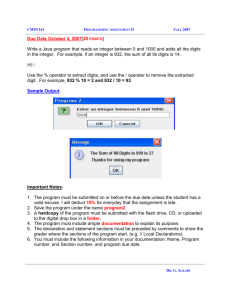
[#JSCIENCE-125] Mismatch: FloatingPoint radix 10

[JSCIENCE-125]
Mismatch: FloatingPoint radix 10, LargeInteger radix 2
Created:
19/Jan/09 Updated: 31/Jan/11
Status: Open
Project: jscience
Component/s: www
Affects
Version/s: current
Fix Version/s: Version 6.0
Type: Improvement
Reporter: hstoerr
Priority:
Assignee:
Resolution:
Labels:
Remaining
Estimate:
Time Spent:
Unresolved
None
Not Specified
Votes:
Original
Estimate:
Not Specified
Not Specified
Environment: Operating System: All
Platform: All
Issuezilla Id:
Description
125
I was wondering why the http://www.apfloat.org/ Library performs much better than JScience on arbitrary precision floating point multiplications when the number of digits is large.
(On 10000 digits it was 4 times as fast as JScience, but on
40000 digits it is 16 times as fast as JScience.) The effect becomes painful above 1000 digits or so.
Minor jscience-issues
0
The profiler gave me the hint that most of the time is spent in Calculus.divide. So the reason is the mismatch between
FloatingPoint, which works radix 10 for the exponents, and LargeInteger, which works with radix 2. So the multiplication itself is speeded up by the Karatsuba Algorithm, but afterwards a normalization, that is a division by 10^digitnumber, is performed, which is an expensive operation in radix 2.
So the nifty multiplication algorithm does not help here.
It is impracticable to change the radix for the FloatingPoint exponent, since this would change the interface. However it would be possible to change LargeInteger to work internally with base 10. The _words would then not be between 0 and
9223372036854775808, but between 0 and 1000000000000000000.
A division by a power of 10 would then be a linear operation in
the size of the number, not a quadratic operation as it is now.
You can do that without changing the interface of LargeInteger/FloatingPoint.
A summary of what would happen to the arbitrary precision operations for a large number of digits:
Some operations would have a dramatic speed up:
FloatingPoint multiplication, LargeInteger.toString and valueOf(String) in base
10, the XML serialization
Many operations would be slightly slower since the number has about 5% more _words
Some operations would be dramatically slower: the shift Operations, getLowestBit, longValue if you insist on the "last bits" semantics.
If LargeInteger is changed to base 10, JScience has a distinguishing feature to
ApFloat, since it is base 2 only.
If you want to change this I volunteer for this job, since I find this an interesting problem.
Best regards,
Hans-Peter Störr
Generated at Wed Feb 10 05:04:31 UTC 2016 using JIRA 6.2.3#6260sha1:63ef1d6dac3f4f4d7db4c1effd405ba38ccdc558.