ST102/Elementary Statistical Theory
advertisement

Examiners’ commentaries 2015
Examiners’ commentary 2015
ST102 Elementary Statistical Theory
General remarks
Learning outcomes
By the end of this module you should:
• be able to summarise the ideas of randomness and variability, and the way in which these link to
probability theory to allow the systematic and logical collection of statistical techniques of great
practical importance in many applied areas
• be competent users of standard statistical operators and be familiar with a variety of well-known
distributions and their moments
• understand the fundamentals of statistical inference and be able to apply these principles to
choose an appropriate model and test in a number of different settings
• recognise that statistical techniques are based on assumptions and in the analysis of real
problems the plausibility of these assumptions must be thoroughly checked.
Examination structure
You have three hours to complete this paper, which is in two parts: Sections A and B. Answer both
questions from Section A, and three questions from Section B. All questions carry equal marks.
Candidates who submit answers to more than three Section B questions will only have their best 3
answers count towards the final mark. All questions are given equal weight, and carry 20 marks.
What are the Examiners looking for?
The Examiners are looking for you to demonstrate command of the course material. Although the
final solution is ‘desirable’, the Examiners are more interested in how you approach each solution, as
such, most marks are awarded for the ‘method steps’. They want to be sure that you:
• have covered the syllabus
• know the various definitions and concepts covered throughout the year and can apply them as
appropriate to examination questions
• understand and answer the questions set.
You are not expected to write long essays where explanations or descriptions are required, and
note-form answers are acceptable. However, clear and accurate language, both mathematical and
written, is expected and marked.
1
ST102 Elementary Statistical Theory
Key steps to improvement
The most important thing you can do is answer the question set! This may sound very simple, but
these are some of the things that candidates did not do. Remember:
• Always show your working. The bulk of the marks are awarded for your approach, rather
than the final answer.
• Write legibly!
• Keep solutions to the same question in one place. Avoid scattering your solutions
randomly throughout the answer booklet — the Examiners will not appreciate having to spend a
lot of time searching for different elements of your solutions.
• Where appropriate, underline your final answer.
• Do not waste time calculating things which are not required by the Examiners!
Using the commentary
We hope that you find the commentary useful. For each question and subquestion, it gives:
• the answers, or keys to the answers, which the Examiners were looking for
• common mistakes, as identified by the Examiners.
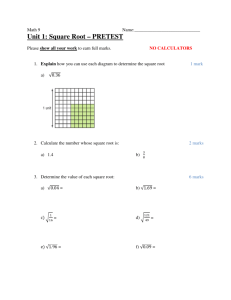
Student performance by question
Question #
1
2
3
4
5
6
7
Number of
attempts
621
613
507
553
342
476
319
Mean Score
Std. deviation
9.93
12.32
10.15
13.39
7.75
13.53
11.00
3.71
5.80
6.53
3.87
3.85
5.68
5.87
10
0
5
Marks
15
20
Boxplots of student performance by question
Q1
Q2
Q3
Dr James Abdey, ST102 Lecturer, July 2015
2
Q4
Q5
Q6
Q7
Examiners’ commentaries 2015
Examiners’ commentary 2015
ST102 Elementary Statistical Theory
Specific comments on questions
Section A
Question 1
(a) Feedback on this question:
Most candidates performed strongly on this part of the question. However, some had difficulty
forming the correct distributions of Y and D in (i.) and (ii.) below. In (iv.), a common error was
determining the correct sample space and associated probabilities. Follow through marks were
awarded in (v.) as appropriate.
Full solutions are:
Let Xi ∼ N (150, 100) be the amount of coffee in cup i, and let Z ∼ N (0, 1).
i. By independence of the Xi s, then Y =
5
P
Xi ∼ N (750, 500). Hence:
i=1
P (Y > 700) = P
700 − 750
Z> √
500
= P (Z > −2.24) = 0.98745.
(3 marks)
ii. Let D = Xi − Xj for i 6= j, then D ∼ N (0, 200). Hence:
20 − 0
20 − 0
√
√
P (−20 < D < 20) = P −
<Z<
= P (−1.41 < Z < 1.41) = 0.8414.
200
200
(3 marks)
iii. We have:
P (Xi < 137) = P
Z<
137 − 150
√
100
= P (Z < −1.30) = 0.0968.
