Lecture 3 Make the Molecules
advertisement

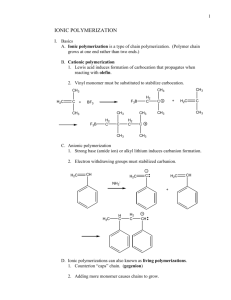
POLYMERS 3/PH/AM Lecture 3 Make the Molecules This lecture is divided into three parts: (1) Types of Simple Polymerization (2) Statistics of Polymerization (3) Copolymerization (1) TYPES OF SIMPLE POLYMERIZATION Addition Chain-Growth Condensation Step-Growth ‘Living’ People used to use these regularly, but they relate to chemical processes rather than the statistics of polymerization. Now we use these. Chain Growth Polymerization Here we have a lattice of monomer molecules (light grey). A site is activated (by a chemical initiator, by radiation, or whatever) – this is the very dark grey circle. This then adds monomer after monomer to the chain (dark grey), while the activity (star) is transferred to the end of the growing chain. Some kind of process deactivates the growing end, and then we have a polymer molecule in solution in the monomer. The characteristic of this type of polymerization is that it gives complete chains in solution in monomer. Step-Growth Polymerization Here we have a lattice of monomer molecules (light grey). There is no need to activate a site: temperature or a catalyst enables the reaction. All the time, at various places, one monomer adds to another forming a dimer. Dimers can add monomers, making trimers, or two dimers can add, making a tetramer. And so the process goes on. During this type of polymerization, we have a mass of partly grown polymer chains, .all of which are combining to make bigger molecules. Living Polymerization. Here we have a fixed number of active sites which stay alive. The monomer may be used up, but if we add more than these sites continue to grow. One can imagine them as corals on a reef which only grow when they are fed. (2) STATISTICS OF POLYMERIZATION Why do we want to know molecular weights? Weaker PROPERTIES Stronger Lower MOLECULAR WEIGHT Higher Easier PROCESSING Harder Here we have an example of Step Growth Polymerization, where the reaction proceeds, making bigger and bigger molecules. We show the accompanying change in properties. This particular one is a condensation polymerization, because water is eliminated during the reaction. But that is secondary. To sort that sort of distinction out, go to: http://www.psrc.usm.edu/macrog/synth.htm Self Condensation of HO(CH2)9COOH Mn Number of ester groups Spinnability 4,170 25 Absent 5,670 33 Short fibers, no cold drawing 7,330 43 Long fibers, no cold drawing 9,330 55 Long fibers that cold draw 16,900 99 Easy to spin and cold draw 25,200 148 Spins at T>210°C and cold draws Data from Organic Chemistry of Synthetic High Polymers, R. W. Lenz, 1967, p 66. Step-growth statistics Consider the self-condensation of A-B and the stoichiometric polymerization of A-A with B-B where A may react only with B and vice-versa. This is equivalent to determining the probability of finding a polymer molecule containing x structural units of the form A-B [A-B]x-2 A-B Let p = probability that a B group has reacted. (This is equivalent to the fraction of B groups reacted.) 1 – p = probability that a B group is unreacted In virtually all cases (except for polyurethanes) one can assume that the reaction events are independent. Thus, the probability that an x-mer has formed is given by p x –1 (1-p) Most Probable Distribution: Number Fraction P.J. Flory, Principles of Polymer Chemistry, 1953, p 32 Number Average Molecular Weight, Mn Most Probable Distribution: Weight Fraction P.J. Flory, Principles of Polymer Chemistry, 1953, p 32 Weight Average Molecular Weight, Mw The breadth of the Distribution is usually characterized by the value Mw / M n Otherwise known as the Polydispersity For step-growth polymers, the equations imply that: as p tends to 1, the polydispersity tends to 2. Chain-growth Polymerization Consider a chain growing until random something stops it. Let p = probability that it keeps on going. 