Introduction
advertisement

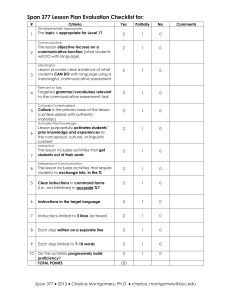
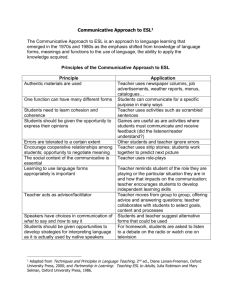
Lifelike Avatars and Agents through Modeling Communicative Behaviors Hannes Högni Vilhjálmsson Proseminar Fall 1997 If Nicholas Negroponte's Media Lab has any say, we'll connect to the global computer exactly the way we connect to each other, through full-bodied, fullminded conversation. -Stewart Brand, The Media Lab Introduction A face-to-face conversation is an activity in which we participate in a relatively effortless manner, and where synchronization between participants seems to occur naturally. This is facilitated by the number of channels we have at our disposal to convey information to our partners. These channels include the words spoken, intonation of the speech, hand gestures, facial expression, body posture, orientation and eye gaze. Although this interface between people consists of a number of elaborate biological devices that need to be coordinated at the spur of the moment, we don't seem to be burdened by the sophisticated control mechanisms. In fact, we are not even aware of the particular motion or vocal parameters that constantly need to be fed to our conversational engine. After a successful encounter with another human being, we leave with the general impression of the transaction but without all the specifics of our communicative performance. We can therefore say that our face-to-face interface with other people is usually invisible to us in a similar way as the cones and rods in our eyes. When we attempt to extend our capability to communicate with the world around us through the use of technological devices, we are introducing a synthetic layer that often places explicit constraints on our ability to conduct a natural conversation. This is true 1 for technology that mediates between people as well as technology that acts as an interface to conversational computer systems or agents. The last decade has seen efforts in virtual reality, ubiquitous computing and seamless media to make technology disappear and have information sharing and manipulation play the central role in a natural interaction among people and agents. But to even consider having the interface taking a seat with the invisible retinal tissues, one has to fully understand and alleviate the constraints that disrupt and hinder the flow of conversation. Historically, studying interfaces from the perspective of the human user has been an interest of the Media Lab. I believe that this area of study is necessarily in the province of research in the Media Lab, for the field of Media Arts and Sciences is thought of as exploring the technical, cognitive, and aesthetic bases of satisfying human interaction as mediated by technology1. State of the art Transmission of presence In 1980 the Architecture Machine Group demonstrated a radical system for extending the reach of human conversational abilities. The system was dubbed "Talking Heads" and was basically a video conferencing system where the live image of each participant was projected into the hollow sculpture of a head. The sculpture could swivel and pivot (Figure 1), to indicate gaze direction and nodding as detected on the sender's end. If such heads were carefully arranged around each participant, one could actually generate 1 From the MAS "General Information for Applicants" brochure 2 Figure1: A live video was projected on a sculptured head that swiveled a strong illusion of presence (Brand 1987). Although this approach has not been pursued further as a practical solution to teleconferencing, many different videoconference hybrids have attempted to extend beyond the basic video and voice delivery. Some support a shared workspace, such as the ClearBoard system (Ishii and Kobayashi 1992) (Figure 2) or add a sense of continuous group awareness such as in the Portholes project (Dourish and Bly 1992). Figure 2: Two people working through the ClearBoard There are three main problems that make systems based on streaming video difficult to use for transmitting presence. The first one is that it requires a lot of bandwidth to send a high quality live picture at a frame rate that captures all conversational motion such as quick glances or nods. Some research effort is going into finding ways to parameterize human face motion so that only changes in particular face features need to be sent (MPEG-4 for example) and we can also expect this problem to diminish as available bandwidth increases. But the second problem remains: the user on the transmitting end is living in a space that is often drastically different than the space surrounding that user's image on the receiving end. The user's behavior when interpreted on the receiving side does not always make sense and can in some cases be misleading. The third problem is scaling. This problem is in fact related to the second problem