Instructions for Authors - Computer Science & Engineering
advertisement

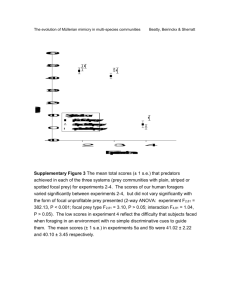
Evolution of Complex Behavior Controllers using Genetic Algorithms Kerry A. Gruber Jason Baurick Sushil J. Louis Computer Science Dept. University of Nevada, Reno Reno, NV 89557 kkgruber@ix.netcom.com http://www.cs.unr.edu/~gruber Computer Science Dept. University of Nevada, Reno Reno, NV 89557 Genetic Algorithm Systems Lab. Computer Science Dept. University of Nevada, Reno Reno, NV 89557 sushil@cs.unr.edu Abstract Development of robotic controllers for complex behavioral tasks is difficult when the exact nature or complexity of an environment is not known in advance. This paper explores the use of genetic algorithms to evolve neural network controllers that exhibit generalized complex behavior. We compare the performance of the evolved controllers to those developed by human programmers. Keywords: Genetic Algorithms, Neural Networks, simulated robotics. 1 INTRODUCTION Lack of knowledge regarding the actual operating environment at design time makes design of controllers that perform reliably under changing environmental conditions a difficult task. This is especially true when the operating environment is expected to be dynamic in nature, or the exact specifications, such as the topology, are unknown. In order for a controller to perform reliably under such conditions; it must be able to adapt to its environment, or it must be able to generalize complex behaviors applicable to all possible conditions. Artificial neural networks are an increasingly popular alternative to traditional control strategies, particularly when the exact mechanics of a problem are difficult to define or are non-linear in nature. Neural networks are capable of learning very high-order statistical correlations that are present in a training environment, and very importantly, they provide a powerful and attractive mechanism for generalizing behavior to new environments (Nolfi et al. 1990). However, neural networks are limited in their ability by the methods used in training. Traditional approaches to training neural networks are based on a supervised model using such techniques as backpropogation or conjugate gradient descent. The supervised model relies on a set of examples to provide a mapping from input to output. For the simulation used in this paper, it is possible to design a reaction-based neural network controller using the supervised model based on desired reactions to specific states. This would, in effect, be the same as programming the controller using a standard rule set. The programmers understanding of the environment and the anticipated consequences of predefined reactions limit such rule sets. Neuro-evolution, the use of Genetic Algorithms (GAs) to train or build neural networks, has been shown as a promising alternative to classical techniques for design of complex behavioral systems (Nolfi et al. 1990; Yamauchi and Beer, 1994; Moriarty and Miikkulainen, 1997). The Genetic Algorithm Training of Robot Simulations (GATORS) system uses a GA to train the weights of a neural network to control the motor functions of robots in a simulated environment. Fitness within the system is based on performance of complex behavioral tasks. Wall following, vacuum cleaning, obstacle avoidance, and prey-capture scenarios are examples of such complex behavior because they are not tied to specific spatial locations (Gomez and Miikkulainen, 1997). A demonstration version of the system is available via the web at http://www.cs.unr.edu/~gruber. The body of this paper is organized as follows: The next section provides a short introdution to artificial neural networks. (Readers already familiar with this topic are invited to skip to Section 3.) Section 3 describes the simulated environment and agents. The methods employed by the GATORS system are discussed in Section 4. Results of our methods are provided in Section 5. A summary of the conclusions reached is given in Section 6. In Section 7 we outline possible future work related to the GATORS system. 2 2.1 BACKGROUND NEURAL NETWORKS A neural network is an artificial representation of the connections and functions occurring within the brain. Artificial neural networks do not approach the complexity of the human brain; but do share two key similarities: First, the building blocks of both networks are simple computational devices that are highly connected. Second, the connections between neurons determine the function of the network (Hagan et al., 1996). An artificial neural network is a group of simple interconnected neurons; normally divided into layers. (refer to Figure 1). In its simplest form; each neuron consists of a series of connections with the previous layer, a bias input, and an output that feeds to the next layer. Each connection has a “weight” associated with it, which is multiplied with the input from the previous layer. The output is simply the sum of the bias and the inputs multiplied by their associated weights and passed through an activation function. If we consider a simple two input neuron; the inputs, weights, and bias form the equation of a line. The output of the neuron is based on whether the input point lies above or below the line. So, each neuron divides the two-dimension input space in half. This concept can be extended to N-dimensional space. Each neuron separates the input space in half. The network acts as an effective classifier. Input Layer I1 Variable Number of Obs. Obs. Area Coverage Ear Length Hearing Range Number of Prey Prey Length Prey Sleep Time 3.2 bh1 Output bo Weights In bhn Figure 1: Artificial Neural Network 3.1 Table 1: Summary of Environment Variables Min. Value 3 5% 1 20 1 1 100 Max. Value 10 10% 10 200 4 10 1000 ROBOTS Hidden Layer Output Layer 3 Obstacles are randomly placed within the environment for the robots to avoid or negotiate in order to find and capture prey. This increases the complexity of the control task since you do not want to cover the same location over and over, particularly in tight locations where the robots tend to bounce between close walls. As robots negotiate obstacles, it is possible for them to “crash” into the obstacle in the process. This is a situation which is highly undesirable and causes the robot to stop moving and corresponds to the a real-world robot hitting an obstacle and possible leading to damage. The robots must learn to negotiate obstacles by coming close enough to sense them while reducing the number of crashes. Table 1 outlines the variables related to the simulation. These values are randomly set prior to a simulation and do not change during the simulation. SIMULATION There are two types of robots in the simulations, predators and prey. In this study, prey do not move and w are only interested in evolving controllers for predators. Each predator is equipped with a set of seven sensors (refer to Figure 2). Five of the sensors are binary touch sensors, and the remaining two are hearing sensors that return real values. The touch sensors signal contact with an obstacle provide obstacle location information. The hearing sensors determine the approximate direction of prey in relation to a robot’s current position. The five binary touch sensors are located at the front, rear, and center of the robot (refer to Figure 2). When the center touch sensor (also called the crash sensor) touches an obstacle, a crash is registered against the robot. DESCRIPTION The simulation is based on those used by Louis, Sun, and Li (Louis and Sun, 1996; Louis and Li, 1996). The simulator is primarily designed to develop and test robots in performance of “vacuum cleaning”, the ability to cover as large an area as possible in the time allotted. The simulation is designed so that a number of complex behaviors are required in order to achieve acceptable results. Each robot is equipped with a battery that decreases as the robot moves. Prey/food in the simulation emit “sound” and when robots move close enough, are “eaten” by robots to recharge their batteries. Once eaten, prey cannot be re-eaten for a set amount of time. 6 Units Variable Length 10 Units Hearing Sensor Rear Touch Sensor Figure 2: Robot Sensor Locations 3.4 The hearing sensors are located on the right and left sides of the robot (refer to Figure 2). The lengths of the hearing sensors are variable from 1 to 10 and are randomly set during training. Prey emit sound whose magnitude received at the hearing sensors is proportional to the hearing range of a robot and inversely proportional to the square of the distance. Sound is cut off outside a robot’s specified hearing range. The total sound level received is the sum of the emissions of all prey. Hearing ranges vary from 20 to 200 and are set randomly during training. Each robot is equipped with a pair of motors, one on each side. As robots move in the environment, their battery levels decrease in accordance with the distance moved. The maximum move distance during a single step is 4 units in the forward direction and 2 units in reverse. The change in heading angle is proportional to the difference in actuator levels and varies within a maximum range of ± 30°. 