1 – p = probability that it gets stopped Thus, the probability that an x-mer formsS is given by p x –1 (1-p) Most Probable Distribution: Number Fraction Number Average Molecular Weight, Mn Most Probable Distribution: Weight Fraction Weight Average Molecular Weight, Mw the Polydispersity Mw / M n Which is the same as we got for step-growth polymerization. However, things other than simple stoppage can happen in chain growth polymerization: two growing chains can join their two active ends, etc., and these can give rise to different statistics. Notice that in ideal chain growth polymerization, the average molecular weights stay the same, while the number of polymer molecules goes on increasing; while in step growth polymerization, the average molecular weight keeps on increasing, while the total number of molecules goes down. (a) This shows the number and weight distributions for a chain growth polymer, with random statistics. Stem length is taken relative to the number average chain length. The number distribution falls away from the left, while the weight distribution rises to a peak and then falls off. These curves are practically identical to the step-growth one, so why bother? In the chain-growth polymerization, the mean stem length, ideally, remains the same all through, while the total mass of polymer increases at the expense of monomer. In the chain growth weight distribution, the peak continuously shifts to higher values. (b) This shows the mass distribution plotted as a function of log molecular weight. This approximates to a log-normal distribution with a polydispersity of 2 (again!) This shows a cumulative distribution for the above statistics. Only 27% of the mass of material is made of molecules shorter than the number average (rel. stem length = 1) while 40% is longer than the number average (r.s.l. = 2). Living Polymers Each living site receives monomer molecules adding at random, rather like a puddle receiving random raindrops (we assume that the area of the puddle remains constant!). Systems like these tend to follow a: Poisson Distribution: For largeµ, the Poisson distribution looks very much like the Gaussian. However, it has this special feature, in that the mean and variance are equal, so: Molecular Weight Distributions achieved in Practice Method Polydispersity Stereospecificity Natural Proteins 1.0 Anionic Polymerization ‘Living’ Polymers 1.02 – 1.5 None Ordinary Chain Polymerization 1.5 – 3 None Ziegler-Natta (with catalyst particles) 2 – 40 High Metallocene (directive molecular catalysts) 2 – 2.5 High Cationic Broad None Step Polymerization 2.0 – 4 None Modified after Sperling, p. 95 Perfect COPOLYMERIZATION First we will deal with ‘light’ copolymerization, where one monomer is in the overwhelming majority. A very common example of this is so-called linear low density polyethylene. Here a small percentage of a comonomer is added, for example hexane (C6) is added to the ethylene giving a polyethylene with butyl (C4) branches. Four models of ‘light’ copolymerization, for example ethylene copolymerized with a few % of a heavier monomer. a: uniformly placed branches: too good to be true! (b) statistical random branching – the ideal distribution. All molecules are similar, and branch free lengths are distributed in a similar fashion to molecular lengths in chain growth. Modern metallocene catalysed PEs approach this ideal. (c) Each molecule is statistically randomly branched, but each molecule has a different average comonomer content. This is typical of Ziegler PEs. (d) Different parts of the molecule different. Not found in theory and/or practice? Different Types of Copolymer Random: This is a ‘heavy’ version of what we studied in the page above. Very common. Alternating: Found where each monomer insists on adding to the other. Rather than a copolymer of A and B, it can be regarded as a homopolymer of AB. Block: These are almost always living polymers, where one changes the monomer once or twice during the polymerization. Graft: Here one takes polymer one, and with a help of a graft agent produces active sites along the chain for monomer two to grow. Here we show the rate constants for M1 and M2 adding to chains with active ends M1* or M2*. These are used in the law of mass action. In general, if A is adding to B, then: d(AB)/dt= k[A][B] here we compare chains with either M1 or M2 at the end. Here we show the disappearance of each type of monomer: it is the sum of adding to M1* and M2*. What determines the composition is not the four k’s separately, but the two reactivity ratios. Of course, if the k’s are very low, the reaction will take till the cows come home, and if they’re too high, things will go off like a bomb. This is the easiest situation to envisage. r1×r2 = 1 is called the ideal polymerization, because it resembles ideal solutions in behaviour. But we won’t worry you with that one. This makes alternating copolymers. If both r1 and r2 were very high, this would make a block copolymer. But this does not occur in practice, so block copolymers are made by living polymerizations. Crosslinked Polymers This is a schematic of an Epoxy Resin This is a (very) schematic of Rubber before and after Crosslinking