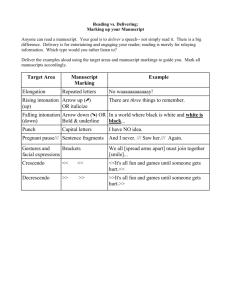
Introduction and Background
advertisement

Introduction and Background Introduction and Background Chapter 1 1 Introduction Intonation is defined by Beckman (1995) as ‘all aspects of the perceived pitch pattern that the speaker intends for the hearer to use in understanding the utterance, or that the hearer does use whether intentionally controlled by the speaker or not’. These pitch patterns of speech have been described by O’Connor and Arnold (1973) as significant, systematic, and language-specific. Taken together, the terms significant and systematic indicate why intonation is assumed to have phonological structure. In traditional analyses of segmental structure, phonology has been seen as concerned with those differences which a given language exploits to convey lexical identity, and thus to convey different meanings. Similarly, two utterances which differ solely in intonational structure can differ in meaning. Additionally, just as the segmental inventories of languages consist of a limited number of phonemes, the number of distinctive pitch patterns is limited. The third characteristic of intonation, its language-specificity, forms the topic of the present study. Phonemic inventories vary across languages, and so do the inventories of possible pitch patterns. Two intonation systems are contrasted here; those of Southern Standard British English and Northern Standard German. In the literature, views on the presence or absence of cross-linguistic differences between the intonation systems of these languages have, at times, been extreme. Some authors have considered the two systems to be identical while others have asserted them to be fundamentally different. Thus, there is currently no consensus as to whether or not the two languages make use of the same basic set of intonation patterns. This investigation, therefore, focuses on basic structural aspects of intonation, that is, the inventory of pitch patterns available in the two languages. Other aspects of cross-linguistic variability such as the combination of patterns, their frequency of occurrence or their meanings in discourse are not addressed; these can only properly be studied once the taxonomy of distinctive patterns has been established. The linguistic framework in which the comparison will be made is the Autosegmental-Metrical framework (for an overview see Ladd, 1996). This framework was chosen principally for its flexibility. Earlier traditions, such as that of the British 1 Introduction and Background school (e.g. Crystal, 1969, O’Connor and Arnold, 1973) describe intonation in terms of a single, unilinear representation, either as a set of holistic tunes or as linear successions of auditory categories. However, within the Autosegmental-Metrical (AM) framework, tunes may be represented at several linguistic levels, both phonetic and phonological. This may be vital for cross-linguistic studies, as it permits analyses in which two languages may be shown to differ at one level of representation and be similar at another. The hypothesis is that previous disagreements as to whether English and German intonation are very similar or very different may be resolved when a sufficiently rich system is used for analysis. Ladd (1996: 119) suggests that cross-linguistic differences among intonation languages may be classified using a taxonomy of parameters derived from the description of segmental phonology and phonetics within British linguistics. According to this taxonomy, distinctions in intonational structure may be systemic, phonotactic, realisational or semantic. Systemic refers to differences in the inventory of intonational categories; realisational to distinctions in the way these categories are realised. Phonotactic refers to differences in the permitted structure of tunes, and semantic involves differences in intonational meaning; for instance, the same tune may signal continuation in one language and finality in another. The cross-linguistic study presented here will concentrate on systemic and realisational differences, on the assumption that these have to be established before differences in intonational meaning or function can be investigated1. 1.1 Outline The first two chapters of this study are introductory. The following two are corpus-based; they present the findings of auditory and acoustic analyses of directly comparable German and English speech data. Chapters 5 and 6 are experimental; they take up hypotheses arising from the corpus analyses presented in Chapters 3 and 4. The final chapter presents a summary and conclusions. Chapter 1 summarises previous studies of German and British English intonation. All comparative studies predate the advent of autosegmental-metrical representations, and therefore, influential monolingual studies of each language within the autosegmental-metrical tradition will also be reviewed. Note that it is commonly accepted that the relationship between accent placement and focus is highly similar in English and German. See Max Planck Institute Annual report 1996: 13 (Ruiter and Wilkins, 1996, eds.) for a study on accent placement and anaphoric reference carried out by the present author which shows that in German, accenting and deaccenting work in the same way as has been shown for English and, incidentally, Dutch (see Gussenhoven, 1992). 1 2 Introduction and Background Chapter 2 discusses methodological issues which arise within the autosegmentalmetrical framework and develops the basic structure of the descriptive system to be used in this study. Additionally, the cross-linguistic corpus of speech data collected for the purposes of the present study, and the presentation of evidence are described. Chapter 3 presents a corpus analysis of Northern Standard German, which has been less extensively studied than Southern British English. The phonological and phonetic properties of the data are presented and illustrated with fundamental frequency traces. This involves the elaboration of the basic descriptive system developed in Chapter 2. Chapter 4 is comparative, making use of data from a parallel English corpus. Hypotheses about cross-linguistic differences and similarities are developed. It is proposed that the languages may be represented as having the same underlying phonological structure but differing in phonetic implementation. Chapters 5 and 6 present experimental investigations of two hypotheses emerging from Chapters 3 and 4. Chapter 5 provides systematic cross-linguistic evidence suggesting that English and German differ in pitch accent accommodation effects, and Chapter 6 shows a difference in the acoustic implementation of downstep. Chapter 7 summarises and discusses the evidence. It concludes that English and German share a common inventory of phonological representations but differ in the way these representations are realised phonetically. 2 Past Research on German and English Intonation The following review of contrastive studies concentrates, as far as possible, on standard varieties of German and British English. The contrastive studies discussed were carried out in a variety of descriptive frameworks, all of which may be described as ‘holistic’, that is, none of them explicitly described intonation with more than one level of linguistic representation. 2.1 Contrastive studies 2.1.1 General remarks In the literature, views on the contrast between English and German intonation have been extreme; some authors have claimed the intonation systems of the languages to be fundamentally different, but others have asserted them to be identical (see Scuffil, 1982 for an overview). Barker (1925), for instance, suggests that English and German intonation are fundamentally different. In her handbook of German intonation for English 3 Introduction and Background students, she contrasts an English passage transcribed with English intonation with the same passage transcribed with German intonation. ‘The ludicrous effect produced by the wrong intonation of his mother tongue’, Barker points out, ‘will convince the student, if nothing else can, that English and German intonation are fundamentally different’. German intonation is claimed to differ most clearly from that of English in that it is ‘jerky’ and should not be spoken with an ‘indolent drawl’. The pitch variations in German speech are greater, and the quiet, even tones of English intonation need to be replaced by louder and more energetic tones. Fifty years later, Pürschel (1975) would appear to support Barker’s view. He argues that the apparent inability of German learners of English to use intonation patterns of English appropriately even after several years of teaching suggests fundamental differences. Fundamental cross-linguistic differences are claimed also in Féry’s (1993) study of German intonation (see section 2.2.3.4 below). However, the hypothesis that English and German intonation are quite different is not supported by the findings of contrastive studies by Kuhlmann (1952: 206), Schubiger (1965), Esser (1978: 51) and Scuffil (1982: 72). These authors assert that differences between English and German intonation are not fundamental. However, none of the authors is explicit on the nature of the claimed non-fundamental differences. Yet other authors have claimed that English and German intonation are virtually identical. Kingdon (1958: 267), for instance, points out that English and German have very similar intonation systems, and Moulton (1966) suggests that the systems are not only identical but also used in much the same way. In the literature, the discrepant views on contrastive German and English intonation are accompanied by two further conceptions. Firstly, authors commonly state that too little contrastive information is available German and English intonation (Moulton, 1966, Pürschel, 1975, Bald, 1976)2, and secondly, authors point out that we know more about the intonation of English than about that of German. As early as 1965, Schubiger stated that the investigation of English intonation had reached a point where its form had been explored almost to perfection. The intonational structure of German, on the other hand, had been explored less thoroughly. Almost twenty years later, Scuffil (1982) and Fox (1984) still point to widespread disagreement about the basic facts of German intonation. Since Scuffil’s (1982) contrastive study of English and German intonation, the most recent to my knowledge, a great deal of further research has been carried out on the intonation of English, and models such as the autosegmental-metrical system proposed in Pierrehumbert (1980) have been widely adopted. Within the study of Anderson (1979) would appear to be an exception. He points out that from the literature, a relatively clear picture of structural similarities and differences emerges. Scuffil (1982: 74), however, contradicts Anderson’s assertion and points to wide disagreement in the literature. 2 4 Introduction and Background German intonation, however, no comparable consensus is apparent (Jin, 1990:3, Möbius, 1993: 31). 