem [4]. The iHMM proposed a method whereby the relationship between a state and all other states would be represented not only as a simple probability distribution calculated from the state-to-state transition matrix, but as a process where the resulting distribution would contain the possibility that the resulting state is not one of the currently known states, but is a new state. This is accomplished by the use of a Dirichlet Process (DP) [5] — a random process whose sample functions are probability measures, a “measure of measures”. The DP has two properties — a base measure and a scaling parameter. As a non-parametric Bayesian model, the primary problem of the iHMM is to infer a prior distribution for the hidden state based on the observations [6]. Instead of calculating the prior as simple distribution based on the state matrix — or, in the case of observations, from the emission matrix — a DP is used where a random distribution is produced using the state matrix (or emission matrix) as the source of the base measure and a random hyperparameter as the scaling parameter. This alone is not sufficient to generate an HMM with infinite states because any new states, although produced by the DP, would never be selected since they do not have any transitions recorded in the transition matrices. The HDP-HMM [7] solves this problem by creating a model where the base measure of the DP is not derived from the transition tables but from another global DP. Thus, new states have a possibility of being selected since this step is based on a random DP process. The HDP-HMM is therefore a good candidate for modelling a stream of tweets due to the temporal nature of the model and the flexibility to handle an infinite state space. III. OBSERVATION MODAL HMMs attempt to model temporal processes using two matrices. First, the state transition matrix contains counts of the number of times a given state has transitioned to any other state. Second, and more crucially for this discussion, is the observation matrix. This matrix stores the various possible observations and the counts of their state emissions. It is often also called an emission matrix since it contains the counts of states emitted by various observations. The observations describe real world, measurable traits. For example, counts of tree rings or temperature values [8]. For complex temporal processes it is often not possible to directly map the observation value itself to a numeric value for Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 28 the purposes of the observation matrix. For example, a tweet consists of a chunk of words along with other attributes and the iHMM has no way to directly parse the raw information. An observation model was therefore developed to convert a single tweet into a numeric token. The resulting stream of tokens was sent as a vector to the iHMM which returned a stream of state tokens. The state stream contained a single state for each emission. In principle, similar tweet emissions would end of being assigned similar states, thus leading to the possibility of grouping similar tweets together, or of filtering them, based on their assigned states. The mechanism used by the observation model for distilling the tweet into an emission was therefore of the highest importance. Metrics used include: 1. Has the tweet been retweeted? - Boolean value 2. Doe the tweeter have more than 126 followers? - Boolean value 3. Is the tweet a reply? - Boolean value 4. Does the tweet contain hashtags? - Boolean value 5. Does the tweet contain user mentions? - Boolean value 6. Is the tweet a retweet? - Boolean value 7. Has the tweet been marked as a favorite by anyone? Boolean value 8. Does the tweet contain at least one of the search terms? Boolean value 9. How many top ten words (nouns only) does the tweet contain, up to 5? Range value (0…5). IV. ALGORITHMS Standard algorithms employed with the classical HMM are unsuitable for use with the HDP-HMM because they iterate over the entire state space, which is infinite in this case. Various algorithms have been developed to address this need and this project focused on using the beam sampler [9]. The beam sampler considers each time-step of the HMM in a slice that has a finite number of possible states. There is no need to sample an infinite state space in this case and each slice of the sampler ends with the possibility of having extended the state space. The resulting vector of hidden states produced by the beam sampler running against the HDP-HMM was used to tag each tweet with its matching state. The structure of observation model, having been built on predictive characteristics of the tweet selected to allow the model to cluster tweets based on the information content and popularity of the tweet, implies that the tweets clustered together into smaller groups have a higher “value” and should be selected for inclusion in the final summarized digest of tweets. V. RESULTS A web news site was built (syntacti.ca) that provided an extract from the Twitter stream, based on high-value tweets identified by the HDP-HMM, that matched currently trending topics sourced using Yahoo content and the Yahoo YQL API [10]. These topics were to the HDP-HMM processing loop and the results were saved in a database for retrieval. In addition a generic topic entitled “World New” was supplied to provide an ongoing summarization of tweets matching this topic. The site presented users with the following content: 1. Topic Timeline View - A timeline presentation showing historical tweets for past hours and days. Tweet tags were shown on the timeline and the tweet icon could be