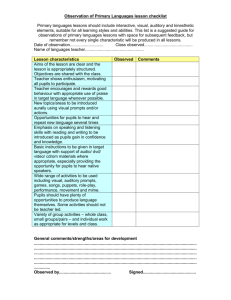
WEIGHTED STATISTICAL MEASURES FOR GROUPED DATA
advertisement

WEIGHTED STATISTICAL MEASURES FOR GROUPED DATA
Nancy Stevens, Texas Education Agency
essential for calculation of the statistics
are:
INTRODUCTION
Research in the social and policy sciences
often combines a methodology that defines
the individual as the unit of analysis with
data that is available only at the group level.
There are two directions the research design
can follow--either modify the data to
correspond to the unit of analysis or modify
the calculations for use with grouped data.
The major benefit of the second approach is
the smaller data set--one observation for
each group compared to one observation for
each individual. The advantages of working
with a smaller data set sometimes outweigh
the additional time required to modify
statistical calculations for use with grouped
data.
1. One observation for each school district the group (DISTRICT)
2. A variable representing the number of
pupils in each school district - the unit of
analysis (PUPILS)
3. Per-pupil revenue equal to total revenue
divided by number of pupils (PERCAP=
REVENUE/PUPILS) - adjustments to revenue
(cost of living or price differential indexes)
and number of pupils (need equivalence
scales) are made before computing the
average
4. Variables for number of pupils (PUPILS)
and per-pupil revenue (PER CAP) appear in the
data set in that order (matrix configuration)
This paper describes a procedure for
calculating weighted statistical measures
for grouped data. The procedure entails (1)
creating SAS® data sets, (2) modifying
statistical formulas, (3) using SAS
statistical procedures, and (4) writing basic
SAS code to calculate statistics. Statistical
measures include general statistical
dispersion measures as well as income
inequality measures and measures developed
through research in school finance. The
example is from the area of school finance.
The school district is the smallest unit for
which data on educational revenues is
available; however, the accepted methodology
in school finance research often defines the
pupil as the unit of analysis. As a proxy for
the pupil unit of analysis, the average
revenue per pupil for each school district is
used in analysis and each school district is
weighted according to the number of pupils in
attendance.
5.
Data set is sorted by per-pupil revenue
It is also assumed that the number of pupils
in each school district varies.
STATISTICAL FORMULAS
The following statistical notation is used
throughout the 'examples,
Wi = number of pupils in school district i
Xi = per-pupil revenue in school district
natural logarithm of per-pupil
revenue in school district i
N = number of school districts
M = number of school districts in which the
per-pupil revenue is below the median
DATASET
Unless otherwise noted, the summation sign L
is understood to denote Li= 1:N·
MODEL is the primary data set used in the
examples. Variables are DISTRICT (unique
identifier for each school district), PUPILS
(number of pupils in the school district),
REVENUE (school district total revenue), and
PERCAP (average revenue per pupil).
Characteristics of the data set that are
Two types of modifications to the formulas
are required for weighted statistics. In the
summation LXi, the index i assumes in
succession the values of all the observations
from ito N, The result is the sum of the
799
values of X for all observations from j to N.
In the case of grouped data, each observation
respresents a group, and the value of X
applies to every member of the group. To
achieve the desired result--the sum of the
values of (X times W) for all observations
from j to N --the formula is modified to
IW jXj. The second modification to the
formulas involves replacing the variable N
(number of observations) with IWj (unit of
analysis). These two changes are repeated
for each element of all statistical formulas.
Following are examples of formulas for
unweighted and weighted statistics.
It may be possible to simplify formulas,
thereby simplifying the programming required
to calculate the statistics. An example is the
formula for the weighted Gini coefficient.
The Gini coefficient formula involves
matching every observation with every other
observation, resulting in duplicate sets of
matching pairs (school district j with school
district j, and school district j with school
district /). Since the formula uses the
absolute value of differences, duplicate pairs
can be eliminated and the formula reduced to
the following easier to code equivalent:
Gini Coefficient
(IIj = 1 :NI Xj- Xj 1)1 [2 (N) 2 (IXj I N)]
Often statistics produced by SAS statistical
procedures appear as elements of a formula
not produced by the procedure. The
denominator of the Gini coefficient formula
consists of the sum of the weight variable
and the mean, both produced by the MEANS
procedure.