2.1.2 Specific remarks The specific remarks summarised in this section will be restricted to ‘realisational’ and ‘systemic’ cross-linguistic differences. Unfortunately, explicit comparative remarks are rare, and again, more detailed systemic and realisational information appears to be available for English (Bald, 1976:45). Isolated remarks on realisational differences come from a set of comparative studies involving American English and German as well as other languages carried out by Delattre and colleagues in the sixties (1965a, 1965b). Delattre (1965) suggests that in German, the rising part of a falling accent takes the shape of an ‘S’, followed by a sharp fall to a flat low level which give the impression of being separated from what precedes. He then compares the effect to English speakers hearing the sequence street-car level as street | car-level (other things being equal). In English, the ‘S’ is reversed, and constitutes the falling, rather than the rising part of the accent. This observation led Delattre, Poenack and Olsen (1965) to suggest that in English the general form of intonation is wave-like, whereas in German it can be compared to the blade of a saw. German English I re - MEM-ber it I re - MEM -ber it. Figure 1 Phonetic differences between English and German intonation (adapted from Delattre, 1965); note that English and German intonations were produced on an English text). Anderson (1979) describes the difference between English and German intonation illustrated in Figure 1 as one involving ‘falling’ vs. ‘rising’ emphasis in the pitch accent. Additionally, he suggests a number of rather general tonal and rhythmic differences between German and English. Firstly, the ‘neutral’ pattern in English and German is said to be realised differently. In German, the pattern is the equivalent of a ‘flat hat’, that is, rising pitch on the first accented syllable followed by falling pitch on the second (see ‘t Hart, Collier and Cohen, 1990 for the term ‘flat hat’). In English, the first and second accents are rising-falling. In short sentences, however, ‘declarative falls’ and 5 Introduction and Background ‘interrogative rises’ are claimed to be near-identical, and generally, the suggestion is that the basic tonal inventory is very similar. A minor difference characterises the stretch between the last accent in the phrase and the following boundary, which is said to be lower in pitch and more monotonic in German. Anderson also suggests rhythmic differences. German speech is said to give ‘more equal weight’ to each syllable and contain longer series of unstressed syllables whereas American English is claimed to be characterised by a stronger ‘stress beat’. Gibbon (1984:35) informally lists a number of cross-linguistic differences which have been claimed to distinguish English and German. German pitch contours are claimed to have a higher proportion of level tones, level stretches and jumps between levels rather than glides; and compound tones tend to be less frequent than in English (except in dialects). However, Gibbon also points out that observations of this kind are doomed to remain atomistic unless the broader framework of language use is taken into account. A successful comparison needs to consider factors such as speaking style and register; otherwise, ‘the systems’ of two languages one appears to contrast may, in fact, be ‘phantoms’. Finally, Trim (1988: 240) states that German speakers tend to treat all nonnuclear prominent syllables alike (mid to high level or low rising, according to region) and this may produce an effect of monotony and lack of rapport in an English listener. Moreover, German speakers are said to use intensity rather than pitch range for emphasis (some support for this claim has been provided recently in Gut, 1995)3 and this may sound aggressive to English listeners. English speakers, on the other hand, are said to make use of the first stressed syllable in an intonation phrase as an index of cheerfulness, arranging subsequent syllables on a descending scale. In German, this feature is said to be altogether absent. Trim suggests that this may mean that German speakers fail to establish the emotional atmosphere in a way expected by an English interlocutor. Additionally, in German discourse, the end of a turn is said to be commonly signalled by a falling nuclear tone. This is likely to be perceived by English listeners as an attempt to impose a belief. In English, on the other hand, turns are frequently concluded with rising or falling-rising tones which are said to invite comment from a listener. More generally, Trim points out that German intonation may make speakers sound bleak, dogmatic or pedantic, and as a result, English listeners may consider them uncompromising and selfopinionated (often to the German speakers’ surprise). Germans, on the other hand, feel that the pitch of an English speaker’s voice wanders meaninglessly if agreeably up and down. Additionally, ‘they [the English speakers] often turn out to have meant something quite different from what they actually said, showing them to be devious and hypocritical Similar observations may have led Klinghardt (1920: 23) to point out that ‘Wir Deutsche sind bei allen unseren germanischen Brüdern weithin als Schreier bekannt’ (‘among our Germanic brothers, we Germans are well known to be yellers’). 3 6 Introduction and Background behind that infamous snobbish reserve and meretricious facade of gentleness, such that butter would not melt in the mouth!’ (Trim, 1988: 244). 2.1.3 Summary and discussion A survey of the relatively small number of previous studies comparing English and German intonation suggests that authors have generally agreed that we know very little about this comparison, but disagreed on almost all aspects that have been investigated. Why might this disagreement have arisen? Firstly, because researchers have compared information collected in different descriptive traditions, focusing on different aspects of intonational structure, and may have described different speaking styles characterised by different realisations of the languages’ intonational systems. The problem does not only apply to cross-linguistic comparisons; it is compounded by similar difficulties applying specifically to German. Scuffil (1982: 51) points out that studies of German intonation are not only marked by a variety of theoretical approaches, but there is also less agreement on the facts than is the case for English. Similarly, Möbius (1993:1) states that even the attempt to survey studies investigating German intonation is considerably hindered by individual contributions being based on completely different theoretical assumptions. Less agreement on the intonational phenomena to be described emerges than from studies investigating English intonation. A second reason may be that researchers have addressed more than one of the linguistic functions of intonation at a time. Intonation has multiple functions in speech, intonation patterns play a role in discourse, they may signal paralinguistic information such as tenderness or anger, they may convey semantic information such as ‘nonroutineness’ and they may signal syntactic structure. Accounts of English and German which combine several aspects of intonation in its description without explicitly motivating the combination may have complicated cross-linguistic comparisons. A third reason may be that researchers have assumed that intonation could be modelled with only one level of linguistic representation, the exact status of this representation being unclear. Were it the case that English and German differed at one level of representation but not at another, then a unilinear system would not be able to deal with this. Studies within a unilinear system might then come up with either the ‘highly similar’ or the ‘very different’ view, depending on which aspect of intonation they investigated, or whether their investigative technique was auditory or instrumental. However, before the 1970s, no widely accepted non-holistic framework for the description of intonation was available. Since then, however, considerable theoretical advances have been made. The ‘autosegmental-metrical framework’, which has become widely accepted, may be said to combine O’Connor and Arnold’s three premises of intonational significance, 7 Introduction and Background systematicity and language-specificity with a departure from the unilinear representation of intonation. Instead, perceived intonation contours are broken down into a number of linguistic representations, which allow, for instance, a clear separation between crosslinguistic differences involving the phonological system of a language and those reflecting phonetic surface distinctions arising despite a shared phonological inventory. This theoretical advance, combined with technological progress which allows extensive speech corpora to be stored, labelled and widely disseminated, has opened up new avenues for cross-varietal research . 2.2 Monolingual Autosegmental studies The following sections will provide a brief summary of the autosegmental-metrical framework (for a comprehensive overview of the autosegmental-metrical framework see Ladd, 1996). This will be followed by a more detailed presentation of those autosegmental-metrical studies on which the system used here was based. 2.2.1 The autosegmental-metrical framework Researchers working within the autosegmental-metrical framework postulate that English and German tunes may be represented as having more than one level of linguistic representation. Basic to all systems is the assumption that intonation patterns may be decomposed into a number of primitives (primitive only at the intonational level, as each represents a synchronisation of two prosodic events, one tonal and one rhythmic). In English and German these primitives are pitch accents, that is, pitch movements anchored to stressed syllables, and boundary tones, which are pitch movements accompanying rhythmic discontinuities at the phrase edge4. The tonal properties of primitives are transcribed by using the letters H and L, which stand for high and low events in fundamental frequency and pitch, and the rhythmic properties by assigning a ‘*’ following the letter transcribing the tone associated with a stressed syllable in the case of pitch accents and a ‘%’ in the case of boundary tones. In representations of English and German intonation, pitch accents are commonly assumed to be either monotonal or bitonal, and boundary tones to be monotonal (see Pierrehumbert, 1980, Ladd, 1983a, Gussenhoven, 1984, Beckman and Pierrehumbert, 1986, Pierrehumbert and Beckman 1988 and Lindsey, 1985 for English, and Wunderlich, 1988, Uhmann, 1991 and Féry, 1993 for German). The primitives are used to transcribe intonation at the phonological level, and languages may differ in their inventory of primitives. The phonological representation is 4 For pitch accent theory see Bolinger, e.g. 1958, 1986. 8 Introduction and Background mapped onto a phonetic realisation via a set of phonetic realisation rules, which are again language-specific (note that in this study, and with respect to intonation, ‘phonetic’ will refer to the combined auditory impressions of pitch, length and loudness). Some authors assume one level of intonational phrasing (e.g. Pierrehumbert, 1980, Gussenhoven, 1984, Lindsey, 1985, Uhmann, 1991, Féry, 1993); others, following Beckman and Pierrehumbert (1986) assume two; the intonation phrase (IP) and a level of phrasing below the IP, the intermediate phrase, a prosodic constituent smaller than the intonation phrase. In systems following the ‘Beckman-Pierrehumbert’ approach, the intonation phrase is delimited by a boundary tone (transcribed with a percent sign following the high or low tone), and the intermediate phrase is delimited by a phrase accent (transcribed with a dash following the tone). However, it not always clear which criteria distinguish an intermediate phrase from an intonation phrase proper, and the concept of the phrase accent itself is somewhat controversial (see Ladd, 1983a: 746 and 1996: 89 for a critique and section 2.2.2.1 below). 