(1 mark)
iv. There are two possible outcomes: no income from cup i with probability 0.0968, and £1
income with probability 1 − 0.0968 = 0.9032. Therefore, the expected income from cup i is:
0 × 0.0968 + 1 × 0.9032 = £0.9032 ≈ £0.90.
(3 marks)
v. Let N denote the number of cups with coffee below 137 ml among the 5 cups purchased,
then N ∼ Bin(5, 0.0968). Hence:
P (N ≥ 1) = 1 − P (N = 0) = 1 − (0.9032)5 = 0.3989.
(3 marks)
3
ST102 Elementary Statistical Theory
(b) Feedback on this question:
This question was meant to be deliberately challenging and aimed to assess a candidate’s ability
to approach an unseen question through thinking. Indeed, the subject matter of a question
should be of great interest to all taking the course due to the graduate selection theme!
The probabilities for i = 1, 2 and n should have proved straightforward for all. The general
expression required a candidate to recognise that classical probability is appropriate.
Full solutions are:
Let:
πi = P (the best candidate is hired | the hiring occurs in the ith interview).
With n candidates, after i − 1 rejections there are n − (i − 1) = n − i + 1 remaining candidates.
Since candidates are selected for interview in a random order, for the best candidate to be hired
in the ith interview, s/he needs to be chosen from the remaining applicants which occurs with
probability:
1
.
πi =
n−i+1
Hence:
• πi = 1/n for i = 1
• πi = 1/(n − 1) for i = 2
• πi = 1/(n − k + 1) for i = k
• πi = 1 for i = n.
(7 marks)
4
Examiners’ commentaries 2015
Question 2
(a) Feedback on this question:
Overall candidates knew the concepts but algebraic mistakes were quite common. In (i.), errors
included:
• X1 = 1, X2 = 2, . . . , Xn = n
• mixing up the product of Xi s with the sum of Xi s
• algebraic manipulation to get the estimator, resulting in an expression in terms of X̄.
Full solutions are:
i. Since the Xi s are independent and identically distributed, the likelihood function is:
n √
P
n
Y
√
−θ
θn
θ
i=1
√ e−θ Xi =
L(θ) =
e
n
Q√
2
X
i
n
i=1
2
Xi
Xi
.
i=1
Hence the log-likelihood function is:
n p
n p
X
Y
l(θ) = ln L(θ) = n ln θ − θ
Xi − ln 2n
Xi
i=1
!
.
i=1
Differentiating with respect to θ, we obtain:
n
n Xp
dl(θ)
= −
Xi .
dθ
θ i=1
Equating to zero, we obtain the maximum likelihood estimator:
n
θb = P
n √
.
Xi
i=1
(8 marks)
b
ii. The maximum likelihood estimator of θ/2 is θ/2.
For the given data, the point estimate is:
θb =
√
2( 4.1 +
√
4
√
√
= 0.1953.
7.3 + 6.5 + 8.8)
(2 marks)
(b) Feedback on this question:
This question required material direct from the lectures. It was noticeable that many candidates
had memorised the bias, and some stated the result without proof.
Full solutions are:
i. Since σ 2 = µ2 − µ21 = E(X 2 ) − (E(X))2 , then:
n
σ
b2 = M2 − M12 =
n
1X 2
1X
Xi − X̄ 2 =
(Xi − X̄)2 .
n i=1
n i=1
(4 marks)
5
ST102 Elementary Statistical Theory
ii. We have:
E(b
σ2 )
=
E(X 2 ) − E(X̄ 2 )
=
σ 2 + µ2 −
=
n−1 2
σ .
n
σ2
+ µ2
n
The bias is E(b
σ 2 ) − σ 2 = −σ 2 /n.
(5 marks)
iii. The sample variance:
n
S2 =
1 X
(Xi − X̄)2
n − 1 i=1
is a more frequently-used estimator for σ 2 , due to it being an unbiased estimator, i.e.
E(S 2 ) = σ 2 .
(1 mark)
6
Examiners’ commentaries 2015
Section B
Question 3
(a) Feedback on this question:
In (i.), some candidates did not know the definition of the cdf, such as using a incorrect integral
interval and applied a discrete format and some calculations were incorrect. In (ii), some
candidates did not know the definition of expectation, with around half suffering calculation
problems.
