B.2.5. “Mining Bibliography Citations Data”

Mining Bibliography Citations Data
*
D.A. Dervos 1 , N. Karapatsas 2
1 Dept. of Information Technology, Alexander Technology Educational Institute (ATEI),
Thessaloniki, Greece
Tel: +30 2310791295, Fax: +30 2310791290, E-mail: dad@it.teithe.gr
2 Dept. of Applied Informatics, University of Macedonia, Thessaloniki, Greece
Tel: +30 2310891844, Fax: +30 2310891800, E-mail: mai0640@uom.gr
In this paper we report on a research exercise whereby a data mining technique (affinity analysis) is applied to bibliography citations involving author-supplied and automatically generated keywords. The exercise aims at devising a strategy that combines semantic and pragmatic retrieval in a bibliography citations database.
As a testbed, six years of Science Citation Index Expanded (SCIE) citations data are utilized (1999-2005). The dataset has been made available by Thomson Scientific
(http://scientific.thomson.com/) to be used along the lines of the Cascading Citations
Analysis Project (C-CAP, http://www.ccapnet.org).
1. Introduction
Bibliography data relate to published items (e.g. research articles), the references cited by each one item (i.e. the bibliography resources used), and the citations received, namely: the identification of all published items that include the given item in their cited references lists. In this respect, citations data are seen to populate a citations graph whereby nodes represent the published items and directed edges represent bibliography references. The latter originate from the citing item and target the cited reference item. Citations data are usually utilized for ranking the impact of published items, as well as that of the hosting journals; the larger the number of citations received, the higher is the impact of the published item.
Another, equally if not more important, use of citations data is in implementing certain bibliography search strategies: researchers forward- and backward- chain along the citation links in order to track relevant publications in bibliography.
Content relevance comprises also the sought objective when it comes to assigning keyword descriptors to each one published item. Research article indexing today comprises an issue of utmost importance when one considers: (a) the internet based scholarly communication environment, (b) the open access movement, and
(c) the globalization in academia and research. Such developments signal the crucial importance of the accessibility factor for published works, best described by one simple rule: ‘ if a digital object is not indexed properly it cannot be retrieved; if not retrieved, it does not exist
’.
* This work is co-funded by the Research Committees of the Alexander Technology Educational
Institute (ATEI), and the University of Macedonia, Thessaloniki, Greece.
Traditionally, keyword- and descriptor- based retrieval together comprise the dominant mode of commercial bibliographic database searching today. Keywords and descriptors are entered either by the authors themselves, by professional indexers, or they are machine-generated by considering selected sections of the scientific article’s textual content (e.g. title, abstract, referenced articles, etc.). Still, it was as early as in 1961 when Dr. Eugene Garfield, the inventor of the citation index, first thought critically about the possibility of using an article’s cited references as index terms, rather than using machines to automatically assign traditional subject descriptors (ISI, 1999). Later, M.L. Pao compared and contrasted the two searching modes, referring to the former by the name of semantic retrieval and to the latter by the name of pragmatic retrieval (Pao, 1993).
Regarding the drawbacks of keyword- and descriptor- based semantic retrieval,
M.L. Pao is in agreement with S.P. Harter’s explanation for the low recall values observed; namely that the latter are due to the existence of many reasonable candidate search elements and search items for any given topic (Pao, 1993; Harter,
1990). Equivalently, the problem is attributed to the absence of authority control on the names of the concepts and topics involved, as well as to the fact that the keywords and descriptors used are subject to linguistic change or obsolescence
(ISI, 1999).
On the other hand, the main weakness of the citation based (pragmatic) retrieval relates to the user having to initiate the search by supplying a seed article of relevance (Larsen, and Ingwersen, 2002). B. Larsen, and P. Ingwersen attempt to rectify the stated drawback by introducing their boomerang effect approach whereby a set of top-ranked articles is identified by conducting an initial keyword based search. Next, the frequently occurring citations are extracted and used to compile a query that is processed against the citation index. Still, their approach is reported to require further improvement in order to outperform the keyword based retrieval
(Larsen, and Ingwersen, 2006).
In the present research exercise, an attempt is made to combine the semantic and pragmatic retrieval approaches by utilizing information present in the cascading citations paradigm. The latter extends the citations paradigm by introducing two new concepts: the indirect citation , and the chord (Dervos et al., 2006). An indirect citation is defined to be the instance whereby a target article receives a citation not by being a cited reference of the source article, but by being a cited reference of a third article which is in turn a cited reference of the source article. Evidently, indirect citations may be considered up to any desired depth . In (Dervos, and Kalkanis,
2005; Dervos et al., 2006), indirect citations are considered up to a depth of 3: direct citations are code-named 1-gen , the next level (2) citations are code-named 2-gen , and the next level (3) citations are code-named 3-gen . Thus, a chord instance is defined to be one whereby a direct ( 1-gen ) and an indirect ( 2-gen , or 3-gen ) citation co-exist, involving the same source and target articles. Chords are also codenamed as 2-chord (when a 1-gen co-exists with a 2-gen citation), and 3-chord
(when a 1-gen co-exists with a 3-gen citation).
