Help Sheet for reading SPSS printouts

SPSS Help 1
Help Sheet for Reading SPSS Printouts
Heather Walen-Frederick, Ph.D.
This document will give you annotated SPSS output for the following statistics:
1. Correlation
2. Regression
3. Paired Samples t-test
4. Independent Samples t-test
5. ANOVA
6. Chi Square
Note that the version of SPSS used for this handout was 13.0
(Basic). Therefore, if you have advanced add-ons, or a more recent version there may be some slight differences, but the bulk should be the same.
One possible difference would be for later versions or advanced packages to give the option of things like effect size, etc. In addition, the data used for these printouts were based on data available in the text:
Statistics for the Behavioral Sciences, 4 th Edition (Jaccard & Becker, 2002).
This guide is meant to be a help; it should not replace reading the text, your class notes, the APA manual or simply using your head. If you have trouble with data entry, or other items not addressed in this guide, please try using the SPSS help that comes with the program (when i n SPSS, go under the “help” tab and click on “topics”; you may be surprised at how “user friendly” SPSS help really is). At the end of this document is a guide to assist you in picking the most appropriate statistical test for your data.
Note: No test should be conducted without FIRST doing exploratory data analysis and confirming that the statistical analysis would yield valid results. That is, check that the assumptions for each test are met, or that the test is robust against violation(s). Please do thorough exploratory data analysis, to check for outliers, missing data, coding errors, etc. Remember: Garbage in, garbage out!
A note about statistical significance (what it means/does not mean).
Most everyone appreciates a “refresher” on this topic.
Statistical Significance: An observed effect that is large enough we do not think we got it on accident
(that is, we do not think that the result we got was due to chance alone).
How do we decide if something is statistically significant?
If H
0 is true, the p -value (probability value) is the probability that the observed outcome (or a value more extreme than what we observe) would happen. The p -value is a value we obtain after calculating a test statistic. The smaller the p -value, the stronger the evidence against the H
0.
If we set alpha at .05, then the p -value must be smaller than this to be considered statistically significant; if we set alpha at .01, then it must be smaller than .01 to be considered statistically significant. Remember, the p -value tells us the probability we would expect our result (or one more extreme) GIVEN the null is true. If our p-value is less than alpha, we REJECT THE NULL and say there appears to be a difference between groups/a relationship between variables, etc.
Conventional alpha (
) levels p < .05 and p < .01
What do these mean? p < .05 = this result would happen no more than 5% of the time (so 1 time in 20 samples), if the null were true . p < .01 = this result would happen no more than 1% of the time (so 1 time in 100 samples), if the null were true .
SPSS Help 2
Because these are low probabilities (events not likely to happen if the null were true), we reject the null when our calculated p-value falls below these alpha levels.
What if your p-value is close to alpha, but slightly over it (like .056)? You cannot reject the null.
However, you can state that it is “marginally” significant. You will want to look at your effect size to determine the strength of the relationship and also your sample size. Often, a moderate to large effect will not be statistically significant if the sample size is low (low power). In this case, it suggests further research with a larger sample.
Please remember that statistical significance does not equal importance. You will always want to calculate a measure of effect size to determine the strength of the relationship. Another thing to keep in mind is that the effect size, and how important it is, is somewhat subjective and can vary depending on the study at hand.
1. Correlation
A correlation tells you how and to what extent two variables are linearly related. Use this technique when you have two variables (measured on the same person) that are quantitative in nature and measured on a level that at least approximates interval characteristics. When conducting a correlation, be sure to look at your data, including scatterplots, to make sure assumptions are met (for correlation, outliers can be a concern).
This example is from Chapter 14 (problem #49). The question was whether there was a relationship between the amount of time it took to complete a test and the test score. Do people who take longer get better scores, maybe due to re-checking questions and taking their time (positive correlation), or do people who finish sooner do better possibly because they are more prepared (negative correlation)?
This is the default output.
This box gives the results.
Correl ations sc ore Pearson Correlation
Sig. (2-tailed) sc ore
1 time
.083
.745
Correlation p -value time
N
Pearson Correlation
Sig. (2-tailed)
18
.083
.745
18
1
N 18 18
You see the correlation in the last column, first row: .083. Clearly, this is a small correlation (remember they range from 0-1 and this is almost 0). The pvalue (in the row below this) is .745. This is consistent with the correlation. This is nowhere near either alpha (.05 or .01); in other words, because the p -value
EXCEEDS alpha, it is not statistically significant. Thus we fail to reject the null, and conclude that the time someone takes to complete a test is not related to the score they will receive.