2.2.2 Studies on English 2.2.2.1 Pierrehumbert (1980) The first comprehensive autosegmental-metrical account of English was offered in Pierrehumbert’s (1980) doctoral thesis, and this account has been influential ever since. Combining insights from previous work by Liberman (1975), Liberman and Prince (1977), and Bruce (1977), Pierrehumbert proposed a comprehensive account of American English intonation using two pitch levels associated with metrically strong syllables and intonation phrase boundaries. Previous authors had assumed four pitch levels, which led to considerable ambiguity in the resulting system (Pike, 1945, and Trager and Smith, 1951, suggested accounts of this type; for a critique, see Bolinger, 1951). Moreover, Pierrehumbert set new standards of experimental verification in intonation analysis by (a) making an explicit distinction between phonological and phonetic levels of representation, and (b) providing a set of mapping rules from one level to another (Ladd, 1996: 3). Note, however, that unlike in studies of intonation carried out within the British school of intonation analysis (e.g. Crystal, 1969), in Pierrehumbert’s study ‘phonetic’ refers to the acoustic representation of fundamental frequency only (see Nolan, 1990 for a discussion of different views on levels of representations in phonetics). Within the British school, ‘phonetic’ may refer to the acoustic realisation of intonation, but more commonly, the term refers to the auditory impression of a specific contour when analysed by a trained phonetician. In Pierrehumbert’s system, each intonation phrase must consist minimally of a pitch accent, an initial and a final boundary tone. Additionally, each intonation phrase must have a phrase accent. The phrase accent was borrowed from Bruce’s (1977) 9 Introduction and Background description of Swedish and posited by Pierrehumbert to account for F0 movement on and following the last pitch accent in the intonation phrase. Taken together, the phrase tone and the boundary tone account for the difference in complexity which frequently distinguishes intonation phrase final and non-final pitch accents. The phonological inventory Pierrehumbert posits for English is shown in (1); it claims that pitch accents may be monotonal or bitonal and may be ‘right-headed’ or ‘left-headed’, that is, either the first or the second element in a bitonal accent may be associated with a metrically strong syllable. Additionally, accents may be downstepped, that is, the high element of a pitch accent may be lowered in the pitch range relative to a preceding high tone. Downstep allows Pierrehumbert to account for the pitch patterns of English with only two pitch levels, despite cases in which a high tone is absolutely lower in the register than another high tone. (1) Pitch accents H*+L L*+H H*+H H* L* H+L* L+H* Phrase accents Boundary tones HL- H% L% The phrase accent (or phrase tone, as phrase accents do not represent complete pitch accents but part of a pitch accent) allows Pierrehumbert to distinguish between two types of nuclear fall, a terminal fall which goes all the way down to the hypothesised baseline of a speaker’s register, and a vocative fall which stops well above the baseline (1980: 74). This difference, Pierrehumbert argues, cannot be captured in models accounting for intonation patterns as sequences of F0 changes rather than sequences of F0 targets. In such models, she states, the declarative and the vocative fall involve more or less falling pitch5. In Pierrehumbert’s system, the terminal fall is decomposed into H* L- L% and the vocative fall into H*+L H-L%. H*+L in the vocative contour is said to differ from H* in the declarative in that H*+L triggers downstep of a following high Hphrase accent. As a result, H- is lowered beyond the location expected in the normal course of an utterance (basically, to a mid-level). The lowered H- tone, in turn, is said to trigger upstep of the final L%, and thus, a fall in F0 ending mid is generated. Figure 2 below schematises the difference in F0 between vocative and terminal declarative falls as well as the transcriptions Pierrehumbert suggests. Note, however, that Crystal (1969) describes this distinction as a categorical difference between a nuclear fall proper and a suspended nuclear fall. His system accounts for intonation patterns as sequences of F0 changes. 5 10 Introduction and Background F0 H*+L H-L% Vocative H* Terminal declarative L-L% time Figure 2 Terminal declarative and vocative falls in Pierrehumbert (1980). Without the phrase accent, the distinction between vocative and terminal falls cannot be made in Pierrehumbert’s system (see Ladd, 1983a and 1986 for a similar point)6. However, as the transcription of the vocative contour in Figure 2 shows, transcriptions involving phrase accents are rather complex. Additionally, the transcriptions do not reflect the structural similarity between declarative and vocative contours very well. This latter problem emerges also in the following example (adapted from Pierrehumbert 1980: 227): L*+H L*+H L*+H L*+H L* H-H% (2) Do you really believe Ebenezer was a dealer in Magnesium?7 The question in (2) is accounted for by Pierrehumbert as a series of rising accents, the last of which is transcribed as L* H-, that is, as phonologically different from the preceding accents. Additionally, the final L* H- is followed by H%. This transcription captures the difference in realisation between the phrase-final rising accent and the preceding rises: in (2), the pitch range of the final rise is larger. A more straightforward account of this difference appears to be L*+H H% with the H% capturing the final rise. However, in Pierrehumbert’s system, this transcription is not possible. The trailing H in L*+H does not trigger upstep of the H%, and the final rise is not accounted for. Only the phrase accent H- triggers upstep, and this means that the phrase-final pitch accent must be transcribed as L* H- rather than as L*+H. An apparent phonological difference between the final accent and the preceding accents is the result. If one were to assume, alternatively, that boundary tones are implemented relationally rather than absolutely, i.e. The vocative fall is captured more straightforwardly in Gussenhoven (1984) as H*L with HALF-COMPLETION, a modification which prevents F0 crossing the middle of a speaker’s register and without HALF-COMPLETION. This account captures the falling character of both accents as well as their differences. 7 Pierrehumbert (1980) illustrates this example with a fundamental frequency trace. In this trace, the IP-final H- is marked as if it was located higher in the register than preceding H- tones. It is not clear why this was assumed to be the case; at the end of the phrase, the trace rises smoothly and no one event in the trace rather than another appears to be associated with the location of H-. 6 11 Introduction and Background an H% boundary tone is always higher than an immediately preceding H, then a transcription without a phrase accent would capture the pattern equally well, and reflect the structural and semantic similarity between the rising accents in the phrase. Intuitively, the final pitch accent does not seem to differ in meaning from the preceding pitch accents. Further comments on the phrase accent can be found in section 2.4 of the following chapter. Pierrehumbert posits one level of intonational phrasing; the intonation phrase, which is obligatorily delimited by a high or a low boundary tone. High boundary tones are motivated by sharp upwards movements in F0 at the phrase edge in the absence of a stressed syllable, but low boundary tones are not realised by equivalent downward F0 movement. Nevertheless, Pierrehumbert suggests that the description of intonation is considerably simplified if we assume that there is a low counterpart to H%, and accounts for the difference in phonetic implementation between high and low boundary tones by a special phonetic implementation rule. This rule states that phrase accents are spread before tones which are phonetically equal or higher, but not before those which are lower. Thus, L- does not spread before L% which is claimed to be lower, but rather interpolates with L% and this accounts for the gradual drop in F0 which is often observed in intonation phrases ending low (Pierrehumbert, 1980: 47)8. Note, however, the hypothetical status of the claim that L% is lower than L-. Evidence comparable to that for H% being higher than H- is not available. 2.2.2.2 Intonational phrasing: Beckman and Pierrehumbert (1986) and Ladd (1986) In 1986, two proposals were published within the autosegmental-metrical tradition suggesting a level of intonational phrasing below that of the intonation phrase (Beckman & Pierrehumbert, 1986 and Ladd, 1986). Although in effect, they addressed the same issue, the authors proposed their models of phrasing for different reasons. Ladd's proposal aimed to account for apparent mismatches between tonal and rhythmic cues to intonational phrasing. Traditionally, an intonation phrase had been defined by (a) the presence of a ‘nuclear’ accent (see Cruttenden 1986: 48 for the notion of nucleus), and (b) rhythmic breaks or pausing. However, as Ladd pointed out, some phrases appear to contain two nuclear accents, not separated by an audible rhythmic break, and intonational tags can be delimited by pauses but nevertheless not bear an accent. To account for such apparently mismatched cues, Ladd posited a recursive two-level intonational phrase It is not immediately obvious why tones should spread only when followed by a tone which is at the same level or higher, but not when followed by a lower tone. Possibly, however, Pierrehumbert’s rule reflects a more general asymmetry between high and low tones in American English (e.g. high tones are downstepped, but low tones are not). 8 12 Introduction and Background structure. The lower level, the Tone Group, was defined on the basis of tonal information whereas the higher level, the major phrase, was set off by audible rhythmic breaks. Beckman and Pierrehumbert’s (1986) proposal on the other hand, explicitly built on Pierrehumbert’s (1980) approach. The authors proposed the ‘intermediate phrase’, a level of intonational structure below that of the intonation phrase. Intermediate phrases are delimited by Pierrehumbert’s (1980) phrase accent, and account for a wide range of intonational phenomena such as intonation phrases with multiple nuclei, similar tonal patterns in lists and intonational tags (for tags see e.g. Gussenhoven, 1990)9. Moreover, intermediate phrases were claimed to be the domain of downstep (for downstep see also Pierrehumbert and Beckman, 1988). Beckman and Pierrehumbert’s model of intonational phrase structure contrasts with Ladd’s in that both levels are defined on the basis of tonal information only, whereas in Ladd’s proposal, one is defined on the basis of rhythmic and the other on the basis of tonal information. However, both proposals leave a number of questions open. Firstly, clear acoustic cues distinguishing the two levels of phrasing proposed appear to be elusive, and to my knowledge, no comprehensive study contrasting them is available. In spontaneous speech, Ladd’s major intonational phrases will not necessarily be delimited by audible prosodic breaks. Beckman & Pierrehumbert do not suggest any clear acoustic cues beyond the similarity in tonal structure between successive intonation phrases in lists. In tags, however, which are also accounted for as intermediate phrases, no such similarity needs to emerge; a tag may be unaccented, and is then dissimilar in patterning from a preceding host phrase. This point will be taken up again in section 1.2.7 below, where the view taken on phrasing in this study will be discussed. 