In section 2 (Research Aim and Methodology), the approach applied in the present exercise is presented. The citations database used as a testbed is outlined in section 3 (The Testbed). The results obtained are presented and discussed in section 4 (Results), and section 5 (Conclusion) concludes and identifies issues calling for further research.
2. Research Aim and Methodology
In the present research exercise, it is assumed that the keywords used to index each one article are indicative of the subject/research area(s) covered. Also, for a
(any) collection of articles: it is assumed the keywords used to index its members, plus their frequencies distribution values are indicative of the subject/research area(s) covered by the collection, as a whole.
Having made the aforementioned assumptions, one may now proceed and ask questions like: (a) when comparing an article to its cited references, how much in focus is the former with respect to the subject area(s) covered by the latter?, and (b) considering an article next to those articles that include it in their cited references lists, how much in focus is the base/reference article with respect to the subject area(s) covered by the latter? Questions of this type are worth exploiting since, for example, an out of focus case in (b) is indicative of the base/reference article being one of an interdisciplinary value. Also, when one considers the (extended) cascading citations paradigm, it is worth comparing the degree of focus of a typical
1-gen citations population to (say) that of the 2-gen citations population that target the same base/reference article.
More formally, beginning with the cited references of and the articles that cite a given published item (article)
A
: (a) by backward chaining along the links in the citations graph, one obtains its set of cited references, and (b) by forward chaining, one identifies a set of articles which include the article in question in their own cited references lists. Let the former set be denoted by R , and the latter by D .
Equivalently:
R denotes the set of articles referenced in
A
, and
D denotes the set of articles that directly cite
A
(i.e. they include it as a cited reference in their bibliographies). In a similar way, considering the cascading citations paradigm, let
I denote the set of articles that cite A via a 2-gen citation, and let C denote the set of articles from which 2-chord instances originate that target
A
. At this point, it is worth noting that C
D
I always hold true, by definition.
Considering the above:
A
is the base/reference article. To proceed further, some similarity measure need be introduced; one which utilizes the keywords to quantify the likeness of
A
to each one of the four populations of the cascading citations paradigm: R , D , I , and C . In this respect, four similarity values need be calculated:
Sim (
A
,
R
), Sim (
A
,
D
), Sim (
A
,
I
), and Sim (
A
,
C
). The four similarity measures, can be normalized to obtain values in the [0,1] range as follows:
S ( A , x )
Sim ( A , x )
MAX { Sim ( A , R ), Sim ( A , D ), Sim ( A , I ), Sim ( A , C )}
, where x
{ R , D , I , C }
For the purpose of the research exercise in question, two types of similarity measures are considered: one which is occurrence statistics based, and the other is affinity analysis based. In both cases, A is assumed to come with m keywords: k
1
, k
2
, …, k m
. In addition,
x denotes any one of the four populations of the cascading citations paradigm: x
{ R , D , I , C } .
2.1. Occurrence Statistics Based (OSB) Similarity Measure
Considering the set of keywords that index each one article in x
, the occurrence frequency of each one keyword is calculated (i.e. the number of articles in
x indexed by the keyword in question). Next, the keywords in
x are ranked in terms of their occurrence frequency values: the most frequently occurring keyword is assigned the rank value 1, and the least frequently occurring one is assigned a rank value N , say. Ties are handled by assigning the same rank value to all keywords having the same occurrence frequency value. Next, the m keywords present in
A are considered. Say that keyword k
1
is identical or synonymous to a keyword of
x which has been assigned the rank value n
.
In this respect, k
1
is said to contribute a ( N n +1) value in calculating the value of Sim ( A ,
x
). For example, when n =1 (i.e. k
1
is the top-most ranked keyword for x
), the value it contributes in the calculation of Sim (
A
,
x
) is N . When n =5, the contribution equals N -4, etc. In cases where a keyword of
A is not present in x
(directly, or indirectly via a synonym term), it is taken to have a zero contribution in the calculation of the value of Sim ( A ,
x
).
2.2. Affinity Analysis Based (AAB) Similarity Measure
For a given base/reference article
A
, each x
may be modeled in terms of the market basket a nalysis paradigm (Dunham, 2002), the ‘transaction’ being an (any) article B in x , and the ‘items purchased’ being the keywords that index B . In the affinity analysis output, one obtains a set of association rules each involving itemsets of keywords in both its body (LHS) and head (RHS): k x
, k y
, …, k z
k m
, k n
, …, k r
The above rule reads as follows: articles in x
which are indexed by {k tend to also be indexed by {k m
, k n
, …, k r
}. x
, k y
, …, k z
}
The strength (validity) of an association rule is measured by means of the lift metric.
