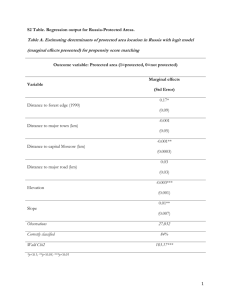
ec422 lectures: dummy variables
advertisement

EC422 LECTURES: DUMMY VARIABLES
Introduction
In this chapter, we examine variables that take on only the values zero or one.
These are sometimes called binary variables, or dummy variable or indicator variables.
We will consider how to use and interpret these variables as both independent and
dependent variables in a regression model.
Describing qualitative information
Dummy variable are a useful way to describe qualitative information.
Qualitative here means ordinal or unordered information, rather than cardinal
information. Examples of qualitative information include sex, marital status, state of
residence, type of car, mode of transportation to work, self-reported health, and so on.
For variables that take on only two values, the mapping to {0,1} is very clear. We will
see why these two values, rather than others, are especially useful shortly.
For variables that take on multiple values, we can code each value as a 0/1 dummy
variable. For example, for state of residence we can create 50 dummy variables, one for
each state, and set the variables equal to one when an individual lives it the state
referenced by the variable and zero otherwise.
A single dummy independent variable
Dummy variables and conditional means
Dummy variables allow us to look at conditional means very simply.
Define the binary variable male 1 for men and male 0 for women. Thus, male is a
“sex dummy”.
Suppose that we estimate the following model:
earnings 0 1male u .
What is the expected value of earnings for men? It is given by
E (earnings | male 1) 0 1 ,
1
where we obtain this relationship by taking the expected value of the regression equation,
under the assumption that the conditional mean of the error term equals zero.
Similarly, we can determine the expected value of earnings for women. They are given
by
E (earnings | male 0) 0 .
In this simple model, the two parameters have very clear interpretations.
We have that 0 gives the mean earnings of women, 0 1 gives the mean earnings of
men and 1 represents the difference in mean earnings between men and women.
Note that 1 is completely flexible (can be either positive or negative), so that men can
have higher or lower mean earnings than women.
Testing 1 0 here is equivalent to doing a t test of the difference in means between the
two groups. You will get exactly the same answer.
Now suppose that we define another dummy variable, with female 1 for women and
female 0 for men.
We use this new dummy variable to estimate the following model:
earnings 0 1 female .
In this model, we have that
E (earnings | female 1) 0 1
while
E (earnings | female 0) 0 .
The two models provide exactly the same information, but in a slightly different way. To
see this, link the parameters of the two models:
Mean earnings of men: 0 1 0 ;
Mean earnings of women: 0 0 1 ;
Mean earnings of men – mean earnings of women: 1 1 .
Thus, both means and the difference in means can be recovered from both models.
2
The dummy variable trap
Why not include both the male and female dummies in the same model, as in
earnings 0 1male 2 female ?
The reason is perfect multicollinearity (assuming no hermaphrodites).
Keep in mind that the constant term is implicitly the coefficient on a vector of 1s. We
can see very simply that
male female 1 ,
so that with a constant term, we have perfect multicollinearity.
This is a general feature of using dummy variables to represent categories. If you include
an intercept / constant term, you must leave out one of the dummies.
As we showed in the discussion of the male and female dummy variables, the mean for
whichever group is left out is given by the intercept. When we used the male dummy,
the mean for the omitted group (women) was given by the intercept term. Similarly, with
the female dummy, the mean for the omitted group (men) was given by the constant
term.
The group that is left out is called the omitted group, the reference group or the baseline
group or the benchmark group.
Trying to put in the dummy variables for all of the groups, and having Stata throw one of
them out for you, is called falling into the dummy variable trap.
A dummy variable in a regression with a continuous independent variable
Now consider what happens when we include a dummy variable in a regression along
with a continuous variable, as in:
earnings 0 1male 2educ u .
Once again, it is helpful to take expected values. What is the expected value for men?
E (earnings | male 1, educ) ( 0 1 ) 2educ .
What is the expected value for women?
E (earnings | male 0, educ) 0 2educ .
3
Taking expected values reveals two important features of this model:
1) The expected value of earnings has the same slope, 2 , for men and women.
2) The expected value of earnings has a different intercept for men and women. For men
the intercept equals (0 1 ) while for women it equals 0 .
Draw a graph to illustrate the model.