(IIj =1 :NWjWj IXj- Xj 1)1
[2(IWj)2(IWjXjl IWi}l
SAS STATISTICAL PROCEDURES
The WEIGHT procedure information statement
can be used with many SAS statistical
procedures to compute statistics when
observations are grouped data. The WEIGHT
statement identifies a variable whose values
are relative weights for the observations.
The VARDEF option, which .can often be used
along with the WEIGHT statement, specifies
the divisor that is used to calculate the
variance. The WEIGHT statement cannot be
used with some statistical procedures, and
may not apply to all statistics produced by a
procedure when it is used. However, when the
WEIGHT statement is used, it applies to all
variables in the analysis.
Several features of the SAS language are
particularly useful when writing code for
statistical calculations. The sum statement
works much like the summation sign (I) in
mathematical notation. The results of a
mathematical operation are added to a
variable as the operation is performed on
each observation. When used in conjuction
with the END= data set option, the final
result of the summation can be assigned to a
macro variable for use in later calculations
andlor output to a data set without saving all
the intermediate values of the operation.
CALCULATION OF WEIGHTED STATISTICS
BASE SAS CODE
In the following examples, formulas and
descriptive information appear in the left
column with corresponding SAS code in the
right column. All formulas and SAS code
presented are for weighted statistics. If the
data set had an observation for each pupil,
then the variable representing the number of
individuals in each group would be set equal
to one.
Not all statistics computed by SAS
statistical procedures are weighted and most
areas of research rely upon a wide range of
field-specific statistical measures that are
not produced by SAS statistical procedures.
The basic SAS language is well suited for
programming statistical calculations.
Writing SAS code for statistical calculations
begins with the formulas for the statistical
measures. For weighted statistics the
formulas are modified as described above.
800
DATA MODEL
(KEEP=PUPILS REVENUE PERCAP LOGPRCAP);
MERGE STUDENTS
(IN=A KEEP=DISTRICT PUPILS)
BUDGETS
(IN=B KEEP=DISTRICT REVENUE);
BY DISTRICT;
IF A AND B;
PERCAP=REVENUE!PUPILS;
LOGPRCAP=LOG(PERCAP);
STATISTICAL DISPERSION MEASURES
General statistical dispersion measures used
in school finance equity research are the
range, mean, standard deviation, coefficient
.of variation, and standard deviation of the
natural logarithm. The WEIGHT procedure
information statement used with the MEANS
procedure produces weighted dispersion
measures and sums. The option VARDEF=WDF
requests that the sum of PUPILS minus one
be used as the divisor in calculation of the
variance.
PROC SORT DATA=MODEL;
BY PERCAP;
PROC MEANS DATA=MODEL
NOPRINT VARDEF=WDF;
VAR PERCAP LOGPRCAP;
WEIGHT PUPILS;
OUTPUT OUT=MDLMEAN RANGE=RANGE
MEAN=MEAN SUMWGT=TOTPUPIL
CV=CV STD=STDVAR STDLOG
SUM=TOTALREV;
Two additional measures of deviation in perpupil revenue from the mean are the relative
mean deviation and Theil's measure. The
relative mean deviation, calculated from the
absolute values of the differences between
per-pupil revenues and the mean, is the
differences as a percent of total revenue.
Theil's measure, originally developed as a
measure of entropy in information theory,
incorporates the natural logarithm of perpupil revenue.