selected for more detail. Tweets were selected for each date by choosing the tweets corresponding to the clusters with the least tweets for the day. 2. Tweet Stream - Tweets from the current date were shown in a list in their entirety. Tweets were selected by choosing the tweets corresponding to the clusters with the least tweets for the most recent date. Overall, the tweet digest produced a stream of tweets that contained roughly 4% of the original source stream. In the addition, the resulting summarization contained a far higher ratio of “high-value” tweets compared to the raw stream, containing roughly 90% on-topic tweets and 70% of selected tweets contained meaningful data. VI. CONCLUSIONS The approach showed significant potential for meeting the project design goals, in terms of fast online summarization of tweet streams and summarization quality. The high volume of tweets gives credence to such a system since, without a summarization, it is practically impossible to read a stream of tweets and obtain the overall opinion and attitude expressed by the users and also to uncover the undoubted high-value information obscured by the high noise of the unfiltered Twitter stream. REFERENCES [1] R. Kelly. (2009, August 12). "Twitter Study – August 2009" [Online]. Available: http://www.pearanalytics.com/wp-content/uploads/2012/12/Twitter-Stu dy-August-2009.pdf [2] L. R. Rabiner, “A tutorial on Hidden Markov Models and selected applications in speech recognition,” Proceedings of the IEEE, vol. 77, no. 2, 257-286, 1989. [3] J. M. Conroy, J. D. Schlesinger, D. P. O'Leary, M. E. Okurowski, “Using HMM and Logistic Regression to Generate Extract Summaries,” In DUC Workshop on Text Summarization (with ACM SIGIR) . 2001. [4] M.J. Beal, Z. Ghahramani, and C. Rasmussen, “The Infinite Hidden Markov Model,” in T. G. Dietterich, S. Becker, and Z. Ghahramani (eds.) Advances in Neural Information Processing Systems, Cambridge, MA: MIT Press, vol. 14, pp. 577–584, 2002. [5] C. E. Antoniak, “Mixtures of Dirichlet Processes with Applications to Bayesian Nonparametric Problems,” The Annals of Statistics, vol. 2, no. 6, pp. 1152-1174, Nov., 1974. [6] J. Sethuraman, “A constructive definition of Dirichlet priors,” Statistica Sinica, 4, 639-650, 1994. [7] Y. W. Teh, M. I. Jordan, M.J. Beal, & D. M. Blei, “Hierarchical Dirichlet Processes". Technical Report 653, UC Berkeley Statistics, 2004. [8] M. Stamp. (2012, September 28). “A Revealing Introduction to Hidden Markov Models.,” [Online]. Available: http://www.cs.sjsu.edu/~stamp/RUA/HMM.pdf [9] J. Van Gael, Y. Saatci, Y. W. Teh, and Z. Ghahramani, “Beam sampling for the infinite hidden Markov model,” In Proceedings of the International Conference on Machine Learning, vol. 25, 2008. [10] Yahoo Developer Network, [Online]. Available: http://developer.yahoo.com/ Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index 2nd International Graduate Research Workshop (IGRW 2014) 29 Agent Coordination and Reasoning Capabilities for Adaptive Assessment in Quiz Games Steeve Laberge, Athabasca University slaberge@acm.org Abstract—The use of games in an educational context has proven to be an effective means to motivate learners and enhance learning for decades, and recent research again confirms their intrinsic value not only as a complementary learning tool, but also as a non-intrusive method of formative assessment. However, the customization of a learner's gaming experience based on his/her abilities, preferences and interpretation of assessment results is an important facet that largely remains unexplored territory. Current adaptive testing techniques have been primarily designed for the specific task of assessing learner ability levels in the context of summative assessment and fall short of the type of dynamic decision-making processes that are required for game based environments. This research proposes a novel collaborative approach for game-based adaptive assessment in the form of a multi-agent system (MAS) that uses the Belief-Desire-Intent (BDI) agent paradigm to (1) prepare game plans that are tailored to each individual's knowledge levels and learning goals, (2) implement stealth assessment techniques to maintain an adequate level of challenge during game play while maintaining learning "flow", and (3) capture and process game results in real-time and update the learner's competency levels with a view to confirming learning goals and adapting subsequent game cycles accordingly. Index Terms—Educational reward, academic achievement, motivation, learning activities, game I. INTRODUCTION W hen compared to traditional pencil and paper tests and even advanced computerized adaptive testing (CAT) systems, game-based assessment is a much more complex undertaking in which aspects such as game playability and educational value must be taken into consideration [1]. Significant deviations in either aspect can disrupt what is known as "learning flow" and annihilate the educational value of the game [2,3]. As such, incorporating adaptive testing capabilities to game-based environments requires interactions beyond those found in traditional testing systems, and intelligent agents are emerging as the dominant form of enabling technology in pursuit of that goal [4]. Going back to the basic characteristics of agents, one can see that they are indeed ideally suited for that purpose: • Agents are goal-oriented - they can be designed to pursue one or more goals, using either declarative methods, derived by inference from multiple known facts, or by injection through external inputs. • Agents are autonomous - they can act autonomously towards achieving