The latter indicates the factor by which the rule’s confidence exceeds the confidence of the (hypothetical) random case whereby the body and the head of the rule are statistically independent to each other (IBM, 2002). In this respect, valid association rules involve lift values which are larger than 1.
Let
K
A
denote the set of keywords that index
A
. Also, let
Ω denote the set of rules whereby the head of each one rule consists of one keyword, and that the latter is a member of
K
A
:
Ω : {k x
, k y
, …, k z
k m
, where m
K
A
}
For each one rule in Ω its lift value was multiplied by the rule’s support value (i.e. the probability for an article in x
to be indexed by both its body and head). The result obtained was assumed to reflect the likeness (in terms of subject areas covered) of x
to A : the more articles there are in x
which are indexed by keywords found to co-exist with keywords that index
A
, the more similar x
is to
A
(in terms of the subject areas covered). The sum of all such likeness values over Ω was taken to calculate the value of Sim ( A ,
x
).
3. The Testbed Environment
To test the approach outlined in Section 2, six years of citations data (1999-2005) from the Science Citation Index Expanded (SCIE) were utilized. The data have been made available from Thomson Scientific in order to be used for research purposes, along the lines of the Cascading Citations Analysis Project (C-CAP, http://www.ccapnet.org). The dataset registers 7,364,211 items (articles) published in 372,544 issues of 11,076 journals. Each one article is indexed by two sets of content descriptors: (a) the author-supplied keywords and (b) keywords plus
®
, a set of machine-generated terms, extracted from the titles of the article’s cited references (ISI 1999). The dataset was measured to involve an average of 2.06 keywords, and 4.2 keywords plus
®
per article. The typical article was measured to involve an average of 22 (within-the-set) cited references, and receive an average of 4.82 citations from articles present in the given dataset.
From the aforementioned citations dataset, a subset was extracted, involving articles published in journal issues indexed by the ‘Computer Science’ subject category descriptor. The CSc dataset registered 247,857 articles, published in
18,833 issues of 1959 journals. Including articles indexed as interdisciplinary applications relating to computer science, the dataset was measured to involve
657,216 1-gen citations, 2,513,141 2-gen citations, and 295,179 2-chord instances.
Interestingly enough, an additional 669 2-gen instances were identified to comprise cycles , namely pairs of articles that cite one another. Cycles were not considered to be valid 2-gen and 2-chord instances, and they are excluded from all calculations and results presented in the sequel.
To proceed with the research exercise, eight (8) highly cited articles in the CSc set were selected to work with (Table 1).
No Title Author(s) Published with
1
2
4
5
6
7
8
GROMACS 3.0: a package for molecular simulation and
Content-based image retrieval at the end of the
Lindahl E., Hess B.,
Van der Spoel D.
Smeulders A.W.M., et al. early years
3 Intrinsically disordered protein Dunker AK., et al.
J. Molecular Modeling, 7(8), 2001
IEEE Tran. Pattern Anal., and
Mach. Intellig. , 22(12), 2000
J. Molecular Graphics, and
Modeling, 19(1), 2001
Machine learning in automated text categorization
Gene selection for cancer classification using …
Sebastiani F.
Guyon I., et al.
ACM Com. Surv., 34(1), 2002
Machine Learning, 46(1-3), 2002
A review of protein-small molecule docking methods
Taylor RD., Jewsbury
P.J., Essex J.W.
J. Comp. Aided Molecular Design,
16(3), 2002
The meshless local Petrov-
Galerkin (MLPG) method …
Atluri S.N., Shen S.P.
CMES-Comp. Modeling in Eng. &
Sciences, 3(1), 2002
The del center dot B=0 constraint capturing… in shock-
Toth G.
J. of Computational
161(2), 2000
Table 1. The eight (8) highly cited articles of the testbed environment
Physics,
4. Results
Table 2 presents the citation scores of the eight articles considered (retaining the numbering of Table 1), the cascading citation measurements included:
No
5
6
7
8
1
2
3
4
1-gen
519
241
176
173
150
93
75
72 ref
13
32
41
14
10
26
13
11
2-gen
2115
274
2589
82
380
456
343
258
2-chord
455
68
639
11
80
66
169
80
Table 2. Citation scores of the eight articles considered
In the results that follow, the cited references ( ref ) population is not present since the corresponding samples were measured to be of a small size, for affinity analysis processing in particular. Thus, the research experiment proceeded by considering the D ( 1-gen ), I ( 2-gen ), and C ( 2-chord ) populations/sets, only.