The write up would look like this: r (18) = .08, p > .05 (if you were using an alpha of .01, it would read: r (18) = .08, p > .01. Alternatively, you could write: r (18) = .08, p = .75 (the difference is that in the last example, you are reporting the actual p -value, rather than just stating that the p -value was greater than alpha).
SPSS Help 3
2. Regression
A regression is typically used to predict a DV with an IV (or multiple IVs). It is a procedure that is closely related to correlation (as such, look at your data before performing a regression, paying particular attention to outliers).
This regression is based on problem #50, Chapter 14. The researchers were interested in whether a person’s GRE score was related to GPA in graduate school (after the first two years). Whether or not there is a relationship could be answered by a correlation. However, the researchers would like to be able to predict GPA for in-coming graduate students using their GRE scores. Also, remember that typically researchers perform multiple regressions. These are regression with multiple predictor variables used to predict the DV; this is much more complex than a simple regression and questions answered by such a technique could not be answered by a correlation.
The output below is the default for this analysis.
This box is telling you that GRE was entered to predict GPA (this box is meaningless for this example, but would be important if you were using multiple predictor (X) variables and using a method of entering these into the equation that was not the default).
Variables Entered/Removed b
Model
1
Variables
Entered
GRE a
Variables
Removed Method
.
Enter a. All requested variables entered.
b. Dependent Variable: GPA
This box gives you summary statistics.
Model Summary
Model
1
R
.751
a
R Square
.564
Adjusted
R Square
.509
Std. Error of the Estimate
.25070
a. Predictors: (Constant), GRE
Reading across, the second box tells you the correlation (.75 – a strong, positive, linear relationship). The next box gives you a measure of effect R 2 : 56% of the variance in GPA is accounted for by GRE scores
(this is a strong effect!). Adjusted R 2 adjusts for the fact that you are using a sample to make inferences about a population; some people report R 2 and some report the adjusted R 2 . You then see the standard error of the estimate (think of this as the standard deviation around the regression line).
This box gives you the results of the regression. The F is significant at .05, but not .01.
ANOV A b
Model
1 Regres sion
Residual
Sum of
Squares
.650
.503
Total 1.153
a.
Predic tors: (Constant), GRE b. Dependent Variable: GP A df
1
8
9
Mean S quare
.650
.063
F
10.343
Sig.
.012
a
SPSS Help 4
A write up would look like: A regression analysis, predicting GPA scores from GRE scores, was statistically significant, F (1,8) = 10.34, p < .05 (or: F (1,8) = 10.34, p = .012). You would want to report your R 2 , explain it and if the analysis was performed to be used for actual prediction, you would want to add the regression equation (see below) and something like: For every one unit increase in GRE score, there is a corresponding increase in GPA of .005.
This box gives you the coefficients related to a regression.
Model
1 (Const ant)
GRE
Unstandardized
Coeffic ients
B
.411
.005
St d. E rror
.907
.002
St andardiz ed
Coeffic ients
Beta t
.453
3.216
Sig.
.662
.012
.751
a. Dependent Variable: GP A
You can see that the t values associated with GRE is significant at the same level the F statistics was
(this will happen if you have only 1 X variable). The regression equation is: Ŷ = .411 * .005X.
3. Paired Samples t-test
A paired-samples, or matched-pairs, t -test is appropriate when you have two means to compare. It is different from an independent samples t -test in that the scores are related in some way (like from the same person, a couple, a family, etc.). Do not forget to check that assumptions for a valid test are met before performing this analysis.
The output shown here is the default.
This example based on an example from Chapter 11 (problem #8). In this study, 5 participants were exposed to both a noisy and a quiet condition (this is the IV) and given a learning test (this is the DV). The question is whether learning differs in the two conditions; is there a statistically significant difference in the means for the noisy and quiet condition?
The first box gives you means, standard deviations, and the N .
