Time series analysis and forecasting
advertisement

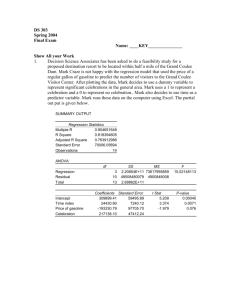
CHAPTER 15 Time Series Analysis page 651 15. Introduction page 651 Chapter 15 deals with the basic components of time series, time series decomposition, and simple forecasting. At the end of this chapter, you should know the following: The four possible components of a time series. How to use smoothing techniques to remove the random variation and identify the remaining components. How to use the linear and quadratic regression models to analyze the trend. How to measure the cyclical effect using the percentage of trend method. How to measure the seasonal effect by computing the seasonal indices. How to calculate MAD and RMSE to determine which forecasting model works best. Definition A time series is a collection of data obtained by observing a response variable at periodic points in time. Definition If repeated observations on a variable produce a time series, the variable is called a time series variable. We use Yi to denote the value of the variable at time i. Four possible components: Trend ( secular trend) -- Long term pattern or direction of the time series Cycle ( cyclical effect) -- Wavelike pattern that varies about the long-term trend, appears over a number of years e.g. business cycles of economic boom when the cycle lies above the trend line and economic recession when the cycle lies below the secular trend. Seasonal variation -- Cycles that occur over short periods of time, normally < 1 year e.g. monthly, weekly, daily. Random variation ( residual effect) --Random or irregular variation that a time series shows Could be additive: Yi = Ti + Ci + Si + Ii or multiplicative: Yi = Ti x Ci x Si xIi 1 Forecasting using smoothing techniques The two commonly used smoothing techniques for removing random variation from a time series are moving averages and exponential smoothing. Moving average: ( MA) Moving averages involve averaging the time series over a specified number of periods. We usually choose odd number of periods so we can center the averages at particular periods for graphing purposes. If we use an even period, we may center the averages by finding twoperiod moving averages of the moving averages. Moving averages aid in identifying the secular trend of a time series because the averaging modifies the effect of cyclical or seasonal variation. i.e. a plot of the moving averages yields a “smooth” time series curve that clearly shows the long term trend and clearly shows the effect of averaging out the random variations to reveal the trend. Moving averages are not restricted to any periods or points. For example, you may wish to calculate a 7-point moving average for daily data, a 12-point moving average for monthly data, or a 5-point moving average for yearly data. Although the choice of the number of points is arbitrary, you should search for the number N that yields a smooth series, but is not so large that many points at the end of the series are "lost." The method of forecasting with a general L-point moving average is outlined below where L is the length of the period. Forecasting Using an L-Point Moving Average 1. Select L, the number of consecutive time series values Y1, Y2. . . YL that will be averaged. (The time series values must be equally spaced.) 2. Calculate the L-point moving total, by summing the time series values over L adjacent time periods. 3. Compute the L-point moving average, MA, by dividing the corresponding moving total by L 4. Graph the moving average MA on the vertical axis with time i on the horizontal axis. (This plot should reveal a smooth curve that identifies the long-term trend of the time series.) Extend the graph to a future time period to obtain the forecasted value of MA. 2 Exponential smoothing: One problem with using a moving average to forecast future values of a time series is that values at the ends of the series are lost, thereby requiring that we subjectively extend the graph of the moving average into the future. No exact calculation of a forecast is available since the moving average at a future time period t requires that we know one or more future values of the series. Exponential smoothing is a technique that leads to forecasts that can be explicitly calculated. Like the moving average method, exponential smoothing de-emphasizes (or smoothes) most of the residual effects. To obtain an exponentially smoothed time series, we first need to choose a weight W, between 0 and 1, called the exponential smoothing constant. The exponentially smoothed series, denoted Ei, is then calculated as follows: Ei= W Yi+(1- W)Ei-1 (for i>=2) where Ei = exponentially smoothed time series Yi = observed value of the time series at time i Ei-1 = exponentially smoothed time series at time i-1 W = smoothing constant, where 0<= W <=1 Begin by setting E1=Y1 E2= W Y2+(1- W)E1 E3= W Y3+(1- W)E2 . . Ei= W Yi+(1- W)Ei-1 You can see that the exponentially smoothed value at time i is simply a weighted average of the current time series value, Yi, and the exponentially smoothed value at the previous time period, Ei-1. Smaller values of W give less