where it is clear that combining video images of multiple people is going to cause a lot of confusion unless the images of the participants are carefully placed around the room (such as in the Talking Heads demo). But then you are stuck with a fixed number of participants that all need to have exactly the same setup. An alternative to using streaming video is to use a graphical representation, or an avatar, on the receiving end, directly or indirectly controlled by the transmitting user. Avatars have been used in Distributed Virtual Environments (DVEs) to represent soldiers in a 3 virtual battlefield (the majority of such projects are related to DARPA's SIMNET or the various multi-player video games) or users in on-line chat systems. The high-end versions of such systems drive the avatar's motion by tracking the user's movements and immerse the user in the avatar's world through head-mounted displays (thus solving the space ambiguity presented above). Tracking the user's facial expression and eye movement is a hard problem and therefore even these high-end Virtual Reality systems lack adequate fidelity for having a natural conversation. Low-end avatar-based systems (such as all the commercial graphical chat systems) usually require users to manipulate their avatars through keyboards, mice or joysticks. This introduces a new problem: How do you control a fully articulated figure with button presses, menu selections or stick movements? Furthermore, in light of the previous discussion about the invisibility of the human interface, how can users possibly recreate the appropriate communicative behaviors explicitly when most of what happens during a conversation is spontaneous and even involuntary? The issue that keeps coming up here is the one of behavior mapping. That is, given a local user and some transmitted presence of that same user, how do we map the local behavior onto the remote representation so that it can be appropriately interpreted on the remote side? This mapping should take into account variability in the number of participants and should not require each user to master the art of puppetry. I believe that the solution to this problem lies in how the image on the receiving end is composed. The avatar should not mimic precisely what the user is doing, but use its knowledge of the perceived social situation, the user's communicative intention and some basic psychosocial competencies to automatically render appropriate communicative behavior. This solution requires the development of computational models that describe and predict communicative behavior. By researching the fields of conversation and discourse analysis, linguistics, sociology and cognitive sciences, I believe we can construct models that can help us attack the mapping problem. 4 Studies of human communicative behavior have seldom been considered in the design of believable avatars. Significant work includes Judith Donath’s Collaboration-at-a-Glance (Donath 1995), where an on-screen participant’s gaze direction changes to display her attention, and Microsoft’s Comic Chat (Kurlander et al. 1996), where illustrative comic-style images are automatically generated from the interaction (Figure 3). In Collaboration-at-a-Glance the users lack a body and the system only implements a few functions of the head. In Comic Chat, the conversation is broken into discrete still frames, excluding possibilities for things like real-time backchannel feedback and subtle gaze. For my Master's thesis here at the Media Lab titled "Autonomous Communicative Behavior in Avatars" I built a working prototype of a Distributed Virtual Environment, BodyChat (Vilhjálmsson 1997), in which users are represented by cartoon-like 3D animated figures. Interaction between users is allowed through a standard text chat interface. The new contribution of that work was that visual communicative signals carried by gaze and facial expression were automatically animated, as well as body functions such as breathing and blinking. The animation was based on parameters that reflect the intention of the user in control as well as the text messages that were passed between users. For instance, when you approach another avatar, you would see from its gaze behavior whether you were invited to start a conversation, and while you speak your avatar would take care of animating its face and to some extent the body (Figure 4). In Figure 4: Facial expression is automatically generated to accompany a text message in BodyChat 5 particular it animated functions such as salutations, turn-taking behavior and back channel feedback. Humanoid agents An issue that is closely related to the transmission of presence is the construction of a synthetic presence. In this case there is not a user on the other end of the line, but a computer. As a number of researchers have pointed out, there are times when