Paired Samples Statistics
Pair
1 quiet noisy
Mean
12.6000
8.4000
N
5
5
Std. Deviation
6.42651
4.97996
Std. Error
Mean
2.87402
2.22711
This box next gives you the correlation between quiet and noisy.
Pa ired Sa mpl es Correlations
N Correlation Sig.
Pair 1 quiet & noisy 5 .928
.023
Typically, if you are conducting a t -test, you will not report these results. Nevertheless, because they are here, I will interpret them for you. There is a significant correlation (relationship) between the quiet and noisy conditions (the null is rejected). That is, if you scored high on one condition, you scored high on the other (this makes sense because it is the same person in both conditions). It is statistically significant at an alpha of .05, because when you look at the last box labeled “Sig.” the number there is .023 (this is the
SPSS Help 5 p -value). This is below (less than) an alpha of .05 (if you happened to be using a more conservative alpha such as .01, this result would not be statistically significant and you would retain the null).
The write up would be: r (5) = .93, p < .05. (or: r (5) = .97, p = .023). Using an alpha of .05 you would conclude there is a relationship between the conditions, which we would expect because it is the same people in each condition (again, this is not typically reported, because the question we want the answer to: are there differences in the conditions? This is not answered by this output).
This next box gives you the results of your t -test.
Pa ired Sa mpl es Test
Paired Differenc es
95% Confidenc e
Int erval of t he
Difference
Mean St d. Deviat ion
St d. E rror
Mean Lower Upper t df Sig. (2-tailed)
Pair 1 quiet - nois y 4.20000
2.58844
1.15758
.98603
7.41397
3.628
4 .022
It is statistically significant if you are using an alpha of .05, because the p -value in the last box is .022
(which is less than .05). Again, this is a great example, because if you were using an alpha of .01, it would NOT BE statistically significant (because .02 is greater than .01). Let us assume we are using an alpha of .05. We would declare the result statistically significant and reject the null.
A write up of this would look something like: t (4) = 3.77, p < .05. Again, you could write: t (4) = 3.77, p =
.02. You would want to go on to report the means and standard deviations as well as a measure of effect
(eta 2 ), which you would have to calculate by hand (NOTE: there is a way to get this on SPSS. You would need to run the test as a repeated measures ANOVA and click on effect size in the option box.
Introducing this analysis is beyond the scope of this guide, however, feel free to use SPSS help and experiment with this for yourself). Eta 2 = t 2 /(t 2 + DF) [for this example: 3.628
2 /(3.628
2 + 4) = .77]. This means 77% of the variability in the DV (test scores) is due to the IV (condition); this is a large effect! You could also report the 95% confidence interval (.99 – 7.41). This interval is giving you a range of test score differences; we know there is a difference in the test scores based on condition. How big is the difference between the mean scores? Our best guess is somewhere between about 1 point (.99) and 7 ½ points
(7.41).
4. Independent Samples t-test
An independent samples t -test is like a paired samples t -test, in that there are two means to compare. It is different in that the means are not related (for example, means from a treatment and control group). Do not forget to check that assumptions for a valid test are met before performing this analysis.
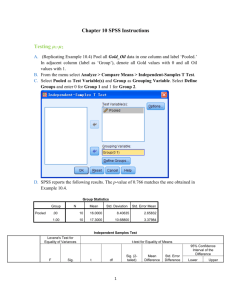
This example is based on problem #57 in Chapter 10. Briefly, the study was interested in whether choice influenced creativity in a task. The researchers randomly assigned children (2 – 6 years of age) to one of two groups: choice or no choice. They then had the children make collages and had the collages rated for creativity. In the “choice” condition, children got to choose 5 boxes (out of 10) containing collage materials. In the “no choice” condition, the experimenters chose the 5 boxes for the children. Creativity ratings (given by 8 trained artists) could range from 0 – 320.
The output below is the default output.
This first box shows you the N, the mean, standard deviation, and standard error of the mean for each condition.
SPSS Help 6
Group Statistics creative condition choice
N Mean
14 188.7857
Std. Deviation
16.32449
Std. Error
Mean
4.36290
no choice 16 142.0625
13.89709
3.47427
This next box gives you the results of your t -test . The first column that you come to is labeled “Levene’s
Test for Equality of Variances.” This tests the assumption that the variances for the two groups are equal.
