Autosomal Dominant Diseases:
advertisement

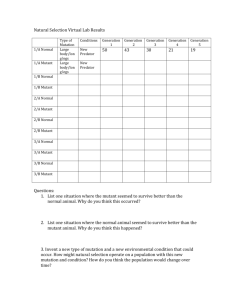
Familial Hypercholesterolemia: Understanding the Molecular Biology Authors: John Sabo & Kevin Messner This paper will discuss the inherited disease familial hypercholesterolemia. The overall purpose is to teach the user how to search protein databases using the Biology Workbench, a suite of bioinformatics tools, to conduct research. This tutorial uses tools that range in complexity, and it is designed to allow the user to walk through the research process, step-by-step, in order to get the desired results and achieve understanding of the molecular biology of this disease. Familial hypercholesterolemia is a genetic disorder in which cholesterol levels in the blood are very high. There are several genes which can affect cholesterol levels. The type we will study is an autosomal recessive genetic disorder. This means that only people with two recessive alleles of this gene are unable to transport cholesterol to the liver cells that metabolize it. Cholesterol is carried through the bloodstream in a lowdensity lipoprotein (LDL, a protein and lipid containing particle). In normal people, the lipoprotein binds to a specific receptor on the liver cell surface and is then taken up into the cell by endocytosis. Some people who have the disorder lack a fully functional lipoprotein, named Apolipoprotein E, due to a point mutation in the genetic sequence that encodes the protein. In the point mutant, an arginine amino acid in position 158 is mutated into a cysteine amino acid. This changes the conformation of the protein and the cholesterolcarrying lipoprotein cannot enter the cell because it cannot successfully attach itself to the receptor protein on the liver cell. The excess cholesterol can build up on the inner walls of the blood vessels, which can lead to blockage in the arteries, causing a heart attack, or a blood clot in the brain, leading to a stroke. there are also other genetic problems that cause this disease, such as mutations in the lipoprotein receptor, but in this tutorial we will deal only with Apolipoprotein E. PART I: Opening an Account If you already have a Biology Workbench account, go ahead and log into the program. If not, this is what you need to do: Go to the Biology Workbench homepage: http://workbench.sdsc.edu Click on the link that says, “Set up a free account”. Fill out the information requested. After you submit the necessary information, click on “Register”. Type in your user name and password and click on “OK”. You will then be brought to the homepage for the Biology Workbench. Scroll down to the bottom and select the background color you want. (We recommend rose because this makes it easier to see the blue and green colors used later when aligning sequences.) Note: There are a variety of different layouts for the Biology Workbench. You can toggle between the different layouts by clicking on the Biology Workbench logo at the top of the screen – click on it until you find the format that fits the layout of this tutorial. Starting a New Session: As you can see, there are a number of different tool domains supplied by the Workbench: “Session Tools”, “Protein Tools”, “Nucleic Tools”, “Alignment Tools”, and “Structure Tools (Alpha)”. We will use "Session Tools" and "Protein Tools" in this experiment. To remain organized, when you enter or leave the Workbench, you should create a new session for every different topic you research. 1) Click on “Session Tools”. Highlight “Start New Session” and click on “Run”. 2) The following screen will require that you name this session. Call this session “Hypercholesterolemia”. Then click on “Start New Session”. Your new “Hypercholesterolemia” session will appear right below your “Default Session”. You can click back and forth between the default and Hypercholesterolemia sessions. However, make sure for the remainder of this exercise that the “Hypercholesterolemia” session is selected. In this tutorial, you are going to learn how to use the tools that will allow you to search protein databases and analyze protein sequences imported into the Workbench. Clicking on the box that says “Protein Tools” at the top of the page will bring you to the Protein Tools homepage. The new page says it is “empty”, that is, no protein sequences have been saved here yet. Importing sequences from any number of sequence databases will change this and the word “empty” will disappear; in its place will be the list of sequences that were imported. PART II: Importing Sequences and Viewing Structures from Protein Databases In this section, you will learn how to search databases for a protein sequence. As mentioned above, you will be working with apolipoprotein E to study this form of hypercholesterolemia. Notice the scrollable textbox at the top of the page… this box contains a variety of tools, some of which you will now explore. Highlight “Ndjinn – Multiple Database Search” and click “Run”. The next screen list the different databases that you can search. In the search box at the top of the page, type: “lipoprotein”. This tells the search engine what to look for. Also, notice the box to the right of the input box. This simply allows you to decide how many sequences you want to display. For this exercise, you want to see all of the sequences that are found, so select “All”. Scroll down the page. Below the input box, you will see a list of many different databases, all containing a variety of sequence information. The databases are