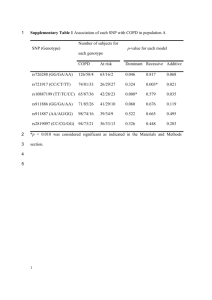
Supplementary Methods (doc 236K)
advertisement
")
Confidential
.
1
SUPPLEMENTARY METHODS
2
AMBROSIA: The pseudocode for the AMBROSIA algorithm is shown in Supplementary
3
Figure 1.
4
Case Study 1, Interactions in Data with Simulated LD Patterns: The gene-gene
5
interaction model used for this case study is shown in Supplementary Figure 2A.
6
We simulated 60 SNPs in four groups, G1 through G4, with linkage disequilibrium within
7
each group (Supplementary Figure 2B). The disease-causing SNPs corresponding to
8
SNPs i and j in Supplementary Figure 2A were SNP 7 (red in G1) and 22 (red in G2),
9
respectively. The minor allele frequencies (MAF) of the central SNP in each group were
10
0.5; the MAF of the flanking SNPs and LD pattern were the same within each group
11
and are shown in Supplementary Figure 2B. The penetrance matrix corresponding to
12
the disease associated gene-gene interaction between SNP 7 and SNP 22 was:
13
BB
Bb
bb
AA
p
p 1 p
Aa
p
p 1 p
aa 1 p 1 p 1 p
14
The major and minor alleles for SNP 7 are A and a, respectively, whereas the major
15
and minor alleles for SNP 22 are B and b, respectively. The probability of disease in
16
individuals with the risk-associated genotype combinations, {AA, BB}, {AA, Bb}, {Aa,
17
BB}, {Aa, Bb}, is p. The probability of disease in individuals without the risk-associated
18
genotypes was set to (1 – p). In this context, the relative risk was the ratio of p to (1 –
19
p). The case-control status phenotype variable was denoted by Y.
20
The relative risk values used in simulation were 1.2, 1.5, 1.8, 2.0 and 2.5. The case-
21
control design with 2500 cases and 2500 controls was used.
Page 1
Confidential
.
1
Power was assessed from 100 independent repetitions of the simulation procedure.
2
Power was defined as the proportion of models that contained the interacting
3
combinations. The average number of false combinations per model (FCM) was
4
defined as the number of false combinations in each model averaged over the 100
5
independent repetitions. For Case Study 1, the AMBIENCE input parameter values
6
were = 10 and = 2. All power calculations in AMBROSIA were done with = 0.001.
7
Case Study 2, Gene-Gene Interactions with Genetic Heterogeneity: To challenge
8
the capabilities of AMBROSIA, we created a simulation with two pairs of gene-gene
9
interactions.
10
The model for Case Study 2, summarized in Supplementary Figure 2C, contained 120
11
SNPs in eight groups. The allele frequencies of the central SNPs were all 0.5; the MAF
12
of the flanking SNPs and the LD patterns within each group were similar to Case Study
13
1.
14
The model contained genetic heterogeneity (GH) with two pairs of interacting loci, SNP
15
7 with SNP 22 and SNP 67 with SNP 82 that each increased risk in half of the cases.
16
Both pairs of interactions followed the penetrance matrix of Case Study 1. The relative
17
values used in simulation were 1.2, 1.5, 1.8, 2.0 and 2.5 and a case-control design with
18
2500 cases and 2500 controls was used. For Case Study 2, the AMBIENCE input
19
parameter values were = 10 and = 2.
20
Comparisons with Multi-factor Dimensionality Reduction (MDR)
21
The AMBROSIA method was compared head to head with MDR
22
implementation was downloaded from http://sourceforge.net/projects/mdr/.
23
Comparisons to MDR using Case Study 2. The MDR method was first run to conduct
24
an exhaustive search of all possible 1 to 4-locus interactions with each data repetition
25
of Case Study 2. However, each of these MDR runs failed to complete successfully
Page 2
2.
The MDR
Confidential
.
1
after 48 hours of run time. To enable comparison of AMBROSIA to MDR, we created a
2
smaller data set by simplifying Case Study 2 to contain only 24 SNPs. The central SNP
3
and one SNP with R2 = 0.9 and one SNP with R2 = 0.8 were selected from each of the
4
eight Groups. The LD patterns of this reduced data set are summarized in
5
Supplementary Figure 2D.