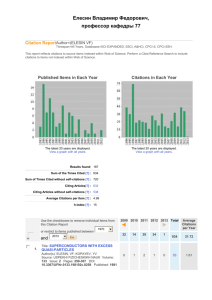
Figure 1: Occurrence Statistics Based (OSB) similarity values (normalized).
Figure 2: Affinity Analysis Based (AAB) similarity values (normalized).
Figures 1 and 2 present the results obtained for the eight articles considered. In the case of OSB (Figure 1), there appears to be no notable differentiation in the similarity values calculated for each one of the three populations ( D , I , C ). On the other hand, under the AAB approach (Figure 2): the C ( 2-chords ) population calculates larger similarity values in all but one case for both indexes ( keywords and keywords plus
®
); this is in agreement with what one would have expected to happen, by intuition: an article that targets the same cited reference both directly and indirectly is more likely to be (semantically/content-wise) nearer to the latter.
The issue calls for further investigation, beyond the probing scope of the present research exercise, i.e. by using larger samples from the citations dataset, plus by including the cited references ( R ) population.
5. Conclusion
In the research exercise, two approaches for the calculation of keyword based similarity values were considered and tested against a bibliography citations dataset: an Occurrence Statistics Based (OSB), and an Affinity Analysis Based
(AAB) approach. In both cases, the calculated similarity values were taken to reflect the likeness of a published article to populations of articles that relate to the former via direct or indirect citation links ( 1-gen , 2-gen , and 2-chord citation instances).
The objective is to devise a strategy that combines semantic and pragmatic retrieval in a bibliography citations database. More specifically, when a researcher has targeted an article s/he is interested in and considers its forward- and backward- chained bibliography links, it makes sense to proceed and consider next articles that are characterized by a relatively high degree of likeness (similarity) to the former. By intuition, one would expect the 2-chord instances to involve higher similarity values since an article that targets the same cited reference both directly and indirectly is more likely to be nearer (semantically/content-wise) to the latter.
An initial set of results were obtained, using eight (8) highly cited articles from the
SCIE dataset (indexed to relate to the Computer Science subject category, articles published during the 1999-2005). Two types of document content indexing schemes were used
: (a) author supplied keywords/descriptors, and (b) Thomson Scientific’s machine-generated descriptors (keywords plus
®
). The results obtained in the AAB output came to be closer to what one would expect by intuition, both for authorsupplied keywords, and for machine-generated keywords-plus
®
.
Acknowledgements
D.A. Dervos wishes to thank Peiling Wang for the invaluable guidance and the assistance provided. Special thanks are due to Thomson Scientific for the availability of the SCIE dataset. Lastly, the authors wish to thank IBM; the relational
DBMS ( DB2 ), and the data mining ( Intelligent Miner for Data ) software used are made available for educational/research use via the IBM Academic Initiative program ( http://www-304.ibm.com/jct09002c/us/en/university/scholars/academicinitiative/ ).
References
Dervos D., and Kalkanis T. (2005), cc-IFF: A Cascading Citations Impact Factor Framework for the
Automatic Ranking of Research Publications, 3rd IEEE International Workshop on Intelligent Data
Acquisition and Advan ced Computer Systems: Technology and Applications (IDAACS’2005), Sofia,
Bulgaria, 09/2005. Retrieved on 01 July 2007 from: http://dlist.sir.arizona.edu/1105/
Dervos D., Samaras N., Evangelidis G., and T. Folias (2006), A New Framework for the Citation Indexing
Paradigm, Proceedings, 2006 Annual Meeting of the American Society of Information Science and
Technology (ASIS&T), Austin, Texas, USA, 11/2006. Retrieved on 01 July 2007 from: http://eprints.rclis.org/archive/00008405/
Dunham M.H. (2002), Data Mining: Introductory and Advanced Topics , Prentice Hall, 1 st Edition.
Harter, S.P. (1990). Search Term Combinations and Retrieval Overlap: A Proposed Methodology and
Case Study. Journal of the American Society for Information Science , 41(2), 132-146.
IBM (2002), Using the Intelligent Miner for Data , Version 8, Release 1, IBM publication SH12-6750-00.
ISI Thomson Scientific (1999). Introduction to Citation Indexing and Citation Indexes. Retrieved on
February 23, 2007 from: http://scientific.thomson.com/media/scpdf/lis_sem_0704.pdf
Larsen, B., and Ingwersen, P. (2002). The Boomerang Effect: Retrieving Scientific Documents via the
Network of References and Citations. Proceedings, 2002 SIGIR Conference, Tampere, 397-398.
Larsen, B., and Ingwersen, P. (2006). Using Citations for Ranking in Digital Libraries. Proceedings, 6 th
ACM/IEEE Joint Conference on Digital Libraries, Poster paper, 370-370.
Pao, M.L. (1993). Term and Citation Retrieval: A Field Study. Information Processing & Management ,
29(1), 95-112.