separated into two distinct groups: the first group contains sequences from many different organisms (for example, “GBBCT” contains a large number of sequences from many different bacteria), whereas the second group contains the entire genome of specific organisms (for example, “Mthe” contains the entire genome sequence of the bacterium Methanobacterium thermoautotrophicum). Click on the box that is next to the PDBFinder Database. This database contains protein sequences that have a crystal structure formulated so that a 3-D picture of the protein can be visualized. A little later we will look at some of these pictures. Scroll back up to the top of the screen and click on “Search”. You will then be sent to a page that contains the results of your search. At the time this tutorial was written, the search engine found 53 matches for “lipoprotein”. If you get more than 53 results, do not panic. Inconsistencies in the number of search results can occur because new sequences are being added to the databases on a daily basis. From the descriptions of the search results, we need to determine which one is the wild type sequence for the lipoprotein receptor protein. In order to find the correct sequence, we will need to check the records of the sequences to find out which sequence is wild type. To do this, highlight the 53 sequences with your mouse. Once all of the sequences are highlighted, click on the button below that says “Show Records”. This tool will give a detailed description of each sequence that is highlighted. If you are using Netscape, a new window will appear; in Windows Explorer the browser will move to a new page. Scroll down this page until you can locate the wild type sequence for Apolipoprotein E. Specifically, we want the "LDL receptor-binding domain" of the protein. If you have correctly identified the wild type protein, you should have picked the following: This file (1LPE) is the wild type, or normal, protein sequence for lipoproteins found in people that do not have hypercholesterolemia. This is the protein that we want to work with. We need to do two things: look at a model of the protein structure, and second, download the amino acid sequence of the protein into our Biology Workbench session. First, let's look at at structural model of this protein. Click on the link to "PDB Structure Explorer" in the upper-right hand of the entry for our protein. This will bring up a new window with a page from the Protein Databank web site. Click on the link to "View Structure" on the left side of this page: You will come to a page with several options for viewing the protein crystal structure. We will look at a still image of the protein. Scroll down and click on the link that reads "Ribbons (250 x250)": This will take you to a ribbon diagram of the protein. In this diagram you can't see individual atoms or amino acids, but you can see the overall shape of the protein molecule. Note the "corkscrews" that make up most of the protein chain. These represent alpha helices, a common kind of protein structure. So that later on you can compare this picture side-by-side with a picture of the mutant protein, copy this picture into an application like Word. To do this, RIGHT click on the picture itself, and then click on the "Copy" command that comes up in the command box: Next, open Word, and use the command bar go to Edit --> Paste (or press "CTRL" and "v" simultaneously): The picture should appear on your Word document as shown below. Be sure to label your picture so you will remember what it is and not confuse it with the next picture. Now that we've got the picture of the protein, next we want to import the sequence of this protein from the Protein Databank into the Biology Workbench. Keep the Word document open so we can look at it again later, and go back to the Biology Workbench screen with the Ndjinn search results. (Note: If you are using Netscape, you can close the pop-up Biology Workbench window with the full records. If you are using Windows Explorer, you will need to hit the "back" button on the browser to get back to the search results page). Highlight the correct sequence: “pdbfinder:1lpe – lipoprotein”. Now click on the button at the bottom that says “Import Sequence(s)”. This will bring the wild type protein sequence for the lipoprotein (the sequence we just highlighted) into the protein tools homepage for further investigation. PART III: Finding the Mutant Lipoprotein Sequence: Using BLAST Now that you have the wild type lipoprotein sequence, you can use it to find the mutant lipoprotein sequence that causes familial hypercholesterolemia. Because we know that the mutant lipoprotein equence differs from the wild type sequence by a single amino acid, we can use the wild type sequence to search a database for sequences that are extremely similar (or homologous) to it. In order to carry out the homology search, you are going to use a tool called BLAST. Scroll down the textbox and look for the tool called “BLASTP – Compare a PS to a PS DB”. (This is an abbreviation for “Compare a Protein Sequence to a Protein Sequence Database”.) Select this tool and ensure that your ILPE lipoprotein sequence has a checkmark in the box next to it – then click on the “Run” button. You will be sent to a screen that will give you many options. These options allow the user to fine-tweak their search. For the purposes of this exercise, we do not need to deal with this. The important step here is to choose the database you want to use for your homology search. Scroll