Machine Learning Designs for Artificial Histone Acetyltransferases
advertisement

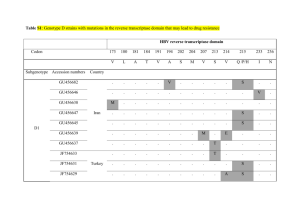
Machine Learning Designs for Artificial Histone Acetyltransferases Man Xia Lee, Aye Sandar Moe1, Susheel Kumar Gunasekar, Kinjal Mehta, Zhiqiang Liu, Natalya Voloshchuk, Jin K. Montclare, Phyllis Frankl and Lisa Hellerstein Polytechnic Institute of NYU http://cis.poly.edu/~amoe/mlpd Abstract: Although, in vivo incorporation of unnatural amino acids can be used to improve protein stability; there is a trade off. Higher stability of the protein may lead to loss in activity. One way to improve function is to employ machine-learning algorithms to identify proteins that have enhanced activity. Our target protein Tetrahymena GCN5 (tGCN5), a member of the family of Histone Acetyltransferases (HAT), acetylates histones at specific lysine residues, enabling transcriptional regulation. Experimental data have shown an increase in stability of the protein but loss in activity with the incorporation of ortho-fluorophenylalanine (oFF) into tGCN5. Using information from biochemical and structural data, we identify 11 potential mutants that may lead to improve function. We investigate the structure and function of the tGCN5 mutants in the conventional and fluorinated contexts. Moreover, we seek to generate optimized variants bearing these mutants with the help of machine learning algorithms. Introduction: Histone Acetyltransferases (HAT) are proteins that acetylate the lysine residue of the histone proteins on the N-terminal tails, enabling transcriptional regulation (Figure 1 A) [1]. When the positive charged lysine residue of the histone protein is acetylated, the 1 Man Xia Lee and Aye Sandar Moe were supported by the CRAW Multidiciplinary Research Opportunities for Women (M-ROW) program. Additional support was provided by the Othmer Institute, Polytechnic University. histone becomes neutralized and the negative charged DNA is more accessible for transcription to occur [2]. The HAT protein Tetrahymena GCN5 (tGCN5) is comprised of a mixture of alpha-helices and beta-sheets [3] that catalyze the reaction involving the transfer of the acetyl group from the acetyl-coenzyme A [4]. A) B) F F OH H2N O F F OH H2N O oFF OH H2N OH H2N O mFF Figure 1. A) Crystal structure of tGCN5: Nine phenylalanine residues are shown in purple. B) Structure of phenylalanine (F), ortho-fluorophenylalanine (oFF), meta-fluorophenylalanine (mFF), and parafluorophenylalanine (pFF). Previously, Montclare and coworkers incorporated the fluorinated phenylalanine (oFF, mFF and pFF) into tGCN5 in a residue specific fashion (Figure 1 A, B). According to experimental data, in vivo incorporation of oFF has shown an increase in thermal stability. Although tGCN5 bearing oFF displays improved thermal stability, there is a decrease in activity. Based on biochemical data by numerous groups, we identified 15 residues that are important in the activity and stability of the protein [3-8] (Table 1, O pFF Figure 2). With this set of mutants, we plan to create new variants with combined mutations to improve protein function. Table 1. Summary of mutations and their significance. A) V 86 T K 87 R F 90 Y V 98 A I 99 V L 100 I I 107 V F 112 R Q 114 L Structurally similar Alignment analysis: conserved Alignment analysis: conserved Important role in protein stability [6, 8] Important role in protein stability [6, 8] Important role in protein stability [6, 8] Important role in protein stability [6, 8] Alignment analysis: conserved Important in raising the pKa for a more hydrophobic area[6, 7] A 121 T A 130 S R 140 H K 144 H Alignment analysis: conserved Alignment analysis: conserved Alignment analysis: conserved Important role in catalysis [6, 7] F 145 L Important role in catalysis [6, 7] Y 192 A Important role in catalysis [6, 7] Figure 2. Structure of tGCN5 with mutations highlighted in green are the conserved residues [6], orange are residues that are critical for catalysis [6], red residues are important for protein stability [6, 7], and blue residue is an isoteric change. To reduce the time and cost investigating a combination of all 15 residues mentioned in Table 1 for a more active tGCN5, we based our design on the theory of Design of Experiments. The Placket Burman design is widely used to generate a set of Table 2. Placket-Burman