You want this to be non significant (because you want there to be no difference in the variances between the groups – this is an assumption for an independent samples t-test). To determine if it is significant, you look in the column labeled “Sig.” In this example, the p -value is .165 (this is not less than either alpha, so it is non significant). This means we can use the row of data labeled “Equal variances assumed” and we can ignore the second row (“Equal variances not assumed”). If Levene’s test WAS significant, then we would use the second row (“Equal Variances not Assumed”), and ignore the first row. The p -value is in the box labeled “Sig. (2-tailed)” and is .000; thus we reject the null (this is less than either alpha).
The write up would be: t (28) = 8.47, p < .05 (or: t (28) = 8.47, p < .001 - round the p -value, because you would never report a p = .000). There is a difference in the creativity between the groups. You would want to report the means and standard deviations for both groups and a measure of effect size (calculate this like above in the paired-samples example). The rest of the information in the box gives you the mean difference (the groups differed on creativity scores by about 47 points), and also the 95% CI (which you may also want to report).
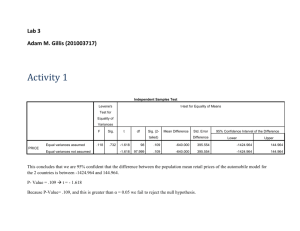
Independent Samples Test creative Equal variances as sumed
Equal variances not ass umed
Levene's Test for
Equality of Variances
F
2.032
Sig.
.165
t
8.470
8.377
df
28
25.743
t-test for Equality of Means
Sig. (2-tailed)
.000
Mean
Difference
46.72321
Std. Error
Difference
95% Confidence
Interval of the
Difference
Lower Upper
5.51608
35.42404
58.02239
.000
46.72321
5.57723
35.25349
58.19294
5. One-way Analysis of Variance (ANOVA)
An ANOVA is the analysis to use when you have more than two means to compare (it is like the independent samples t-test, but when you have more than two groups). Do not forget to check that assumptions for a valid test are met before performing this analysis.
This analysis is based on the example in Chapter 12 (problem #53). Briefly, the study was designed to examine whether a participant would give more shocks to a more “aggressive” learner. There were four conditions (4 levels of the IV): non-insulting, mildly insulting, moderately insulting and highly insulting. An
ANOVA is appropriate because there are more than two means being compared (in this case, there are four). Each participant was in one condition only (thus, the design is between-subjects; had the same person been in all conditions, you would have a within-subjects design and need to perform a repeated measures ANOVA – this is not covered in Stats. I).
The output below is what you get when asking SPSS for a oneway ANOVA under the “compare means” heading. You will get something different if you do an ANOVA using the univariate command under the heading “General Linear Model.” (NOTE: using the univariate command will give you the option of
SPSS Help 7 selecting effect size, however, the printout is more complicated and beyond the scope of this guide.
Again, feel free to experiment with this.).
The output below is not the default . In order to get this output, when you are setting up the ANOVA (under compare means, oneway ANOVA) you need to click on “Post Hoc” and select S-N-K (you are free to use whatever post hoc test you would like), and you need to click on “Options” and select: Descriptives,
Homogeneity of variance test, and plot means.
This first box gives you descriptive information.
Descriptives
Shocks
Non
Mildly
Moderately
N
10
10
10
10
Mean
9.3000
12.6000
17.7000
24.4000
95% Confidence Interval for
Mean
Std. Deviation Std. Error Lower Bound Upper Bound
2.90784
.91954
7.2199
11.3801
3.43835
2.90784
5.05964
1.08730
.91954
1.60000
10.1404
15.6199
20.7805
15.0596
19.7801
28.0195
Minimum Maximum
6.00
16.00
8.00
14.00
16.00
17.00
23.00
32.00
Highly
Total 40 16.0000
6.77098
1.07059
13.8345
18.1655
6.00
32.00
It tells you there were 10 participants in each group (N). It gives you the means and standard deviations for each group (you can see the mean number of shocks increased with each condition, and the variability in the 4 th condition was the greatest). It also lists the standard error, 95% CI for the mean for each group, and the range of scores for each group.
This next box gives you the results of a homogeneity of variance test.
Test of Homogeneity of Variances
Shocks
Levene
Statistic df1 df2 Sig.
