PROTEINS
advertisement

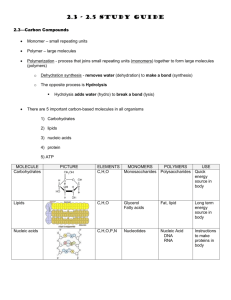
1 BI1507 PROTEINS Lecture 1 AIMS To review: protein functions monomer (amino-acid) structure polymer (polypeptide) structure amino-acid isomerism examples of the 20 coded amino-acids. 2 REFERENCES Purves Edition 8 pp. 42-49. 3 1 WHY STUDY PROTEINS? A Present in all cells; human cell contains ~104 different proteins. B Their structures (and hence functions) are determined genetically. DNA structure genetic information stored directs protein structure genetic information used (‘expressed’) 4 C All biomolecules are made, function, and then broken down through reactions using protein catalysts. D >1400 human genetic diseases are caused by loss of/defect in particular, single proteins. 5 2 PROTEIN FUNCTIONS Wide variety: no other biomolecules are so versatile. Many functions depend on interaction of the protein with another molecule: often the interaction is specific. 6 A Enzymes biological catalysts very efficient very specific bind to reactants (‘substrates’) most water-soluble, globular. B Structural most water-insoluble, fibrous e.g. hair keratin. C Movement e.g. muscle myosin. 7 D Transport e.g. O2-carrying haemoglobin. E Protective e.g. antibodies. F Hormones e.g. insulin. G Storage e.g. milk casein. H Receptors e.g. retina rhodopsin. I Gene regulation some proteins bind to DNA and switch genes on or off. 8 What is it about protein structure that allows such versatility? A surprise(?): In general terms, all proteins have the same molecular structure. All are linear polymers made of -amino-acid monomers. 9 3 MONOMER (AMINO-ACID) STRUCTURE [See: Purves, p. 42.] Note carbon; amino group; carboxyl group; side-chain (R group), which is different in different amino-acids. 10 11 4 POLYMER (POLYPEPTIDE) STRUCTURE [See: Note Purves, p. 44.] peptide (amide) bond, made by water elimination (later BI1505 lectures show how it is made in cells); amino (N terminus); carboxy (C terminus). 12 13 14 The polymer is called a ‘polypeptide’. How big are proteins? Total monomers present insulin 51 lysozyme 129 haemoglobin 574 glutamate dehydrogenase ~8300 15 No. of polypeptides 2 1 4 ~40 16 5 AMINO-ACID ISOMERISM carbon has 4 different groups attached, arranged tetrahedrally. 2 ways in which they can be arranged in space, giving 2 (optical) isomers, the L- and D- forms. 17 Amino-acid isomers: [See: Note the two, Purves, pp. 40-41.] non-superimposable, mirror-image structures. Only L-isomers occur in proteins. It is not clear why this evolutionary ‘decision’ was made. 18 6 EXAMPLES OF THE 20 CODED AMINO-ACIDS >300 amino-acids are found in nature. Just 20 are used to make proteins. Examples of the 20 A Simplest glycine [See: Purves, p. 43.] 19 B Non-polar (hydrophobic) alanine phenylalanine [See: Purves, p. 43.] 20 C Polar (hydrophilic) serine [See: Purves, p. 43.] 21 D Charged at pH 7 (hydrophilic) glutamate lysine [See: Purves, p. 43.] E S-containing cysteine [See: Purves, p. 43.] 22 Why (these) 20? Only they are genetically coded (by particular DNA triplet code-words). 20, combined in various ways, are enough to generate a very large number of protein structures (and hence functions). 23 BI1507 PROTEINS Lecture 2 AIMS To review: levels of protein structure compound proteins the link between DNA structure and protein function. 24 1 LEVELS OF PROTEIN STRUCTURE A PRIMARY = sequence of amino-acids. Each protein has a unique, genetically coded sequence. With 20 possible occupants for each position, a very large number of sequences is theoretically possible; e.g. for a polypeptide of 100 amino-acids, 20100 (= 1.27 x 10130) are possible. This is the source of versatility in protein structure (and function). 25 B SECONDARY = structures formed by H-bonding between -NH and C=O groups of the polypeptide backbone. There are 2 main types of secondary structure: -helix -sheet. 26 The -helix [See: Purves, p. 45.] Note the groups involved in the Hbonding, and the periodicity of the helix; that is, between one amino-acid and the other to which it is hydrogen-bonded, there are three intervening amino-acids in the primary structure of the polypeptide. 27 28 29 30 31 The -sheet [See: Purves, p. 45.] Note the groups involved in the H-bonding and the layering effect produced. 32 In many globular proteins, including enzymes, both -helix and -sheet may occur. [See: Purves, p. 47, where this is illustrated by diagrams of the structure of lysozyme.] 33 34 C TERTIARY = folding of the polypeptide in space. It involves various interactions of R groups. (i) van der Waals forces Non-specific, weak attractions between atoms 0.3 – 0.4 nm apart. Structures allowing contacts are stabilised. many such 35 (ii) Ionic interactions between 2 close, oppositely charged R groups. 36 (iii) H-bonds between R groups or of R groups to surrounding water molecules. 37 (iv) Disulphide bonds covalent between 2 cysteines. Occur particularly in extracellular proteins. 38 (v) Hydrophobic interactions Our discussion of secondary and tertiary structure suggests that proteins have particular shapes largely because parts of the polypeptide interact with other parts. Why should a polypeptide form H-bonds ionic bonds van der Waals interactions within itself, when it can just as readily form them with surrounding water molecules? 39 The answer is that such intra-polypeptide interactions occur in an environment within the polypeptide from which water is excluded. Exclusion occurs because hydrophobic R groups cluster. 40 41 This clustering occurs because surrounding water molecules are then more free to H-bond to one another. So, in globular, water-soluble proteins, hydrophobic R groups tend to be on the inside of the protein, (making the waterexclusion zones secondary/tertiary where structure the intra- polypeptide interactions occur), while hydrophilic R groups tend to be on the outside, H-bonding to water, and making the protein water-soluble. 