down in the textbox until you come to the “PDBFinder” database. We will use this database again since it is the one that we started with. Highlight this database. Now scroll to the bottom and click on “Submit”. You will be sent to the following screen that contains the results of your BLASTP search: Now, you will need to find the mutant sequence that is responsible for causing familial hypercholesterolemia. But, before you do this, look at the number to the right hand side of the results box. If you look over to the “Score (bits)” column, you will see that the first few sequences have very high Score (bits) values. A Score (bits) value above 200 means that the sequence has high homology with the sequence that you are comparing it to. However, you can be more certain of the extent of the homology between two sequences by looking at the “E Value”. This is the number right next to the “Score (bits)” number. E Value The E Value or “Expect” value is the most intuitive, or instinctive, way to rank the results of a search. The E Value estimates the statistical significance of the search result by specifying the number of matches with a given score that could be expected to occur purely by chance in a search of a database of a particular size. For example, an Expect value of 2.0 would indicate that two matches with that particular score would be expected to occur purely by chance. The expected value changes with the size of the database (in a larger database, more chance matches with a given score are expected). Search results with E values much higher than 0.1 are unlikely to reflect true sequence relatives, but in some circumstances they are useful. Essentially, the smaller the E value, the more homologous or similar the sequence is to the original sequence BLASTED. An E value of zero indicates that no matches would be expected by chance – this would represent a perfect or near perfect match. Now it is time to decide which sequence is the mutant lipoprotein sequence. The mutation that causes familial hypercholesterolemia is a point mutation in the protein sequence that changes the amino acid arginine in the 158th position to the amino acid cysteine. Find the mutant in these results that matches this description. You can do this by checking the records like we did a bit ago. The correct sequence record is shown below: If you will notice, this is a mutant that replaces arginine at position 158 with a cysteine. That is the one we want!! Like before, we want to take a look at this protein structure. Click on the "PDB Structure Explorer" link at the top right of this record. On the window that comes up click on the "View Structure" link on the left side. On the next screen click the link that says "Ribbons (250 x250)." Like before, you can copy the picture that comes up to your Word document. Right click on the picture, copy, then switch to the Word document you still have up. Put the new picture beneath the first one. Make sure the cursor is at the bottom of the Word document, then paste the picture in. Put in a caption for the second picture; make sure to use the word "mutant" in this label. Now, without the captions, could you tell the two proteins apart? They look practically identical -- even though one of them is a mutant, and we know the mutant protein doesn't function correctly! What's going on? Let's go back to the Biology Workbench to see if we can figure this out. If you're using Netscape, you can close the extra Biology Workbench window with the detailed protein records, and just keep open the window with the list of "sequences producing significant alignments." If you're using Explorer, you'll just need to use the "back" button on the browser to get to the sequences screen. We want to import the sequence for the mutant protein. This is: (1LE2_LIPOPROTEIN|Apolipoprotein – E2_(LDL_receptor_binding_d…). Once the sequence is highlighted, click “Import Sequence(s)”. Now, the mutated sequence that causes the disease hypercholesterolemia is stored in the Protein Tools homepage along with the wild-type sequence. We will now further investigate where the mutation occurs in the mutant sequence of the lipoprotein, and try to figure out why the mutant protein doesn't work. PART IV: Aligning the sequences: Using CLUSTALW In order to compare two protein sequences side-by-side, they must be aligned one on top of the other. This is the purpose of the CLUSTALW tool. The alignment process takes place by comparing the two sequences and finding common regions within them. The Biology Workbench then uses an algorithm to compute the most likely position in which the two sequences line up. Therefore, alignment is a key step for you to determine where a mutation is located. The two sequences are aligned one on top of the other and a color-coding system is used to differentiate highly conserved regions and semi-conserved regions (in royal blue and green, respectively) from the non-conserved regions. On to the alignment… Scroll down in the text box menu and highlight “CLUSTALW – Multiple Sequence Alignment”. Click on the two lipoprotein sequences, 1LPE and 1LE2. Once there are checkmarks in the boxes next to the sequences, click on the “Run” button. Another screen will appear in which the alignment parameters can be altered – we are going to use the default settings so just click on the “Submit” button. You will now be taken to a screen that will show you the aligned sequences. Scroll down until you see the alignment. If you will notice, the wild type sequence