Review the graph.
Show the different intercepts for men and women.
Show the common slope for men and women.
Adding a dummy variable allows us to make the model more flexible by having different
intercepts for different groups while retaining a common slope (or slopes if additional
continuous variables are included in the model).
Dummy variables and program evaluation
Sometimes the dummy variable represents a choice rather than a characteristic.
For example, it often represents the receipt of some “treatment” such as a drug,
counseling, participation in a government program and so on.
In this case, we worry about endogeneity, that is, about correlation between the treatment
dummy and the error term resulting from non-random selection into the treatment.
Discuss the example of the employment offices in Canada.
Only in cases of random assignment can we be sure that such endogeneity is not a
problem.
In the case of random assignment, the simple model
outcome 0 1treated u
provides an estimate of the mean impact of receiving the treatment. This estimate is
provided by ̂1 , the estimated coefficient on the dummy variable for treatment.
You will estimate experimental impacts on the problem set using the NSW data. The
NSW was implemented as a social experiment and then used to benchmark nonexperimental estimators of program impact.
4
Interpreting coefficients on dummy variables when the independent variable is ln(y)
Suppose that we have the model
y 0 1d 2 x u ,
where y and x are continuous variables and d is a dummy variable.
How do we interpret the estimated coefficient on d?
Casually, 100 times the estimated coefficient is the estimated change in the expected
value of y in response to a change in d from zero to one.
For example, if ˆ1 0.12 , the casual interpretation is that a change in d from zero to one
would increase the expected value of y by 12 percent.
More formally, the exact change is given by
%E( y | d , x) 100[exp( ˆ1 ) 1] .
In the case of ˆ1 0.12 , we get
100[exp(0.12) 1] 100(1.1275 1) 100(0.1275) 12.75 ,
so that the precise interpretation is a change in the expected value of y of 12.75 percent.
In general, for “small” values of ˆ1 , the casual and formal interpretations give about the
same answer.
Examples in Stata
Handout the stata example.
The example uses the CPS sample from the NSW data.
It considers differences between married and unmarried individuals.
Go over the means obtained using the tab, summarize command.
Go over the means (and difference in means) obtained in the regression using the married
dummy variable.
Go over the creation of the not married dummy variable.
5
Go over the means (and difference in means) obtained in the regression using the not
married dummy variable.
Go over the regression with the married dummy and education.
Draw the graph and put the numbers on the graph.
Go over the regression with the not married dummy variable. Link to the graph.
Using dummy variables for multiple categories
Multiple unordered categories
Dummy variables can also be used to estimate conditional means, or allow different
intercepts, for cases where there are more than two groups.
Continuing with our earnings example, suppose that we want to separately consider
single men and women and married men and women.
This means that we now have four groups: single men, single women, married men and
married women.
Aside on the economics of the married male wage premium as a motivation for why it is
interesting to look at these groups separately.
Let’s define four dummy variables – msing, wsing, mmarr, wmarr – for the four groups.
Keeping in mind the dummy variable trap, we can now estimate a model with just three
of the dummy variables, as in
earnings 0 1wsing 2 mmarr 3 wmarr u .
In this model, 0 gives expected earnings for single men, ( 0 1 ) gives expected
earnings for single women, ( 0 2 ) gives expected earnings for married men and
( 0 3 ) gives expected earnings for married women.
Note that we can pick the omitted group so as to have the regression generate particular
contrasts of interest. Thus, to have the regression estimate the difference in means
between married men and married women, we would want one of these two groups to be
the omitted group.
All of this holds as well in models that also include continuous regressors.
6
Incorporating ordinal information using dummies
WHAT TO DO WHEN YOU HAVE, SAY, A CUSTOMER SATISFACTION
MEASURE OR SOME OTHER ORDINAL VARIABLE
EXAMPLE: VERY SATISFIED, SOMEWHAT SATISFIED, SOMEWHAT
DISSATISFIED, VERY DISSATISFIED.
COULD CODE AS 1 TO 4 AND ENTER AS A CONTINUOUS VARIABLE
THIS ASSUMES THAT THE CHANGE FROM 1 TO 2 HAS THE SAME MEANING
AS THE CHANGE FROM 2 TO 3 OR FROM 3 TO 4. YOU MAY NOT WANT TO
ASSUME THIS.
