Math 15: Elementary Statistics Elementary Linear Regression
advertisement

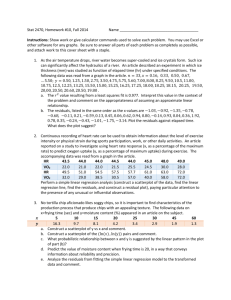
Math 15: Elementary Statistics Elementary Linear Regression Modeling Following are the high school GPAs and the college GPAs at the end of the freshman year for 10 different students: Student High School GPA College GPA 1 2.7 2 3.1 3 2.1 4 3.2 5 2.4 6 3.4 7 2.6 8 2.0 9 3.1 10 2.5 2.2 2.8 2.4 3.8 1.9 3.5 3.1 1.4 3.4 2.5 We can use a TI-83plus to draw the following scatterplot of the data using High School GPA as the independent variable and College GPA as the dependent variable as follows: The college GPA is the response variable and corresponds to the vertical axis. It appears that the college GPA increases as the high school GPA increases. Thus, we expect the correlation coefficient for be positive. Furthermore, the data appear to cluster along a strait line. It seems reasonable to use linear regression to find the equation of the best-fit line. To test the significance of the model we use the LinRegTTest to test the hypothesis: H0: β = 0 Η1: β > 0 Here is the procedure: Notice that the p-value (p = 0.001) is small indicating that the null hypothesis of no relationship should be rejected and that there is a statistically significant linear relationship between high school GPA and college GPA. The equation of the best-fit line is yˆ = "0.950 + 1.347x and r = 0.844 indicating a fairly strong positive correlation. Furthermore, r2 = 0.71 indicating that approximately 71% of the variation in the predicted college GPA is explained by high school!GPA using a linear model. We can use this equation to compute a predicted y for each value of x and then calculate the error of the prediction as follows. Thus, e1 = y1 " yˆ1 = 1.4 "1.7436 = "0.3436 e2 = y2 " yˆ2 = 2.4 "1.8783 = .5217 . . . ei = yi " yˆi Definition of a Residual: ! From the data point (xi , yi ) the observed value of y is yi and the predicted value of y is obtained from the equation yˆi = a + bxi ! ! ! The error of the prediction, called the residual, is the difference in the actual yi and the predicted yˆi . The residual associated with the data point (xi , yi ) is ! ei = yi " yˆi ! An important and useful tool for determining the appropriateness of a model is a plot of ! the residuals against the predictor variable. In this example we plot the residuals against the predictor variable high school GPA. The TI-83plus automatically stores the residuals !in a list named “”RESID.” Thus we can plot the residuals as from a regression analysis follows: Notice that the residuals oscillate in a somewhat random pattern about the horizontal line at residual = 0. This pattern is typical of data that do not deviate substantially from the model under study. It appears that the line has explained most of the trend in these data. Another Example: The moisture content of marine muds that accumulate in small inlets on the Gulf Coast is of interest to geologists in eastern Louisiana. The following measurements of the moisture contents of core samples were obtained by comparing the weight of a sample immediately after its removal from the core barrel with its weight after forced drying. The moisture content is expressed as grams of water per 100 grams of dried sediment. We wish to relate the moisture content to the depth, in meters, of the core sample. Depth Moisture 0 124 5 78 10 54 15 35 20 30 25 21 30 22 35 18 We begin our analysis by drawing a scatterplot of the data: Next we use the TI-83plus to perform a linear regression analysis in this data: The p-value (p = 0.001) is small indicating a statistically significant linear relationship between the depth and moisture content. The correlation coefficient r = -0.891 indicates a fairly strong negative linear correlation, and r2 = 0.79 indicates that approximately 79% of the variation in moisture is explained by depth using a linear model. At this point, the linear model seems appropriate. Let’s plot the residuals against depth. It is clear that the pattern of the residuals in this plot is not random. The pattern being displayed in this plot is known as curvilinear. Often the scatterplot will reveal such nonlinear relationships, but if one overlooks the pattern in the scatterplot and continues to fit a line to the data, the resulting residual plot will magnify the pattern and, as in this case, suggest that the linear model is an inadequate model. Closer examination of the original scatterplot for this data reveals a decaying exponential pattern suggesting an exponential model might create a better fit for this data. The traditional method for fitting an exponential model to data is to take the natural logarithm of the response, y, data. This transformation is referred to as a linearization of the data. Notice that if y = be ax then ! and since ln(y) = ln(be ax ) ln(y) = ln(b) + ln(e ax ) ln(b) is just some constant and ln(e ax ) = ax , we can write ! ln(y) = b0 + ax ! can take the natural logarithm of the moisture list and store these values in a list ! ! We named “LNMST” as follows: ! Now we will draw a new scatterplot using the linearized moisture data. Now we use the TI-83plus to conduct a linear regression analysis on this linearized data. Notice the improvement in the p-value, r and r2 values. The pattern in the residuals is also reduced in the scatterplot below. The exponential form of the equation can be found as follows: ! ln(y) = 4.59 " 0.054 x y = e 4.59"0.054 x y = e 4.59e"0.054 x y = 98.5e"0.054 x ! Here is a scatterplot of the data with the exponential model. ! ! Activity: Windmill Outputs Joglekar et. al. (1989) considered the following windmill data that record the direct current (in volts) produced by given wind velocities (in miles per hour): Velocity (MPH) Output (volts) Perform a linear regression analysis on this 2.45 .123 data. Be sure to include the p-value, r, r2 2.70 .500 and do not forget to include a residual plot. 2.90 .653 If there is a pattern in the residuals, suggest 3.05 .558 a nonlinear model that might fit better. 3.40 1.057 3.60 1.137 3.95 1.144 4.10 1.194 4.60 1.562 5.00 1.582 5.45 1.501 5.80 1.737 6.00 1.822 6.20 1.866 6.35 1.930 7.00 1.800 7.40 2.088 7.85 2.179 8.15 2.166 8.80 2.112 9.10 2.303 9.55 2.294 9.70 2.386 10.00 2.236 10.20 2.310