3.3 ENVIRONMENT The environment is a spatially independent grid that may be varied in size from 200x200 to 1000x1000. For testing and training purposes we use a size of 300x300. The simulation randomly places rectangular obstacles into the environment for each generation. The number of obstacles ranges from 3 to 10. The obstacle dimensions are also randomly generated for each generation. The maximum area a single obstacle may cover is limited 10% of the total environment area, and the minimum area to 5%. This assures that obstacles never completely cover the entire operating region. The environment also contains a minimum border of 5 units between the environment edge and all obstacles. The border is small enough that a robot can not fit between the environment’s outer edge and an obstacle without sensing one or the other. Figure 3 displays a random environment generated by the simulation. Prey Obstacles Predators Figure 3: Randomly Generated Environment SIMULATION PROCESS Our simulations run for 1000 time steps. During a time step each robot is given a turn to move. Movement order is random for each step. The simulation supplies each controller with the current sensors state made up of battery level, the hearing sensor magnitudes, and the touch sensor states. No absolute or relative location information is supplied by the simulation. The simulation moves the robots based on the controller output levels, current position, current heading, and interaction with any obstacles. Angular change is registered prior to displacement. If the crash sensor of a robot crosses the boundary of an obstacle or the environment edge, the robot is placed just inside the location of intersection with the obstacle and a crash is registered against the robot. Noise may also be present in the and a noise level bias determines the overall effect of noise in the system. The bias may be varied from 25 to 75. The noise function returns a value of ±1, dependent upon whether a random number modulus 100 is above or below the bias level. The value returned is added to the change in robot heading and distance. Use of levels below 50% results in an overall bias to move left and forward; while levels above 50% results in a bias to move backward and right. As the value moves farther from the central value of 50, the effect of noise becomes more pronounced. If a crash is registered, the simulation still decreases the battery level of the robot as if the full move had occurred. If the battery level for a robot reaches 0, the robot is considered “dead”, and is no longer allowed to move. Each predator begins with a battery level of 1000. 4 4.1 METHODOLOGY NEURAL NETWORK The system utilizes a two-layer feed-forward neural network. The network contains of 10 input nodes, with all inputs normalized between 0 and 1. W varied the number of hidden nodes between 1 to 10. The controller presented here uses four hidden nodes based on experimental results. The system uses four output nodes for motor control stimuli. The activation function is a standard sigmoid function. The outputs are limited using a threshold value of 0.5. The robots can not effectively capture prey without a minimum of state information. This is due to the presence of virtual food sources as perceived by the robots. Figure 4 shows two circles centered on each of the hearing sensors. The magnitude received by the hearing sensors is the same whether the source is located at either position. Recurrent networks have been used as an effective strategy for incorporation of short-term state information (Gomez and Miikkulainen, 1997). We chose to use a simpler method so that only the minimum state information necessary is present. Instead of feeding the hearing levels directly to the network, the levels generate two binary inputs that signify the side the prey is on and whether prey is present. We save these values at each step for use during the subsequent step. Figure 5: Encoding Methods 4.2 GENETIC ALGORITHM 4.2.1 Encoding GAs are highly disruptive when used in conjunction with neural networks. The process of combining dissimilar sections from different networks often leads to nonfunctioning networks. In order to minimize disruption, two different encoding strategies are used in formation of the GA strings. The objective of both strategies is to minimize disruption by placing highly dependent sections of the neural network in close proximity during encoding. For both strategies, we use a 16-bit binary encoding of each weight and bias value. The first method groups together the input weights and biases associated with each neuron. The objective in this strategy is to maintain the full set of weights associated with each node during mating (refer to Figure 5). The total number of bits required to encode a single network is given by: Ntot=((Ni+1)*Nh + (Nh+1)*No)* 16, where Ni is the number of inputs, Nh is the number of hidden nodes, and No is the number of output nodes. Since each network contains ten inputs and four outputs, a network with four hidden nodes requires a 1024-bit string. The input weights to each node are encoded to represent numbers between ±100.0. The bias weights are encoded to represent numbers between ±100.0*Ni, where Ni is the number of inputs to a given node. The biases are then able to offset the full range of possible input values. Actual