Range
DATA MDLMEAN;
SET MDLMEAN;
LOGMEAN=LOG(MEAN);
CALL SYMPUT('MEAN',MEAN);
CALL SYMPUT('LOGMEAN',LOGMEAN);
CALL SYMPUT('TOTALREV',TOTALREV);
CALL SYMPUT('TOTPUPIL',TOTPUPIL);
LABEL TOTPUPIL='TOTAL PUPILS'
TOTALREV='TOTAL REVENUE'
MEAN='AVERAGE PER-PUPIL REVENUE'
LOGMEAN='LOG PER-PUPIL REVENUE'
STDVAR='STANDARD DEVIATION'
STDLOG='STANDARD DEVIATION OF LOG'
CV='COEFFICIENT OF VARIATION'
RANGE='RANGE PER-PUPIL REVENUE';
Highest Xi - Lowest Xi
Standard deviation
Sw = "[2:WdX w - Xil 2 1 2:Wi-1]
Coefficient of variation
DATA DEVCALCS(KEEP=RELMNDEV THEIL);
SET MODEL END=EOF;
TOTALDEV +
(PUPILS*(ABS(PERCAP-&MEAN»);
THEILNUM+(PUPILS*«PERCAP*LOGPRCAP) (&MEAN*&LOGMEAN»);
IF EOF=l THEN DO;
RELMNDEV=TOTALDEV!&TOTALREV;
THEIL=THEILNUM!&TOTALREV;
OUTPUT;
END;
ELSE DELETE;
LABEL RELMNDEV='REL MEAN DEVIATION'
THEIL='THEIL"S MEASURE';
10 a S wi Xw
Standard deviation of the natural logarithm
"{2:Wi[1 ogeXi- (2:Wil ogeXjl 2:Wj- 1 )]21
2:Wj- 1)
Relative mean deviation
(2:WilXj- Xwlll (2:WjXil
Theil's measure
[2:Wj(Xjl og eXj- Xwl og eXw)]1 (2:WjXil
LORENZ CURVE AND GINI COEFFICIENT
The Lorenz curve is a plot of the percentage
of total revenue available to increasing
percentages of pupils when the pupils are
ranked by per-pupil revenue. When the same
revenue is available to each pupil (perfect
equity), the Lorenz curve is a 45 degree line
running from the 0,0 coordinate to the
DATA LORENZ;
SET MODEL;
CUMPCTP+«PUPILS!&TOTPUPIL)*lOO);
CUMPCTR+«REVENUE!&TOTALREV)*lOO);
CUMPCTEQ=CUMPCTP;
LABEL CUMPCTP='PERCENT OF PUPILS'
CUMPCTR='PERCENT OF REVENUE';
801
100,100 coordinate. The greater the inequity,
the farther the Lorenz curve lies below this
45 degree line. The Gini coefficient is a
measure of the area between the Lorenz curve
and the line of perfect equity.
Gini coefficient
(ILj ~1 :NWjWj IXj- Xj 1)1 [2(IWj)2Xw]
PROC PLOT DATA=LORENZ NOLEGEND;
PLOT CUMPCTR*CUMPCTP=' * ,
CUMPCTEQ*CUMPCTP='-' / OVERLAY
VAXIS=O TO 100 BY 10
HAXIS=O TO 100 BY 10 VZERO HZERO;
TITLE1 'GRAPH OF LORENZ CURVE';
TITLE2 'SAMPLE MODEL';
FOOTNOTE1 '--- PERFECT EQUITY';
FOOTNOTE2 1*** SAMPLE MODELl;
Ql. (IIj ~j +1 :NWjWjIXj- Xj
DATA GINIDATA;
SET MODEL(KEEP=PUPILS PERCAP);
1)1 [(IWj)2X w ]
PROC MATRIX;
FETCH GINIMTRX DATA=GINIDATA;
NUMERATR=O;
N=NROW(GINIMTRX);
NBRLOOPS=N-1;
DO 1=1 TO NBRLOOPS BY 1;
ONEDIST=GINIMTRX(I,l 2);
STRTPAIR=I+l;
OTHERDST =
GINIMTRX(STRTPAIR:N, 1 2);
DIFREV=OTHERDST(*,2)-ONEDIST(*,2);
PUPLPROD =
ONEDIST(*,l)#OTHERDST(*,l);
PRODUCT=DIFREV#PUPLPROD;
ABSDIF=SUM(PRODUCT);
NUMERATR=NUMERATR+ABSDIF;
FREE ONEDIST OTHERDST STRTPAIR
DIFREV PUPLPROD PRODUCT ABSDIF;
END;
FREE GINIMTRX N NBRLOOPS;
OUTPUT NUMERATR OUT=GINI;
FREE NUMERATR;
STOP;
The PLOT procedure produces a graphical
display of the Lorenz curve. Since calculation
of the Gini coefficient requires comparisons
between observations, the MATRIX procedure
is used. In the DO loop, each observation
(ONEDIST) is paired with all remaining
observations (OTHERDST) in the distribution.
