Data Analysis with SPSS
advertisement

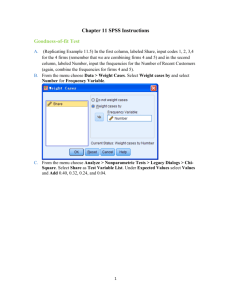
Statistics – Spring 2008 Lab #6 – Mediation and SEM Defined: Variables: Relationship: Example: Assumptions: Testing interrelationships amongst variables Variables are continuous or categorical Structure amongst variables What is relationship between provocation, anger, aggression, etc. If linear, then linear assumptions. If categorical, then multicollinearity. 1. Mediation SPSS can calculate the Baron/Kenny approach using three separate linear regressions, but SPSS can not calculate the Sobel Test. A macro on the following website allows SPSS to calculate Baron/Kenny and Sobel simultaneously. Here are the instructions for using the macro: 1. Go to this website – http://www.comm.ohio-state.edu/ahayes/sobel.htm (also listed on PsychWiki) 2. Download the macro to your computer by clicking on “Click here to download SPSS syntax file”. 3. Open the macro by double-clicking on it. 4. The new “syntax” window that opens up is the macro. 5. The blank data editor that opens up is where you need to put the data you want to analyze. 6. For our example, I am going to analyze three variables: commit1, liborcon, rel_person. Thus, I open our “legal beliefs” data file, copy the variables, and then paste the variables into the blank data editor. 7. You “activate the macro” by highlighting everything in the “syntax” window, and clicking the blue triangle underneath the “Graphs” pull-down menu. The information displayed in the “Output” window will be a duplicate of the syntax code for the macro. 8. You are now ready to start conducting mediation. 9. In the syntax window, copy/paste the following text: SOBEL y=yvar/x=xvar/m=mvar/boot=z. 10. In the place of “yvar”, put the SPSS variable name of your DV 11. In the place of “xvar”, put the SPSS variable name of your IV 12. In the place of “mvar”, put the SPSS variable name of your mediator. 13. In the place of “z”, put 1000. This tells the macro to run bootstrapping. I will explain this later. 14. As a concrete example, I want to test the relationship between: commit1, liborcon, rel_person. 15. More specifically, I want to test the relationship between commit1 and liborcon, and then see if rel_person is a mediator. To put that into “hypothesis” wording, I am starting with the finding that there is a positive and significant relationship between being “liberal versus conservative” and belief about “What percent of people brought to trial did in fact commit the crime?”. In other words, being more conservative leads to a higher percentage of defendants that people believe are guilty by simply being brought to trial. The hypothesis is whether or not being a religious person (rel_person) mediates that relationship. In other words, maybe being “liberal or conservative” leads to higher percentage for “commit1” BECAUSE of religiousocity. 16. To put that into a graphical form: Religious Liberal-Con commit1 1 17. To put that relationship into “syntax” wording, I type the following into the syntax window: y=commit1/x=liborcon/m=rel_person/boot=1000. 18. I highlight only that new line, and click the blue arrow. 19. The output window will show the analysis: Pasted below is the entire output: a. DIRECT AND TOTAL EFFECTS are the steps for the Baron and Kenny approach. In the first step of analysis, there was a significant relationship between IV & DV (p = .0860). In the second step of analysis, there was a significant relationship between IV & M (p = .0000). In the final step of the analysis, there was a significant relationship between M & IV (p = .0293), while the relationship between IV & DV became non-significant (p = .3411). b. INDIRECT EFFECT is the sobel test. The significant value (p = .0424) tells you that “rel_person” is a significant mediator between the IV and DV c. BOOTSTRAPPING tells you the same thing as the sobel test, but: (1) it calculates the analysis by first “bootstrapping”, which is a type of robust technqiue to control for non-normality, and (2) it gives you output in the form of “confidence intervals” instead of “p values”. I suggest reporting the Sobel test, and ignore the others tests (Baron/Kenny, bootstrapping). Here is how you report the sobel test: a. There was a significant initial relationship between the independent variable and dependent variable ( = .10, p = .086) that was non-significant after controlling for the mediator ( = .06, p = .341) which indicates level of religiousness mediates the relationship between the independent variable and dependent variable. b. FYI – I got the effect size () for the relationship between the “IV and DV” by conducting bivariate 2 regression (which is the same as bivariate correlation), and I got the effect size () for the relationship between the “IV and DV while controlling for the mediator” by including those three variables in a linear