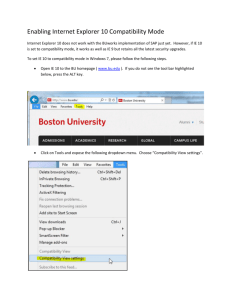
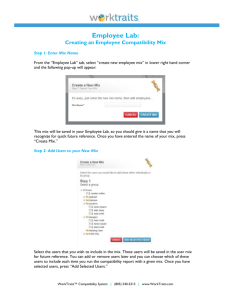
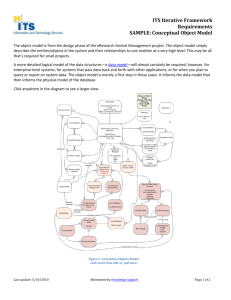
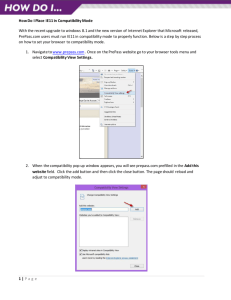
Requirements for DC V2.0
advertisement

Hi Stu, Here's my notes from the breakout session on V2 requirements. This breakout group met Tuesday afternoon. Before the meeting I had talked briefly with Cliff and Cecilia, the two basic requirements we thought we had going into the meeting were: 1) Ease of migration (aka backward compatibility with DC 1.x). 2) Avoid second-system syndrome (more of a goal than a requirement, but I digress). But when the group met and started considering the basic questions of "what problem are we trying to solve" and "what are the constraints on the solution" we quickly found that we do not have a crisply defined problem to solve. This lack of specificity in the problem description is the first order of business that needs to be addressed in the 2.0 effort. The initial purpose of the Dublin Core was "simple resource discovery". We have noted strong push-back on all three of these words. Some of the discovery scenarios that have been postulated are anything but simple. We see a desire to describe 'resources' that are a long way from the initial conception of resources as "document-like objects". Finally, purposes such as administration and rights-clearance are being added to the original purpose of 'discovery'. At the same time, the group was not able to articulate a crisp boundary between what was and was not in the scope of the 2.0 effort. The core is very general and can be used to describe a wide range of things. Using it to describe people is one example of pushing it to an extreme. So, "effectiveness" is an important notion. The DC is most effective at describing web resources that are 'document like objects' that were 'born digital'. Describing digital renditions of physical objects, or describing objects that are not like documents, is a less effective use of the DC. We can imagine a bell curve centered over "DLOs" and tailing off as we describe things that are not like documents. The abstract vs. concrete nature of a resource is another axis for effectiveness. If we go with the notion of abstract works like "Hamlet", the DC can describe them, but less effectively than if we were describing Project Gutenberg's particular instance of Shakespeare's playscript. Events, People, Places, Services, Collections, ... are some of the things people may want to describe as part of DC 2.0 records and are outside the most effective use of DC 1.0 Some of the problems that we are trying to solve were vaguely articulated: 1) interoperability between different communities 2) lessen the ambiguity of the 1.x definitions and usages 3) sounder logical model than 1.x 4) retain purpose of simple resource discovery Listing the constraints that 2.0 would have to live under seemed to be an easier job. We very quickly listed: 1) Compatibility with 1.x descriptions (where "compatibility" is only loosely defined). 2) Compatibility with the Warwick framework. (RDF and XML namespaces appear to be a reasonable implementation path that makes this feasible to meet). Random notes: One question that arose was just what we meant when we said "interoperable" descriptions. Does that mean anything more than machine-translatable field identifiers? It may be very important to reaffirm the "optional" and "repeatable" principles of the DC, or to explicitly repudiate them. We were also able to come up with a negative requirement: Perfectly reversible transformations between 1.0 and 2.0 records are explicitly NOT a requirement. Explicit Conceptual Model: A fair amoun tof our time was spent talking about explicit conceptual models. "David's green boxes" is one proposal for a conceptual model behind the Dublin Core. A lot of current thinking (e.g. IFLA, Delsey) about bibliographic description is based on such conceptual models. This seems to be inspired in very great measure by techniques from the computer science community such as Entity-Relationship modeling and Object-Oriented modeling. Basing DC 2.0 on an explicit conceptual model may present a problem with preserving backward compatibility. 2.0 would be considered NOT compatible with 1.x if there was any 1 element in 1.0 that would be split into 2 or more elements in 2.0 and there was no algorithmic procedure for deciding the proper 2.0 element to use. As an example, assume that 2.0 has an explicit notion of "abstract work". DC 1.0 "Creator" would encompass both creators of abstract works, such as William Shakespeare for Hamlet, and creators of concrete instances of the work, such as Kenneth Branaugh for one of the many movies of Hamlet. (Now, whether this is a practical problem is another story. If the percentage of DC 1.0 records that describe abstract works is low, then this is not a real problem). Summary: The major conclusion of the breakout group was that the DC 2.0 effort should begin by stating the purpose of the change, defining the problem that we are trying to solve, and taking a look at the COSTS and the BENEFITS of the change form 1.x to 2.0. This analysis might begin by considering the uses of the Dublin Core. A couple of examples: 1) We expect most DC descriptions to be obtained from more detailed information. For example, a down-translation of information from a MARC catalog. 2) We expect users to start queries with DC fields. Then, if and when their search brings them into a particular domain, their search tools will start showing more of the domain-specific information that does not have a natural fit to the core. A second conclusion was that we should not introduce feature creep into the core to address problems that are handled by the Warwick Framework. Ron Daniel Jr. DATAFUSION, Inc. 139 Townsend Street, Ste. 100 San Francisco, CA 94107 415.222.0100 fax 415.222.0150 rdaniel@datafusion.net http://www.datafusion.net