their goals, i.e. without external global control • Agents are situated - intelligent agents are "context aware". They can perceive changes in their environment and also affect it through their actions. • Agents are proactive and adaptive - agent can be opportunistic and act in their best interest when the right conditions are met (as opposed to a more reactive approach triggered by external events) • Agents are social - they can interact with other agents in a multi-agent system. In a game environment, agents can either be purely AI-based (also known as Non-Person Character - NPC in immersive simulation environments) or can represent real-people. Communications between agents is paramount to ensuring a high degree of socialization. Under a MAS-based approach, adaptive testing functions such as item selection and ability assessment can be now be handled by collaborative, goal-driven agents rather than procedurally, making the overall architecture much more open and flexible than other techniques. II. THEORETICAL BASIS FOR THIS RESEARCH This research is grounded on well-established theories in the fields of artificial intelligence, computerized adaptive testing and game based learning: • Item Response Theory (IRT). The Item Response Theory (IRT) is the dominant psychometric evaluation technique used in Computerized Adaptive Testing-based systems, including those used in admission tests such as the Graduate Record Examination (GRE). IRT's main tenant is that the probability of a correct answer to a question (referred as an item) can be calculated as a function of person abilities and item characteristics [5]. It has been shown that adequately predicting student performance and tailoring the game interplays as a function of the student’s knowledge profile greatly improves the effectiveness of games as a learning tool [6]. IRT therefore plays a pivotal role in the design of the proposed MAS-based adaptive testing framework. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index Chang, M. (Ed.) 30 • Game based assessment. Authoritative work in the field of game based learning and assessment has been used to establish the underlying principles of the proposed MAS-based approach to game based learning and assessment. In particular, “Stealth assessment” [3] is an important concept that has been emerging in the last few years in which assessment functions are so interwoven into the fabric of the game that the learners are unaware that they are being tested. This concept has proven its worth in terms of accuracy and effectiveness of games as an assessment tool. • Belief-Desire-Intent (BDI) agent theory. The proposed MAS-based gaming framework requires the highest degree of autonomy and reasoning capability on the part of the agents that participate in the decision making process. The BDI agent paradigm [7] is ideally suited for that purpose. Based on key aspects of Michael Bratman’s theory of human practical reasoning, BDI agents establish a clear separation between belief (assumptions), desire (goal) and intent (selection of a plan to move towards a goal). III. EXPERIMENTAL TEST BED DESIGN The first stage of this research, which focused on developing the theoretical concepts and defining the architecture of the experimental test bed, was completed last year. REFERENCES [1] R. Van Eck, "Building artificially intelligent learning games," in Games and simulations in online learning: Research and development frameworks, 2007, pp. 271-307. [2] T. Augustin, C. Hockemeyer, M. Kickmeier-Rust and D. Albert, "Individualized Skill Assessment in Digital Learning Games: Basic Definitions and Mathematical Formalism," in IEEE Transactions on Learning Technologies, vol.4, no.2, 2011, pp. 138-148. [3] V.J. Shute, "Stealth assessment in computer-based games to support learning," in Computer games and instruction, 2011, pp. 503-524. [4] W. Joost, F. Dignum, and V. Dignum, "Scalable adaptive serious games using agent organizations," in 10th International Conference on Autonomous Agents and Multiagent Systems, vol. 3, International Foundation for Autonomous Agents and Multiagent Systems, 2011, pp. 1291-1292 [5] R.K. Hambleton, H. Swaminathan, and H.J. Rogers, “Fundamentals of Item Response Theory”. Newbury Park, CA: Sage Press, 1991. [6] N. Thai-Nghe, L. Drumond, T. Horváth, A. Krohn-Grimberghe, A. Nanopoulos and L. Schmidt-Thieme, “Factorization techniques for predicting student performance”, Educational Recommender Systems and Technologies: Practices and Challenges (In press), IGI Global, 2011. [7] A.S. Rao, M.P. Georgeff, et al., “BDI agents: From theory to practice”, in Proceedings of the first international conference on multi-agent systems, ICMAS-95, 1995, pp. 312-319 Key elements of the architecture include: • A repository, which stores the student’s model, the game artifacts and historical data on game performance • The Multi-Agent System Environment itself, which uses the repository as main input for the decision making process and for establishing actions in the gaming environment • The gaming environment, a web based framework that enacts the gaming scenarios, accepts student input and feeds student performance data to the MAS core system. IV. NEXT STEPS This research has entered Stage 2 in February 2014, which will take the design to the second level of detail and will see the implementation of the MAS algorithms to support the high-level interaction model defined in stage 1. It is expected that this phase will take 6 months to complete. Athabasca University EdTech Forum: Practices, Ideas and Experiences (EdTech PIE) http://adapt.athabascau.ca/index.php?edtech-pie/index