IN THIS CASE, YOU CODE EACH RESPONSE AS A DUMMY VARIABLE AND
ENTER ALL BUT ONE OF THE DUMMIES. THIS IS LESS RESTRICTIVE THAN
ENTERING THE ORDINAL MEASURE AS A CONTINUOUS VARIABLE.
Semi-parametric estimation and functional form choice
USING DUMMY VARIABLES IS A WAY TO LET THE DATA SPEAK ABOUT
FUNCTIONAL FORM
YOU CAN THEN USE THE INFORMATION FROM THE ANALYSIS WITH
DUMMY VARIABLES TO PICK A MORE PARAMETRIC SPECIFICATION IF YOU
LIKE (AND IF THE DATA AGREE!)
GO THROUGH STEPS:
CODE CONTINUOUS VARIABLE INTO SMALL INTERVALS, WITH ONE
DUMMY VARIABLE FOR EACH INTERVAL.
PICK INTERVAL SIZES CAREFULLY – YOU WANT ENOUGH OBSERVATIONS
IN EACH INTERVAL TO GET A REASONABLE ESTIMATE.
ENTER ALL DUMMIES IN REGRESISON IN PLACE OF THE CONTINUOUS
VARIABLE.
PLOT THE COEFFICIENTS ON THE DUMMIES AND CONSIDER THEIR SHAPE.
THIS IS CALLED SEMI-PARAMETRIC ESTIMATION
LINK TO PROBLEM SET QUESTION ON AGE
GO THROUGH HANDOUT EXAMPLE WITH EDUCATION
7
Interactions involving dummy variables
Interactions between dummy variables
Let us revisit now the married wage premium question. Before, we estimated this using
the model
earnings 0 1wsing 2 mmarr 3 wmarr u .
Another way to estimate the model is by interacting the married dummy variable and the
male dummy variable, as in
earnings 0 1male 2 married 3male married u .
The coefficients on the male dummy and the married dummy are called “main effects”
and the coefficient on the interaction term is called the “interaction effect”.
A model with all possible main effects and interactions is called a “fully saturated”
model.
See how the expected values work out:
For single women: E (earnings | male 0, married 0) 0 .
For single men: E (earnings | male 1, married 0) 0 1 .
For married women: E (earnings | male 0, married 1) 0 2
For married men: E (earnings | male 1, married 1) 0 1 2 3
Once again, we use four parameters to estimate four means.
Sometimes you may want to test the restriction that the effect of marriage is the same for
men and women or, more generally, that the interaction effect is zero, so that the effect of
both variables can be obtained by adding their main effects.
In this context, that test is just the t test of the null that the coefficient on the interaction
term is zero. In symbols, we test:
H 0 : 3 0 .
Note that testing this null would have required an F test in the model written the other
way, as we would have had to test whether the coefficients on mmarr and wmarr were
equal.
Interactions between dummy variables and continuous variables
8
Interactions between dummy variables and continuous variables allow different slope
coefficients for different groups.
Return to our example from before regarding sex and education. There we had the model
earnings 0 1male 2educ u .
That model allowed for different intercepts for men and women, but not for different
slopes for men and women. To allow for different slopes, we estimate the augmented
model
earnings 0 1male 2educ 3male educ u ,
which includes an interaction term between male and educ.
Consider the expected values of earnings for men and women:
Women: E (earnings | male 0) 0 2educ
Men: E (earnings | male 1) ( 0 1 ) ( 2 3 )educ
In this model, 0 is the intercept for women, 1 is the difference in the intercept between
men and women, 2 is the slope coefficient on education for women, and 3 is the
difference in the slope coefficient on education between men and women.
Draw the picture and link up the picture to the parameters of the model.
Go through the handout example and link it to the picture.