6
The model contained genetic heterogeneity (GH) with two pairs of interacting loci:
7
Interaction 1 consisted of SNP 1 and SNP 4 and Interaction 2 consisted SNP 13 and
8
SNP 16 that each increased risk in half of the cases. Both pairs of interactions followed
9
the penetrance matrix of Case Study 1. The simulation strategy was similar to Case
10
Study 1.
11
The relative risk value of 2.0 was studied and a case-control design with 2500 cases
12
and 2500 controls was used.
13
The MDR method was first run to conduct an exhaustive search of all possible 1 to 4-
14
locus interactions with each data repetition. Statistical significance in MDR was
15
obtained by comparing the observed prediction error for each MDR model to the null
16
distribution obtained from 10,000 permutations.
17
The AMBIENCE input parameter values were = 50 and = 2. The power and FCM of
18
MDR and AMBROSIA were computed from 100 independent simulations.
19
Comparisons with MDR using Models Based on the MDR Power Paper. Four two-
20
locus interaction models employed in the MDR power evaluation paper by Ritchie et al.
21
1
22
models used is shown in Table 1 of the main paper.
23
A case-control study design with 2500 cases and 2500 controls was assumed. 24
24
diallelic SNPs were simulated in eight groups (Supplementary Figure 1D). For each
were used for comparison against AMBROSIA. The penetrance matrices for the
Page 3
Confidential
.
1
group with 3 SNPs, the central SNP is in LD with R2 = 0.9 and R2 = 0.8 with the other
2
two SNPs of that group respectively.
3
Four interaction models were simulated with genetic heterogeneity. Models 1-GH, 2-
4
GH, 3-GH and 4-GH contained genetic heterogeneity (GH) with two pairs of interacting
5
loci, SNP(1) with SNP(4), defined as Interaction 1 and SNP(13) with SNP(16), defined
6
as Interaction 2. The corresponding penetrance matrices in Table 1 were used for
7
simulations for both pairs of interacting loci for each model such that each Interaction
8
increased disease risk in half of the cases. The remaining SNPs were not associated
9
with the phenotype. For models 1-GH and 2-GH, within each 3-SNP group, the allele
10
frequency for the central SNP was 0.5; the minor allele frequencies (MAF) for the other
11
two SNPs were 0.445 (R2 of 0.9 with the central SNP) and 0.474 (R2 of 0.8 with the
12
central SNP) respectively. For model 3-GH, within each 3-SNP group, the MAF for the
13
central SNP was 0.25; MAF for the other two SNPs were 0.232 (R2 of 0.9 with the
14
central SNP) and 0.211 (R2 of 0.8 with the central SNP) respectively. For model 4-GH,
15
within each 3-SNP group, the MAF for the central SNP was 0.1; MAF for the other two
16
SNPs were 0.091 (R2 of 0.9 with the central SNP) and 0.082 (R2 of 0.8 with the central
17
SNP) respectively. For each model, we simulated 100 data sets. Genotypes were
18
assumed to be in Hardy-Weinberg equilibrium proportions.
19
20
SUPPLEMENTARY RESULTS
21
Demonstration Run with Case Study 1, Interactions in Data with Simulated LD
22
Patterns: We used the top 10 one-SNP and two-SNP combinations with the highest
23
KWII values identified by AMBIENCE to build the most parsimonious model using
24
AMBROSIA.
Page 4
Confidential
.
1
In the first step of AMBROSIA, we confirmed that all the combinations identified by
2
AMBIENCE were significant using permutation based approaches with = 0.001. The
3
KWII values for the combinations are summarized in Supplementary Table 1. The value
4
of was set to 0.001.
5
AMBROSIA starts with the combination {22, Y}, which has the highest KWII, as the first
6
member combination in the model. In the next step, it assesses whether {7, Y} can be
7
added to the model. It evaluates KWII(7, 22, Y) = 0.012 > 0 and because MICC = 254,
8
which makes e–MICC < . As a result {7, Y} gets added to the model, so that M = {{22, Y},
9
{7, Y}}. In the same step, the significant combination {7, 22, Y} is also added to the
10
model because it has positive KWII and since its sub-combinations are present in the
11
model, the overall model complexity is not increased. Next the combination {23, Y} is
12
evaluated; however, KWII(22, 23, Y) = -0.036 < 0, so {23, Y} is rejected. Repeating
13
these steps for the 1-way and 2-way combinations listed in Table 2 does not add any
14
more combinations to M. Finally M = {{22, Y}, {7, Y}, {7,22, Y}} emerged as the most
15
informative and parsimonious model explaining the disease phenotype. The
16
significance of the overall model was p < 0.0001. These results from AMBROSIA are
17
consistent with model used for simulation.