2.2.2.3 Downstep: Pierrehumbert (1980), Liberman and Pierrehumbert (1984) and Pierrehumbert and Beckman (1988) Pitch tends to decline over the course of phrases and utterances, and this effect has been one of the most widely studied properties of speech (Ladd, 1984, 1996). Pierrehumbert (1980) was the first to model downtrends in English fundamental frequency as ‘downstep’, that is, a local, step-wise lowering of pitch at specific accents rather than as a property of the complete intonation phrase. The notion of downstep is important to her account of (American) English and the AM framework in general, because it permits a modelling of tunes as linear sequences with only two pitch levels H and L, despite the fact that within one tune, some high targets may be lower than others. Pierrehumbert proposed, specifically, that downstep is triggered by an alternating sequence of H and L In Pierrehumbert (1980), phrase accents immediately precede a boundary tone and cannot occur between pitch accents. 9 13 Introduction and Background tones. In some of her descriptions, an L tone is simply there to lower the F0 value of a following H tone and has no direct manifestation in the F0 contour (see section 2.2.1 above for a brief discussion of the phrase accent, which was introduced as a direct result of this proposal). Pierrehumbert’s work was further developed in Liberman and Pierrehumbert (1984) and Pierrehumbert and Beckman (1988), and the model of downstep first presented in Liberman and Pierrehumbert (1984) is probably the most explicit one currently available for (American) English. An experimental investigation led the authors to propose four characteristic aspects of downstepped sequences; (1) the value of each accent peak in the sequence may be expressed as a constant proportion of the one immediately preceding; (2) therefore, the steps between successive pairs of accents decrease; (3) English has ‘final lowering’, that is, the final accent in a sequence appears lower in F0 than predicted by the location of the immediately preceding accent, and (4) the final low in each IP is constant for each speaker. Their findings led them to suggest that downstep may be modelled with an exponential decaying curve. ’Final lowering’ explains why the last accent in their sequences does not fit this curve. Beckman and Pierrehumbert (1988) further elaborated details of the model of downstep first proposed in Liberman and Pierrehumbert (1984). They explicitly distinguished between three sources of downtrend in F0, ‘catathesis’, ‘declination’ and ‘final lowering’ (in later work, the authors replaced the term ‘catathesis’ with ‘downstep’, the earlier term). Catathesis has been covered by the summary of downstep given above. Declination is defined by the authors as a lowering of the pitch range which operates in time from the beginning of the utterance, without regard to the tonal description. Unlike downstep, declination is not a process whose domain is the intermediate phrase; rather, it appears to operate at some larger level of structure. Its existence in English is controversial, but the authors did find evidence for it in Japanese. Final lowering happens at the ends of declarative sentences; and is defined as a gradual compression and shift of the pitch range which occurs in anticipation of the end of a declarative utterance. It affects the scaling of accents as well as postnuclear tones. Finally, Beckman and Pierrehumbert point out that the many studies investigating downtrends do not adequately separate the effects of catathesis and final lowering from those of declination. Downtrends in English and German will be dealt with in more detail in Chapter 6. 2.2.2.4 An autosegmental-metrical feature model: Ladd (1983) Ladd (1983b) presents an autosegmental-metrical feature model of intonational phonology based on work by Bruce and Gårding (1978) and Pierrehumbert (1980). His aim was to remedy shortcomings in previous work along the same lines, specifically, a 14 Introduction and Background difficulty in expressing a number of phonological and function generalisations based on overall contour shape. The central problem with Pierrehumbert's and similar work, Ladd points out, is an excessive concern with the perceptual and acoustic details of F0. However, such details play a secondary role in understanding the linguistic structure of intonation. More important are the functional distinctions of intonation, which have been extensively investigated in non-instrumental models of intonation (e.g. the British tradition). Ladd bridges the gap between instrumental and functional approaches by positing ‘a systematic taxonomy of intonational phonetics’ which is to serve as a basis for analysing the phonology of intonation. This taxonomy would then allow researchers to state generalisations about function. The system Ladd uses to illustrate his point has four pitch accents (H, L, HL and LH) and two boundary tones (L% and H%). The leftmost tone is automatically associated with a metrically strong syllable, and therefore the ‘*’ is omitted. Ladd then exemplifies his proposal with three phonetic features: [delayed peak], [raised peak], and [downstep]. For instance, the difference between a HL accent with a delayed peak and one without a delayed peak corresponds to that between rise-fall and a fall in the British tradition; the advantage in Ladd’s system is that the structural and semantic similarity of the fall and the rise-fall is captured more explicitly. Similarly, [raised peak] captures the similarity between an accent with an extra high peak and one without. Ladd’s account of downstep differs from Pierrehumbert’s in that it does not posit a sequence of H and L as a downstep trigger. Instead, downstep is claimed to be an independent speaker choice and accounted for by a downstep feature. Ladd (1983) proposes downstep to be a feature of intonational peaks involving an independent speaker choice. A criticism levelled against Ladd’s downstep feature, however, is that it overgenerates, in that it allows tones to be downstepped in isolation although downstep is generally assumed to be a relational phenomenon (Grice, 1995a). It allows for the first H accent in a phrase to be downstepped, although this does not appear to happen10. Therefore, Ladd (1983) proposed that the downstep trigger be marked on the accent preceding the one that is downstepped. Then, an initial accent could not be downstepped. However, as Grice (1992) points out, this has the disadvantage that, theoretically, a low tone could be downstepped, and again, this does not appear to be the case. In a modified proposal (Ladd, 1990b, 1993a) accounts for downstep as a metrical relationship between intonational constituents (see Liberman, 1975 for a similar proposal for English). Note, however, that this problem depends on the way one defines downstep. If one assumes that an accent can ‘step down’ not only from another high accent, but also from an initial high boundary tone, then one could account for a falling accent preceded by high preaccentual pitch as, e.g. %H !H*+L. 10 15 Introduction and Background 2.2.2.5 Two levels of phonological representation: Gussenhoven (1984) Gussenhoven's (1984) autosegmental account of British English is based on the nuclear tones recognised in the British tradition. Three of these tones, the rise (L*H), the fall (H*L) and the fall-rise (H*LH) he takes as basic; all other patterns observed are derived from the basic tones. Thus, while Pierrehumbert asserts that English lacks rules which alter tonal values or delete tones (1980: 3), and that therefore underlying and derived phonological representations are identical, Gussenhoven posits just such tonal alteration rules, and suggests that English intonation is best accounted for with an underlying and a surface level of phonological representation11. Similarly to analyses of connected speech processes in segmental phonology which, for example, posit a process of assimilation to change the realisation of /s/ towards /S/ in she packs shorts, Gussenhoven’s tonal rules alter the realisations of tones in certain contexts. In this respect, his system is the only one in the AM tradition to meet an objection raised by Crystal to intonational analyses in general (1969:40); “there is the hidden assumption that, having done an analytic survey of the basic functional ‘blocks’ of intonation, the synthesis of these blocks into connected utterance is simple. All the evidence goes to suggest that this is not the case, and that connected speech makes important modifications to the units into which it can theoretically be broken down.” Other AM systems postulate (implicitly) that there should be no difference between the intonational structure of citation forms and that of continuous speech. This would appear to imply that intonation is different from the segmentals of speech, i.e. that only segmental structure undergoes connected speech processes and suprasegmental structure does not. In Gussenhoven's account, two kinds of operations may change tonal values, and their domain of application differs. ‘Modifications’ apply to nuclear tones and ‘linking rules’ to prenuclear tones. Four modifications are proposed to apply in British English: DELAY, which can turn a fall into a rise-fall by delaying the peak of the fall relative to the accented syllable, STYLISATION which creates a spreading mid-tone12, for instance in calling contours, HALF-COMPLETION which accounts for tones failing to run their full course13, and RANGE, which runs orthogonal to the other three modifications in that it affects nuclear tones as a whole and expands or compresses their realisations. RANGE Note, however, that despite Pierrehumbert’s (1980) claim that General American English lacks rules which alter tonal values, her account includes downstep, a process which lowers high tones. 12 This feature was borrowed from Ladd (1978). 13 Gussenhoven defines HALF-COMPLETION as 'the failure of the tone to cross the mid-line’ (1984:222). 11 16 Introduction and Background appears to be somewhat problematic; this modification does not match the other categories well in that it is claimed to be gradient rather than categorical. This makes it difficult to see how one decides whether RANGE has applied or not or whether it applies by default at all times, just in differing degrees. Also, RANGE may be confused with HALF-COMPLETION. Gussenhoven indicates that in combination, nuclear tones and modifications specify twelve nuclear tones, although the gradient status of RANGE makes this claim problematic. Furthermore, Gussenhoven points out that the twelve tones cannot capture all nuclear contours found. The remaining contours, which occur less frequently, are accounted for by combining modifications (for details, cf. Gussenhoven, 1984:232 and Gussenhoven, 1988). ‘Linking rules’ optionally reduce the realisations of prenuclear accents and thereby account for the differences between nuclear and prenuclear accent patterns which are an integral part of descriptive systems put forward within the British tradition (e.g. Crystal, 1969, O'Connor and Arnold, 1973). Theoretically, any tone can be linked to any following tone, but in practice, not all combinations occur equally frequently. Two types of linking may apply; partial linking and complete linking (see Figure 3 below). Partial linking results in the slope of the fall or rise following an accented syllable being more gradual than that characterising unlinked nuclear tones. Complete linking is rather difficult to describe in purely auditory terms (this partially explains why completely linked contours have been described as categorically different from unlinked contours in the British tradition). 