Technical Report - Personal.psu.edu
advertisement

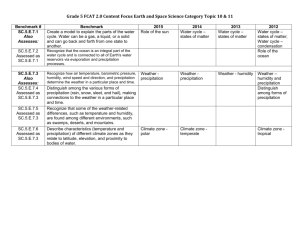
Group 3 – Milestone4 Michael O'Neill, Stephen Hopkins, Bryant Sell WILDFIRE RISK Introduction Wildfires are a real danger and need to be better predicted to know when and where fires will occur. Weather has a big impact on not only the fire starting and spreading, but also on the firefighters trying to fight them as well. For our project, we generated an algorithm that uses multiple variables to compute a wildfire risk map. The objectives are to generate different levels of risk utilizing threshold values for each variable, which we turned into probabilities to show, on a map, where wildfire risks are the highest. Data & Methods For wildfires, we found data for days in which we knew that the fire risk was high in parts of the country. The data is SREF ensemble model forecast. There are 21 model members in the ensemble that compute similar, but different, results that are all possible. The final result takes these ensembles and averages the answers from each member. The variables in the SREF that we used include temperature, relative humidity, wind speed and precipitation. The only SREF relative humidity variable is for 850mb which is not at the surface where we need the data for. To derive something useful from this, we used the temperature dew point and heights at 850 mb along with the surface temperature to compute an estimate of the relative humidity at the surface. For each of the five main variables, the risk assigns a ‘1’ for highest risk and ‘0’ for lowest risk. However two of the categories are combined to give a total of four risks. The four risks are then averaged together and multiplied by 100 at the end to give the percentage of wildfire risk given by that particular model. To get the final risk, all 21 ensemble members are added, and then divided by 21. To decide when wildfire risks are highest, we started with precipitation. If there is no chance of precipitation at the location for the given time, the risk of wildfire from precipitation is automatically set at ‘1’. If precipitation is expected, we divided it into three categories. For precipitation during a 3 hour period of less than .05in, the risk is set at ‘1’, for precipitation between .05in and .5in, the risk is .5, and finally for anything above half an inch, the risk is ‘0’. Next, we looked at relative humidity. For humidity of less than 25%, this risk is assigned a ‘1’. For between 25% and 50% RH, the risk is ‘.5’, for RH between 50% to 75%, the risk is given a value of ‘.25’ and for anything above 75% the risk is ‘0’. For the wind speed, anything less than 5 mph the risk is automatically ‘0’. For wind speeds between 5 and 15 mph, the risk is assigned ‘.25’, for 15 to 25 mph, the risk is ‘.5’, for 25 to 35, the risk is ‘.75’ and for anything above 35-----, the risk is ‘1’. Finally, if the temperature is less than 32 degrees Fahrenheit, the risk is 0. For temperatures above 70 degrees, the risk is ‘1’. Results The maps that are generated show areas where the probabilities are between 0% and 25%, 25% and 50%, 50% and 75%, 75% and 100%- each category designated by different colors. To test the algorithm, we used four sets of mock data values for each variable and entered them into the formula for risk calculation. This mock data are values such that we can verify high and low risks. The risk calculation is simply the average of each category’s risk, for instance we have a risk of 1 for precipitation and relative humidity, and a risk of 0 for temperature and wind, and we should get out a total risk of 50%. Discussion/Conclusion This product can be used in a number of ways. The most obvious implication is for firefighters who need to know when to be alert for potential wildfires. They may need to know ahead of time when they will need to have extra resources prepared and ready for possible fires. For those who live in fire prone areas, you need to know when you shouldn’t have open fires outside or when you may need to be aware of fires nearby that may come close to their homes. Disaster response teams may need to know where to set up relief efforts for those affected if homes evacuated or lost. Fires also have a dangerous health concerns for those who have breathing problems due to the smoke. In the future, our product could be fine-tuned if we find that the variable requirements for the risk are off. We may need to add more categories or change the percentage of risk assigned to each variable. More variables could be added to make the model more complex. Lightning risk can be used to predict where fires may be sparked. It could be implemented so that the used could type in a location and they would receive the wildfire risk value for that particular location only. We could also make it easier to change the data that is being used so that it can be updated for future forecasts.