users may benefit from a conversational system that allows them to have a face-to-face conversation with an intelligent agent (Laurel 1990, Thorisson and Cassell 1996). Many research groups around the world are looking into the various aspects of natural conversational interfaces, but only a few have actually constructed a fully animated multi-modal interface agent. The first system to fluidly employ speech, gaze and some gesture in the interaction with a humanoid agent is Gandalf (Figure 5), a prototype agent built on top of an Figure 5: A user interacting with Gandalf, a humanoid agent architecture called Ymir. The architecture is based on a computational model of psychosocial dialogue expertise and supports the creation of interfaces that afford full-duplex, real-time face-to-face interaction between a human and an anthropomorphized agent (Thorisson 1996). Other multi-modal agent research projects include the Persona project at Microsoft Research (Ball et al. 1995) and the Multi-modal Adaptive Interfaces project at the Media Lab (Roy and Pentland 1997). 6 Future contribution Future transmission of presence Building autonomy into an avatar that represents a user brings up many interesting issues. With the BodyChat system described above, I introduced an approach rather than a solution. This invites further research, both to see how well the approach can be applied to more complex situations and how it can be expanded through integration with other methods and devices. The following two sections elaborate on two different aspects of expansion. The first deals with the capabilities of the avatar and the second with the monitoring of the user’s intentions. Avatar behavior The MS thesis only started to build a repertoire of communicative behaviors, beginning with the most essential cues for initiating a conversation. It is important to keep adding to the modeling of conversational phenomena, both drawing from more literature and, perhaps more interestingly, through real world empirical studies conducted with a particular domain in mind. Behaviors that involve more than two people should be carefully examined and attention should be given to orientation and the spatial formation of group members. The humanoid models in BodyChat are simple and not capable of carrying out detailed, co-articulated movements. In particular, the modeling of the arms and hands needs more work, in conjunction with the expansion of gestural behavior. User input An issue that did not get a dedicated discussion in my thesis, but is nevertheless important to address, is the way by which the user indicates intention to the system. Because, only when the user's intention is clear, can the avatar automatically select the most appropriate behavior for the given situation. BodyChat makes the user point, click and type to give clear signals about intention, but other input methods may allow for more subtle ways. For example, if the system employed real-time speech communication 7 between users, parameters, such as intonational markers, could be extracted from the speech stream. Cameras could also gather important cues about the user’s state. This gathered information would then be used to help constructing the representation of the user’s intentions. Other ways of collecting input, such as novel tangible interfaces and methods in affective computing, can also be considered. Future humanoid agents Clearly creating a synthetic communicative character is a major undertaking and the current state-of-the-art only represents the first brave steps in that direction. The objective with Gandalf was primarily to demonstrate that a fully reactive multi-modal interaction loop between a user and a character was possible and that communicative non-verbal behaviors were crucial to making that interaction fluid. But the interaction itself was limited to a few canned question-response pairs and only a few recognized and generated behaviors. We have already started work on the next generation of a humanoid agent where the emphasis will be on allowing a more flexible conversation through expanded understanding and generation modules. We are also replacing a cumbersome user body tracking suit with computer vision allowing people to walk right up to the agent and start interacting without having to dress up in the agents eyes. Another expansion involves giving the agent a full upper body with gesturing arms, whereas the earlier version only had the head and a floating hand showing. All these improvements work towards the goal of allowing life-like interaction with the agent. Alongside the technical improvements, we keep building up our repertoire of communicative behavior models, acquired through literature research, empirical studies and iterative design. 