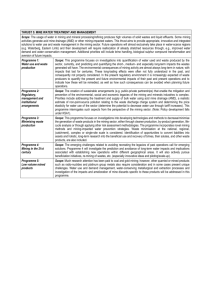
Data Mining Stages
advertisement

Data Mining Process 1. The SEMMA method from SAS institute Sample the data by creating one of more tables Explore the data by searching for anticipated relationships, unanticipated trends and anomalies in order to gain understanding and ideas. Modify the data by creating, selecting, and transforming the variables. Model the data by using the analytical tools to search for a combination of the data that reliably predicts a desired outcome. Assess the data by evaluating the usefulness and reliability of the findings from the data mining process. Input data Plot data Transform variables Select variables/ features Partition data Regression Decision tree Assessment Cost /score Neural net Fig. 1- SAS Institute Enterprise Miner Analysis Diagram (uses SEMMA) 2. Realistic data mining process Caveat: the process as well as all phases/steps are iterative; the sequence of steps/phases depends on the real-life circumstances. Data preparation phase (i.e. “turn a mess of data into an organized whole”): Data cleaning: consistency, stale information, typos Missing values: fill them in, ignore them Data derivation: derive composite features Merging data from several databases: using a flat file (usually) Transforming raw data: normalizing, smoothing, scaling, encoding Dealing with outliers Define a study (i.e. selecting data to mine and output, phase I; i.e. “what are we doing here”): Define the goal, for example: Define the characteristics (i.e. the profile) of patients who have allergies Profile the patients who recover in 0-2 weeks, 2-3 weeks, 3-6weeks, and 6+ weeks Profile patients who use mild or high pain relievers in order to reduce pain Identify which features are of interest, for example: What features are useful to profiling people with allergies? How descriptive are the fields in the current features? What types of features should we include? Identify input and output features Selecting data to mine and output, phase II (i.e. “how can I mine only a subset of data and get good results if I have a large database”): “Shrink” the table along X axis (i.e. reduce number of columns either by deleting or merging features): Feature selection and reduction (e.g. by comparing mean and variance, by entropy, by principal component analysis) Feature composition (e.g. by merging using principal components) Reducing feature values (e.g. by discretizing feature values using binning) Merging input intervals (e.g. by Chi-square) “Shrink” the table along Y axis (i.e. reduce number of rows either by deleting or merging samples/cases): Cases selection and reduction Build the model and mine it: Pick suitable data mining strategy(ies) and tool(s) Validate the model: Test the model on data which wasn’t used to build the model. If you built several models (you did, most likely), determine which ones are the best Calculate the error Issues: is the model accurate, understandable, lets you know where it’s confident and where it isn’t and why (i.e. provides quantitative assessment with complex conclusions), lets you trace which inputs affect the output; is it fast 3. Data Mining Techniques Anatomy Each data mining technique can be classified into the following categories based on the functionality provided by the technique (i.e. the primary data mining task): Classification Regression Clustering Summarization Dependency modeling Change and Deviation detection All data mining techniques can also be classified as using: supervised or unsupervised learning; and using inductive or deductive learning. 4. Menu of data mining strategies/tools Statistical methods: Bayesian inference Logistic regression ANOVA analysis Log-linear models Cluster analysis: Divisible algorithms Agglomerative hierarchical clustering Partitional clustering Incremental clustering Decision trees and rules: CLS algorithm 1D3 algorithm C4.5 algorithm Prunning algorithm Association rules: Market basket analysis Apriori algorithm www path traversal patterns Text mining Artificial neural nets: Multilayer perceptrons with backpropagation learning Kohonen networks Genetic algorithms Fuzzy Inference Systems N-dimensional visualization methods