Since the observations are sorted by perpupil revenue, ONEDIST (Xj) is always
smaller than or equal to OTHERDST (Xj) and
OTHERDST minus ONEDIST is a positive
number. There are no remaining observations
with which to compare the last observation
(NBRLOOPS~N-1 ).
ATKINSON'S INDEX
Atkinson's index is based on a social-welfare
function that measures the total welfare of a
per-pupil revenue distribution. The formula
includes a parameter E, which can vary from
zero to infinity. As the value of E increases,
concern for adequacy decreases and concern
for equity increases. Theoretically and
empirically, Atkinson's index can be
considered two measures, depending upon
whether a high or low value of E is used.
DATA GINIMDL(KEEP=GINICOEF);
MERGE GINI MDLMEANS;
GINICOEF = COLI /
(TOTPUPIL*TOTPUPIL*MEAN);
LABEL GINICOEF='GINI COEFFICIENT';
%MACRO ATKINSON;
%DO 1=2 %TO 10 %BY 2;
DATA ATKIN&I;
SET MODEL END=EOF;
KEEP 1&1;
ATKIN&I =
«PERCAP/&MEAN)**(l-&I))*PUPILS;
SUM&I+ATKIN&I;
IF EOF=l THEN DO;
I&I=(SUM&I/&TOTPUPIL)**(1/1-&I);
Atkinson's index
([IWj(Xjl Xw) 1- E]I (IWj)l 1/ (1- E)
The range of values of the parameter E can be
changed to any series of positive integers by
changing the start, stop, and increment
values of the iterative DO statement. As a
practical matter, it may be necessary to
limit the maximum value of E. With large
values of E, the combination of a small
exponent (1-E) and a small value of Xjl Xw
(PERCAP/&MEAN) may exceed computer
capacity.
LABEL I&I=lIATKINSON E
:=
&1";
OUTPUT;
END;
ELSE DELETE;
%END;
%MEND ATKINSON;
%ATKINSON
DATA ATKIN;
MERGE ATKIN2 ATKIN4 ATKIN6 ATKINS
ATKINIO;
802
WEIGHTED QUANTIlES
DATA RANGE5 BELOW ABOVE,
SET MODEL
(KEEP=PUPILS REVENUE PERCAP),
PUPILPCT = (PUPILSj&TOTPUPIL) *100,
CUMPCT+PUPILPCT,
IF 5 LT CUMPCT LE 95 THEN
OUTPUT RANGE 5 ,
IF CUMPCT LT 50 THEN OUTPUT BELOW,
ELSE OUTPUT ABOVE,
Data sets with subsets of all school districts
are created based on weighted percentiles. A
percentile is a value below which a specified
percentage of the school districts fall. A
weighted percentile is a value below which a
specified percentage of the pupils fall.
Percentiles used in creation of these data
sets are the median or 50th percentile, and
the 5th and 95th percentiles.
DATA NULL ,
SET-RANGE5,
IF N =1 THEN
CALL SYMPUT('FIFTHPCT',PERCAP),
Data set RANGE5 includes only the
observations between the 5th and 95th
percentiles based on number of pupils. The
first observation output to data set RANGE5
is the school district in which the 5th
percentile falls; the last observation output
is the school district in which the 95th
percentile falls.
DATA NULL,
SET-BELOW END=EOF,
IF EOF=l THEN
CALL SYMPUT('BELOWPCT',CUMPCT),
DATA MIDDLE,
SET ABOVE,
IF N =1,
SPLIT~(50-&BELOWPCT)jPUPILPCT,
PUPILS=PUPILS*SPLIT,
REVENUE=REVENUE*SPLIT,
CALL SYMPUT('MEDIAN',PERCAP),
Data set MEDIAN includes all pupils falling
below the median per-pupil revenue. The
first observation output to data set ABOVE is
the school district in which the median falls.
