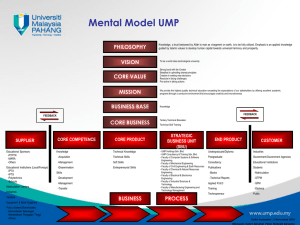
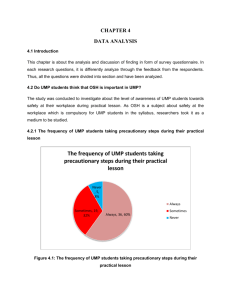
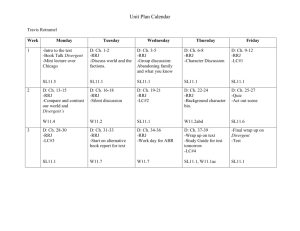
Home Work9
advertisement

V I L L A N O V A U N I V E R S I T Y
Department of Electrical & Computer Engineering
ECE 8412 Introduction to Neural Networks
Homework 09 Due 15 November 2005
Chapter 10
Name: Santhosh Kumar Kokala
Complete the following and submit your work to me as a hard copy.
You can also fax your solutions to 610-519-4436.
Use MATLAB to determine the results of matrix algebra.
1. E10.3
Suppose that we have the following two reference patterns and their targets:
1
1
p1 , t1 1, p 2 , t1 1.
1
1
In Problem P10.3 these input vectors to an ADALINE were assumed to occur with equal probability.
Now suppose that the probability of vector p1 is 0.75 and that the probability of vector p2 is 0.25. Does
this change the mean square error surface? If yes, what does the surface look like now? What is the
maximum stable learning rate?
A. First we need to calculate the various terms of the quadratic function. We know that the performance
index can be written as
F (x) c 2x T h x T Rx.
Therefore we need to calculate c, h and R.
The probability of each input occurring is 0.75 and 0.25, so the probability of each target is also 0.75 and
0.25. Thus the expected values of the square of the targets is
c E t 2 1 0.75 1 0.25 1.
2
2
In a similar way, the cross-correlation between the input and the target can be calculated:
1
1 0.5
h Etz 0.751 0.25 1 .
1
1 1.0
Finally, the input correlation matrix R is
R E zz T p1p1T (0.75) p 2 p T2 (0.25)
1
1
1.0 0.5
0.75 1 1 0.25 1 1
.
1
1
0.5 1.0
Therefore the mean square error performance index is
F x c 2x T h x T Rx
1 2w1,1
0.5
w1, 2 w1,1
1.0
1.0 0.5 w1,1
w1, 2
0.5 1.0 w1, 2
1 w1,1 2w1, 2 w12,1 w1,1 w1, 2 w12, 2 .
The Hessian matrix of F (x) , which is equal to 2R is given by
1.0 0.5 2 1
A 2R 2
0.5 1.0 1 2
Calculating the eigenvalues of A using the Matlab function ‘eig(A)’ we get 1,3 as the eigenvalues.
Therefore the contours of the performance surface will be elliptical. To find the center of the
contours (the minimum point), we need to solve the equation
1.3333 0.6667 0.5 0
x * R 1h
.
0.6667 1.3333 1.0 1
Thus we have a minimum at w1,1 0, w1, 2 1 . The resulting mean square error performance is shown in
the below figure
-2-
The maximum stable learning rate is given by
2
max
-3-
2
0.6667
3
2. E10.4
In this problem we will modify the reference pattern p2 from the problem P10.3:
1
1
p1 , t1 1, p 2 , t1 1.
1
1
(i). Assume that the patterns occur with equal probability. Find the mean square error and sketch the
contour plot.
A. First we need to calculate the various terms of the quadratic function. We know that the performance
index can be written as
F (x) c 2x T h x T Rx.
Therefore we need to calculate c, h and R.
The probability of each input occurring is 0.5 and 0.5, so the probability of each target is also 0.5 and 0.5.
Thus the expected values of the square of the targets is
c E t 2 1 0.5 1 0.5 1.
2
2
In a similar way, the cross-correlation between the input and the target can be calculated:
1
1 1
h Etz 0.51 0.5 1 .
1
1 1
Finally, the input correlation matrix R is
R E zz T p1p1T (0.5) p 2 p T2 (0.5)
1
1
1 1
0.5 1 1 0.5 1 1
.
1
1
1 1
Therefore the mean square error performance index is
F x c 2x T h x T Rx
1 2w1,1
1
w1, 2 w1,1
1
1 1 w1,1
w1, 2
1 1 w1, 2
1 2w1,1 2w1, 2 w12,1 2w1,1 w1, 2 w12, 2 .
The Hessian matrix of F (x) , which is equal to 2R is given by
-4-
1 1 2 2
A 2R 2
1 1 2 2
Calculating the eigenvalues of A using the Matlab function ‘eig(A)’ we get 0,4 as the eigenvalues.
Therefore the contours of the performance surface will be elliptical. The resulting mean square error
performance is shown in the below figure
-5-
(ii). Find the maximum stable learning rate.
A. The maximum stable learning rate is given by
2
max
2
0.5
4
(iii). Write a MATLAB M-file to implement the LMS algorithm for this problem. Take 40 steps of the
algorithm for a stable learning rate. Use the zero vector as the initial guess. Sketch the trajectory on the
contour plot.