is located on the bottom row and the mutant sequence is located on the top row. The letters that you see each represent an amino acid in the protein sequence. Almost all of the amino acids in both protein sequences match up perfectly… You can see this by the royal blue color (see consensus key at the top). However, there is a single position in which the two protein sequences do not match, and are color-coded black instead of royal blue. This is the site of the mutation. This is where the arginine amino acid was replaced by a cysteine amino acid in the mutant sequence. So you can easily see here that the mutation is near the end (or "C-terminus" in biochemistry jargon) of the protein sequence. PART V: Predicting the Secondary Structure of a Protein Sequence: Using GOR4 You are now going to take the two protein sequences and predict the secondary structure of the proteins by using a tool called “GOR4”. This tool will show the sequence of each protein and color code alpha helices with the color red and beta sheets with the color blue, according to where they are found in the protein sequence. We will use this tool to see if the mutated amino acid has caused a conformational change in the mutant sequence when compared to the wild type sequence. Go back to the Protein Tools homepage. You can do this by scrolling to the bottom of the screen and clicking on “Return”. Make sure that there are check marks in the boxes next to the sequences. Highlight the choice that says “GOR4 – Predict Secondary Structure of PS”. Once this choice is highlighted, click on “Run”. Now you will be brought to a new screen. Just click on “Submit”. A new screen will appear and your results will be shown: The top sequence is the wild type (you tell this by looking at the code “1lpe” compared to the mutant sequence found on the bottom; “1le2”. If you will look at the legend found below the sequences, you will see that alpha helices are colored red and beta sheets are colored blue. Now, count the number of alpha helices and beta sheets in the wild type protein sequence and in the mutant protein sequence. If you counted correctly, there are 5 alpha helices and 1 beta sheet in the wild type. However, there are 5 alpha helices and 2 beta sheets in the mutant sequence. Some of the helical structure of the wild-type protein has been changed to beta sheet structure. This tells us that the point mutation in the mutant protein sequence has caused a subtle conformational change in the protein structure. Next we'll do one last experiment, to see if we can determine why the protein structure might be affected in the mutant. PART VI: Determining the Isoelectric Point of the Proteins Think about what determines the structure of a protein. Chemical bonds between the amino acids do. For example, an amino acid with a plus charge, like arginine, might bond with a negative amino acid, like glutamate, to form an ionic bond in the protein that helps keep it together. The "isoelectric point" of a protein is a number between 0 and 14 that measures the charges on the protein. A higher isoelectric point means there are more positive charges on the protein (or fewer negative charges), and a lower the isoelectric point means there are fewer positive charges (and more negative ones). In this section we'll use a tool that predicts the isoelectric points of our proteins to see if there are changes in charge that might explain the change in structure. Go back to the Protein Tools homepage. You can do this by scrolling to the bottom of the screen and clicking on “Return”: Select the tool choice that says "PI -- Isoelectric Point Determination." Unfortunately, we can only run this tool on one protein at a time, so uncheck the mutant protein (1LE2) check box so we calculate the isoelectric point for the wild-type protein (1LPE) first. Then press the "Run" button: On the next screen just press the "Submit" button: On the results page, you will see a table of "pH" and "charge." The isoelectric point is the point where the protein has a net charge of zero. Scroll down to the bottom to find the isoelectric point, as shown below: Then go back to the Protein Tools menu using the "Return" button at the bottom: Next run the same experiment on the mutant protein. Uncheck the "1LPE" box and check the "1LE2" box, then run the program as before. The number you get for the isoelectric point should be different and lower. This means that the mutant protein has lost some positive charge. This positive charge, on the arginine amino acid that was replaced by cysteine in the mutant, must be important for the structure and function of the protein! CONCLUSION Why doesn't the mutant protein work right? We now have some important information, which we found using bioinformatics tools. The change in charge in the mutant apolipoprotein can be seen in the different isoelectric point of the mutant. We also saw using GOR4 that there is a small conformational change in the mutant protein. Remember that we couldn't see that change very well just looking at a picture of the two proteins. This conformational change turns out to be responsible for this form of the disease hypercholesterolemia. The changed shape in the mutant lipoprotein does not allow it to attach onto liver cells which would normally “eat” the cholesterol the lipoprotein delivers. So, instead, the cholesterol cannot be used up by these liver cells and remains in the bloodstream, which causes symptoms and threats such as those mentioned in the beginning of the tutorial.