1.827
3 36 .160
Remember, this is an assumption for a valid ANOVA (that the variances of each group/condition are the same). We want this test to not reach statistical significance. When it is not significant , that is saying the groups ’ variances are not significantly different from each other (this is an assumption for a valid ANOVA).
In this case, our assumption is met ( p = .160). The p -value does not exceed alpha (either .05 or .01). This is what we want; it allows us to move on to the next box. If you did get a significant value here, you need to read up on the assumptions and see if you believe your test is robust against this violation.
This next box gives us our results.
ANOV A
Shock s
Between Groups
W ithin Groups
Total
Sum of
Squares
1299.000
489.000
1788.000
df
3
36
39
Mean S quare
433.000
13.583
F
31.877
Sig.
.000
SPSS Help 8
According to the last box, the p value is < .001 (SPSS rounds, so when you see “.000” in this box, always report it as p < .001, or as less than the alpha you are using). Thus, at either alpha (.05 or .01), we can reject the null; the groups are different.
The write-up would be: F (3, 36) = 31.88, p < .05 (or: F (3, 36) = 31.88, p < .001). Remember, with
ANOVA, at this point that is all we can say. We need to do post hoc tests to see where the differences are. We will get to that box next. To get your measure of effect, calculate by hand (or use univariate method explained above). Eta 2 = SS Between/Ss Total [for this example: 1299/1788 = .73; a large effect].
This next box gives the results of the post hoc tests.
Shocks
Student-Newman-Keuls a
Group
Non
Mildly
Moderately
Highly
Sig.
N
10
10
10
10
1
Subset for alpha = .05
2
9.3000
12.6000
17.7000
.053
1.000
3
24.4000
1.000
Means for groups in homogeneous subsets are dis played.
a. Us es Harmonic Mean Sample Size = 10.000.
The means that differ from each other are in separate boxes (other post hoc tests show differences between groups in different ways, sometimes by an *). Thus, the first two groups do not differ from each other, but all the other means do differ from each other. That is, the non and mildly insulting groups had significantly lower means than both the moderately and highly insulting groups. Further, the moderately insulting group had a significantly lower mean than the highly insulting group. The means in the non and mildly insulting groups did not differ from each other.
This last portion of the output gives you a nice visual display of the group means. You can see the steep increase in shocks given between the non/mildly insulting groups and the moderately/highly insulting groups.
SPSS Help 9
25.00
20.00
15.00
10.00
Non Mildly Moderately Highly
Group
6. Chi-Square
A chi-square (pronounced “ky” square) test is used with you have variables that are categorical rather than continuous. Examples when this test would be useful include the following: Is there a relationship between gender and political affiliation? Is there a relationship between ethnic group and religious group?
Is there a difference between private and public school in dropout rates? Do not forget to check that assumptions for a valid test are met before performing this analysis.
The example here is based on Chapter 15 (problem #46). The research was examining TV and how it influences gender stereotyping. For this study, commercials were classified in terms of whether the main character was male or female and whether he or she was portrayed as an authority (an expert on the product), or simply a user of the product. Thus, the IV is gender (male/female) and the DV is role
(authority/user). Notice that these are categorical, or discrete variables.
The output below is not the default output. In order to get these tables you must do the following:
Analyze Descriptive Statistics Crosstabs. Put one variable in the row box and one in the column. For this example, I put “gender” in the row box , and “role” in the column box. Click on “Statistics” and choose
“Chi Square” and “Phi & Cramer’s V.” Next, click on “Cells” and choose “Counts, Observed” and
“Percentages, Row, Column and Total.”
This first box is a summary, detailing the total N and number and % of missing cases. You can see there are 146 participants, with no missing cases.
Case Processing Summary
Valid
Cases
Missing Total
N Percent N Percent N Percent gender * role 146 100.0% 0 .0% 146 100.0%
This box gives you descriptive information that you will use if your test is significant (to explain the results).
SPSS Help 10 ge nde r * role Crossta bula tion gender
Total male female
Count
% within gender
% within role
% of Total
Count
% within gender
% within role
% of Total
Count
% within gender
% within role
% of Total
This box gives the results of your χ 2 test. authority
75
65.2% role
88.2%
51.4%
10
32.3%
11.8%
6.8%
85
58.2%
100.0%
58.2% us er
40
34.8%
65.6%
27.4%
21
67.7%
34.4%
14.4%
61
41.8%
100.0%
41.8%
Chi-Square Tests
Total
115
100.0%
78.8%
78.8%
31
100.0%
21.2%
21.2%
146
100.0%
100.0%
100.0%
Pearson Chi-Square
Continuity Correction a
Likelihood Ratio
Fis her's Exact Test
Linear-by-Linear
As sociation
N of Valid Cases
Value
10.905
b
9.592
10.849
10.830
df
1
1
1
1
As ymp. Sig.