Full solutions are:
i. We have:
Z
x
x
Z
f (t) dt =
−∞
k
α kα
dt = (−k α )
tα+1
α
=
(−k )(x
Therefore:
−α
(
F (x) =
−k
−α
Z
k
x
x
(−α) t−α−1 dt = (−k α ) t−α k
) = 1 − k α x−α = 1 − (k/x)α .
0
1 − (k/x)α
when x < k
when x ≥ k.
(5 marks)
ii. We have:
∞
Z
E(X)
=
x f (x) dx =
x f (x) dx
−∞
∞
Z
=
k
=
∞
Z
k
αk α
x · α+1 dx =
x
αk
α−1
∞
Z
|k
Z
∞
k
αk α
dx
xα
αk
(α − 1)k α−1
dx =
(α−1)+1
α−1
x
{z
}
(if α > 1).
=1
(7 marks)
(b) Feedback on this question:
The most frequent mistake made by candidates was being unable to split the integral into two
parts.
Full solutions are:
We have:
MX (t) = E(etX ) =
Z
∞
etx f (x) dx =
−∞
=
=
Z
∞
1
etx e−|x| dx
2
−∞
Z 0
Z ∞
1 (t+1)x
1 (t−1)x
e
dx +
e
dx
2
2
−∞
0
h
i0
h
i∞
1
1
e(t+1)x
+
e(t−1)x
2(t + 1)
2(t − 1)
−∞
0
=
−2
2(t + 1)(t − 1)
=
1
1 − t2
provided |t| < 1.
(8 marks)
7
ST102 Elementary Statistical Theory
Question 4
(a) Feedback on this question:
Candidates performed very well on this question, although the correct variance in (i.) and
degrees of freedom in (ii.) proved problematic for some. The values of k in the remaining parts
were generally free of errors.
Full solutions are:
i. ai Zi ∼ N (0, a2i ), hence:
5
X
a i Zi ∼ N
0,
i=1
5
X
!
a2i
.
4
i=1
ii. Zi2 ∼ χ21 , hence:
5
X
Zi2 ∼ χ25 .
i=1
2
iii. kZ1 + Z2 ∼ N (0, k + 1), hence:
P (kZ1 + Z2 ≤ 4) = P
Z≤√
k2 + 1
= 0.8413.
From tables, P (Z ≤ 1) = 0.8413, hence:
√
4
k2 + 1
=1
⇔
k=
√
15.
iv. X = Z12 + Z22 ∼ χ22 , hence:
P (X ≤ 7.378) = 0.975 = k.
v. V = Z12 + Z22 + Z32 ∼ χ23 and W = Z42 + Z52 ∼ χ22 . Therefore:
2k
V /3
≤
= 0.95.
P (V ≤ kW ) = P
W/2
3
From tables, P (F ≤ 19.2) = 0.95 where F ∼ F3, 2 , hence:
2k
= 19.2
3
⇔
k = 28.8.
(10 marks)
(b) Feedback on this question:
This was a fairly easy question making use of known properties of a probability function.
Full solutions are:
i. Let the other value be θ, then:
X
E(Y ) =
y P (Y = y) = (θ × 0.7) + (1 × 0.2) + (2 × 0.1) = 0
y
hence θ = −4/7.
ii. Var(Y ) = E(Y 2 ) − (E(Y ))2 = E(Y 2 ), since E(Y ) = 0. So:
!
2
X
4
2
2
Var(Y ) = E(Y ) =
y P (Y = y) =
−
× 0.7 + (12 × 0.2) + (22 × 0.1) = 0.8286.
7
y
(4 marks)
8
Examiners’ commentaries 2015
(c) Feedback on this question:
This proved the most challenging part of Question 4. The main difficulty seemed to be
understanding that a loss is simply a negative profit. The fact that the gambler bets on red 100
times means the sample size is sufficient to apply the central limit theorem.
Full solutions are:
We have:
E(X) = 5 × 18/38 + (−5) × 20/38 = −10/38 = −0.2632
and:
Var(X) = 25 × 18/38 + 25 × 20/38 − (−10/38)2 = 24.9308.