Design. The mutant(s) represented X1-X11. The ones with only single mutation are X2, X4-X9 and X11. Those that consisted of two mutations are X1 and X10. Only X3 contained three mutants. manageable experiments [9]. Because some of the mutations were adjacent to each other Table 2, we chose to combine those adjacent mutations and designated them as a single mutation. Using the Placket Burman design, we produced twelve variants bearing five to eleven mutations to test (Table 2). Seq# 1 2 3 4 5 6 7 8 9 10 11 12 X1 86 V T T T 87 K R R R X2 90 F Y Y Y Y Y Y X3 98 V A A A A A A 99 I V V V V V V 100 L I I I I I I X4 107 I V V V V V V X5 112 F R R R R R R X6 114 Q L L L L L L X7 121 A T T T T T T X8 130 A S S S S S S X9 140 R H H H H H X10 144 K H H H H H H X11 145 192 F Y L A L A A L A L L A L A To identify which variants to test next, we intend to employ machine learning algorithms in our protein design. Using genetic engineering techniques, we are generating the protein variants and measuring the activities relative to the starting wildtype tGCN5 and with the incorporation of oFF. Machine-learning algorithms can be employed to predict the next set of variants with an improved combination of substitutions [10]. By this approach, we hope to isolate artificial tGCN5 variants with improved activity for the target histone peptide while maintaining improved stability. Active Learning Active learning is a type of supervised learning technique where the classifier is built by iteratively choosing the most informative data from a superset of unlabelled data. This type of learning method is useful for experiments where data is expensive. Based on the available data, a classifier is built. New data points are then chosen based on this classifier. The chosen data points are then added to the training file to build another classifier which is expected to be better than the previous one. We explored uses three active learning methods discussed by Danziger et al.[11], minimal marginal hyperplane, maximal marginal hyperplane, and maximum curiosity. Minimal Marginal Hyperplane [11] Minimal Marginal Hyperplane chooses the next data point by the data point’s proximity to the decision boundary. The assumption here is that the points that are closest to the decision boundary are those the most informative data. Therefore, the classifier expects to achieve the desired learning accuracy faster by making use of this close, unclassified data. Maximal Marginal Hyperplane [11] Maximal Marginal Hyperplane is similar to Minimal Marginal Hyperplane, except that the next furthest point from the hyperplane is chosen to be the next data point. Maximum Curiosity [11] Maximum Curiosity chooses the data point by giving each point a score and then picking the point which has the highest score. The formula to calculate the score of each data point is rt (tpt tnt ) ( fpt fpn ) (tpt fpt )( tpt fnt )( tnt fpt )( tnt fnt ) This method assumes each data point to be active and then calculate the score. Then, it takes the same data point and assumes it to be inactive and then calculate the score. The higher score among the two was chosen. Results and Discussion Comparison of Active Learning Techniques In order to determine the best active learning technique to use selecting tGcN5 variants, we compared the active learning techniques on a similar data set from a project by Liao et al [10]. Figure 3 shows the overall experiment design. Generally, the more the data, the more accurate the classifier will be. The active learning methods are intended to help gain the highest accuracy quicker. We generated two different initial training sets. We recorded the accuracy of the classifier as more data have been added. The following graph shows the accuracy level obtained by each method as more data points are added. Test Data Training data Weka[5] Classifier Accuracy Active Learning Label the new point Best Next Point Figure 3. Choosing the next data point using active learning Max Curiosity accuracy Comparison ( Run 2) Min HP 100 90 80 70 60 50 40 30 20 10 0 Random MaxHP 0 20 40 sizes 60 80 100 Figure 4: Comparison of data points chosen using active learning methods and random selection on the first run To make sure that we did not have a biased initial training set, another training set was chosen to be the starting set and the active learning methods