Prey Location Node N Node 1 WN1 B1 ... W1N W2N ... WNN BN Method I Input N Input 1 W11 B11 ... W1N B1N ... WN1 BN1 Method II Initialization We use two methods to initialize the GA. The first method is by simple random generation of the bits. The second is performed a little differently. First, we generate the input weights randomly. Then we set the bias for each node based on the sum of the input weights: Bj = 0.5 * Wij, where Bj is the bias for an individual node and Wij are the input weights from layer i to layer to the node j. Because the inputs are limited between 0 and 1, this places each node statistically in its operating region. We found that by doing so, the primary characteristics of early generations were significantly altered. Table 2: Initial Characteristics 4.2.3 Figure 4: Virtual Prey Location ... 4.2.2 Behavior Viable Non-Moving Circular Movement Straight Line/Crash Hearing Sensors Virtual Prey Location W11 W21 For the second strategy, we used a novel approach. With it, we broke the bias apart. Each input to a node was associated with its own part of the bias. The input weight and the associated bias are encoded next to each other in the strings. We group the weights according to the inputs, rather than the nodes, so all weights associated with a given input are next to each other. The number of bits required for this encoding is given by: Ntot=(Ni*Nh + Nh*No)*16*2, where the variables are the same as previously. For our network, an encoding with four hidden nodes requires a 1792-bit string. ... WNN BNN w/ Op. Pt. Initialization 40 10 33 17 w/o Op. Pt. Initialization 12 12 66 10 Fitness Determination The fitness of a controller is based on five features: the number of prey consumed, the number of touches, the number of crashes, the distance traveled, and area coverage. Early in the GAs evolution, there are only a few viable candidates produced during each generation. These viable candidates tend to have scores that are disproportionately large relative to the others. When random initialization is used, most of the controllers tend to move in small stationary circles, the others tend to move in either in a straight line until they contact an obstacle and repeatedly crash into it, or do not move at all. Only a small number of initial controllers exhibit acceptable characteristics for multiple categories (refer to Table 2). Because the robots that move in circles normally move the full distance possible without eating prey, when a scaled sum of the features is used the tend to overwhelm the population. Diversity is quickly lost and premature convergence ensues. If the scale factors are increased to produce good candidates during the early generations, later generations are scored too highly in those categories; and once again, there is a loss in diversity. Instead of a scaled sum of features, the fitness function uses the average and standard deviation for a given generation to compute the fitness score. The fitness function is given by: Fi = Wf * Sf * 2(Xif-f)/f where Fi is the fitness for the ith chromosome, Wf is a user-settable weight factor for a feature, Sf is a hard-coded scale factor for a feature, Xif is the score for a given feature, f is the mean value of the scores for a feature, and f is the standard deviation of the feature. (For crashes, the exponent terms are reversed.) Using this function, a chromosome with a score one standard deviation above the average will receive a score which is twice the average. As controllers learn and attain higher scores for a given feature, the fitness function also changes; keeping all portions of the fitness stable. The hard-coded scale factors were determined by examining the score distributions over 100 generations. They were chosen so that the scores in each category tend to be distributed within the same range of values. 4.4 The interface to the system is a set of three Java programs that may be run as applications, or as applets. A configuration interface is provided for setting the variables associated with the system. The second program allows the user to view the chromosome fitnesses and features independently as the GA progress. The last program allows testing of the final controller produced by the system. To ensure that no abuse of systems resources occurs, the applet version is limited in the number of variables that may be set. The applet version of the system is available for use by the general public at http://www.cs.unr.edu/~gruber. With it, a user may create and test their own robots. Additional Structure The standard deviation for consumption is normally on the order of 1.0. When a candidate consumes a large number of prey, this leads to scores which are significantly larger than the rest of the population. The diversity of the population is quickly lost, even with the fitness function used. Scaling was introduced to limit premature convergence associated with a few candidates having very large finesses relative to the rest of the population (Goldberg, 1989). Due to the highly disruptive nature of the GA, we use an elitist selection algorithm to maintain the most fit individuals. Without elitism, the system tends to dismantle viable candidates before they can produce better offspring. During each generation, the 30 best fit chromosomes kept without crossover or mutation. The crossover rate is set at 100% for the remaining chromosomes. 