regression analysis and looking at the standardized beta for “liborcon” to “commit1” (in other words, the linear regression in which you put both “liborcon” and “rel_person” as IV into the analysis will report the unique effect of each variable on the DV, so the unique effect of “liborcon” on the DV is what you are looking for to report as the non-significant effect after controlling for the mediator). After you conduct your “confirmatory” analysis of your hypothesized relationship amongst the variables, you then do exploratory analysis, such as first testing alternative models (that you want to NOT WORK) because then it strengthens your hypothesis by having your hypothesis be the only relationship amongst the variables that does work. (By “work”, we mean finding a significant mediational relationship). With three variables, there are six total permutations. You can run all six if you want to. Some people only run the permutation in which you switch the M and DV (called “reverse” mediation). If none of the alternative models work, you report that in the following way: “No alternative models showed a significant mediational relationship amongst the variables.” Also, notice that you typically want the bivariate relationships amongst your variables to be significant. Thus, I usually look at the bivariate correlations before conducting mediational analysis. 2. Structural Equation Modeling I am going to show you the basic steps involved in SEM so that you are exposed to this type of statistical technique, and so that you understand the basic functions of the analysis. SEM is the ultimate type of statistical analysis because you can include any type of variable (e.g., continuous, categorical, dichotomous) and look at any type of relationship (e.g., any permutation). SEM is the most complicated type of statistical analysis. Entire courses are devoted to understanding SEM, so I can’t cover everything there is to know about SEM; instead I will provide the essential information. If you want to conduct SEM in the future, see me after the class is over and we can talk about how to get the software (EQS) and I can show you how to conduct the analysis in-depth. For simplicity sake, I am going to show you the data from one of my studies on intergroup aggression. We were interested in cycles of retributive violence, and how conflict spreads beyond the initial actors who started the dispute. We asked participants to tell us a time when a fellow ingroup member was harmed by an outgroup member. (the “ingroup” and “outgroup” could be any type of group, such as religion, ethnicity, family, gang, etc). We then asked participants to rate the experience along certain dimensions, such as a. their bond with the ingroup victim (identification), b. the perceived bond between outgroup members (entitativity), c. their emotional reactions (anger) and d. their feelings of retribution (toward the perpetrator, and towards group members of the perpatrator. Our hypothesis was that a. “Identification” was a pre-requisite to seeking retribution, and that it would influence retribution via emotional reactions like anger b. “Entitativity” was a pre-requisite to seeking retribution, but since it is a cognitive variable (and not an emotional variable), it would not influence retribution via emotional reactions like anger. c. Identification is a “motivator” so it will influence retribution toward everyone -- both the perpetrator and anyone involved (e.g., group member of the perpetrator) d. Entitativity is a cognitive perception of the outgroup, so it will ONLY influence retribution toward the group (but not the perpetrator) e. In sum, the reason why cycles of retributive violence continue is because of your attachment to the victim (identification) and perception of outgroup bonds (entitativity) that produces a desire to seek retribution toward the entire outgroup. f. The underlying assumption was that if you seek retribution toward the outgroup, other outgroup members who feel attached to the new victim (identification) will then seek retribution toward your group (entitativity). Thus, both sides undergoe the same process, and the cycle of violence continues as each side seeks more retribution back and forth and back and forth and etc. 3 The way you conduct SEM to test this hypothesized relationship involves three steps. First, draw a path model of the hypothesized relationships: a. Below is a graphical representation I drew in “Microsoft Word”. I drew this graphical representation simply to help you understand the path model. This step is not necessary to conduct SEM. The next picture below show you how to draw the path model in EQS. That step is necessary to conduct SEM. b. Here is the path model in EQS. The EQS program uses SPSS files, so the following variable names are from my SPSS file. The arrows represent the direction of the relationship. The “e” is the error term. Notice that there is not a bidirectional arrow between the two DVs. This is because you insert that relationship manually in the next step of the process. IN_ID3 INTENT_4 ANGRY_C OUT_E3 E1 E5 INTENT_5 E2 Second, EQS converts the path model to formulas and syntax. Notice that the “Equations” look similar to linear regression equations in which the DV is predicted from certain IVs and error terms. Notice also that under “Covariances”, I manually inputted the bidirectional relationship between the DVs (e.g., E1,E2 = *;) /TITLE Model built by EQS 6 for Windows /SPECIFICATIONS DATA='c:\documents and settings\doug stenstrom\desktop\new folder\100cases.ess'; VARIABLES=7; CASES=100; METHOD=ML,ROBUST; ANALYSIS=COVARIANCE; MATRIX=RAW; /LABELS V1=INTENT_4; V2=INTENT_5; V3=IN_ID3; V4=OUT_E3; V5=ANGRY_C; V6=SAD_C; V7=EMOTIN15; /EQUATIONS V1 = *V4 + *V5 + E1; V2 = *V4 + *V5 + E2; V5 = *V3 + E5; /VARIANCES V3 = *; V4 = *; E1 = *; E2 = *; E5 = *; /COVARIANCES V3,V4 = *; E1,E2 = *; /PRINT 4 EIS; FIT=ALL; EFFECT=YES; TABLE=EQUATION; /LMTEST PROCESS=SIMULTANEOUS; SET=PVV,PFV,PFF,PDD,GVV,GVF,GFV,GFF, BVF,BFF; /WTEST PVAL=0.05; PRIORITY=ZERO; /END Third, you run the analysis and get output. The output below is only a small percentage of the total output. The entire output is 10 pages. Each piece of the output is informative, but I just want to show you the essential information: This part of the output tells you whether your data are “normal”. If the “Normalized estimate” is above 3, then your data are non-normal. In this case, our data are “normal”. MULTIVARIATE KURTOSIS --------------------MARDIA'S COEFFICIENT (G2,P) = NORMALIZED ESTIMATE = 4.1230 2.4516 This part of the output tells you how the model fits your data according to various criteria. Remember that evaluating multiple fit indices simultaneously is recommended because different indices assess different aspects of goodness-of-fit, and there is not always agreement on what constitutes good fit, so satisfactory models should show consistently good-fitting results on many different indices. Here are the benchmarks for a “good” fitting model: Chi-square of p < .05; Ratio of x2/df < 3; SRMR < .08; CFI > .95. See the output below for the fit of our model: x2=1.03, p =.794, x2/df =.34, SRMR =.03, CFI =1.00. GOODNESS OF FIT SUMMARY FOR METHOD = ML INDEPENDENCE MODEL CHI-SQUARE INDEPENDENCE AIC = MODEL AIC = 72.65479 -4.97080 = 92.655 ON INDEPENDENCE CAIC = MODEL CAIC = 10 DEGREES OF FREEDOM 36.70359 -15.75616 CHI-SQUARE = 1.029 BASED ON 3 DEGREES OF FREEDOM PROBABILITY VALUE FOR THE CHI-SQUARE STATISTIC IS .79419 THE NORMAL THEORY RLS CHI-SQUARE FOR THIS ML SOLUTION IS FIT INDICES ----------BENTLER-BONETT NORMED FIT INDEX = .989 BENTLER-BONETT NON-NORMED FIT INDEX = 1.079 COMPARATIVE FIT INDEX (CFI) = 1.000 BOLLEN (IFI) FIT INDEX = 1.022 MCDONALD (MFI) FIT INDEX = 1.010 LISREL GFI FIT INDEX = .996 LISREL AGFI FIT INDEX = .979 ROOT MEAN-SQUARE RESIDUAL (RMR) = .133 STANDARDIZED RMR = .028 ROOT MEAN-SQUARE ERROR OF APPROXIMATION (RMSEA) 90% CONFIDENCE INTERVAL OF RMSEA ( .000, = 1.030. .000 .108) 5 This part of the output tells you the effect sizes for the relationships amongst your variables. STANDARDIZED SOLUTION: INTENT_4=V1 INTENT_5=V2 ANGRY_C =V5 = = = .452*V5 .314*V5 .247*V3 R-SQUARED + .159*V4 + .199*V4 + .969 E5 + .873 E1 + .924 E2 .237 .145 .061 This part of the output tells you if there are any relationships (e.g., lines between variables) that should be included or excluded. MULTIVARIATE WALD TEST BY SIMULTANEOUS PROCESS CUMULATIVE MULTIVARIATE STATISTICS ---------------------------------STEP PARAMETER CHI-SQUARE D.F. PROBABILITY ---- ----------- ---------- ---- ----------1 V4,V3 3.548 1 .060 UNIVARIATE INCREMENT -------------------CHI-SQUARE PROBABILITY ---------- ----------3.548 .060 LAGRANGE MULTIPLIER TEST (FOR ADDING PARAMETERS) ORDERED UNIVARIATE TEST STATISTICS: HANCOCK CHI3 DF PARAMETER NO CODE PARAMETER SQUARE PROB. PROB. CHANGE ------------------------ -------- --------1 2 11 V5,V4 .458 .499 .928 .045 2 2 11 V2,V3 .337 .562 .953 .064 STANDARDIZED CHANGE -------.014 .013 After collecting all available information from the output, you write-up the results using the following path diagram and text: .25** Identification Anger composite .23* Entitativity .45*** .31*** .20* Retribution towards the Perpetrator .56*** Retribution towards the Group Structural equation model of Study 1 variables including ingroup identification, outgroup entitativity, anger, retribution toward initial perpetrator, and retribution toward the entire outgroup. Paths with single-headed arrows represent directional effects and paths with double-headed arrows represent nondirectional covariances. Path coefficients are standardized, + p<.10 * p <.05; ** p < .01; *** p < .001. Overall model fit: 2(3) = 1.03, p = .794, 2/df = .34, SRMR = .03, CFI = 1.00. 6