were run again. Random accuracy(%) Comparison MaxHP MinHP 100 90 80 70 60 50 40 30 20 10 0 MaxCuriosity 0 20 40 sizes 60 80 100 Figure 5: Comparison of data points chosen using active learning methods and random selection on the second run The two different seed training file gives different accuracy value to start of with. In figure 4, the classifier improves its accuracy quickly. It was also shown that using active learning methods is actually better than random selection of data. For the second initial training file, the difference between random data selection and active learning methods is not significant. Among the three methods that have been tested, maximum curiosity seems to improve the classifier faster than the other two methods. When the experimental data on tGCn5 are available, we plan to use an active learning method to select additional protein variants. PCR amplification of each fragment In order to generate the designed variants bearing multiple mutations, we had to assemble the fragments bearing mutations. By using the primers containing the mutations, we were able to generate the fragments with the mutation (s) using PCR assembly [12]. PCR allowed the primers to anneal to the template DNA (tGCN5 gene) and amplify a fragment of the tGCN5 sequence. After amplifying all the fragments, we ran another PCR to anneal the individual fragments to each other to generate a full-length variant bearing the set of mutation, an example of sequence 10 shown in Figure 5. Sequence 8, 9, and 11 were also generated shown in Figure 6. The full-length variant will be restricted with the enzymes, Hind III and Bam HI, and cloned into the vector pQE30. Once we have our new construct, we will proceed to protein expression and do fluorescence assay. Figure 5: PCR amplified, example, variant 10 ( (ladder), mutant 1 (~150 bp), mutant 2 (~54 bp), mutant 3 (~48 bp), mutant 4 (~90 bp), mutant 5a and 5b (~212 bp), mutant 6 (~100 bp)) on a 2% DNA gel (left). The fragments are annealed and amplified (right). L 8 I----------------8-----------I I--------------9-----------I I------------11---------I 8 8 9 9 9 11 11 11 Figure 6: PCR alignment of sequence 8, sequence 9, and sequence 11. Protein expression of tGCN5 and single mutants of tGCN5 Protein expressions of wild-type tGCN5, F90Y, and A121T, gene in the plasmid pQE30 were transformed in a phenylalanine auxotrophic strain AFIQ. The protein expression was visualized on 12 % SDS PAGE Figure 7 A. The expressed proteins were purified on a 1 mL cobalt gel slurry (TALON® Metal Affinity Resin) with increasing concentration of imidazole shown on 12 % SDS PAGE Figure 7 B, C and D. From the SDS PAGE, the largest fraction of pure protein appeared in elution 4 (E4) for wild-type tGCN5 at 21 kDa (Figure 7 B). For F90Y and A121T, the largest fraction appeared in elution 2 (E2) and 3 (E3) (Figure 7 C and D). In Figure 7 B, there were impurities shown in E1-4 for F90Y which indicate that we need to optimize purification conditions. The largest fractions were subjected to dialysis for the removal of imidazole for fluorescent assay. -- WT-- -- F90Y -A 20 kDa L - + - + -- A121T -- + B L E1 E2 E3 E4 E5 21 kDa C L E1 E2 E3 E4 E5 D L 21 kDa E1 E2 E3 E4 E5 21 kDa Figure 7 A) SDS PAGE gel result of overexpressed protein at 21 kDa: L (Ladder), pre-induction (-) and overexpressed protein (+). SDS PAGE gel results of protein purification at 21 kDa: B) Wild-type tGCN5, C) F90Y, D) A121T: L (Ladder), E1 (elution 1), L2 (elution 2), E3 (elution 3), E4 (elution 4), E5 (elution 5). Fluorescent assay of tGCN5 and mutants Kinetic data for tGCN5 was determined using fluorometric assay which detects the enzymatic production of coenzyme A (CoA) as tGCN5 transfers the acetyl group from AcCoA to lysine on a peptide, H3p19. The fluorophore, 7-diethylamino-3-(4’maleinidylphenyl)-4-methylcoumarin (CPM), reacts with CoA generated in the acetyltransferase reaction giving a strong fluorescent emission at 465 nm (excitation wavelength is 365 nm) [1]. 