weight to the current value, Yi. Whereas larger values give more weight to Yi The formula indicates that the smoothed time series in period i depends on all the previous observations of the time series. The smoothing constant W is chosen on the basis of how much smoothing is required. A small value of W produces a great deal of smoothing. A large value of W results in very little smoothing. Exponential smoothing helps to remove random variation in a time series. Because it uses the past and current values of the series, it is useful for forecasting time series. The objective of the time series analysis is to forecast the next value of the series, Fi+1. The exponentially smoothed forecast for Fi+1= Ei where Ei= W Yi+(1- W)Ei-1 3 is the forecast of Yi+1 since the exponential smoothing model assumed that the time series has little or no trend or seasonal component. The forecast Fi is used to forecast not only Yi+1 but also all future value of Yi. i.e. Fi = W Yi+(1- W)Ei-1, i = n + 1, n + 2, . . . This points out one disadvantage of the exponential smoothing forecasting technique. Since the exponentially smoothed forecast is constant for all future values, any changes in trend and/or seasonality are not taken into account. Therefore, exponentially smoothed forecasts are appropriate only when the trend and seasonal components of the time series are relatively insignificant. Forecasting: The Regression Approach Many firms use past sales to forecast future sales. Suppose a wholesale distributor of sporting goods is interested in forecasting its sales revenue for each of the next 5 years. Since an inaccurate forecast may have dire consequences to the distributor, some measure of the forecast’s reliability is required. To make such forecasts and assess their reliability, an inferential time series forecasting model must be constructed. The familiar general linear regression model represents one type of inferential model since it allows us to calculate prediction intervals for the forecasts. YEAR SALES t y 1 4.8 2 4.0 3 5.5 4 15.6 5 23.1 6 23.3 7 31.4 8 46.0 9 46.1 10 41.9 11 45.5 12 53 5 YEAR SALES t y 13 48.4 14 61.6 15 65.6 16 71.4 17 83.4 18 93.6 19 94.2 20 85.4 21 86.2 22 89.9 23 89.2 24 99.1 YEAR SALES t y 25 100.3 26 111.7 27 108.2 28 115.5 29 119.2 30 125.2 31 136.3 32 146.8 33 146.1 34 151.4 35 150.9 To illustrate the technique of forecasting with regression, consider the data in the Table above. The data are annual sales (in thousands of dollars) for a firm (say, the sporting goods distributor) in each of its 35 years of operation. 4 A scatter plot of the data is shown below and reveals a linearly increasing trend , so the first-order (straight-line) model E(Yi) = βo + β1i seems plausible for describing the secular trend. The regression analysis printout for the model gives R2 = .98, F = 1,615.724 (p-value < .0001), and s = 6.38524. The least squares prediction equation is Yi = Bo + B1i = .401513 + 4.295630i The prediction intervals for i = 36, 37, . . ., 40 widen as we attempt to forecast farther into the future. Intuitively, we know that the farther into the future we forecast, the less certain we are of the accuracy of the forecast since some unexpected change in business and economic conditions may make the model inappropriate. Since we have less confidence in the forecast for, say, i = 40 than for t =-36, it follows that the prediction interval for i = 40 must be wider to attain a 95% level of confidence. For this reason, time series forecasting (regardless of the forecasting method) is generally confined to the short term. Multiple regression models can also be used to forecast future values of a time series with seasonal variation. We illustrate with an example. EXAMPLE Refer to the 1991-1994 quarterly power loads listed in the attached Table . a. Propose a model for quarterly power load, y`, that will account for both the secular trend and seasonal variation present in the series. b. Fit the model to the data, and use the least squares prediction equation to forecast the utility company's quarterly power loads in 1995. Construct 95% confidence intervals for the forecasts. 5 Solution a. A common way to describe seasonal differences in a time series is with dummy variables. For quarterly data, a model that includes both trend and seasonal components is E(Yi) = Bo + Bli + B2X1 + B3X2 + B4X3 Trend Seasonal component where where i = Time period, ranging from i = 1 for quarter I of 1991 to i = 16 for quarter IV of 1994 Yi = Power load (megawatts) in time i X1_= 1 if quarter I O if not X3 =1 if quarter III X2 =1 if quarter II O if not Base level = quarter IV O if not The coefficients associated with the seasonal dummy variables determine the mean increase (or decrease) in power load for each quarter, relative to the base level quarter, quarter IV. b. The model is fitted to the data using the SAS multiple regression routine. The resulting SAS printout is 2 shown below. Note that the model appears to fit the data quite well: R = .9972, indicating that the model accounts for 99.7% of the sample variation in power loads over the 4-year period; F = 968.962 strongly supports