17 Introduction and Background (a) Unlinked falls to [..] and she waved her mother [..] (b) Partially linked falls to her mother [..] [..] and she waved (c) Completely linked falls [..] and she waved to her mother [..] Figure 3 Prenuclear accents in Gussenhoven (1984). Gussenhoven points out that this analysis of prenuclear accents enables one to group together semantically similar contours which are treated as categorically different in the British tradition. The stylised examples in Figure 3 illustrate his point (the contours represent auditory impressions and the shaded boxes the accented syllables). In the British tradition, both (a) and (b) could reasonably be analysed as falling head plus falling nucleus contours. (c), on the other hand, needs to be described as a level head plus falling nucleus, that is, a categorically different contour, despite its intuitive similarity to the other two. Gussenhoven's analysis captures the intuitive similarity between the three contours but it can also express the differences between them. The argument is that all three contours are underlyingly HL HL. In (a), no linking rules have applied, in (b), partial linking has applied and in (c) complete linking. Thus, the strength of Gussenhoven’s approach lies in its ability to capture structural similarities and differences at more than one level of representation. A further advantage of Gussenhoven’s approach involves its ability to capture parsimoniously differences and similarities between different speaking styles. It is reasonable to assume that speaking styles differ from each other not only with respect to the choice and distribution of pitch accents, but also with respect to the way specific accents are realised. Spontaneous speech, for instance, is likely to be characterised by more instances of ‘accent linking’ that read speech (see Figure 3). In the Pierrehumbert system, each instance of ‘linking’ is accounted for as a separate accent choice, and needs 18 Introduction and Background to be stated separately. In the Gussenhoven system, the difference does not involve accent choice; linked and unlinked realisations of H*+L are derived from a single underlying level of representation. One may state that spontaneous speech is characterised by more frequent applications of linking than read speech. Finally, Gussenhoven’s approach differs from other AM approaches discussed in this study in that it proposes meanings for the modifications postulated to apply at the surface level of phonological representation14. However, intonational meaning is notoriously hard to pin down, largely because of its context dependency, and the meanings Gussenhoven suggests for his modifications reflect this difficulty to some extent15. DELAY is said to signal to listeners that the accented word relates to something 'non-routine' and 'very significant'. STYLISATION, on the other hand, is said to signal 'routineness' (as may be claimed to be signalled in calling contours, for instance). The meaning of HALF-COMPLETION appears to be even harder to define than that of the other modifications; ‘unconvincingness‘ is mentioned tentatively. However, if one may account for the difference between a terminal declarative fall and a vocative fall in the way suggested, then ‘unconvincingness’ would not appear to be appropriate. Finally, differences in RANGE are related to different degrees of insistence. Linking rules are not said to affect the meaning of intonation phrases directly, rather, their application may be related to differences in focus structure. 2.2.2.6 Gussenhoven (1984) vs. Pierrehumbert (1980) Gussenhoven (1984) presents a model of English intonation which, in many ways, parallels traditional analyses of segmental phonetic structure. As in phonemic analysis, a set of primitive, phonologically contrastive categories of intonational structure is posited, and the realisation of these primitives is governed by a set of phonetic implementation rules which are (a) sensitive to segmental structure and (b) language specific. Additionally, the primitives may be realised either directly, or they may undergo phonological adjustments when several categories are combined into an intonational phrase structure. These adjustments systematically modify the underlying structure when basic categories are combined in continuous speech16. It is these adjustments which most See Pierrehumbert and Hirschberg (1990) for a compositional theory of intonational meaning which suggests (partial) meaning to tones in the tonal inventory. 15 For an experimental investigation of intonational meaning in Dutch, see Grabe et. al, 1997. 16 Gussenhoven suggests that primitives and modifications are morphemes. For instance, the effect of adding DELAY to H*+L can be compared to the addition of the past tense morpheme <-ed> to the stem of the verb to walk.. The meaning of walk is changed, but not altered beyond recognition. Similarly, DELAY adds something to the meaning of H*+L (e.g. ‘surprise’), but does not change its character completely. 14 19 Introduction and Background obviously distinguish Gussenhoven’s model from that presented in Pierrehumbert (1980). The difference between the models is apparent especially when we compare the authors’ solutions to modelling the distinction between IP final (i.e. nuclear) and nonfinal accents. Final pitch accents are characterised by a phonetically richer realisation than non-final ones, that is, they tend to exhibit a larger inventory of pitch accent shapes. In principle, there are two ways of accounting for this distinction. Either one reduces the realisations of non-final accents in some way, or one enriches the realisation of final accents. Gussenhoven favours the first solution; he accounts for reduced prenuclear realisations with a linking rule, that is, a phonological adjustment. Pierrehumbert prefers the second; she does not make use of phonological adjustments, and in her account of American English, final accents are followed by a phrase tone and boundary tone, and differences in the realisation of prenuclear accents are handled by a richer set of phonetic realisation rules. Figure 4 illustrates the basic differences between the models. The figure shows that Gussenhoven’s system assumes two levels of phonological representation, the underlying level, at which the primitives are specified, and a surface level. The surface level is derived from the underlying level via a set of phonological adjustment rules, that is, the modifications and linking rules. The phonological surface structure is then translated by phonetic realisation rules into the phonetic realisation. In Pierrehumbert’s model, the phonological representation has only one level, but a richer set of phonetic realisation rules accounts for differences in surface structure. Gussenhoven (1984) Pierrehumbert (1980) Realisation Realisation Phonetic realisation rules Phonetic realisation rules Surface Structure Phonological adjustment rules Underlying Structure Phonological representation Phonological representation 20 Introduction and Background Figure 4 Summary of differences between models of English intonation proposed in Pierrehumbert (1980) and Gussenhoven (1984). The advantage of positing two levels of phonological structure rather than just one can be illustrated by a comparison of Pierrehumbert’s and Gussenhoven’s accounts of the difference between terminal falls, vocative falls and terminal rise-falls. Pierrehumbert accounts for the difference as one involving different choices from the phonological inventory. The fall is transcribed as H*L-L%, the vocative fall as H*+L H-L%, and the rise-fall as L*+H L-L%. In Gussenhoven’s system, on the other hand, the three contours are derived from the same phonological category H*+L . The terminal fall is basic, and is not modified; underlying and surface representations are identical. The vocative fall is represented as H*+L with HALF-COMPLETION, and the rise-fall as H*+L with DELAY. Thus, in Gussenhoven’s system, the structural and semantic similarity between the three types of fall is captured explicitly, whereas in Pierrehumbert’s system, the similarity between the contours is much less obvious (see also Ladd’s 1983 critique of the contour classification generated by the Pierrehumbert system). Table 1 below contrasts the two analyses of terminal fall, vocative fall and terminal rise-fall. Pierrehumbert 1980 Gussenhoven 1984 Table 1 contours. Terminal fall Vocative fall Terminal rise-fall H*L-L% li n Be d a H*+L H-L% li n d a Be L*+H L-L% in Be l d a H*+L H*+L, HALF-COMPLETION H*+L, DELAY Pierrehumbert's and Gussenhoven's analyses of three nuclear falling A further advantage of Gussenhoven's system is that tonal changes which characterise particular speaking styles (e.g. careful vs. casual speech) do not need to be specified separately every time they occur, but can be stated as applying to a set of utterances as a whole. For instance, in casual speech, we often find that prenuclear accents, trailing tones or boundaries are deleted. In Pierrehumbert's system, every instance of deletion has to be specified separately, because every observed difference between contours is taken to reflect a different choice from the phonological inventory. The Gussenhoven system is more parsimonious; we can state that casual speech differs from careful speech in that it has more DELETION. In summary, Gussenhoven’s system appears to be (a) more parsimonious and (b) more flexible. Not only can it account straightforwardly for the structural similarities and 21 Introduction and Background differences which characterise pitch accents, but it can also capture structural similarities between larger stretches of utterance. The Pierrehumbert system offers less transparent transcriptions and cannot account for intonational differences distinguishing different speaking styles in any obvious way. We need to concede, however, that experimental evidence in favour of Gussenhoven’s system is not easy to come by. Generally, controlled data supporting linguists’ intuitions of semantic and structural similarities between contours are scarce, and in the absence of such data, one may argue that it is more consistent to represent what appears to be a surface categorical difference between two intonational surface structures as just that, a categorical difference, and no more (see ‘t Hart, Collier and Cohen, 1990 for such an approach). One experimental study, however, has compared the nuclear tone taxonomies proposed in Pierrehumbert (1980) and Gussenhoven (1984), and this study supports Gussenhoven’s system. Gussenhoven and Rietveld (1991) asked American English subjects to estimate the semantic contrast in paired nuclear tones, and their judgements were correlated with the sets of theoretical differences predicted in the two systems. The results showed that Gussenhoven’s system was a better predictor of the experimental scores. Finally, note that some of the differences in Pierrehumbert’s and Gussenhoven’s systems may result from actual difference between British English and American English intonation. Clearly, the systems do differ in some respects. For instance, in American English, nuclear high rises or rise-level contours are far more commonly used for statements than in British English. At times, such difference may have led the authors to regard different types of distinctions as more relevant than others. However, the experimental subjects tested in Gussenhoven and Rietveld (1991) were American, rather than British English speakers. The finding that Gussenhoven’s system was nevertheless a better predictor of the experimental scores than Pierrehumbert’s system can be interpreted to suggest that Gussenhoven’s account has some validity for American English also. 2.2.3 Studies on German Within German intonation research, there appears to be less agreement on basic facts than in research on English (Möbius, 1993), and far fewer studies have been carried out within the autosegmental framework. These will be reviewed in the following sections, as well as one earlier non-autosegmental-metrical study (Isac*enko and Schädlich, 1966), which is included because the authors were the first to model German intonation with two pitch levels. 