8 Ramification Presence in Cyberspace In the novel Neuromancer, Science-fiction writer William Gibson let his imagination run wild, envisioning the global computer network being a large distributed virtual environment, much like a parallel dimension, into which people could jack via neural implants (Gibson 1984). This was a shared graphical space, defying the laws of a physical reality, allowing people to interact with remote programs, objects and other people as if they were locally present. This novel stirred many minds and is frequently referred to as the origin of the term Cyberspace. Although we are currently using monitors and keyboards to jack into the Internet, shared three dimensional worlds are a reality and provide a compelling space for interaction. The idea of being able to jump into an extra dimension that breaks loose of geological constraints has been appealing to a variety of people. For example, multi-national companies that would like their employees in different locations co-operate on a project would definitely benefit from systems that facilitated conversational flow and natural feedback in a virtual meeting through intelligent avatars. Another large market that would embrace technologies that advance the transmission of presence is the entertainment business. On-line gaming is already a phenomenon spreading like wildfire, but sadly the only mode of communication supported by most current systems is the roar of a gun poised to kill. This is even true for games that encourage team play! These games already provide captivating virtual worlds to inhabit and they often represent users as avatars, adapted for the environment and the particular game requirements. Empowering these avatars with communicative abilities would provide for a much richer experience and allow for a much wider range of on-line recreational activities. 9 Conclusion This paper has discussed how a machine should be able to imitate human communicative behavior, both to facilitate communication between humans and to allow them to have a face-to-face conversation with an autonomous agent. Whereas humans are dynamic and spontaneous and interface effortlessly and seamlessly with each other, a machine is only capable of carrying out behavior that has been explicitly coded into it beforehand. If we want that machine to provide an interface that is as invisible and natural as our own conversational mechanisms, we need to empower it with a range of important behaviors we take for granted in people. Because we take these behaviors for granted and because they are mostly invisible to our consciousness, we need to methodologically study human interaction to unveil what goes on. Fields such as conversation and discourse analysis as well as cognitive sciences give us important tools for conducting this search for patterns in conversational behavior. Combined with engineering disciplines, computer science and visual design, we can expect a fusion that gives birth to a new generation of machines that come closer to having a social awareness than any previous systems. The MIT Media Lab is a place that nurtures a fusion of this sort and is therefore the perfect incubator. 10 References (Ball et al. 1995) Ball, G., Ling, G., Kurlander, D., Miller, J., Pugh, D., Skelly, T. Stankosky, A., Thiel, A., Dantzich, M., Wax, T. (1995). Lifelike Computer Characters: the Persona project at Microsoft Research. Unpublished technical report (Brand 1987) Brand, S. (1987). The Media Lab: Inventing the future at MIT. Viking. London. (Donath 1995) Donath, J. (1995). The Illustrated Conversation. Multimedia Tools and Applications, 1, 79-88. (Dourish and Bly 1992) Dourish, P. and Bly, S. (1992). Portholes: Supporting Awareness in a Distributed Work Group. Proceedings of Conference on Human Factors in Computing Systems (CHI '92), ACM SIGCHI, California, 3-7 May 1992 (Gibson 1984) Gibson, W. (1984). Neuromancer. New York: Ace Books. (Ishii and Kobayashi 1992) Ishii, H. and Kobayashi, M., ClearBoard: A Seamless Media for Shared Drawing and Conversation with Eye-Contact. Proceedings of Conference on Human Factors in Computing Systems (CHI '92), ACM SIGCHI, Monterey, 3-7 May 1992, pp. 525-532 (Kurlander et al. 1996) Kurlander, D., Skelly, T., Salesin, D. (1996). Comic Chat. Proceedings of SIGGRAPH ‘96. (Laurel 1990) Laurel, B. (1990). Interface Agents: Metaphors with Character. The Art of Human-Computer Interface Design. Ed. Laurel. B. Apple Computer, Inc. (Thorisson 1996) Thorisson, K. R. (1996). Communicative Humanoids: A Computational Model of Psychosocial Dialogue Skills. Ph.D. Thesis. MIT Media Lab. (Thorisson and Cassell 1996) Thórisson, K.R., J. Cassell (1996) Why Put an Agent in a Human Body: The Importance of Communicative Feedback in Human-Humanoid Dialogue. (abstract) In Proceedings of Lifelike Computer Characters '96, Snowbird, Utah, 44-45. (Vilhjálmsson 1997) Vilhjálmsson, H. H. (1997). Autonomous Communicative Behaviors in Avatars. MS Thesis MIT Media Lab. 11