18
These promising results provide proof of concept that AMBROSIA can be used for
19
model synthesis in the presence of the confounding effects of LD.
20
Page 5
Confidential
.
1
2
TABLES
Supplementary Table 1. Top 10 one and two-way combinations for Case Study 1.
1-way Combinations
KWII
2-way Combinations
KWII
{22, Y}
0.026
{7, 22, Y}
0.450
{7, Y}
0.026
{7, 21, Y}
0.380
{6, Y}
0.023
{8, 21, Y}
0.379
{8, Y}
0.023
{7, 23, Y}
0.379
{21, Y}
0.023
{6, 22, Y}
0.378
{23, Y}
0.023
{8, 22, Y}
0.323
{5, Y}
0.020
{8, 23, Y}
0.322
{24, Y}
0.020
{6, 21, Y}
0.322
{20, Y}
0.020
{6, 23, Y}
0.321
{9, Y}
0.020
{7, 24, Y}
0.319
3
4
Page 6
Confidential
1
.
Supplementary Table 2. Interactions in the GAW15 data set.
Locus
Chr
SNP #
Phenotype
Effects
DR
6
152-155
RA
Affects risk of RA
A
16
30-31
RA
Controls effect of DR on RA risk
B
8
442
RA
Controls effect of smoking on RA risk
C
6
152-155
RA
Increases RA risk only in women
D
6
161-162
RA
Rare allele increases RA risk 5-fold
E
18
268-269
RA, Anti-CCP
F
11
387-389
IgM
G
9
185-186
Severity
25% QTL for severity
H
9
192-193
Severity
25% QTL for severity
Age
-
RA
Affects RA risk through smoking and sex ratio
Sex
-
RA
Affects RA risk with Locus C
Smoking
-
RA, IgM
Affects of DR on anti-CCP and increases RA risk
QTL for IgM
Affects RA risk with Locus B and through IgM
2
3
Page 7
Confidential
1
.
FIGURE LEGENDS
2
Supplementary Figure 1. Pseudocode for the AMBROSIA algorithm.
3
Supplementary Figure 2. Supplementary Figure 1 shows the gene-gene interaction
4
model used to generate the data for Case Study 1. The red bars correspond to the
5
disease-associated interacting central SNPs whereas the blue bars represent the non-
6
interacting central SNPs in each group. The height of the bars corresponds to the
7
extent of linkage disequilibrium from the central SNP as measured by R2. The R2 values
8
are indicated and range from 0.2-0.9 in intervals of 0.1 for Figure 1B and 1C and are
9
0.9 and 0.8.
10
Page 8
Confidential
1
.
SUPPLEMENTARY FIGURE 1
Algorithm : Ambrosia
Input :
: Set of combinations sorted by KWII.
: Threshold for complexity filter.
Output :
: Model
1. Compute combination p - values with permutations.
2. 0; # MIC; N no. of samples in the data; 1;
3. 1 2N 2 ;
4. ;
5. while is not empty do
2
6.
C Combination with sub-combinations already in M or the one with highest KWII from
7.
temp {C};
8.
Degrees of freedom of M
temp
;
9. 2 2N ( KWII(C)) 2 ;
10. 2 1; # MICC
11. if exp(- ) # Complexity Filter#
12.
13.
14.
15.
if redundancy(M, C) is false # Redundancy Filter#
M M temp ;
KWII(C);
endif
16. endif
17. \ {C};
18. endwhile
19. return M;
3
4
5
Page 9
;
Confidential
1
.
SUPPLEMENTARY FIGURE 2
2
3
4
5
Page 10
Confidential
.
1
REFERENCES
2
Ritchie MD, Hahn LW, Moore JH (2003). Power of multifactor dimensionality reduction
3
for detecting gene-gene interactions in the presence of genotyping error, missing data,
4
phenocopy, and genetic heterogeneity. Genet Epidemiol 24(2): 150-157.
5
6
Ritchie MD, Hahn LW, Roodi N, Bailey LR, Dupont WD, Parl FF et al (2001).
7
Multifactor-dimensionality reduction reveals high-order interactions among estrogen-
8
metabolism genes in sporadic breast cancer. Am J Hum Genet 69(1): 138-147.
9
10
11
Page 11