Approximate Shortest-Path Computation in Networks
advertisement

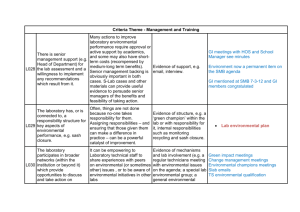
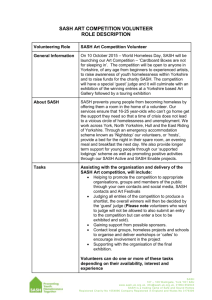
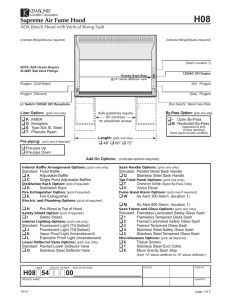
NII International Internship Project: Approximate Shortest-Path Computation in Networks Supervisor: Michael HOULE, Visiting Professor Scheduling and other optimization problems in transportation networks often involve the computation of shortest paths within an underlying graph structure, where nodes represent locations and edges represent the transport links between them. Each edge is assigned a weight denoting the cost of using the transport link. Classical methods for computing shortest paths, such as Dijkstra’s algorithm [1], often require many if not most of the graph nodes to be visited, leading to substantial computation costs when the network is large. However, some optimization heuristics may still perform well when the paths computed are not necessarily the shortest possible. The overall objective of this project is to design and implement an efficient and effective search structure for approximate shortest-path computation in edge-weighted graphs, by adapting an existing practical index for approximate similarity queries of large multi-dimensional data sets: the spatial approximation sample hierarchy (SASH) [2]. A SASH is a multi-level structure of random samples, recursively constructed by building a SASH on a large randomly selected sample of data objects, and then connecting each remaining object to several of their approximate nearest neighbors from within the sample. Queries are processed by first locating approximate neighbors within the sample, and then using the pre-established connections to discover neighbors within the remainder of the data set. The SASH index relies on a pairwise distance measure, but otherwise makes no assumptions regarding the representation of the data. The SASH has been shown to be effective for query-by-example operations on protein sequence, image, and text data sets, including one consisting of more than 1 million vectors spanning more than 1.1 million terms – far in excess of what spatial search indices can handle efficiently. For sets of this size, the SASH can return a large proportion of the true neighbors roughly 2 orders of magnitude faster than sequential search. The specific goals of this project are: To adapt the hierarchical SASH construction to graph data, where the multi-level structure of random samples is replaced by a hierarchy of induced subgraphs of the full weighted graphs. To implement, test, and evaluate the approximate shortest path structure against other techniques (including Dijkstra’s algorithm). 3. References [1] T. H. Cormen, C. E. Leiserson, R. L. Rivest and C. Stein, Introduction to Algorithms, 2nd ed., MIT Press, 2001. [2] M. E. Houle and J. Sakuma, "Fast approximate similarity search in extremely high-dimensional data sets", in Proc. 21st IEEE International Conference on Data Engineering (ICDE 2005), pp. 619-630, Tokyo, Japan, 2005.