4.3 FINAL SELECTION In order to determine the final candidate, the best 20 controllers are scored in 10 random environments. The candidate with the highest fitness sum is then selected. We found that testing the candidate in even 10 environments, did not always yield the best controller; at least in our opinion. This is a very subjective determination. For the web applet implementation, the best candidate, as determined by the system, is used for testing and display. For our own purposes, we hand IMPLEMENTATION The system uses an Intel based Beowulf cluster with eight Pentium II 400MHz machines running RedHat Linux. The GATORS system uses the Local Area Multicomputer (LAM) implementation of the Message Passing Interface (MPI) for inter-process communication. The system achieves an overall speed-up of about 4 (refer to Figure 6). Speed-up 4.2.4 selected what we considered to be a good candidate based on objective criteria in specialized test environments. The controller selected was trained in the absence of noise. 4.50 4.00 3.50 3.00 2.50 2.00 1.50 1.00 0.50 3.93 3.48 3.37 2.88 2.34 1.00 1 1.71 0.93 2 3 4 5 6 7 8 Number of Processors Figure 6: Speed-Up vs. No. of Processors 5 RESULTS We test the hand-selected controller produced by the GATORS system in a competitive environment against three controllers designed by human programmers. Testing takes place by incrementing one of five variables over its allowed range in 100 divisions. For each division, the system runs the controllers through 100 random environments and computes the average scores over the simulations. The system uses the same 100 random environments during each set in the process. The only condition varied in each set of simulations is the variable being studied. Unless specified, noise was turned off for all tests. All other variables are randomly selected within allowed ranges. The variables used for testing are predator ear length, predator hearing range, prey dormancy period, prey eat range, and system noise. Figure 7 shows the average area coverage of the test unit in competition with the three human-developed controllers. The graph shows that controller the constructed by GATORS achieves an average area coverage that is 33% higher than the best controller produced by the human programmers. 1 1450 2 3 Test Unit 1400 Distance 1350 1300 1250 1200 1150 1 2 3 1100 Test Unit 1050 0 20 700 30 40 50 60 70 80 90 100 600 Figure 9: Average distance covered 500 Even with a lower consumption rate, it is able to cover a greater area than the others. 400 300 0 10 20 30 40 50 60 70 80 90 100 Random Environment Set Figure 7: Average Area Coverage The controller’s ability to follow walls is exemplified by the number of times it touches obstacles during a simulation. Figure 8 shows that the test unit touches obstacles at about twice the rate of its nearest competitor. The ability to use energy efficiently is a highly desirable characteristic. The test unit has a tendency to move at a slower rate than the other units and covers less distance. The test unit traverses only about 85% of the distance of two of the other controllers (refer to Figure 9). By moving at a slower rate, the unit is able to conserve energy. The relation of area coverage to the prey sleep time provides a good correlation to energy conservation. The test unit exhibits a higher independence to sleep time than the other controllers (refer to Figure 10). The test unit appears to survive for longer periods of time, allowing sleeping prey to awaken to be consumed. The 1 700 Number of Touches 10 Random Environment Set 2 3 The controller performed at only an average rate with respect to noise. Figure 11 shows that the controller is affected by noise as much as the controllers designed by hand. The reason for the reversal of results with respect to the human-designed controllers is that the GATORS controller moves backwards as a rule. This may be due to the fact that there is only one speed in the reverse direction. The other scoring categories showed similar results in the presence of noise. This is partly due to the fact that the controller that we present here was constructed in environments in which the noise bias was turned off. We found that controllers built without noise exhibited better characteristics in non-noise environments. The controllers built in noisy environments do not perform as well as those built in noiseless environments, but they do perform better than the unit presented here 1 2 3 Test Unit 800 750 700 Area Coverage Coverage 800 Test Unit 650 600 550 500 450 400 350 600 300 100 500 190 280 370 460 550 640 730 820 910 1000 Prey Sleep Time 400 Figure 10: Area coverage versus sleep time when noise is present. 