Matlab Code:
%% Clear the screen and all variables
clear all;
clc;
%% Assuming W=[0 0] as our initial guess
W=[0 0];
disp('Starting with an initial guess vector of W=[0 0]')
%% Our inputs and target outputs
p1 = [1; 1];
t1 = 1;
p2 = [-1;-1];
t2 = -1;
P = [p1 p2];
T = [t1 t2];
%% Assuming a learning rate less than 1/lamda(max) =0.5
lr = 0.1;
%% Iterating through the loop for 40 times
for k = 1:40
a = W*p1;
e1 = t1 - a;
W = W + lr*e1*p1';
disp(W)
a = W*p2;
e2 = t2 - a;
W = W + lr*e2*p2';
disp(W)
end
Output:
After running this LMS algorithm for 40 iterations our weight vector converges to [0.5 0.5].
-6-
Matlab Code for sketching the trajectory on the contour plot.
%% Sketching the trajector on the contour plot
[W11,W12] = meshgrid(weight(:,1),weight(:,2));
x = [W11; W12];
%% Fx calculated in the previous section
Fx = 1 - 2*W11 - 2*W12 +2*W11.^2 + 2*W11.*W12 + 2*W12.^2;
%% Plotting the trajectory on the contour
subplot(2,1,1), mesh(W11,W12,Fx), set(gca,'ydir','reverse')
grid, xlabel('w11'), ylabel('w12'), zlabel('F(x)')
subplot(2,1,2), c = contour(W11,W12,Fx),
clabel(c), xlabel('w11'), ylabel('w12'), set(gca, 'ydir', 'reverse'), grid
Contour Plot:
F(x)
0.45
0.4
0.35
0.1
0.2
0.3
0.4
0.5
0.1
w12
0.2
w11
0.46
0.440.42
0.4
0.38
0.25
w12
0.3
0.5
0.4
0.3
0.2
0.38
0.35
0.4
0.4
0.42
0.44
0.46
0.34
0.36
0.45
0.38
0.2
0.25
0.38
0.3
0.48
0.35
w11
-7-
0.4
0.45
(iv) . Take 40 steps of the algorithm after setting the initial values of both parameters to 1. Sketch the
final decision boundary.
A. When the above algorithm is run with initial parameters set to 1 the algorithm still converges to
[0.5 0.5]. The final decision boundary is shown in the below figure.
(v). Compare the final parameters from parts (iii) and (iv). Explain your results.
A. If we run the algorithm with zero initial guess or with all 1’s our weight vector converges to the same
point.
-8-
3. E10.5
We again use the reference patterns and targets from Problem P10.3, and assume that they occur with
equal probability. This time we want to train an ADALINE network with a bias. We now have three
parameters to find: w1,1 , w1,1 , b
1
1
p1 , t1 1, p 2 , t1 1.
1
1
(i). Find the mean square error and the maximum stable learning rate.
A. First we need to calculate the various terms of the quadratic function. We know that the performance
index can be written as
F (x) c 2x T h x T Rx.
Therefore we need to calculate c, h and R.
w
p
x 1 , z
1
b
The probability of each input occurring is 0.5 and 0.5, so the probability of each target is also 0.5 and 0.5.
Thus the expected values of the square of the targets is
c E t 2 1 0.5 1 0.5 1.
2
2
In a similar way, the cross-correlation between the input and the target can be calculated:
1
1 0
h Etz 0.511 0.5 1 1 1 .
1
1 0
Finally, the input correlation matrix R is
R E zz T p1p1T (0.5) p 2 p T2 (0.5)
1
1
1 0 1
0.511 1 1 0.5 11 1 1 0 1 0.
1
1
1 0 1
Therefore the mean square error performance index is
F x c 2x T h x T Rx
1 2w1,1
w1, 2
0
b1 w1,1
0
-9-
w1, 2
1 0 1 w1,1
b0 1 0. w1, 2
1 0 1 b
1 2w1, 2 w12,1 2bw1,1 w12, 2 b 2 .
The Hessian matrix of F (x) , which is equal to 2R is given by
1 0 1 2 0 2
A 2R 20 1 0 0 2 0
1 0 1 2 0 2
Calculating the eigenvalues of A using the Matlab function ‘eig(A)’ we get 0,2,4 as the eigenvalues.
2
0.5
max 4
(ii). Write a MATLAB M-file to implement the LMS algorithm for this problem. Take 40 steps of the
algorithm for a stable learning rate. Use the zero vector as the initial guess. Sketch the final decision
boundary.
The maximum stable learning rate is given by
2
A. Matlab Code:
%% Clear the screen and all variables
clear all;
clc;
%% Set W = [0 0 0] in the command window before running LMS.
W=[0 0];
disp('Starting with an initial guess vector of W=[0 0]')
%% Our inputs and target outputs
p1 = [1; 1];
t1 = 1;
p2 = [1;-1];
t2 = -1;
P = [p1 p2];
T = [t1 t2];
%% Assuming a learning rate less than 1/lamda(max) =0.5
lr = 0.3;
%% Assuming an initial bias of b=0
b=0;
%% Iterating through the loop for 40 times
for k = 1:40
a = W*p1+b;
e1 = t1 - a;
W = W + lr*e1*p1';
b=b+lr*e1;
disp([W,b]);
a = W*p2+b;
e2 = t2 - a;
W = W + lr*e2*p2';
b=b+lr*e2;
disp([W,b]);
end
- 10 -
Output:
When the above M-file is run the weight vector converges to [0 1] and the bias converges to 0.
w 0 1, b 0.
(iii). Take 40 steps of the algorithm after setting the initial values of all parameters to 1. Sketch the final
decision boundary.
A. When the algorithm is run with the initial values set to 1 the weight vector converges to [0 1] and the bias
converges to 0.
(iv). Compare the final parameters and the decision boundaries from parts(iii) and (iv). Explain your results.
A. If we run the algorithm with zero initial guess or with all 1’s our weight vector converges to the same
point and we get the same decision boundary.
- 11 -