Testing for differences in regression functions across groups
TWO WAYS TO DO THIS
F TEST IN THE MODEL WITH INTERACTION TERMS
GO THROUGH EXAMPLE IN SEX/EDUC MODEL
ESTIMATE WHOLE MODEL SEPARATELY FOR THE TWO GROUPS
BENEFIT: EASIER THAN CREATING LOTS OF INTERACTION TERMS; JUST
NEED AN IF STATEMENT ON THE REGRESSION
COST: MUST ASSUME HOMOSKEDASTICITY BETWEEN GROUPS
COST: NO DIFFERENCES AT ALL, NOT EVEN AN INTERCEPT DIFFERENCE
9
THE F STATISTIC FOR THIS VERSION IS GIVEN BY
F
[ SSRP ( SSR1 SSR2 )] / k 1
SSR1 SSR2 /[n 2(k 1)]
DEFINE TERMS
SSR_P = SUM OF SQUARED RESIDUALS FROM POOLED (RESTRICTED)
MODEL
SSR_1 = SUM OF SQUARED RESIDUALS FROM GROUP 1 MODEL
SSR_2 = SUM OF SQUARED RESIDUALS FROM GROUP 2 MODEL
K+1 = NUMBER OF RESTRICTIONS IMPLICIT IN POOLING
N – (2K+1) = NUMBER OF DF IN THE UNRESTRICTED MODELS
GO THROUGH AN EXAMPLE WITH A SEX/EDUC MODEL
SHOW THE EQUATIONS YOU WOULD ESTIMATE AND WHERE EACH SSR
TERM COMES FROM
THIS IS SOMETIMES CALLED A CHOW TEST
The linear probability model
We now consider the case of a binary dependent variable, rather than a binary
independent variable. The model is now:
di 0 1 x1 2 x2 ... k xk .
This model is called the linear probability model, for reasons that will become apparent
shortly.
The only difference between this and our usual model is that the dependent variable is
binary rather than continuous.
What difference does this make? There are three main issues, which we now discuss in
turn. Following that, we will review an example from Stata.
Interpreting the linear probability model
The key insight in interpreting the linear probability model is that the expected value is
the same as the conditional probability. That is,
10
E (di | x1i , x2i ,..., xki xi ) Pr(di 1| xi ) .
To see this, consider a simple example. Suppose that E (di | xi ) 0.5 . The only way this
can happen is if, on average, half the values are one and half are zero, which means, of
course, that the probability of getting a value of one is 0.5.
Another way to see this is by applying the definition of the expected value. We have
E (di | xi ) (1) Pr(di 1| xi ) (0)[1 Pr(di 1| xi )] Pr(di 1| xi ) .
Thus, in estimating the linear probability we are estimating the conditional probability
function as well as the conditional mean function.
We can interpret the resulting coefficients as the effect of one-unit changes in the
independent variable on the probability that the dependent variable equals one.
Predicted values from the linear probability model
One potential problem with the linear probability model in some applications is that the
predicted values are not restricted to be between zero and one. Of course, probabilities
must lie between zero and one, so it could happen that a predicted value is an invalid
value for a probability.
In general, including additional terms in the model solves this problem. The additional
terms may be either higher order terms liked squared terms or else interaction terms.
Looking at the values of the independent variables for the observations whose predicted
probabilities lie below zero or above one in combination with the parameter estimates
will usually make it clear which independent variables are causing the trouble.
Heteroskedasticity in the linear probability model
Note that the error term in the linear probability model can take on only one of two
possible values, depending on whether the dependent variable equals zero or one.
To see this, rewrite the model as:
di Pr(di 1| xi ) ui .
If di 1 , which occurs with Pr(di 1| xi ) , then ui 1 Pr(di 1| xi ) .
Similarly, if di 0 , which occurs with 1 Pr(di 1| xi ) , then ui Pr(di 1| xi ) .
11
Thus, the error term takes on only two possible values conditional on x and, moreover,
those values depend on x.
The first fact means that the errors are not conditionally normal.
The second means that they are heteroskedastic, because they depend on x. Recall that
homoskedasticity is the assumption that:
var( y | x) 2 ,
where 2 is a constant, and thus not dependent on x.
To find the conditional variance in the linear probability case, we just apply the formula
for the variance and do some algebra. The result is that:
var(di | xi ) Pr(di 1| xi )[1 Pr(di 1| xi )],
which is just the variance for a binomial random variable.
There are ways to deal with this problem but they are beyond the scope of this course.
For our purposes here, just be aware of the fact that there is heteroskedasticity, and that as
a result the standard errors will not be correct. In general, they are approximately correct,
and we proceed on that basis.
Binary independent variables in the linear probability model
There is no difference here in interpreting binary independent variables, except that they
are now effects on probabilities.
Consider an example. Suppose I have the model:
employedi 0 1educi 2 malei 3agei ui .
Then 2 indicates the difference in employment probabilities between men and women
conditional on age and education.
Example from Stata
12