300 200 100 0 10 20 30 40 50 60 70 80 Random Environment Set 90 100 Figure 8: Average Number of Touches other controllers quickly consume any food present, and then use up their energy before the prey awakens. The test unit’s consumption rate decreases in line with the other controllers as the prey sleep time is lengthened; but as we observe in Figure 10, the area coverage is not decreased like the other controllers. The test unit also has a lower consumption rate than two other controllers. 6 CONCLUSIONS The controllers the GA produced exceeded those developed by human programmers in several categories; particularly in the areas of area coverage and energy conservation. In addition, the controllers produced exhibited a number of other complex behaviors. The unit studied here is proficient hunter; able to negotiate obstacles in its path when prey is detected, and capture prey on the other side of those obstacles. References Area Coverage 1 2 3 D. E. Goldberg (1989). Genetic Algorithms in Search, Optimization, and Machine Learning. Reading, MA: Addison-Wesley. Test Unit 900 800 700 600 500 400 300 200 100 0 F. Gomez and R. Miikkulainen (1997). Incremental evolution of complex general behavior. In Evolutionary Computation 5, 317-342. M. T. Hagan, H. B. Demuth, M. Beale (1996). Neural Network Design. Boston, MA: PWS Publishing Co. 25 30 35 40 45 50 55 60 65 70 75 Noise Bias Figure 11: Coverage vs. Noise Bias However, the use of GA to train a neural network controller for complex behavioral functions is a difficult task. This is primarily related to the subjective nature of the scoring procedures used. We found no hard and fast rules regarding scoring which yielded optimal results. As the final performance is subjective in many respects there may be no single optimum, and is simply based on finding desired characteristics for a given circumstance. We found that in order to get any acceptable results, it is necessary to take into account the different stages that occur in development as evolution progresses. In particular, the scoring function used during infancy is of primary importance. Without taking infancy into account, the large differences in fitnesses between dissimilar categories lead to pre-mature convergence due to a loss in genetic diversity. By using a scoring function that is based on relative fitness, rather than absolute measurements, we were able to get much better results. We also found that by using an operating point initialization, the initial chromosomes exhibited behaviors which were more diverse than those produced using random initialization. Noise within the environment made it almost impossible to construct viable controllers in our system. We believe the controllers developed in infancy are unable to cope with the presence of noise. For that reason, the GA is unable to progress in a normal nature. 7 FUTURE WORK The GA functioned at a much higher level using the operating-point initialization functions. Further study into the relationships associated with this type of initialization may prove interesting. The exact reasons for the increase in performance is not immediately self-evident. The fitness function also appears to perform better than the initial scaled sum-of-fitness methods attempted. Both methods deserve further examination. J. H. Holland (1973). Genetic algorithms and the optimal allocation of trials. SIAM Journal of Computing 2 (2), 88-105. S. Louis and J. Sun (1996). Designing robust situated agents using genetic algorithms. Proceedings of the ISCA 5th International Conference on Intelligent Systems, 140144. ISCA Press. S. Louis and G. Li (1996). Designing robust situated agents using genetic algorithms. Proceedings of the ISCA 5th International Conference on Intelligent Systems, 145149. ISCA Press. D. E. Moriarty and R. Miikkulainen (1997). Forming neural networks through efficient and adaptive coevolution. In Evolutionary Computation 5, 373-399. S. Nolfi, J. L. Elman, and D. Parisi (1990). Learning and evolution in neural networks. Technical Report 9019, Center for Research in Language, University of California, San Diego. B. Yamauchi and R. D. Beer (1994). Integrating reactive, sequential, and learning behavior using dynamical neural networks. In D. Cliff, P. Husbands, J. Meyer and S. Wilson (Eds.), From Animals to Animats 3: Proceedings of the Third International Conference on Simulation of Adaptive Behavior (SAB94), 382-391. MIT Press.