the hypothesis that the model has predictive utility (p-value = .0001); and the standard deviation, Root MSE = 1.53242, implies that the model predictions will usually be accurate to within approximately +2(1.53), or about +3.06 megawatts. Forecasts and corresponding 95% prediction intervals for the 1995 power loads are reported in the bottom portion of the printout . For example, the forecast for power load in quarter I of 1995 is 184.7 megawatts with the 95% prediction interval (180.5, 188.9). Therefore, using a 95% prediction interval, we expect the power load in quarter I of 1995 to fall between 180.5 and 188.9 megawatts. Recall from the Table that the actual 1995 quarterly power loads are 181.5, 175.2, 195.0 and189.3, respectively. Note that each of these falls within its respective 95% prediction interval shown. Many descriptive forecasting techniques have proved their merit by providing good forecasts for particular applications. Nevertheless, the advantage of forecasting using the regression approach is clear: Regression analysis provides us with a measure of reliability for each forecast through prediction intervals. However, there are two problems associated with forecasting time series using a multiple regression model. PROBLEM 1 We are using the least squares prediction equation to forecast values outside the region of observation of the independent variable, t. For example, suppose we are forecasting for values of t between 17 and 20 (the four quarters of 1995), even though the observed power loads are for t values between 1 and 6 16. As noted earlier, it is risky to use a least squares regression model for prediction outside the range of the observed data because some unusual change—economic, political, etc.—may make the model inappropriate for predicting future events. Because forecasting always involves predictions about future values of a time series, this problem obviously cannot be avoided. However, it is important that the forecaster recognize the dangers of this type of prediction. PROBLEM 2 Recall the standard assumptions made about the random error component of a multiple regression model . We assume that the errors have mean 0, constant variance, normal probability distributions, and are independent. The latter assumption is often violated in time series that exhibit short term trends. As an illustration, refer to the plot of the sales revenue data. Notice that the observed sales tend to deviate about the least squares line in positive and negative runs. That is, if the difference between the observed sales and predicted sales in year t is positive (or negative), the difference in year t + 1 tends to be positive (or negative). Since the variation in the yearly sales is systematic, the implication is that the errors are correlated. Violation of this standard regression assumption could lead to unreliable forecasts. Measuring forecast accuracy (MAD) Forecast error is defined as the actual value of the series at time i minus the forecast value, i.e. Yi - Ŷ i. This can be used to evaluate the accuracy of the forecast. Two of the procedures for the evaluation are to find the mean absolute deviation (1) MAD= | Yi - Ŷ i | /N and (2) RMSE= ( Yi - Ŷ i)2 /N Descriptive Analysis: Index numbers Time series data like other sets of data are subject to two kinds of analyses: Descriptive and inferential analysis The most common method to describe a business or economic time series is to compute index numbers. INDEX NUMBERS Definition: An index number is a number that measures the change in a variable over time relative to the value of the variable during a specific base period. The two most important are price index and quantity index. Price indexes measure changes in price of a commodity or a group of commodities over time. The Consumer Price Index (CPI) is a price index, which measures price changes of a group of commodities over time. On the other hand, an index constructed to measure the change in the total number of commodities produced annually is a good example of a quantity index, computations here could be complicated. 7 Simple Index Numbers: Definition: When an index number is based on the price or quantity of a single commodity, it is called a simple index number. e.g. to construct a simple index # for the price of silver between 1975-1995, we might choose a base period, say 1975. To calculate the simple index number for any year, we divide that year’s price by the price during the base year and multiply by 100 e.g. for 1980, silver price index =(20.64/4.42)*100=466.97 The index # for the base year is always 100. The increase 466.97 – 100= 366.97 gives the increase in the price of silver over the year. Measuring the cyclical effect: Differences between cyclical and seasonal variation is the length of time period. Also, seasonal effects are predictable while cyclical effects are quite unpredictable. We use percentage of trend to identify cyclical variation. The calculation is carried out as follows: (1) Determine the trend line (by regression) (2) For each time period, compute the trend value Ŷ (3) The % of trend is (Y/ Ŷ)*100 See study guide