We require:
P
Y =
100
X
i=1
!
Xi > −50
≈P
−50 − 100(−0.2632)
Z> √
100 × 24.9308
= P (Z > −0.47) = 0.6808.
(6 marks)
9
ST102 Elementary Statistical Theory
Question 5
Feedback on this question:
Candidates usually score highly on questions involving discrete bivariate distributions, however
this year aggregate performance was below average. The original aspect of the question
concerned the use of a parameter θ in the table of joint probabilities, with the determination of
the parameter space required in (a). Of course, joint probabilities must be non-negative and
cannot exceed 1, so this needed to be recognised to determine the range of θ. Part (b) was
generally done well. Part (c) required some thought, but candidates needed to remember that an
estimator must be a statistic, i.e. a known function of the data – here Y and X for the two
estimators, respectively. Part (d) attempts were generally fine, while (e) required consideration of
the range of θ derived in (a).
Full solutions are:
(a) All values in the table should be in [0, 1] which is equivalent to θ ∈ [−0.1, 1/30].
(3 marks)
(b) For X:
−1
0.3 + 3θ
X=x
P (X = x)
0
0.4 − 6θ
1
0.3 + 3θ
We have:
E(X) = −0.3 − 3θ + 0.3 + 3θ = 0.
For Y :
Y =y
P (Y = y)
−1
0.5 + 4θ
0
0.3 − 5θ
1
0.2 + θ
We have:
E(Y ) = −0.5 − 4θ + 0.2 + θ = −0.3 − 3θ.
(4 marks)
(c) Since E(Y ) = −0.3 − 3θ, an unbiased estimator for θ based on Y is:
b ) = −0.1 − Y .
θ(Y
3
Since E(X) = 0, we need to consider |X| in order to obtain an estimator as a function of X. An
unbiased estimator would be:
|X|
b
θ(X)
= −0.1 +
.
6
(5 marks)
(d) Since E(X) = 0, it holds that:
Cov(U, X) = E(U X) − E(U ) E(X) = E(U X).
As X and Y take values in {−1, 0, 1}, the random variable U X has values in {−1, 0, 1} as well.
We have:
P (U X = 1)
= P (X = 1, U = 1) + P (X = −1, U = −1)
=
P (X = 1, Y = 1) + P (X = −1)
=
0.3 + 3θ
and:
P (U X = −1) = P (X = 1, U = −1) = P (X = 1, Y = −1) = 0.3 + 3θ.
It follows that E(U X) = 0, hence Cov(U, X) = 0.
(4 marks)
10
Examiners’ commentaries 2015
(e) The fact that Cov(U, X) = 0 is only sufficient to show that U and X are uncorrelated, not that
they are independent.
U and X and independent only when θ = −0.1.
When θ = −0.1, we have that P (X = 0) = 1 from which it readily follows that X and U are
independent.
When θ 6= −0.1, then P (U = 0, X = −1) = 0, however:
P (U = 0) P (X = −1) = (0.3 − 6θ)(0.3 + 3θ) 6= 0
since θ ≤ 1/30.
One could also argue that since U = min(X, Y ), then U is a function of X so they cannot be
independent. This would be correct if we were sure that X cannot be a constant, as is the case
when θ 6= −0.1.
(4 marks)
11
ST102 Elementary Statistical Theory
Question 6
(a) Feedback on this question:
Many candidates mixed up the F and t distributions, stating that the t distribution had a pair of
degrees of freedom.
Full solutions are:
2
2
X̄, Ȳ , SX
and SY2 are independent. X̄ ∼ N (µX , σX
/n), Ȳ ∼ N (µY , σY2 /m),
2
2
2
2
2
2
(n − 1)SX /σX ∼ χn−1 and (m − 1)SY /σY ∼ χm−1 .
2
Let σX
= σY2 = σ 2 . Hence X̄ − Ȳ ∼ N µX − µY , σ 2 (1/n + 1/m) and:
2
(n − 1)SX
+ (m − 1)SY2
∼ χ2n+m−2 .
σ2
We have:
X̄ − Ȳ − (µX − µY )
p
σ 2 (1/n + 1/m)
p
((n −
s
n+m−2
X̄ − Ȳ − δ0
·p
∼ tn+m−2 .
