Comparing Correlated Proportions
advertisement

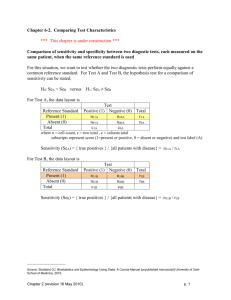
Comparing Correlated Proportions With McNemar’s Test Suppose you are evaluating the effectiveness of an intervention which is designed to make patients more likely to comply with their physicians’ prescriptions. Prior to introducing the intervention, each of 200 patients is classified as compliant or not. Half (100) are compliant, half (100) are not. After the intervention you reclassify each patient as compliant (120) or not (80). It appears that the intervention has raised compliance from 50% to 65%, but is that increase statistically significant? McNemar’s test is the analysis traditionally used to answer a question like this. To conduct this test you first create a 2 x 2 table where each of the subjects is classified in one cell. In the table below, cell A includes the 45 patients who were compliant at both times, cell B the 55 who were compliant before the intervention but not after the intervention, cell C the 85 who were not compliant prior to the intervention but were after the intervention, and cell D the 15 who were noncompliant at both times. After the Intervention Compliant (1) Prior to the Intervention Not (0) Marginals Compliant (1) 45 A 55 B 100 Not (0) 85 C 15 D 100 Marginals 130 70 200 McNemar’s Chi-square, with a correction for continuity, is computed this way: (| b c | 1)2 (| 55 85 | 1)2 . For the data above, 2 6.007 . The chi-square is bc 55 85 evaluated on one degree of freedom, yielding, for these data, a p value of .01425. If you wish not to make the correction for continuity, omit the “1.” For these data that would yield a chi-square of 6.429 and a p value of .01123. I have not investigated whether or not the correction for continuity provides a better approximation of the exact (binomial) probability or not, but I suspect it does. 2 McNemar Done as an Exact Binomial Test Simply use the binomial distribution to test the null hypothesis that p = q = .5 where the number of successes is either count B or count C from the table and N = B + C. For our data, that is, obtain the probability of getting 55 or fewer failures in 85 + 55 = 140 trials of binomial experiment when p = q = .5. The syntax for doing this with SPSS is COMPUTE p=2*CDF.BINOM(55,140,.5). EXECUTE. and the value computed is .01396. McNemar Done With SAS Data compliance; Input Prior After Count; Cards; 1 1 45 1 0 55 0 1 85 0 0 15 Proc Freq; Tables Prior*After / Agree; Weight Count; run; Statistics for Table of Prior by After McNemar's Test ƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ Statistic (S) 6.4286 DF 1 Asymptotic Pr > S 0.0112 Exact Pr >= S 0.0140 The “Statistic” reported by SAS is the chi-square without the correction for continuity. The “Asymptotic Pr” is the p value for that uncorrected chi-square. The “Exact Pr” is an exact p value based on the binomial distribution. McNemar Done With SPSS Analyze, Descriptive Statistics, Crosstabs. Prior into “Rows” and After into “Columns.” Click “Statistics” and select “McNemar.” Continue, OK Prior * After Crosstabulation Count After 0 Prior 1 Total 0 15 85 100 1 55 45 100 Total 70 130 200 Chi-Square Tests Exact Sig. (2Value .014a McNemar Test N of Valid Cases a. Binomial distribution used. sided) 200 Notice that SPSS does not give you a chi-square approximate p value, but rather an exact binomial p value. McNemar Done With Vasser Stats Go to http://faculty.vassar.edu/lowry/propcorr.html Enter the counts into the table and click “Calculate.” Very nice, even an odds ratio with a confidence interval. I am impressed. More Than Two Blocks The design above could be described as one-way, randomized blocks, two levels of the categorical variable (prior to intervention, after intervention). What if there were more than two levels of the treatment – for example, prior to intervention, immediately after intervention, six months after intervention. An appropriate analysis here might be the Cochran test. See http://en.wikipedia.org/wiki/Cochran_test. See also McNemar Tests of Marginal Homogeneity at http://ourworld.compuserve.com/homepages/jsuebersax/mcnemar.htm . Power Analysis I found, at http://www.stattools.net/SSizMcNemar_Pgm.php , an online calculator for obtaining the required sample size given effect size and desired power, etc. For the first sample size calculator, shown below, the effect size is specified in terms of what proportion of the cases are expected to switch from State 1 to State 2 and what proportion are expected to switch from State 2 to State 3. I have seen no guidelines regarding what would constitute a small, medium, or large effect. Suppose that we are giving each patient two diagnostic tests. We believe that 60% will test positive with Procedure A and 90% with Procedure B. We want to use our data to test the null that the percentage positive is the same for Procedure A and for Procedure B. Please note that the calculations for Probability 1 do not take into account any correlation between the results of Procedure A and those of Procedure B, and that correlation is almost certainly not zero. The second set of probabilities does assume a positive correlation between the two procedures. Procedure A Procedure B Probability 1 Probability 2 + + .6(.9) = .54 .59 + _ .6(.1) = .06 .01 - + .4(.9) = .36 .30 - - .4(.1) = .04 .10 In the output, on the next pages, you see that 35 cases are needed under the independence assumption, fewer than 35 if there is a positive correlation. The conservative action to take is to get enough data for the calculation that assumes independence. Assuming Independence Positive Correlation So, how large is the correlation resulting from the second set of probabilities? I created the set of data shown below, from the probabilities above, and weighed the outcomes (A and B) by the frequencies. I then correlated A with B and obtained 0.365, a medium-sized correlation. Since both variables are binary, this correlation is a phi coefficient. Return to Wuensch’s Stats Lessons Karl L. Wuensch, October, 2011