2.2.3.1 Isac*enko and Schädlich (1966) 22 Introduction and Background Partly in response to shortcomings in the Trager & Smith style levels analysis, Isac*enko & Schädlich modelled German intonation with two pitch levels and tested their model with perception experiments using synthesised speech. On the basis of their findings, they suggested that the basic elements of German intonation involve one rising and one falling pitch change (‘Tonbrüche’). Falls and rises are associated with the ‘ictus’ of a stressed syllable, that is, its voiced section. Changes either precede the ‘ictus’ or follow it. Two types of rises and two types of fall result, and are illustrated in Table 2 below. Intuitively, Table 2 summarises the options available in phonetic surface structure of German falls and rises very well, and in a later AM analysis summarised below, Féry (1993) lists patterns which would appear to correspond to those proposed by Isac*enko and Schädlich (1966). Féry’s (1993) transcriptions are given in Table 3. A comparison between Table 2 and Table 3 shows that Isac*enko and Schädlich’s system differs from Féry’s in that it is perfectly symmetrical; the authors simply list logical options: pitch may step up before a stressed syllable, or after a stressed syllable. Féry’s later account shows that the way such options are modelled in the AM framework depends on more than the logical possibilities available for a particular accent’s surface realisation. Generally, the way intonational categories are modelled in the AM framework reflects (a) their distribution and (b) the degree to which they are similar or different, both structurally and semantically. Féry’s modelling, which reflects these concerns, is foreshadowed by comments Isac*enko and Schädlich make about the characteristics of their basic categories. They say that pre- and post-ictic rises differ in their distribution. The post-ictic rise (L*+H) is the ‘rise proper’; it can appear in prenuclear position as well as nuclear position. The pre-ictic rise (H*), on the other hand, cannot appear in nuclear position; in fact, we would be left with a sentence fragment, were a pre-ictic rise to appear intonation phrase-finally. In prenuclear position, on the other hand, a pre-ictic rise is said to ‘foreshadow’ a following fall, either pre- or post-ictic. In Féry’s system, which is based on Gussenhoven’s (1984) approach, H* appears in prenuclear position only and is derived via a linking rule from H*+L, but L*+H can be nuclear or prenuclear. The difference between pre- and post-ictic fall is said by Isac*enko and Schädlich to be distinctive, and, again, this observation is reflected in Féry’s system. 23 Introduction and Background A B rising pitch change I pre-ictic die II post-ictic die Kin der falling pitch change Kinder die Kinder die Kin der Table 2 Isac*enko & Schädlich’s inventory of falls and rising pitch changes in German. Adapted from Isac*enko & Schädlich (1966: 60). I pre-ictic II post-ictic A B Rises Falls H* !H*+L L*+H H*+L Table 3 AM categories of German intonation proposed in Féry (1993) which appear to correspond to those proposed by Isac*enko and Schädlich (1966). The difference between Isac*enko and Schädlich’s falling accents, on the other hand, is not claimed to be distinctive, and both may appear in prenuclear and nuclear position. Again, this observation appears to be reflected in Féry’s system, where these pitch changes are modelled as the same pitch accent H*+L, either downstepped relative to a preceding accent or not. 2.2.3.2 Wunderlich (1988) Following Pierrehumbert (1980) and Ladd (1983), Wunderlich (1988) presents an autosegmental-metrical account of German which distinguishes between a phonological and a phonetic component (in practice, however, the article concentrates on the phonological component and devotes only a few general comments to phonetic implementation). Wunderlich’s system describes a limited set of intonation patterns established on the basis of an examination of F0 traces (no information regarding speakers, dialects or speaking style is given). He illustrates these patterns as in Figure 5 below (my translation of the impressionistic names of the different accent patterns). The small brackets indicate the location of the accented syllables, and the brackets in bold the right or left edge of an intonation phrase. 24 Introduction and Background Observed F0 patterns Phonological transcriptions H* Peak accent H* H L* Bridge accent %H L* Falling low accent L* H% Low accent - rising L* H (H%) Echo accent H* H Left bridge support Figure 5 Wunderlich’s accents patterns of German. Adapted from Wunderlich (1988: 11). As can be seen in Figure 5, Wunderlich’s bridge accent represents a combination of two accents, made up from the ‘left bridge support’ (left) and the falling low accent (right). In the ‘echo accent’, Wunderlich comments, the F0 peak is reached in the post-accentual syllable, but within the accented syllable in the ‘left bridge support’. All patterns were attested in perception experiments, but no details or references are given. However, the status of the brackets surrounding the H% boundary tone in the Echo accent remains unexplained; do they indicate that the presence of H% is optional? And why do we not find a similar opposition for the ‘left bridge support’? Moreover, the term Echo accent represents a category mismatch; here, function rather than form is implied, whereas all other accent terms refer to form only. Wunderlich posits three types of phonological entities; pitch accents, boundary tones, and ‘non-boundary tones’ (presumably similar to trailing tones in Pierrehumbert’s system). He then bases his autosegmental-metrical account of the F0 patterns illustrated in Figure 5 on two phonological oppositions, (a) presence or absence of a boundary tone, and (b) high (H) vs. low (L) tone. Moreover, he assumes a distinction between ‘marked’ and ‘unmarked’ patterns, and suggests that unmarked patterns do not need to be 25 Introduction and Background specified. The distinctions he makes are summarised in Table 4 below (again, the translations into English are mine). Boundary tone non-boundary tone pitch accents Unmarked L L H Marked H H L Table 4 Phonological distinctions and markedness. Adapted from Wunderlich (1988: 19). ‘Non-boundary tone’ is Wunderlich’s term for a trailing tone. These oppositions are the basis for his transcription of the patterns observed as shown in Figure 5 above on the right. Wunderlich’s transcriptions raise a number of questions. Firstly, what is the basis for the marked-unmarked classification of tones in Table 3? Secondly, if only marked patterns need to be specified, why are both low and high accents specified, although high is the default? With respect to boundary tones, it appears that in Figure 5, the unmarked case, that is, the low boundary tone, has not been specified. Thirdly, what is the status of the non-boundary tone? These unresolved questions combined with a lack of clearly laid out evidence and transparent motivations for the modelling make Wunderlich’s claims too weak to generate clear predictions. 2.2.3.3 Uhmann (1991) Uhmann’s autosegmental-metrical analysis of German intonation concentrates on the relationship between intonation and focus. Her observations are based on the analysis of two read speech corpora, in which focus structure was systematically manipulated (her test sentences were embedded in dialogues). Corpus I was read by eight speakers (six female and two male) and Corpus II by four speakers (two female and two male; no information about linguistic background or age is given). However, the data she presents are from two selected speakers from each set. On the basis of her corpus analyses, Uhmann proposes that German has four pitch accents: H*+L, H*, L*+H and L*. These accents are said to have been ‘extracted’ from the corpus. The differences between H*+L and H* and between L*+H and L* are motivated by differences in the realisation of postaccentual syllables. Monotonal pitch accents, she states, do not influence the F0 of following syllables but bitonal pitch accents do. 26 Introduction and Background Intonation phrase boundaries were modelled on the basis of F0 measurements at IP on- and offset. A bimodal distribution of F0 values at IP offset leads Uhmann to posit two boundary tones H% and L%. No similarly clear distribution is observed at IP onset, but nevertheless, Uhmann also posits two boundary tones in this position, although the boundary may also remain unspecified. However, this proposal fails to capture the clear discrepancy between IP onsets and offsets which her data reveals. In terms of the number of representational levels, Uhmann’s system resembles that of Pierrehumbert (1980) rather than that of Gussenhoven (1984). One level of phonological representation and one level of phonetic implementation are assumed, and no explicit distinctions are made between nuclear and prenuclear accents. Phonological adjustment rules are not discussed. On the other hand, Uhmann posits only one level of intonational phrase structure (unlike Beckman and Pierrehumbert 1986), and no phrase tone, and in this respect, her system resembles that of Gussenhoven. 2.2.3.4 Féry (1993) The most comprehensive AM study of German intonation to date was presented in Féry’s (1993) German intonational patterns. Her findings were based on the analysis of a corpus of 100 sentences read by three native speakers of Standard German (375 tokens, because some sentences were read with more than one realisation). Féry’s study had two aims; firstly, to give an autosegmental-metrical account of the phonological properties of German intonation, and secondly, to investigate the influence of a number of linguistic factors on the tonal pattern of utterances. Among these were focus-structure, topic-comment structure and scope. The following summary of her findings will concentrate on the phonological system she posits. Féry’s system differs from Uhmann’s in that it posits two levels of intonational phrasing (the intonational phrase and the intermediate phrase), but, again, no phrase accent. Féry argues that phrase accents are not needed in German, either to describe the pitch movement between the last pitch accent and the boundary tone, or to delimit the intermediate phrase. In Féry‘s system, the pitch movement between the last pitch accent and the boundary is accounted for by the trailing tone of the last bitonal pitch accent which spreads to the end of the intonation phrase (all the nuclear pitch accents she posits are at least bitonal). Féry’s intermediate phrase is not delimited by a phrase accent because of the ‘phrasing which exists independently of the tone structure anyway’ (1993: 72). One optional, final boundary tone is posited, but no initial boundary tone(s). No low boundary tone is said to be needed, because in overall falling contours, there is no tonal movement marking the end of an IP. Within intonation phrases, Féry posits three nuclear accents: H*L, L*H and L*HL. The tritonal accent replaces Ladd’s (1983) ‘delayed peak’. She argues that 27 Introduction and Background German does not have a feature ‘delayed peak’, citing evidence from perception studies by Kohler (1987, 1991). Kohler synthesised continua between falling accent contours with ‘early’, ‘middle’ and late peaks. Féry suggests that if German had the ‘delayed peak’ feature, listeners should have been sensitive to the difference between the late and middle