42 In contrast, proteins embedded in lipid membranes, and some structural proteins, e.g. hair keratin, have many hydrophobic R groups on the outside, making the protein water-insoluble. 43 D Quaternary = occurrence of > 1 polypeptide in the functional protein e.g. adult human haemoglobin contains 2 polypeptides and 2 polypeptides. 44 2 COMPOUND PROTEINS contain a non-polypeptide part, the prosthetic group, necessary for function. E.g. in haemoglobin, each of the 4 polypeptides contains a N/C heterocyclic structure (‘haem’) with Fe attached to which O2 binds. 45 3 THE LINK BETWEEN DNA STRUCTURE AND PROTEIN FUNCTION linear sequence of DNA triplet code-words directs linear sequence of amino-acids in polypeptides directs intra-polypeptide interactions, and interactions between polypeptide and its environment directs protein shape directs protein interactions with other molecules directs protein function 46 BI1507 ENZYMES AIMS To review: how enzymes increase reaction rates lysozyme as an example control of enzyme activity ribozymes. 47 REFERENCES Purves pp. 125-135. 48 Enzymes are: biological catalysts very efficient very specific bind to reactants (‘substrates’) most are water-soluble, globular proteins nearly all biochemical involve them. reactions They work in teams, the product of one enzyme-catalysed reaction becoming the substrate for another. This produces a network of metabolic pathways in cells, concerned with providing energy, making necessary molecules, etc. 49 1 HOW ENZYMES INCREASE REACTION RATES Enzymes increase the rate of spontaneous reactions by decreasing activation energies. What makes a reaction spontaneous or non-spontaneous? Answer: This depends on what the concentrations of the reactants are, relative to their concentrations at equilibrium. 50 Suppose equilibrium of the reaction A B occurs when there are 5 molecules of A for every 2 molecules of B. Now, suppose, in a particular situation, there are 10 molecules of A for every 2 of B. Some A is converted spontaneously into B. A B then, is a ‘spontaneous’ reaction. 51 If, in a different situation, there were 3 molecules of A for every 2 of B, then some B would be converted spontaneously into A, and A B would be a ‘spontaneous’ reaction. [A spontaneous reaction occurs with a -G, that is, a decrease in free energy.] 52 ‘Spontaneous’ does not mean ‘instantaneous’. For the complex reaction wood + O2 CO2 + H2O + smoke + ashes the equilibrium and the ‘concentrations’ of the reactants are such that spontaneous flow always occurs Nevertheless, wood is generally stable over long periods in the presence of O2. 53 Why do spontaneous reactions not occur instantaneously? Answer: an input of energy is needed, to move the reactants (e.g. wood and O2) from their fairly stable state. This energy is the activation energy of the reaction. 54 Energy profile for a spontaneous reaction A [See B Purves, p. 126.] Note: the axes of the graph; the transition state, which has a higher free energy than either A or B; the activation energy, which is the difference in free energy between the free energy of A and that of the transition state; the fact that B has a lower free energy than A. 55 56 There are 2 ways to increase the rate of a spontaneous reaction: 1 Heat reactants The input in energy allows passage through the activation energy barrier. 2 Lower the activation energy barrier. This is what enzymes do. In terms of our ‘wood’ example: 1 burn the wood in air; 2 feed the shipworms. wood to termites or 57 Enzymes do not ‘shift’ equilibria; make non-spontaneous reactions spontaneous. 58 2 LYSOZYME AS AN EXAMPLE Lysozyme is an enzyme found in egg white, saliva, tears. It acts as a natural antibiotic, because it catalyses the cutting of polysaccharide chains (made of sugar monomers) in bacterial walls, causing the cells to lyse (i.e. burst). 59 The reaction is a hydrolysis: and is spontaneous, but certainly not instantaneous (the cell wall is stable and very tough). 60 This is because, for hydrolysis, the sugars need to be distorted before the bond between them will break. The distorted form is called the transition state (look back at the energy profile diagram). 61 Lysozyme has a groove (the enzyme’s active site) into which the chain fits precisely. 62 When the enzyme binds, it distorts the chain, so that the transition state is easily reached. Once the chain is broken, the enzyme releases it, and can repeat the process. Only certain chains fit the active site: this is the specificity. origin of the enzyme’s 63 3 CONTROL OF ENZYME ACTIVITY An example is feed-back inhibition. Consider a metabolic pathway enzyme a A B Z the function of which is to make Z. Often, when sufficient Z is present, then, at that concentration, it ‘feeds-back’ and inhibits enzyme a. 64 It does this by binding non-covalently to a site other than the active site, causing the enzyme protein to change shape, so that it no longer binds (or processes) the substrate so well. This is called allosteric (other site) inhibition. 65 For the organism, this means that when there is sufficient Z, its synthesis slows. When [Z] falls, the inhibition is relieved, and its rate of synthesis increases. A neat control system: the rate of synthesis of Z depends on [Z], and [Z] stays ~ constant in the cell. Allosteric occurs. activation of enzymes also 66 4 RIBOZYMES Enzymes are proteins. We know that protein structure is directed by DNA structure. In fact, sequence of bases in DNA directs sequence of bases in RNA directs amino-acid sequence in proteins. Nowadays, protein enzymes catalyse the synthesis of DNA, RNA, but, before there were proteins, how were nucleic acids made? 67 In 1982, a few RNA molecules were shown to act as catalysts, called ‘ribozymes’. Perhaps they are remnants of very early, pre-protein catalysts.