pages 294- 296 Whether graphed or not, we should look for cycle whose peaks and valleys and time periods are approximately equal. However, in practice, random variation is likely to make it difficult to see cycles. Measuring the Seasonal Effect: Seasonal effect may occur within a year, month, week or day. To measure seasonal effect, we construct seasonal indexes, which attempt to gauge the degree to which the seasons differ from one another. One requirement for this method is that we have a time series sufficiently long to allow us to observe the variable over several seasons. The seasonal indexes are computed as follows: (1) Remove the effect of seasonal and random variation. This can be accomplished in one of two ways: First: Calculate moving average by setting the number of periods in the moving average equal to the number of types of seasons, e.g. if the seasons represent quarters, then a 4-period moving average will be most suitable. The effect of the Mi is seen as follows: Assuming a multiplicative model, Yi = Ti x Ci x Si xIi 8 MA removes Si and Ri leaving MAi = Ti x Ci By taking the ratio of the time series and the MA, we obtain Yi / MAi = Ti x Ci x Si xIi / Ti x Ci = Si xIi Second Method: If the time series is not cyclical, we have Yi = Ti x Si xIi So, Yi/Ŷi= Si xIi Since Ŷi represents the trend = Ti The two methods thus yield the same results. (2) For each type of seasons, calculate the average of the ratios in step 1. This procedure removes most of the random variation. The average is a measure of seasonal differences. The seasonal indexes are the average ratio from step2 adjusted to ensure that the average seasonal index is 1. Detecting Residual Correlation: The Durbin—Watson Test Many types of business data are observed at regular time intervals thus giving rise to time series data. We often use regression models to estimate the Trend component of a time series variable. However, regression models of time series may pose a special problem. Because business time series tend to follow economic trends and seasonal cycles, the value of a time series at time t is often indicative of its value at time (i + 1). That is, the value of a time series at time t is correlated with its value at time (i + 1). If such a series is used as the dependent variable in a regression analysis, the result is that the random errors are correlated, and this violates one of the assumptions basic to the least squares inferential procedures. Consequently, we cannot apply the standard least squares inference-making tools and have confidence in their validity. In this section, we present a method of testing for the presence of residual correlation. Consider the time series data in the Table below, which gives sales data for the 35 year history of a company. The computer printout shown below gives the regression analysis for the first-order linear model Yi = B0 + B1i + e This model seems to fit the data very well, since R2 = .98 and the F value (1,615.72) that tests the adequacy of the model is significant. The hypothesis that the B1 coefficient is positive is accepted at almost any alpha level (i = 40.2 with 33 df) The residuals e-hat = Y - (B0 + B1i) are plotted in . Note that there is a distinct tendency for the residuals to have long positive and negative runs. That is, if the residual for year i is positive, there is a tendency for the residual for year 9 (i+ 1) to be positive. These cycles are indicative of possible positive correlation between residuals. T A B L E A Finn's Annual Sales Revenue (thousands of dollars) YEAR SALES t y 1 4.8 2 4.0 3 5.5 4 15.6 5 23.1 6 23.3 7 31.4 8 46.0 9 46.1 10 41.9 11 45.5 12 53 5 YEAR SALES t Y 13 48.4 14 61.6 15 65.6 16 71.4 17 83.4 18 93.6 19 94.2 20 85.4 21 86.2 22 89.9 23 89.2 24 99.1 YEAR SALES t y 25 100.3 26 111.7 27 108.2 28 115.5 29 119.2 30 125.2 31 136.3 32 146.8 33 146.1 34 151.4 35 150.9 For most economic time series models, we want to test the null hypothesis Ho: No residual correlation against the alternative Ha: Positive residual correlation exists since the hypothesis of positive residual correlation is consistent with economic trends and seasonal cycles. The Durbin-Watson d statistic is used to test for the presence of residual correlation. This statistic is given by the formula at the bottom of page 714 and has values that range from 0-4 with interpretations as follows: Summary of the interpretations of the Durbin-Watson d statistic 1. If the residuals are uncorrelated, d is approx. = 2 2. If the residuals are positively correlated, d < 2, and if the correlation is very strong, d is approx. = 0 3. If the residuals are negatively correlated, d > 2, and if the correlation is very strong, d is approx. = 4 10 As indicated in the printout for the sales example, the computed value of d, .821, is less than the tabulated value of dL, 1.40. Thus, we conclude that the residuals of the straight-line model for sales are positively correlated. Moving averages can also be used to provide some measure of seasonal effects in a time series. The ratio between the observed Yi and the moving average measures the seasonal effect for that period. 11