peaks in Kohler’s studies; in fact, listeners were found to make a categorical distinction between early and middle peaks, but not between middle and late peaks. Given this, however, it is not clear why Féry postulates the additional tritonal nuclear pitch accent, considering that the distinction between middle and later peak appears to be smaller than that between middle and early peak (and this distinction is the one she accounts for with an ‘early peak’ feature; see below). In Gussenhoven’s (1984) system, which Féry to some extent adopts, the phonological distance between two different nuclear accents is actually greater than that between variants of the same accent with or without a modification. Following Gussenhoven (1984), Féry posits two modifications, STYLISATION and EARLY PEAK. The term STYLISATION is borrowed from Ladd (1978) and accounts for calling contours, whereas EARLY PEAK accounts for high preaccentual pitch. This second modification is based on the categorical distinction between ‘early’ and ‘middle peak’ observed by Kohler (1987, 1991). The nuclear-prenuclear distinction, finally, is accounted for by Gussenhoven’s tone linking rules. A special problem in German which Féry raises involves the ‘hat pattern’ (t’Hart, Collier and Cohen, 1990). Féry states that German has two different types of hat patterns, whose derivation is not straightforward. Her account of the derivation postulates that the patterns contain different accents but have, by coincidence, the same form. Hat contour 1 is analysed as a completely linked sequence of two H*L pitch accents. After linking has applied, the structure of an H*+L H*+L sequence is H* H*+L. Hat contour 2 consists of two fully realised accents L*+H H*+L. The difference between the contours is said to be not always phonologically clear-cut, and their lack of distinctiveness in some contexts is compared to neutralisation in segmental phonology. Féry’s account of the two types of hat contour may be compared to Wunderlich’s (1988) distinction between a ‘Bridge accent’ and an ‘Echo accent’ (see Figure 5 earlier). Wunderlich based his distinction on the alignment of the F0 contour with the stressed syllable. In the first element of the Bridge accent, F0 rises throughout the accented syllable and then levels out into a plateau. In the Echo accent, the F0 patterns is the same, but aligned later; now the rise continues beyond the accented syllable. The Bridge accent appears to be comparable to Féry’s hat contour 1, where the first accent is H*, and the Echo accent resembles hat contour 2 which begins with L*+H. Unlike Uhmann (1991), Féry (1993) contains a section on downtrends, in which she provides fundamental frequency traces illustrating examples of downstep in German. These contours are discussed briefly in the light of accounts of downstep in English 28 Introduction and Background posited by Pierrehumbert (1980), Liberman and Pierrehumbert (1984) and Ladd (1983), and Féry concludes that more research into downstep in German is needed. Féry’s account of German intonation leaves open a number of questions17. Firstly, the phonetic realisations of the intonational categories posited are not discussed. Further data on accent and realisation are required, for instance, on the distinction between the two types of hat pattern suggested. Also, a discussion of the theoretical implications of the boundary tone asymmetry posited would be desirable. Secondly, the status of Féry’s intermediate phrase is unclear; specifically, it is not obvious how an intermediate phrase can be distinguished from an intonation phrase. The intermediate phrase is said to be delimited by the trailing tone of the last pitch accent in it. But how can a trailing tone have a delimiting function? In intonation phrases, this same trailing tone is claimed to spread up to the IP boundary. Thirdly, as Féry points out, more evidence is needed on downstep in German. Of special interest to the present study are hypotheses offered by Féry about the difference between English and German intonation. Her hypotheses are summarised and briefly discussed below. (1) The set of possible postnuclear realisations is more restricted in German than it is in English (1993: 61). (2) In English, the phrase accent is needed to control the melody between the nuclear accent and the boundary tone. In German, the nuclear accent is generally followed by an abrupt fall or rise immediately after the nuclear accent and not by a boundary tone at the end of the intonation phrase (1993: 74). (3) There is no tonal movement marking the end of a falling IP in German (1993: 72). The claim under (1) motivates the one optional boundary tone postulated by Féry as opposed to the two phrase accents and two boundary tones delimiting the intonation phrase in Pierrehumbert’s account of English. However, no comparative data is offered to support this claim. Moreover, at least with respect to the intonation phrase, Féry‘s optional boundary tone would appear to generate more rather than fewer boundary options (i.e. ‘low’ in H*L without a boundary tone, ‘high’ in L*H without a boundary tone, and ‘extra high’ in L*H with a high boundary tone H%). This would suggest a larger rather than a smaller range of postnuclear realisations than the two available in English. 17 See also Gussenhoven’s (1994) and Ladd’s (1994) reviews of Féry’s study. 29 Introduction and Background Claim (2) can be interpreted to imply that in English the nuclear accent is not generally followed by an abrupt fall or rise immediately after the nuclear accent. However, Pierrehumbert’s (1980) results suggest otherwise. In English H*L-L%, for instance, the fall takes place on the postaccentual syllable after which the contour levels out gradually (see Pierrehumbert 1980: 187, figure 2.32 B). The suggestion under (3) also implies a cross-linguistic difference. English is assumed to exhibit tonal movement marking the end of a falling IP, but German is not. However, again, there is counter-evidence. Pierrehumbert’s (1980) examples of intonation phrases with L% do not show downward movement in F0 at the end of the IP, and therefore Pierrehumbert suggests a special phonetic implementation rule which accounts for the apparently asymmetrical realisation of high and low IP boundaries. Moreover, an AM account of English has been proposed by Lindsey (1985) which assumes that English has high but no low boundary tones. Clearly, some of Féry’s proposals require further investigation. Accent and boundary realisation in English and German, the question of unspecified intonation phrase boundaries, and downstep in German are among the issues addressed in the following chapters. 2.3 Prosodic labelling: ToBI The contrastive autosegmental-metrical analysis of English and German presented in the present study was based on evidence from a directly comparable corpus of English and German speech data. Contrasting these data required (a) that they should be prosodically labelled, and (b) that the labels should be comparable. This precluded the use of preexisting systems such as Pierrehumbert’s for English and Féry’s for German which are not directly comparable. The following sections will briefly discuss two relatively widely used, very similar AM prosodic labelling systems which have recently been proposed for English and German. 2.3.1 English ToBI In 1992, the ToBI system for prosodic labelling18 was proposed as a standard for the transcription of General American English, General Australian and Southern Standard British English (Silverman et al. 1992, see also Beckman and Ayers 1994). The labelling system was the joint initiative of a group of researchers and based on Pierrehumbert ToBI stands for ‘Tones and Break Indices’; ‘tones’ refers to intonation, and ‘break indices’ to rhythmic structure. 18 30 Introduction and Background (1980) and subsequent revisions of her work by Beckman and Pierrehumbert (1986) and Pierrehumbert and Beckman (1988). The development of ToBI was motivated by a need to establish a commonly used and understood system to indicate prosodic features in labelled computer corpora of speech (Ladd 1996: 94). Briefly, ToBI transcribes intonation as a linear sequence of prosodic events on parallel tiers, principally the tone tier and the break index tier. On the tone tier, five pitch accents (H*, H+!H*, L*, L+H*, L*+H) and a two level intonational phrase structure are transcribed. Downstep is indicated by a ‘!’ symbol. Both the intonation phrase and the smaller intermediate phrase may end high or low (H% vs. L% and H- vs. L-). On the break index tier, the degree of coherence between adjacent words is labelled on a scale from ‘0’ (highest level of coherence) to ‘4’ (least coherent). ‘0’ is defined in terms of connected speech processes such as cliticisation; ‘1’ describes most medial word boundaries in connected speech; ‘3’ delimits an intermediate phrase and ‘4’ marks a full intonational phrase boundary. The exact linguistic status of ToBI has remained somewhat vague. Specifically, it is unclear whether ToBI is intended to provide phonetic transcriptions of intonation, phonological transcriptions, or possibly neither. When the transcription system was first introduced, it appeared to be phonetic rather than phonological in nature. The authors pointed to a need for a single standard for prosodic transcription analogous to the IPA for phonetic segments, and they appeared to suggest that ToBI was developed to meet this need (Silverman et al. 1992: 867). However, this parallelism is questionable; an IPA transcription of speech may be made without applying linguistic decisions (i.e. nonsense words may be transcribed), but ToBI labelling requires linguistic decisions. For instance, transcribers need to be able to identify the stressed syllables with which pitch accents are associated. Thus, it appears that ToBI is not a phonetic transcription system19. Whether ToBI is strictly phonemic, however, is also questionable. For instance, we find that a distinction is made between falling nuclear accents with a smaller or a larger onglide in pitch and fundamental frequency on the stressed syllable (labelled as H* L-L% and L+H* L-L%). This distinction is not made in the British school of intonation analysis, which also claims to transcribe phonological differences. Moreover, in an evaluation of ToBI, L+H* is described as a minor variant of H*, and the categories L+H* and H* are collapsed (Pitrelli et al., 1994)20. Apparently, ToBI is not strictly phonemic either. The Ladd (1996: 95), for instance, has pointed out that ToBI is not some kind of hightech IPA for prosody. Moreover, Pierrehumbert (1980), on whose work ToBI draws, has argued that there are no phonetic representations other than those derived directly from the physical signal (see Nolan, 1990 for a critique). A phonetic ToBI would appear not to fit in with this view. 20 Grice et al. (1996) present an evaluation of German ToBI, in which L+H* and H* are the categories which are most frequently confused. However, L+H* was also 19 31 Introduction and Background impression that ToBI represents a compromise between a phonetic and a phonemic transcription system is reinforced by discrepancies in the system between labels which are minimally abstract, such as, for instance those referring to the distinction between H* L-L% and L+H* L-L%, and those transcribing intonation phrase boundaries which are relatively indirect. L* H-L%, for instance, transcribes a rise-to-mid, requiring a phonetic implementation rule ‘upstep’ which raises the final L% to the level of the preceding H-. To summarise, it appears that in its current state, ToBI represents an uneasy compromise. Ladd (1996: 95) points out that ToBI is first of all a set of conventions for labelling prosodic features, aimed at making large corpora of speech more useful for research, Clearly, when developing such conventions, compromise is required. Whether a compromise between a phonetic and a phonological transcription is the best solution, however, may be questioned. A labelling system which explicitly distinguishes between a narrow level of transcription, which is minimally abstract and a broader, more obviously phonological level combined with more detailed explorations of the status of both levels may be preferable to the type of compromise offered by ToBI. 2.3.2 German ToBI On the basis of the ToBI system developed for American English (henceforth ‘EToBI’), a unified single ToBI system for German (ToBIG or GToBI) emerged in 1995 (Grice et al. 1996). Contributions came from ToBI-style systems developed in parallel at the universities of Braunschweig, Saarbrücken, and Stuttgart (Batliner and Reyelt, 1994, Grice and Benzmüller, 1995, Mayer, 1995). The GToBI inventory contains the five pitch accents of EToBI plus one further accent H+L*, and again, downstep is indicated by the ‘!’ symbol. Additionally, GToBI differs from EToBI in that intermediate phrases do not have to contain an accent (this is obligatory in EToBI). Inter-transcriber consistency among labellers using GToBI has been evaluated (Grice et al. 1996), and the results appear to be comparable to those obtained in a similar study using EToBI (Pitrelli et. al, 1994). In the GToBI labelling test, 71% inter-transcriber consistency was achieved for pitch accents whereas 68.3% was achieved in the EToBI test. Part of this agreement was on whether or not an accent was present (87% in GToBI vs. 80.6% in EToBI) and which accent was present (51% in GToBI vs. 64.1% in EToBI). 33% of the disagreement on which pitch accent was present in GToBI involved the accent pair L+H* and H*, but L+H* was also confused with L*+H, that is, in some cases, a falling accent L+H*L- must have been confused with a rising accent L*+H; a rather worrying finding. In the EToBI test, the results for L+H* and H* were merged, which suggests that transcribers may not confused with L*+H, and authors conclude that L+H* can therefore not be treated as a subcategory of either H* or L*+H. 32 Introduction and Background have distinguished between them reliably. Thus, in both EToBI and GToBI, transcribers tend to agree relatively reliably on the presence or absence of an accent, but the agreement for the type of accent present appears to be rather low. Nevertheless, the evaluators of GToBI conclude that GToBI is already adequate for the transcription of databases in German. The evaluators of EToBI conclude that the EToBI convention and its training materials have been refined to the point that they can be used fruitfully for the labelling of prosodic phenomena in speech databases. Considering the levels of agreement found, however, both conclusions seem somewhat hasty. Presumably, the users of prosodically transcribed databases require more than just a reliable indication of whether an accent is present or not. Developers of speech synthesis systems, for instance, are likely to be interested in accurate information about the type of accent used in a specific utterance as well as in information about accent distribution. Some criticism has been levelled at GToBI by Kohler (1995). Firstly, Kohler questions the status of the phonological model underlying the GToBI. He points out that the underlying model for EToBI is the one developed for American English by Pierrehumbert and colleagues. With respect to GToBI, however, it is not entirely clear whether the transcription system is based on an independent analysis of German intonation or whether the notational device of American ToBI has simply been transferred to German21. Considering that English and German intonation are nowhere near as different from each other as for instance, German and French intonation, Kohler concedes that this might not necessarily be a big problem, but if this is an appropriate approach, then it needs clear phonetic and phonological justification. GToBI may in some part be based on Féry’s (1993) study of German but this analysis constitutes only a partial model of German intonation and is functionally orientated towards focus and grammatical phrasing rather than constituting a formal phonological model. Possibly in response, Grice et al. (1996: 1717) point out briefly that English and German are closely related languages which share a similar rhythm and intonation structure. However, there are differences in the inventories of pitch accents (GToBI has a pitch accent H+L* which EToBI does not have), and in the phonetic realisation of the pitch accent categories the languages share. Secondly, Kohler questions the re-introduction of Pierrehumbert's (1980) H+L* and points to the lack of justification for this decision. It is unclear, he states, whether the decision was made on language-independent grounds or because the labelling of German made it mandatory. This criticism may not be entirely fair, however. One may assume that the decision to introduce H+L* was made on language-independent grounds, since Saarbrücken ToBI, one of the contributors to GToBI, was developed on the basis of Map Similarly to EToBI, GToBI appears to be a compromise, driven to some extent by the need for an agreed labelling system for prosody that could be used in the VERBMOBIL project (see Batliner and Reyelt, 1994). 21 33 Introduction and Background Task data and has H+L* (see Anderson et al., 1991 for the Map Task). Additionally, Kohler’s own work appears points towards a categorical distinction between early and medial F0 peaks in German nuclear falling accents (Kohler, 1987a). Thirdly, Kohler points out that the theoretical objections to ToBI are compounded by practical problems; we do not know how the phonological categories given in ToBI are realised in the phonetics. Transcribers are, in fact, given some examples of the phonetic realisation of EToBI and GToBI labels in training materials available by anonymous ftp from the Linguistics Department at Ohio State University, and the Phonetics Department at Saarbrücken University. However, these examples are unlikely to suffice in their present form. For instance, neither training set provides systematic comparisons of the realisation of a specific pitch accent on different segmental material, and in English and German, pitch accents may be realised quite differently in different contexts. For instance, in English, the peak of an accent may shift to the right or left, depending on the amount of sonorant segmental material contained in the stressed syllable or the number of syllables following before an intonation phrase boundary intervenes (see van Santen and Hirschberg, 1994, Silverman and Pierrehumbert, 1990 for segmental effects on pitch accent realisation in English). Such changes in peak location may compound the confusions between the categories L+H* and H*. In German, on the other hand, an H* L- pitch accent does not involve a fall in F0 when realised on an IPfinal syllable with a small proportion of sonorants (see Chapter 5 of the present study). This may lead a transcriber to label the pitch accent as H*H- rather than as H*L-. Thus, detailed information about segmental influences on acoustic patterns is required for successful prosodic labelling, but such information is not given in the EToBI and GToBI training materials. Finally, the acoustic phonetic realisation of a specific label is not likely to be identical in different varieties of American English and German; transcribers need to be aware of this, and they need to know what to expect. When combined, the difficulties which inexperienced labellers face are likely to render a successful application of GToBI or EToBI doubtful. 3 Summary This chapter has summarised previous contrastive accounts of English and German intonation. The survey has shown that authors have agreed that we know little about this particular contrast but have disagreed on most of the aspects which have been investigated. Consequently, some authors have claimed that the intonational structures of English and German are quite similar, but others have claimed them to be fundamentally different. In the present chapter, it was argued that the disagreement is likely to have 34 Introduction and Background arisen because (a) generally, research on German intonation is characterised by less agreement about basic facts than English intonation, (b) researchers may have compared data which are not directly comparable (e.g. utterances analysed in different descriptive traditions), and (c) researchers have assumed that intonation can be modelled with only one level of linguistic representation. English and German may, however, differ at one level of representation and be similar at another. Additionally, the linguistic status of the representations which have been used often remains unclear. A relatively recently developed linguistic framework which allows for a description of intonation contours on several linguistic levels is the autosegmental-metrical framework. In this framework, a distinction may be made between cross-linguistic differences involving, for instance, the phonological systems of two languages and those reflecting phonetic surface distinctions arising despite a shared phonological inventory. Accordingly, this is the framework used for cross-linguistic comparison in this study. As English and German have not been compared previously within the autosegmental-metrical framework, a number of relevant monolingual autosegmentalmetrical accounts of English and German intonation were summarised. The summary illustrated the range of approaches which have been taken within this framework. The differences between two influential systems, the one proposed by Pierrehumbert (1980) and the one proposed by Gussenhoven (1984) were discussed in detail, and it was suggested that Gussenhoven’s approach is better suited to cross-linguistic research. The principal strength of Gussenhoven’s system lies in its ability to capture structural similarities and differences at two levels of phonological representation. English and German may well be felicitously described as not differing at the underlying level of phonological representation but differing at the surface level, and Gussenhoven’s system would allow for such an account. Pierrehumbert’s system, on the other hand, which posits only one level of phonological representation, does not allow for an account of this type. To conclude, the relatively small number of previous contrastive studies on English and German intonation have generated some hypotheses about cross-linguistic similarities and differences, but the lack of agreement among researchers suggests that there is scope for further research. Tightly constrained studies are needed which address the realisation of one or more clearly specified aspect of intonation in a restricted number of conditions. For instance, discoursal aspects of intonation may be compared across languages in one specific speaking style, or the speaker attitudes conveyed by certain patterns may be compared across different social groups. Moreover, the linguistic background of experimental subjects needs to be controlled for. The research presented in the following chapters is restricted to structural aspects of intonation patterns produced in one speaking style, and the speakers were closely matched for language background and age. The assumption was that cross-linguistic data about basic structural 35 Introduction and Background characteristics need to be available first, before other issues such as discoursal or attitudinal differences may be fruitfully addressed. 36