2 + (m − 1)S 2
1/n + 1/m
(n − 1)SX
Y
=
2
1)SX
+ (m −
1)SY2
)/σ 2 ) /(n + m − 2)
The tn+m−2 distribution arises due to the divison of a standard normal random variable by the
square root of an independent chi-squared random variable divided by its degrees of freedom.
(10 marks)
(b) Feedback on this question:
This question was generally done well, although common errors included using the test statistic
in (a) and using the t table to look up critical values.
Full solutions are:
We test H0 : σ12 = σ22 vs. H1 : σ12 6= σ22 . Under H0 , the test statistic is:
T =
S12
∼ Fn−1, m−1 = F7, 8 .
S22
Critical values are F0.975, 7, 8 = 1/F0.025, 8, 7 = 1/4.90 = 0.20 and F0.025, 7, 8 = 4.53. The test
statistic value is:
21.2/7
= 0.8130
29.8/8
and since 0.20 < 0.8130 < 4.53 we do not reject H0 , which means there is no evidence of a
difference in the variances.
(7 marks)
(c) Feedback on this question:
This required a standard definition of the p-value, although some candidates thought the p-value
is used to calculate critical values.
Full solutions are:
A p-value is a measure of the discrepancy between the hypothesised (claimed) value for θ and the
observed/estimated value. It is the probability of observing the test statistic value, t, or more
extreme values under the null hypothesis. It is compared to a significance level in order to decide
whether or not to reject the null hypothesis.
(3 marks)
12
Examiners’ commentaries 2015
Question 7
(a) Feedback on this question:
Around a third of candidates who attempted this question got the wrong answer when taking the
first-order derivative.
Full solutions are:
We have:
n
X
S=
(yi − βxi )2
i=1
and:
n
X
dS
= −2
xi (yi − βxi ).
dβ
i=1
Setting the first derivative to zero and solving, we obtain:
n
P
xi yi
i=1
b
.
β= P
n
x2i
i=1
Since:
P
n
xi yi
b = E i=1
E(β)
n
P
i=1
x2i
P
n
xi (βxi + εi )
= E i=1
n
P
i=1
x2i
n
P
=β+
i=1
xi E(εi )
n
P
i=1
=β
x2i
then βb is an unbiased estimator for β.
(5 marks)
(b) Feedback on this question:
In (i.), many struggled to derive the proof which, as can be seen below, is fairly short. Part (ii.)
was much better attempted
due to the provision of the formula sheet. In (iii.), many got the
P
wrong answer for i (xi − x)2 , although method marks were awarded as appropriate.
Full solutions are:
i. Since:
ybi = βb0 + βb1 xi = ȳ + βb1 (xi − x̄)
then:
ybi − ȳ = βb1 (xi − x̄).
The required identity follows from this immediately.
(4 marks)
ii. We have:
βb1
=
8.39 + 1.06 × 13.14/12
= 0.6823
14.09 − (−1.06)2 /12
βb0
=
13.14 + 1.06 × 0.6823
= 1.1553
12
σ
b2
=
(27.80 − 13.14 × 13.14/12) − (0.6823)2 (14.09 − 1.06 × 1.06/12)
= 0.6896.
10
Note (i.) is the regression sum of squares, hence subtracting from the total sum of squares
gives the residual sum of squares to obtain σ
b2 .
(6 marks)
13
ST102 Elementary Statistical Theory
iii. For x = 0.5, we have:
µ
b(x) = 1.1553 + 0.6823 × 0.5 = 1.4965.
Also:
X
(xi − x)2
=
i
and
P
i (xi
X
(xi − x̄)2 + n(x̄ − x)2
i
=
(14.09 − 1.06 × 1.06/12) + 12 × (1.06/12 − 0.5)2
=
16.03
− x̄)2 = 13.9964. Since t0.025, 10 = 2.228, a 95% confidence interval for µ(x) is:
µ
b(x) ± t0.025, 10 · σ
b·
!1/2
P
2
(x
−
x)
i
Pi
n j (xj − x̄)2
r
=
1.4965 ± 2.228 × 0.6896 ×
=
1.4965 ± 0.4747
=
(1.02, 1.97).
16.03
12 × 13.9964
(5 marks)
14