5.9 µM tGCN5 and tGCN5 mutants were tested with different concentrations of H3p19 (1.2 mM, 0.6 mM, 0.3 mM. 0.15 mM, and 0.075 mM). The Line-Weaver Burke equation generated from the fluorescent assay was used to calculate Vmax, Kcat, and Km. Based on the data (Figure 8 A, B, C and Table 3), A121T appeared to have the highest turnover and specificity towards H3p19 compared to wild-type tGCN5 and F90Y. Wild-type tGCN5 was tested in triplicate whereas the mutants were tested only once. The Vmax, Kcat, and Km for wild-type tGCN5 were within the standard deviation. The observed large standard deviation might be due to the fact that each trial we did for the wild-type tGCN5 was performed at room temperature. We will need to repeat the experiment. A) Wild-type tGCN5 25 1/V(o) 20 15 10 5 y = 121.57x + 0.35 0 0 0.05 0.1 0.15 0.2 1/[H3] B) C) F90Y A121T 45 40 500 35 30 1/V(o) 600 1/V(o) 400 300 25 20 15 10 200 100 y = 874.58x + 197.01 y = 246.73x + 0.2883 5 0 0 0 0.05 0.1 1/[H3] 0.15 0.2 0 0.05 0.1 1/[H 3] 1/[H3] 0.15 0.2 Figure 8. Fluorescence assay results of: A. wild-type tGCN5. B.F90Y. C. A121T. Table 3: Line Weaver-Burke equation was used to determine kinetics of wild-type tGCN5 and mutants. WT tGCN5 F90Y A121T Vmax(mM/sec) 0.018 ± 0.025 1.14E-06 0.0035 Km (mM) 2.388 ± 3.321 0.001 0.8558 Kcat (Sec-1) 3.068 ± 4.226 0.001163 3.5274 Kcat/Km (Sec -1mM-1) 1.420 ± 0.247 1.162786 4.1217 Conclusion Wild-type tGCN5, F90Y and A121T were tested for activities using fluorescent assay. The experimental data showed that A121T exhibited better activity and highest turnover than wild-type tGCN5 and F90Y. Moreover, the wild-type tGCN5 Vmax, Kcat, and Km were successfully calculated. The samples will be tested further under ice for each trial to confirm experimental data. Site-directed mutagenesis on tGCN5 was carried out to create single mutations shown in Table 2 (X1- X10). Eight mutations were confirmed by DNA sequencing. We will repeat site-directed mutagenesis procedure for the other three (X3: V98A, I99V, L100I, X1: V86T, K87R, and X2: F112R) and send it for sequencing. The confirmed single mutations will be analyzed for stability or/and activity and compared to wild-type tGCN5. Once we have activity results from the protein variants shown in Table 1 and Table 2 with or without the incorporation of oFF, we will employ a machine-learning algorithm to design a set of variants, which we hope will have improved activity. Our machine learning experiments suggest that maximum curiosity will be the best active learning technique to use. In future work, we plan to explore variants of the active learning algorithms and different ways to model the feature space of the tGCN5 variants. References: 1. 2. 3. 4. Trievel, R.C., F.Y. Li, and R. Marmorstein, Application of a fluorescent histone acetyltransferase assay to probe the substrate specificity of the human p300/CBPassociated factor. Anal Biochem, 2000. 287(2): p. 319-28. Tanner, K.G., et al., Catalytic mechanism and function of invariant glutamic acid 173 from the histone acetyltransferase GCN5 transcriptional coactivator. J Biol Chem, 1999. 274(26): p. 18157-60. Rojas, J.R., et al., Structure of Tetrahymena GCN5 bound to coenzyme A and a histone H3 peptide. Nature, 1999. 401(6748): p. 93-8. Langer, M.R., et al., Modulating acetyl-CoA binding in the GCN5 family of histone acetyltransferases. J Biol Chem, 2002. 277(30): p. 27337-44. 5. 6. 7. 8. 9. 10. 11. 12. Yan, Y., et al., Crystal structure of yeast Esa1 suggests a unified mechanism for catalysis and substrate binding by histone acetyltransferases. Mol Cell, 2000. 6(5): p. 1195-205. Lin, Y., et al., Solution structure of the catalytic domain of GCN5 histone acetyltransferase bound to coenzyme A. Nature, 1999. 400(6739): p. 86-9. Brownell, J.E., et al., Tetrahymena histone acetyltransferase A: a homolog to yeast Gcn5p linking histone acetylation to gene activation. Cell, 1996. 84(6): p. 843-51. Trievel, R.C., et al., Crystal structure and mechanism of histone acetylation of the yeast GCN5 transcriptional coactivator. Proc Natl Acad Sci U S A, 1999. 96(16): p. 8931-6. Burman, R.L., J. P., The design of optimum multifacterial experiments. Vol. 33. 1943: Biometrika. 305-325. Liao, J., et al., Engineering proteinase K using machine learning and synthetic genes. BMC Biotechnol, 2007. 7: p. 16. Danziger, S.e.a., Choosing where to look next in a mutation sequence space: Active Learning of informative p53 cancer rescue mutants. Bioinformatics. 23: p. 104-114. Stemmer, W.P.C., Crameri, A., Ha, K. D., Brennan, T. M., and Heyneker, H. L., Single-step assembly of a gene and entire plasmid from large numbers of oligodeoxyribonucleotides. Elsevier Science 1995. 164: p. 49-53.