(2-sided)
.001
.002
.001
.001
Exact Sig.
(2-sided)
.002
Exact Sig.
(1-sided)
.001
146 a. Computed only for a 2x2 table b.
0 cells (.0%) have expected count less than 5. The minimum expected count is 12.
95.
You read the first row (first line). Your p -value appears in the forth column (box titled “Asymp. Sig. (2sided)). For this example, the p = .001. At either alpha this is statistically significant and we would reject the null and conclude there is a relationship between gender and role portrayal.
A write up may look like this: χ 2 (1, N = 146) = 10.91, p = .05 (or: χ 2 (1, N = 146) = 10.91, p = .001). Thus, there is a relationship between gender and role portrayal in commercials. When your result is significant, you will want to go on to report percents and effect size. For percents, go back to the previous box. In this case, you may say something like: When an authority role was portrayed, it was a male 88% of the time, while it was a female only 12% of the time.
This box gives your measure of effect.
SPSS Help 11
Symmetric Measures
Nominal by
Nominal
N of Valid Cases
Phi
Cramer's V
Value
.273
.273
146
Approx. Sig.
.001
.001
a. Not ass uming the null hypothesis.
b. Us ing the asymptotic standard error as suming the null hypothesis.
It is in the first line (first row) and is called “Cramer’s V” (pronounced Cramer’s Phi). In this case, the effect size is .273, a small to moderate effect.
A note about this symbol: χ 2 You get this, in Word, by choosing the “Insert” tab, and then “symbol.” It is a
Greek letter. You may have to change your font to get it to show up like it is supposed to (Times New
Roman always works). Once you get the χ , you need to add the superscript “2”.
Bonus: Books you may find helpful (in addition to Jaccard & Becker)
The Basic Practice of Statistics 2
nd
Edition.
By: David S. Moore / Published by: Freeman.
ISBN:0-7167-3627-6. [This is an undergraduate level text book that would serve as a nice refresher for basic topics. It is easy to read and understand.]
Statistical Methods for Psychology 5
th
Edition.
By: David C. Howell / Published by: Duxbury
ISBN: 0-534-37770-X. [This is a graduate level text book and is very detailed, however, the author took great pains to make it readable.]
Reading and Understanding Multivariate Statistics.
Edited by: Laurence G. Grimm & Paul R. Arnold / Published by: APA.
ISBN: 1-55798-273-2 [This is an EXCELLENT book for multivariate statistics. For each analysis, an example is given, complete with how to read printouts and how to report APA style. I would go so far as to say this is a *must have* for a graduate student in the social sciences.]
SPSS Help 12
Which test do I use?
Note: there are many other statistical tests available, but this outline should provide you, at the very least, with a starting point in helping you determine the type of test you will need to perform.
Dependent or Response Variable
Continuous
Or
Quantitative
Discrete
Or
Categorical
Independent
Or
Explanatory
Variable
Continuous
Or
Quantitative
Discrete
Or
Categorical
Correlation/Regression t -test or ANOVA (see below for more details)
Logistic Regression (not covered in Statistics 1)
Chi-Square ( 2)
To use this table, first determine your IV and whether it is measured on a continuous (e.g. age in years) or discrete scale (e.g. gender). This will determine which ROW you use. Next, determine if the DV is continuous (e.g. happiness on a 10-point scale) or discrete (e.g. political affiliation). This will determine the
COLUMN you will use. With both pieces of information, you will end up in one box. If you land on the “t-test or ANOVA box” see the illustration below to help you further narrow it down.
One sample t-test
How many groups do I have?
1
2
>2
Matched Pairs
OR
Two sample t-test
ANOVA
Note: No test should be conducted without FIRST doing exploratory data analysis and confirming that the
statistical analysis would yield valid results. That is, check that the assumptions are met, or that the test is robust against violation(s).