The proportion of pupils and corresponding
revenues in this school district that fall
below the 50th percentile is computed. This
observation is combined with the school
districts falling below the 50th percentile
(BELOW) to create a complete data set of
pupils that fall below the median.
DATA MEDIAN,
SET BELOW MIDDLE,
DATA RNGRATIO(KEEP=FIFTHPCT NINE5PCT
RESRANGE FEDRATIO),
SET RANGE5 END=EOF,
IF EOF=l THEN DO,
FIFTHPCT=&FIFTHPCT,
NINE5PCT=PERCAP,
RESRANGE=NINE5PCT-FIFTHPCT,
FEDRATIO=RESRANGE/FIFTHPCT,
OUTPUT,
END;
ELSE DELETE,
LABEL FIFTHPCT='5TH PERCENTILE'
NINE5PCT='95TH PERCENTILE'
RESRANGE='RESTRICTED RANGE'
FEDRATIO='FEDERAL RANGE RATIO',
The restricted range and federal range ratio
are measures based on the per-pupil revenues
at the 5th and 95th percentiles. The
restricted range is the difference between
the per-pupil revenue at or above which five
percent of the pupils fall and the per-pupil
revenue at or below which five percent of the
pupils fall. The federal range ratio is the
restricted range divided by the per-pupil
revenue at the 5th percentile.
Restricted range
Federal range ratio
DATA MCALC
(KEEP=MEDIAN MCLOONE MBURDEN),
SET MEDIAN END=EOF,
BELOWPUP+PUPILS,
BELOWREV+REVENUE,
IF EOF=l THEN DO,
MEDIAN=&MEDIAN,
MCLOONE=BELOWREV/(BELOWPUP*MEDIAN),
MBURDEN=(MEDIAN*(l-MCLOONE))/&MEAN,
OUTPUT,
END;
ELSE DELETE,
LABEL MEDIAN='MEDIAN REVENUE'
MCLOONE='MCLOONE INDEX'
MBURDEN='RELATIVE BURDEN',
Xg 5- X5
X95- X5! X5
The Mcloone index is the weighted average
per-pupil revenue of school districts below
the median, as a proportion of the median. A
measure of relative burden is represented by
the proportion of total revenue of all school
districts necessary to raise the per-pupil
revenue of school districts below the median
to the median.
803
Median M w = Xi
at 50th percentile of pupils
Relative burden of revenue gap of lower half
of distribution
[Z.i=1 :MWi(Mw- Xiljl Z.WiXi or
ACKNOWLEDGMENTS
The author would like to acknowledge the
contributions of Charles Z. Aki, Deborah
Verstegen, and Joseph Wisnoski, who helped
to develop the concepts presented in this
paper.
REFERENCES
SAS is a registered trademark of SAS
Institute Inc., Cary, NC, USA.
Atkinson, A.B. The Economics of Ineguality.
2nd ed. Oxford: Clarendon Press, 1983.
Berne, Robert and Leanna Steifel. The
Measurement of Eguity in School
Finance: Conceptual. Methodological
and Empirical Dimensions. Baltimore:
Johns Hopkins University Press, 1984.
SAS Institute Inc. SAS User's Guide: Basics,
Version 5 Edition. Cary, NC: SAS
Institute Inc., 1985.
SAS Institute Inc. SAS User's Guide:
Statistics, 1982 Edition. Cary, NC: SAS
I nstitute Inc., 1982.
Sen, Amartya. Poverty and Famines: An Essay
on Entitlement and Deprivation. Oxford:
Clarendon Press, 1981 ...
Theil, Henri. Statistical Decomposition
Analysis with Applications in the
Social and Administrative Sciences.
Studies in Mathematical and Managerial
Economics, Vol. 14. Amsterdam: NorthHolland Publishing Company, 1972.
804



![afl_mat[1]](http://s2.studylib.net/store/data/005387843_1-8371eaaba182de7da429cb4369cd28fc-300x300.png)